

状态空间模型是时间序列分析领域中一类强大、灵活、多样的模型,
配合卡尔曼滤波技术,可以涵盖ARIMA模型、许多非平稳的、带有外生变量的模型,
比前面所述的线性时间序列模型更为灵活。
R扩展包statespacer实现了许多基于线性高斯状态空间模型的模型,
并且可以自定义模型。
参考:
- (Tsay 2010)
- (Durbin and Koopman 2012)
- (Beijers 2020)
作为入门,
先介绍一个局部水平模型。
这个模型很简单,
所以可以用来演示状态空间模型的表示和估计。
27.1 模型
设{yt,t=1,2,…,T}为时间序列,
满足如下模型
yt=μt+1=μt+et, {et}∼iid N(0,σ2e), t=1,2,…,n,μt+ηt, {ηt}∼iid N(0,σ2η),(27.1)(27.2)
其中{et}与{ηt}相互独立,
初始值μ1为给定值或者是服从正态分布的随机变量,
且与{et,ηt,t>0}相互独立。
称{μt}为{yt}的水平,
模型中{yt}可观测而{μt}不可观测。
方程(27.1)-(27.2)是线性高斯状态空间模型的一个特例。
{μt}代表系统在t时刻所处的状态,
不可观测,方程(27.2)称为状态方程,
描述了系统的内在演变规律;
{yt}代表系统在t时刻的观测值或输出值,
(27.1)称为观测方程,
{et}是观测误差,
仅影响到t时刻,
是一个瞬态的误差或噪声。
这个模型称为局部水平模型,
也是“结构时间序列模型”的一个特例。
例27.1 考虑Alcoa股票日现实波动率数据,
时间期间为2003-01-02到2004-05-07,
共340个观测。
日现实波动率是用交易日内每隔10分钟的对数收益率的平方和计算的。
da <- read_table("aa-3rv.txt",
col_names = FALSE,
show_col_types = FALSE)
ts.alcoa <- ts(log(da[[2]]))plot(ts.alcoa, main="Alcoa股票日现实波动率对数值数据")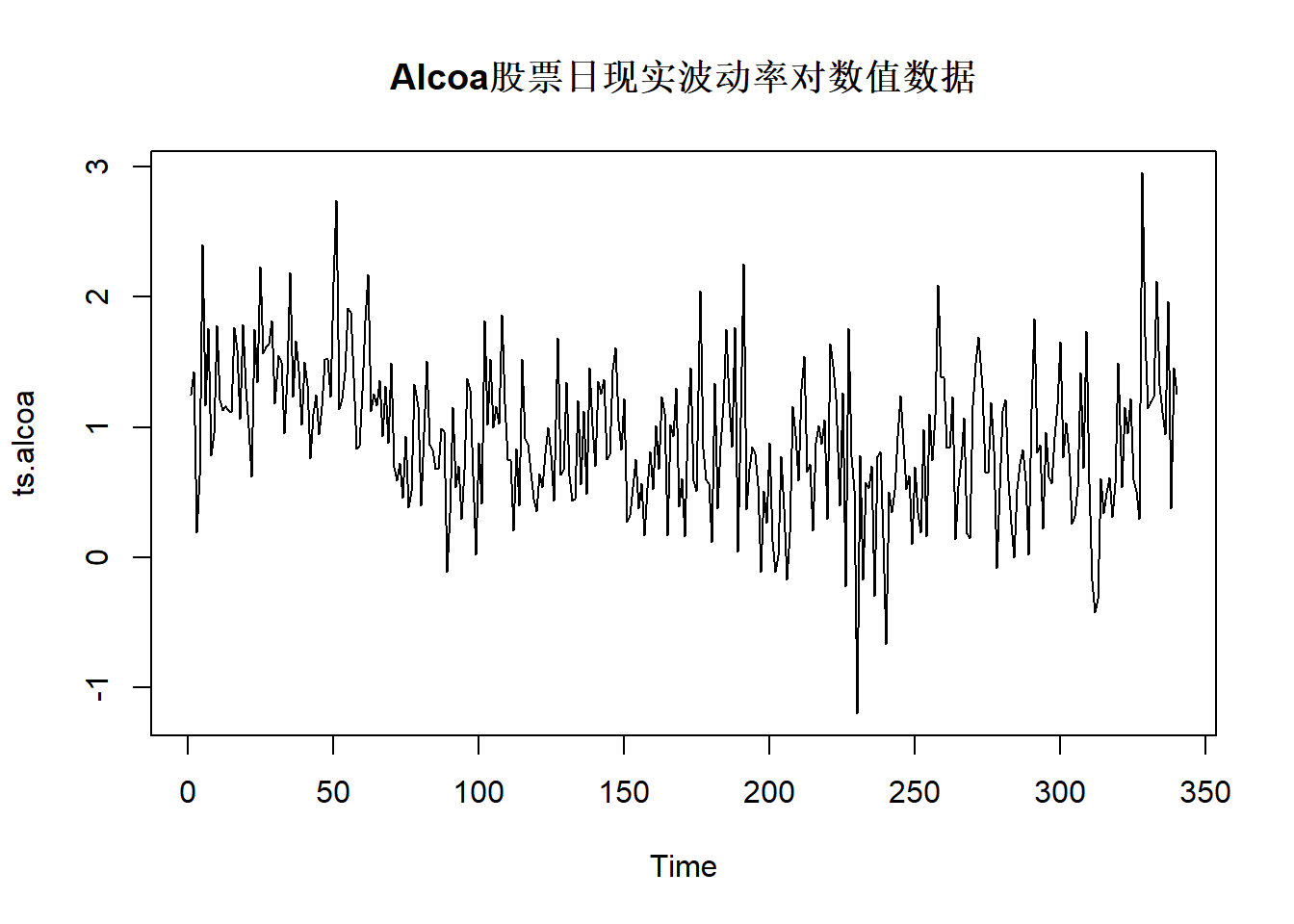

可以用局部水平模型获得{μt},
作为去噪声的波动率估计。
27.2 局部水平模型与ARIMA模型的关系
注意到
yt−yt−1=ηt−1+et−et−1,
记ξt=ηt−1+et−et−1,
易见ξt的自相关函数在1以后截尾,
所以ξt服从一个MA(1)模型。
由多元正态分布的性质可知存在{at}∼N(0,σ2a)和|θ|≤1使得
yt−yt−1=at+θat−1,
从而yt服从一个高斯的ARIMA(0,1,1)模型。
由
Var(ξt)=Cov(ξt,ξt−1)=2σ2e+σ2η=σ2a(1+θ2),−σ2e=θσ2a,
可以求解出θ且使得−1<θ<0:
θ=b+b2+4‾‾‾‾‾‾√2, 其中 b=−2−σ2ησ2e<−2.
反过来,如果yt服从一个ARIMA(0,1,1)模型且θ为负值,
则可以将其写成(27.1)-(27.2)的形式。
如果θ为正值,
可以写成σe=0的形式。
例27.2 对Alcoa股票日现实波动率对数值数据用ARIMA建模。
mod <- arima(ts.alcoa,
order=c(0,1,1))
mod##
## Call:
## arima(x = ts.alcoa, order = c(0, 1, 1))
##
## Coefficients:
## ma1
## -0.8582
## s.e. 0.0397
##
## sigma^2 estimated as 0.2688: log likelihood = -258.98, aic = 521.95得到的ARIMA(0,1,1)模型为:
(1−B)yt=(1−0.8582B)at, at∼WN(0,0.2688).
通过σ2e, σ2η与θ, σ2a的关系,
可以解出
σ2e=−θσ2a=0.2307,σ2η=σ2a(1+θ2)−2σ2e=0.0054
可见噪声严重超过了信号的扰动。
下面用R的statespacer扩展包估计局部水平模型。
library(statespacer)
ssr1 <- statespacer(
y = cbind(as.vector(ts.alcoa)),
local_level_ind = TRUE,
initial = rep(0.5*log(var(ts.alcoa)), 2),
verbose = TRUE)## Starting the optimisation procedure at: 2022-01-23 10:36:04## initial value 1.022439
## iter 10 value 0.765458
## iter 20 value 0.764395
## final value 0.764395
## converged## Finished the optimisation procedure at: 2022-01-23 10:36:04## Time difference of 0.0195000171661377 secs上面的程序中输入数据需要是矩阵形式,
每列为一个时间序列分量,
一元时间序列也需要输入为仅有一列的矩阵。
选项local_level_ind = TRUE表示有局部水平成分。initial给出超参数初值选取,
为了保证σ2e和σ2η估计为正数,
模型中使用了其对数值作为参数,
所以初值取了对数。
查看估计的σ2e和σ2η:
c(sigmasqr_e = ssr1$system_matrices$H$H,
sigmasqr_level = ssr1$system_matrices$Q$level)## sigmasqr_e sigmasqr_level
## 0.230623632 0.005404681与从ARIMA模型换算的结果基本相同。
statespacer利用了(Durbin and Koopman 2012)的模型和记号,
H表示观测方程误差项方差阵,
Q表示系统方程误差项方差阵。
设statespacer()的输出为ssr,
这是一个列表,
其中ssr$system_matrices$H$H是观测方程的方差阵估计,
这里即σ2e,
但保存成1×1矩阵;ssr$system_matrices$Q是与系统方程方差阵有关的输出,
而局部水平的状态方程对应的误差项的方差阵则为ssr$system_matrices$Q$level,
这里就是σ2η,
保存成1×1矩阵。
27.3 滤波、平滑和预报
对状态空间模型如(27.1)-(27.2),
输入数据{yt,t=1,2,…,n},
如果认为模型中参数(这里是σ2e和σ2η)已知,
经常讨论如下的统计推导问题:
- 滤波:从{y1,…,yt}估计μt;
- 平滑:从{y1,…,yn}估计{μ1,μ2,…,μn};
- 预报:从{y1,…,yt}估计μt+h或yt+h(h>0)。
当参数已知,
记y1:t=(y1,…,yt),
易见:
- 滤波解为E(μt|y1:t);
- 平滑解为E(μt|y1:n);
- 预报解为E(μt+h|y1:t)或E(yt+h|y1:t)。
设μ1∼N(a1,P1),
且与扰动序列独立。
由正态分布的性质,
状态空间模型(27.1)-(27.2)是高斯过程,
其条件分布仍为高斯分布,
所以μt|y1:s和yt|y1:s仍服从高斯分布(多元正态分布),
其条件期望为为最小均方误差估计,
也是线性无偏估计。
μt在y1:s下的条件分布完全由条件期望和条件方差决定。
记μt|s=E(μt|y1:s),
记Σt|s=Var(μt|y1:s)。
记yt|s=E(yt|y1:s)。
特别地,
记at=E(μt|y1:t−1),
Pt=Var(μt|y1:t−1)。
由高斯分布性质,
条件方差都是非随机的。
记
vt=yt−E(yt|y1:t−1),
这是对yt做最优一步预报时的误差,
显然Evt=0,
令
Ft=Ev2t=Var(vt),
由多元正态分布性质,
vt与y1:t−1独立,
所以也有
Ft===Var(vt)=E(v2t)=E(v2t|y1:t−1)E[(yt−E(yt|y1:t−1))2|y1:t−1]Var(yt|y1:t−1).
于是由观测方程可得
yt|t−1=vt=Ft===E(yt|y1:t−1)=E(μt+et|y1:t−1)=μt|t−1=at,yt−yt|t−1=yt−at,Var(yt−yt|t−1|y1:t−1)=Var(μt+et−μt|t−1|y1:t−1)Var(μt−μt|t−1|y1:t−1)+Var(et|y1:t−1)Σt|t−1+σ2e=Pt+σ2e.(27.3)(27.4)
由多元正态分布性质可知预报误差vt与y1:s(s<t)独立,
所以
Cov(vt,ys)=0, t>s.
从而{vt,t=1,2,…,n}相互独立。
由多元正态性质,
σ(y1,…,yt−1,yt)=σ(y1:t−1,vt).
其中σ(⋅)表示由其中的随机变量所生成的最小σ代数。
对随机向量X,Y,
记μX=EX,
ΣXX=Var(X),
ΣXY=Cov(X,Y)。
从多元正态分布性质有如下定理(Tsay 2010) P.562:
定理27.1 设随机向量X, Y,
Z的联合分布为多元正态分布,
每一个的协方差阵都非退化,
ΣXZ=0。
则有如下性质:
(1) (2) (3) (4) E(Y|X)=μY+ΣYXΣ−1XX(X−μX);Var(Y|X)=ΣYY−ΣYXΣ−1XXΣXY;E(Y|X,Z)=E(Y|X)+E(Y−μY|Z)=E(Y|X)+ΣYZΣ−1ZZ(Z−μZ);Var(Y|X,Z)=Var(Y|X)−ΣYZΣ−1ZZΣZY =ΣYY−ΣYXΣ−1XXΣXY−ΣYZΣ−1ZZΣZY.
另外,
Y−E(Y|X)与X独立,所以
Var(Y|X)=E[(Y−E(Y|X))2|X]=E[(Y−E(Y|X))2],
等于X对Y的最优估计的均方误差。
27.4 卡尔曼滤波
卡尔曼滤波是一种递推算法,
对t=1,2,…,
基于μt|y1:t−1的条件分布和新得到的观测值yt,
求μt|y1:t条件分布,
这等于μt|(y1:t−1,vt)条件分布,
只要求条件高斯分布的期望和方差。
由前一节,
μt|y1:t−1∼N(at,Pt),
vt∼N(0,Ft)与y1:t−1独立。
注意{et}与{ηt}独立所以{et}与{μt}独立,
利用定理27.1,
条件期望为
====μt:t=E(μt|y1:t)E(μt|y1:t−1,vt)E(μt|y1:t−1)+E(μt−Eμt|vt)at+Cov(μt−Eμt,vt)Var(vt)vtat+Cov(μt,vt)Ftvt.
其中
=======Cov(μt,vt)E(μtvt)(注意Evt=0)E[μt(yt−at)]E[μt(μt+et−at)]E[μt(μt−at)]+E[μtet]E[μt(μt−at)]+0E{E[(μt−at)2|y1:t−1]}E{Pt}=Pt.
于是
E(μt|y1:t−1,vt)=at+PtFtvt,
记
Kt=PtFt=PtPt+σ2e,(27.5)
称Kt为卡尔曼增益。
可以将条件期望写成
E(μt|y1:t−1,vt)=at+Ktvt,
这个公式将y1,…,yt−1,yt对μt的最优预报(滤波)公式分解为两部分,
第一部分是y1,…,yt−1对μt的最优预报,
第二部分是yt新增的信息vt对μt的最优预报,
vt的系数为卡尔曼增益Kt,
最优预报是线性的。
再来求条件方差Var(μt|y1:t−1,vt)。
由定理27.1,
====Σt|t=Var(μt|y1:t)Var(μt|y1:t−1,vt)Var(μt|y1:t−1)−[Cov(μt,vt)]2Var(vt)Pt−P2tFt=Pt(1−PtFt)Pt(1−Kt).
记
Lt=1−Kt=σ2ePt+σ2e,(27.6)
则有
Σt|t=PtLt.
因此,滤波公式为:
μt|t=Σt|t=Kt=at+Ktvt,Pt(1−Kt),PtFt.(27.7)(27.8)
有了μt|y1:t分布后,
可以给出一步预测的条件分布μt+1|y1:t,
这也只需要计算条件期望和条件方差:
at+1==Pt+1==μt+1|t=E(μt+1|y1:t)=E(μt+ηt|y1:t)μt|t+0=μt|t,Σt+1|t=Var(μt+1|y1:t)=Var(μt|y1:t)+Var(ηt|y1:t)Σt|t+σ2η.(27.9)(27.10)
在上式推导中要注意ηt是μt+1所对应的状态方程的误差项,
ηt与y1:t和μ1,…,μt独立。
(27.7)–(27.10)构成了卡尔曼滤波的一轮操作。
在下一轮中,
输入了新的观测yt+1后,
计算μt+1|y1:t+1的均值μt+1|t+1和方差Σt+1|t+1,
再计算μt+2|Yt+1的均值at+2和方差Pt+2,……。
各个关键变量的含义汇总:
- y1:t={y1,y2,…,yt}。
- at=E(μt|y1:t−1),
Pt=Var(μt|y1:t−1),
μt一步预报分布为
μt|y1:t−1∼N(at,Pt)。 - μt|t=E(μt|y1:t),
Σt|t=Var(μt|y1:t),
μt的滤波分布为
μt|y1:t∼N(μt|t,Σt|t)。 - vt=yt−E(yt|y1:t−1)是yt的一步预报误差,
Ft=E(v2t)=Var(yt|y1:t−1),
vt∼N(0,Ft)与y1:t−1独立。 - Kt=PtFt称为Kalman增益,
是用y1:t−1,vt对μt作最优线性预测时vt的系数。 - yt的一步预报分布为yt|y1:t−1∼N(at,Ft)。
设初始状态μ1服从N(μ1|0,Σ1|0)=N(a1,P1),
将(27.7)-(27.8)
代入到(27.9)-(27.10)中,
得卡尔曼滤波过程如下:
⎧⎩⎨⎪⎪⎪⎪vt=Ft=Kt=at+1=Pt+1=yt−at,Pt+σ2e,Pt/Ft,μt+1|t=at+Ktvt,Σt+1|t=Pt(1−Kt)+σ2η, t=1,2,…,n.(27.11)
算法中初始分布参数a1=μ1|0和P1=Σ1|0的选取有很大影响,
后面将专门说明。
(27.11)的卡尔曼滤波算法在给定参数
σ2e和σ2η和初始分布参数a1,P1后可以迭代计算(y1,y2,…,yn)的联合密度,
因此可以用来进行最大似然估计。
如果不假定模型中的μt,yt都服从多元正态分布,
将滤波问题看成是将y1:t看成已知量,
用y1:t对μt做最优线性无偏估计(Minimum Variance Linear Unbiased Estimate, MVLUE,也称为BLUE或BLUP)的问题,
结果将得到完全相同的公式。
所以卡尔曼滤波可以看成是递推的最优线性无偏估计算法。
如果将模型中的μt看成是随机参数,
将yt看成是观测值,
从先验分布μt|y1:t−1到后验分布μt|(y1:t−1,yt)的计算公式也和卡尔曼滤波公式完全相同。
参见(Durbin and Koopman 2012)第2.2节。
对前面Alcoa现实波动率对数值数据,
利用估计的模型参数进行卡尔曼滤波计算,
将原始序列与滤波结果(μt|t,图中绿色线),
一步预测结果(yt|t−1=at,图中红色线)同时显示:
plot(ts.alcoa, ylim=c(-2, 4))
lines(as.vector(time(ts.alcoa)),
ssr1$filtered$level, col="green")
lines(as.vector(time(ts.alcoa)),
ssr1$predicted$yfit, col="red")
legend("topleft", lty=1, col=c("black", "green", "red"),
legend=c("Obs", "Filtered", "Predicted 1 step"))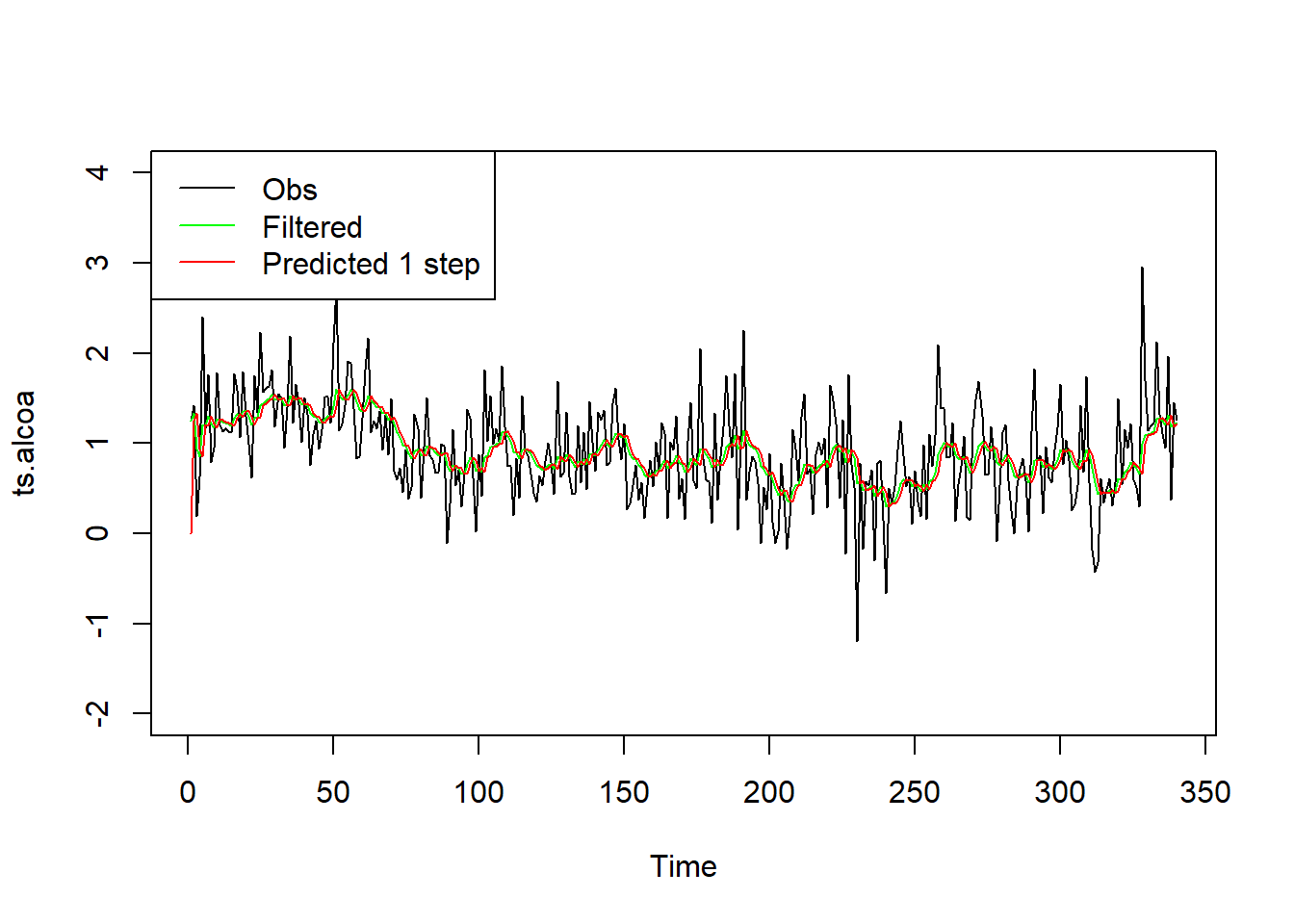
滤波值和一步预测值的序列都比较光滑。
程序中,
拟合结果的$filtered成分保存滤波结果,$filtered$level为{μt}的滤波结果{μt|t};
拟合结果的$predicted成分保存一步预报结果,$predicted$yfit保存对yt的一步预报{yt|t−1}。$filtered中还有$filtered$a表示状态的滤波,
这里即{μt|t},$filtered$P表示滤波方差,即{Σt|t},
是一个1×1×n数组,
n为时间序列观测长度。$predicted中还有$predicted$v,即{vt},$predicted$Fmat即{Ft},$predicted$a即{at},$predicted$P即{Pt}。
一步预测误差(vt)的图形:
plot(as.vector(time(ts.alcoa)),
ssr1$predicted$v,
type="l", ylim=c(-2, 4),
xlab="", ylab="error")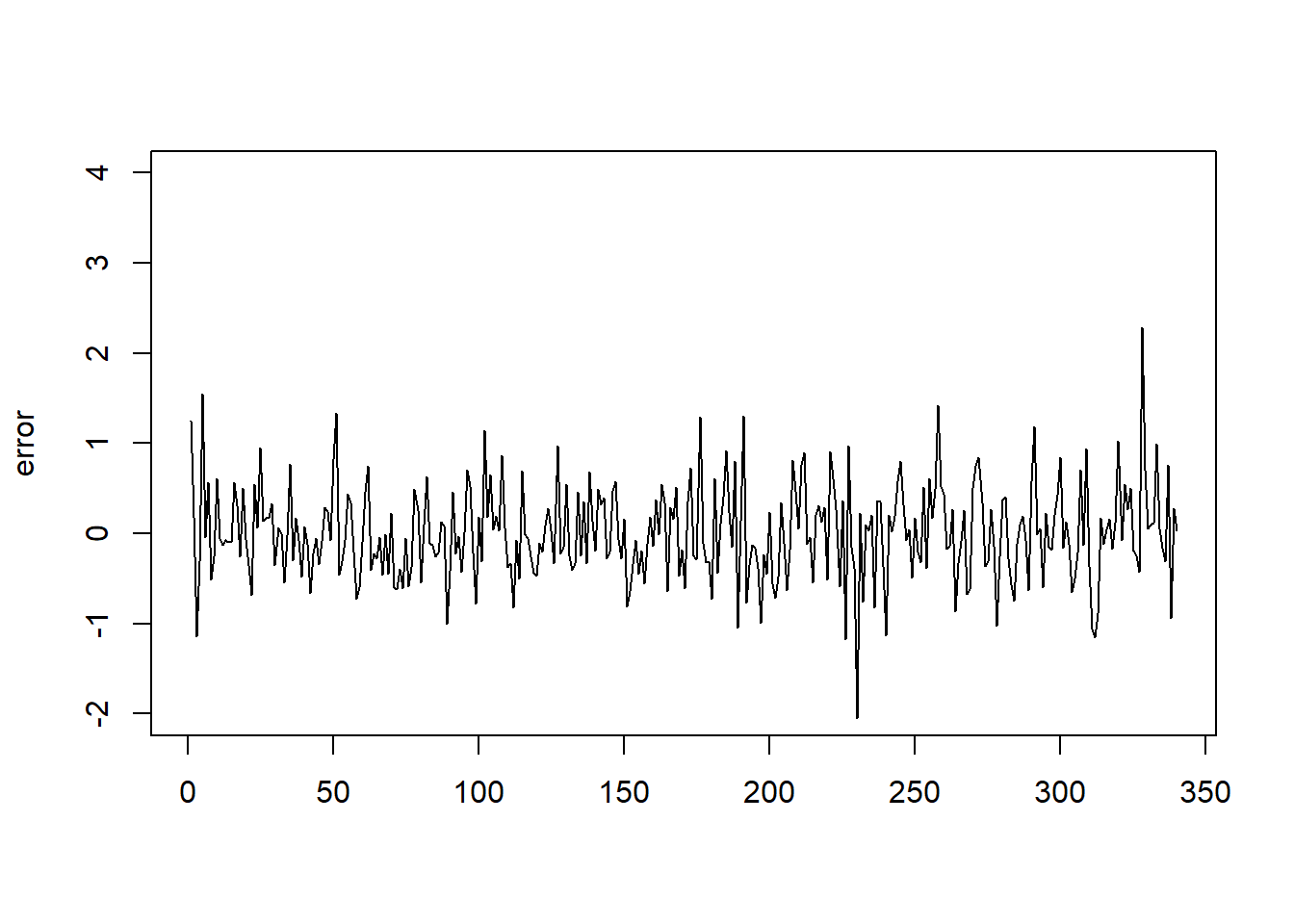
一步预测误差较大,
这可能是因为用高频数据计算波动率,
本身就有较大的观测噪声。
滤波的水平μt及其95%置信区间的图形:
plot(ts.alcoa, ylim=c(-2, 4))
lines(as.vector(time(ts.alcoa)),
ssr1$filtered$level, col="red")
lines(as.vector(time(ts.alcoa)),
ssr1$filtered$level + 1.96*sqrt(ssr1$filtered$P[1,1,]),
col="green", lty=3)
lines(as.vector(time(ts.alcoa)),
ssr1$filtered$level - 1.96*sqrt(ssr1$filtered$P[1,1,]),
col="green", lty=3)
legend("topleft", lty=c(1,1,3), col=c("black", "red", "green"),
legend=c("Obs", "Filtered", "95% CI of level"))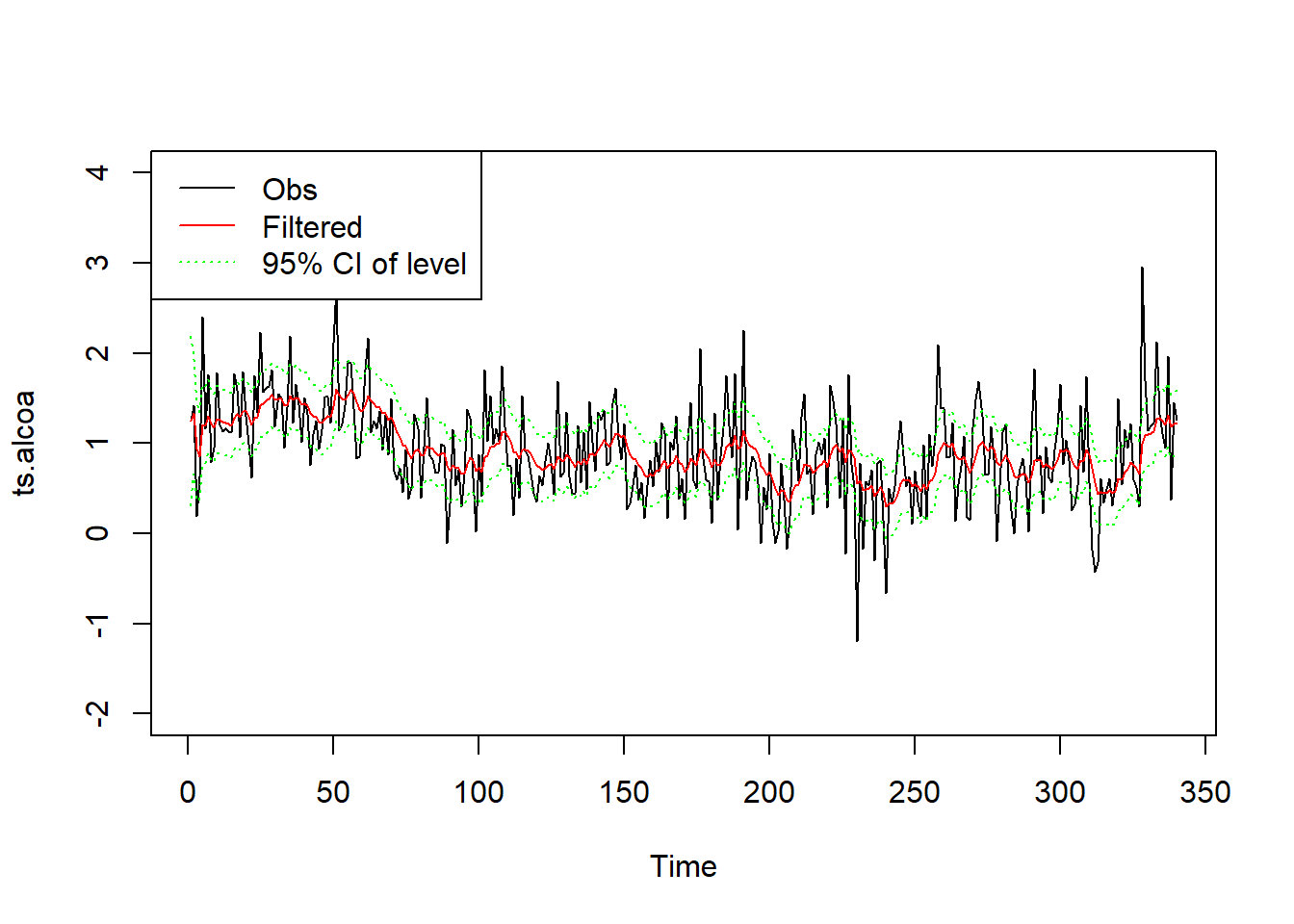
27.5 一步预报误差
一步预报误差序列{vt}在滤波算法和参数估计中起到重要作用。
从初值μ1的分布N(a1,P1)出发,
可以递推计算{vt,t=1,2,…,n},
vt是y1,y2,…,yt的线性组合,
如:
v1=v2=v3=y1−a1,y2−a2=y2−a1−K1(y1−a1),y3−a3=y3−a1−K2(y2−a1)−K1(1−K2)(y1−a1),⋯⋯
将从y到v的这些线性变换写成矩阵形式,
令Yn=(y1,…,yn)T,
v=(v1,…,vn)T,
1T表示元素都等于1的n维列向量,
则
v=K(Yn−a11n),(27.11)
其中
K=⎛⎝⎜⎜⎜⎜⎜⎜1k21k31⋮kn101k32⋮kn2001⋮kn3⋯⋯⋯⋱⋯000⋮1⎞⎠⎟⎟⎟⎟⎟⎟,
而ki,i−1=−Ki−1, i=2,3,…,n;
对i=3,4,…,T和j=1,2,…,i−2,有
kij=−(1−Ki−1)(1−Ki−2)…(1−Kj+1)Kj。
从卡尔曼滤波的公式可以看出,
卡尔曼增益Kt,t=1,2,…,n并不依赖于观测值{yt},
只依赖于参数σ2η, σ2e以及初始分布方差P1,
是非随机的。
{vt}是相互独立的随机变量序列。
事实上,
(y1,y2…,yn)的联合密度函数为
py(y1,y2,…,yn)=py(y1)∏t=2npy(yt|Yt−1),
从(27.11)看出,
从(y1,y2…,yn)到(v1,v2…,vn)的变换的雅科比行列式绝对值等于1。
由多元的连续性随机向量变换的密度公式可知
=pv(v1,v2,…,vn)=py(y1,y2,…,yn)=py(y1)∏t=2npy(yt|Yt−1)pv(v1)∏t=2npv(vt)=∏t=1npv(vt),
其中py(y1)表示y1的分布密度,
pv(v1)表示v1的分布密度,
因为y1=μ1+e1∼N(a1,P1+σ2e),
而v1=y1−y1|0=y1−μ1|0∼N(0,P1+σ2e),
所以
py(y1)=Φ′(y1−a1P1+σ2e‾‾‾‾‾‾‾‾√)=Φ′(v1P1+σ2e‾‾‾‾‾‾‾‾√)=pv(v1),
对t≥2,
yt|Yt−1∼N(at,Ft),
vt=yt−yt|t−1∼N(0,Ft),
Ft=Pt+σ2e,
所以
py(yt|Yt−1)=Φ′(yt−atFt‾‾√)=Φ′(vtFt‾‾√)=pv(vt),
其中Φ(⋅)表示标准正态分布函数。
从上述的(v1,v2,…,vn)的联合密度可知各个分量相互独立,
均值为0,
vt的方差为Ft=Pt+σ2e。
从另一个角度看,
v是对Yn的正交化,
类似于Gram-Schimdt正交化方法,
(v1,…,vt)与(y1,…,yt)可以互相线性表示。
记Var(Yn)=Ω,
由(27.11)可知
Var(v)=Ω=diag(F1,F2,…,Fn)=KΩKT,K−1diag(F1,F2,…,Fn)(K−1)T,
其中K−1为下三角矩阵且对角线元素都等于1,
这构成了对y的方差阵Ω的Cholesky分解。
27.6 状态的一步预报误差
令
ζt=μt−μt|t−1=μt−E(μt|y1:t−1),(27.12)
则
Var(ζt|y1:t−1)=Eζ2t=Var(ζt)=Pt,
由卡尔曼滤波公式得
vt=yt−μt|t−1=μt+et−μt|t−1=ζt+et,
下一个时间点
ζt+1======μt+1−μt+1|tμt+ηt−(μt|t−1+Ktvt)μt−μt|t−1+ηt−Kt(ζt+et)ζt+ηt−Kt(ζt+et)(1−Kt)ζt+ηt−KtetLtζt+ηt−Ktet,
于是有
vt=ζt+1=ζt+et,Ltζt+ηt−Ktet, t=1,2,…,T.(27.13)(27.14)
这构成了以{vt}为观测,
{ζt}为状态的系数时变的线性高斯状态空间模型。
27.7 状态平滑
模型的滤波,
是利用已有观测{y1,…,yt}估计μt
得μt|y1:t。
在获得所有的观测{y1,…,yn}后,
可以利用所有的观测来估计μt,
得到μt|Yn的分布,
这个问题称为平滑问题。
注意:
- 所有的联合分布都是正态的,
所以记μt|y1:n∼N(μt|n,Σt|n)=N(μ̂ t,Vt),
称μ̂ t为平滑状态(smoothed state),
称Vt为平滑状态方差。 - {v1,v2,…,vt}相互独立,
可以与{y1,y2,…,yt}互相线性表示。
Evt=0, Var(vt)=Ft。
显然
σ(y1,…,yt−1,yt,…,yn)=σ(y1,…,yt−1,vt,…,vn).
条件分布μt|y1:n,
等于条件分布μt|y1:t−1,vt,,˙vn。
条件分布为高斯分布,
只要求条件期望和条件方差。
注意vt,…,vn与y1:t−1独立,
由定理27.1,
条件期望为
====μ̂ t=E(μt|y1:n)=E(μt|y1:t−1,vt,…,vn)E(μt|y1:t−1)+E(μt−Eμt|vt,…,vn)at+Cov(μt,(vt,…,vn))Var−1((vt,…,vn))(vt,…,vn)Tat+(Cov(mt,vt),Cov(mt,vt−1),…,Cov(mt,vn)))diag(F−1t,F−1t+1,…,F−1n)(vt,…,vn)Tat+∑j=tnCov(mt,vj)Fjvj.
只要求Cov(mt,vj),
j=t,t+1,…,n。
对j≥t,注意到ζj,ej,ηj,vj都与y1:t−1独立,
ej与ζj独立,
有
===Cov(μt,vj)=E[(μtvj)]E{E(μtvj|y1:t−1)}E{E[(μt−μt|t−1)vj|y1:t−1]}E{E[ζtvj|y1:t−1]}=E[ζtvj],
对j=t,t+1,…,n计算E[ζtvj]:
E(ζtvt)=E(ζtvt+1)===E(ζtvt+2)=⋮E(ζtvn)=E[ζt(ζt+et)]=E(ζ2t)+0=Pt,E[ζt(ζt+1+et+1)]=E[ζtζt+1]+0E[ζt(Ltζt+ηt−Ktet)]=E[Ltζ2t]+0+0PtLt,E[ζt(ζt+2+et+2)]=⋯=PtLtLt+1,Pt∏j=tn−1Lj.
从而,μ̂ t=μt|n公式为
μ̂ t=≡μt|n=at+PtvtFt+PtLtvt+1Ft+1+PtLtLt+1vt+2Ft+2+⋯+PtLtLt+1…Ln−1vnFnat+Ptrt−1,
其中
rt−1=vtFt+Ltvt+1Ft+1+LtLt+1vt+2Ft+2+⋯+LtLt+1…Ln−1vnFn,(27.15)
是新息(vt,vt+1,…,vn)的线性函数,
满足如下递推公式:
rt−1==vtFt+Lt(vt+1Ft+1+Lt+1vt+2Ft+2+⋯+Lt+1…Ln−1vnFn)vtFt+Ltrt,
令rn=0,
有反向递推算法
rt−1=vtFt+Ltrt, t=n,n−1,…,2,1.
所以,
为了求得μ̂ t=μt|n,
需要先进行卡尔曼滤波求出at, Pt, vt, Ft, Kt, Lt,
然后令rn=0,用反向递推计算:
rt−1=μ̂ t=vtFt+Ltrt,μt|n=at+Ptrt−1, t=n,n−1,…,2,1.(27.16)
因为rt是vt+1,…,vn的线性组合,
由v1,…,vn的独立性可知rt,rt+1,…,rn与v1,v2,…,vt相互独立,rt与y1:t相互独立。
27.7.1 状态平滑方差计算
记vt:n=(vt,vt+1,…,vn)T,
则y1:t−1和vt:n独立,
由定理27.1,
Vt====Σt|n=Var(μt|y1:n)=Var(μt|y1:t−1,vt,…,vn)Var(μt|y1:t−1,vt:n)Var(μt|y1:t−1)−[Cov(μt,vt:n)]T[Var(vt:n)]−1[Cov(μt,vt:n)]Pt−∑j=tn[Cov(μt,vj)]2Fj,
其中Cov(μt,vj)=E(ζtvj)已经在前面给出公式。
所以
Vt===Σt|nPt−P2t1Ft−P2tL2t1Ft+1−⋯−P2t(∏j=tn−1L2j)1FnPt−P2tNt−1,
其中
Nt−1==1Ft+L2t1Ft+1+L2tL2t+11Ft+2+⋯+(∏j=tn−1L2j)1Fn1Ft+L2tNt.(27.17)
取Nn=0,
Nt−1是t−1之后的一步预报误差方差倒数的加权和,
并且由rt−1中各个vt的独立性恰好有
Var(rt−1)==1Ft+L2t1Ft+1+L2tL2t+11Ft+2+⋯+(∏j=tn−1L2j)1FnNt−1.
取Nn=0,
状态平滑方差Vt=Σt|n可以反向递推计算如下:
Nt−1=Vt=1Ft+L2tNt,Σt|n=Pt−P2tNt−1, t=n,n−1,…,2,1.(27.18)(27.19)
例27.3 Alcoa股票日现实波动率对数值数据的平滑。
Alcoa股票日现实波动率对数值数据以及平滑结果图形:
plot(ts.alcoa, ylim=c(-2, 4))
lines(as.vector(time(ts.alcoa)),
ssr1$smoothed$level, col="red")
lines(as.vector(time(ts.alcoa)),
ssr1$smoothed$level + 1.96*sqrt(ssr1$smoothed$V[1,1,]),
col="green", lty=3)
lines(as.vector(time(ts.alcoa)),
ssr1$smoothed$level - 1.96*sqrt(ssr1$smoothed$V[1,1,]),
col="green", lty=3)
legend("topleft", lty=c(1,1,3), col=c("black", "red", "green"),
legend=c("Obs", "Smoothed", "95% CI of level"))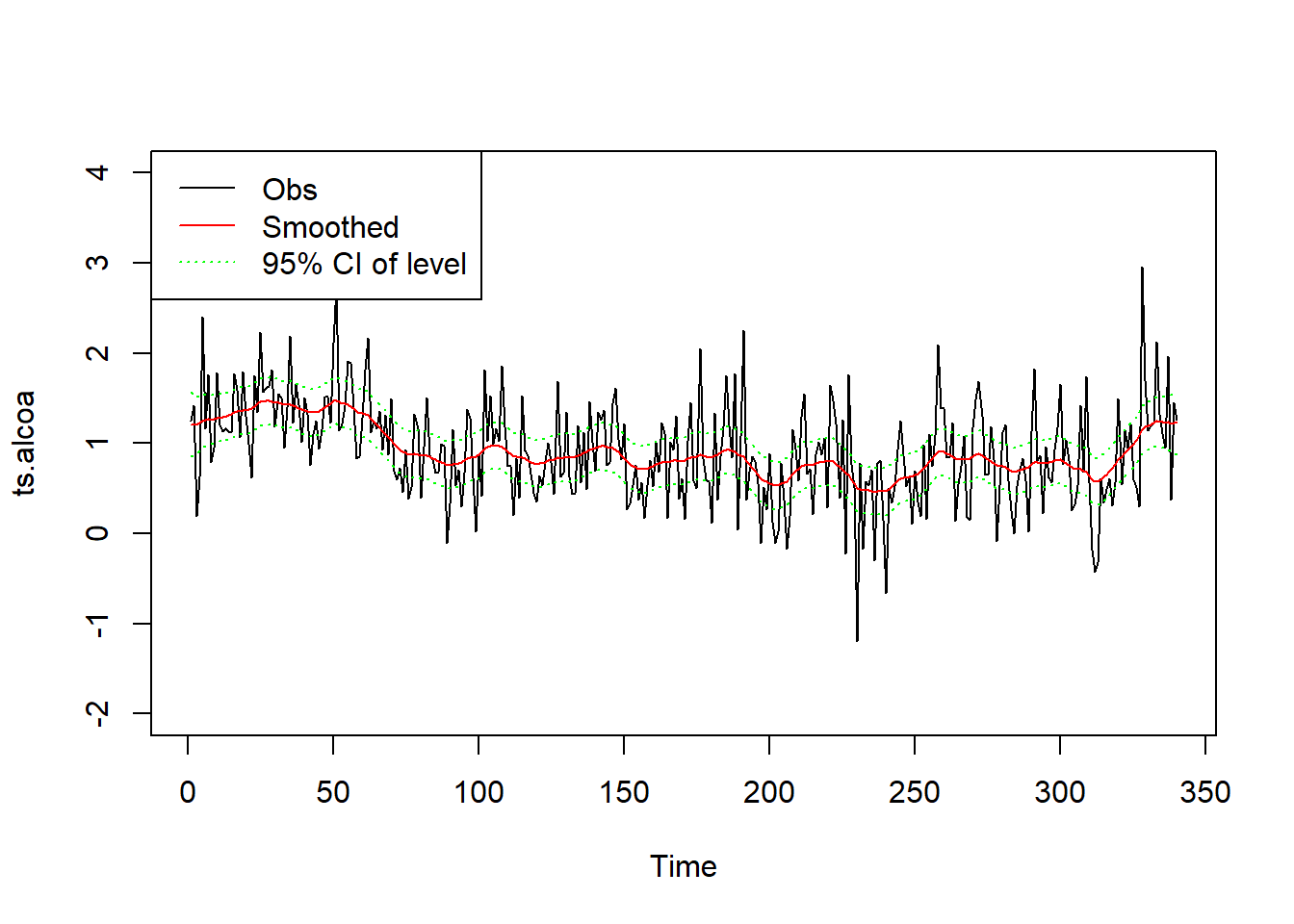
模型结果中smoothed成分保存平滑结果,smoothed$level保存局部水平μt的平滑结果,smoothed$V保存平滑方差估计,
这里是1×1×n数组。
实际上,
R的基本的stats包提供了StructTS()函数,
可以直接拟合包括局部水平模型的结构时间序列模型,
如:
sts.al <- StructTS(ts.alcoa, type="level")
sts.al##
## Call:
## StructTS(x = ts.alcoa, type = "level")
##
## Variances:
## level epsilon
## 0.005403 0.230652plot(ts.alcoa, ylim=c(-2, 4),
main="Alcoa smoothed with StructTS")
lines(tsSmooth(sts.al), col="green")
legend("topleft", lty=c(1,1),
col=c("black", "green"),
legend=c("Obs", "Smoothed"))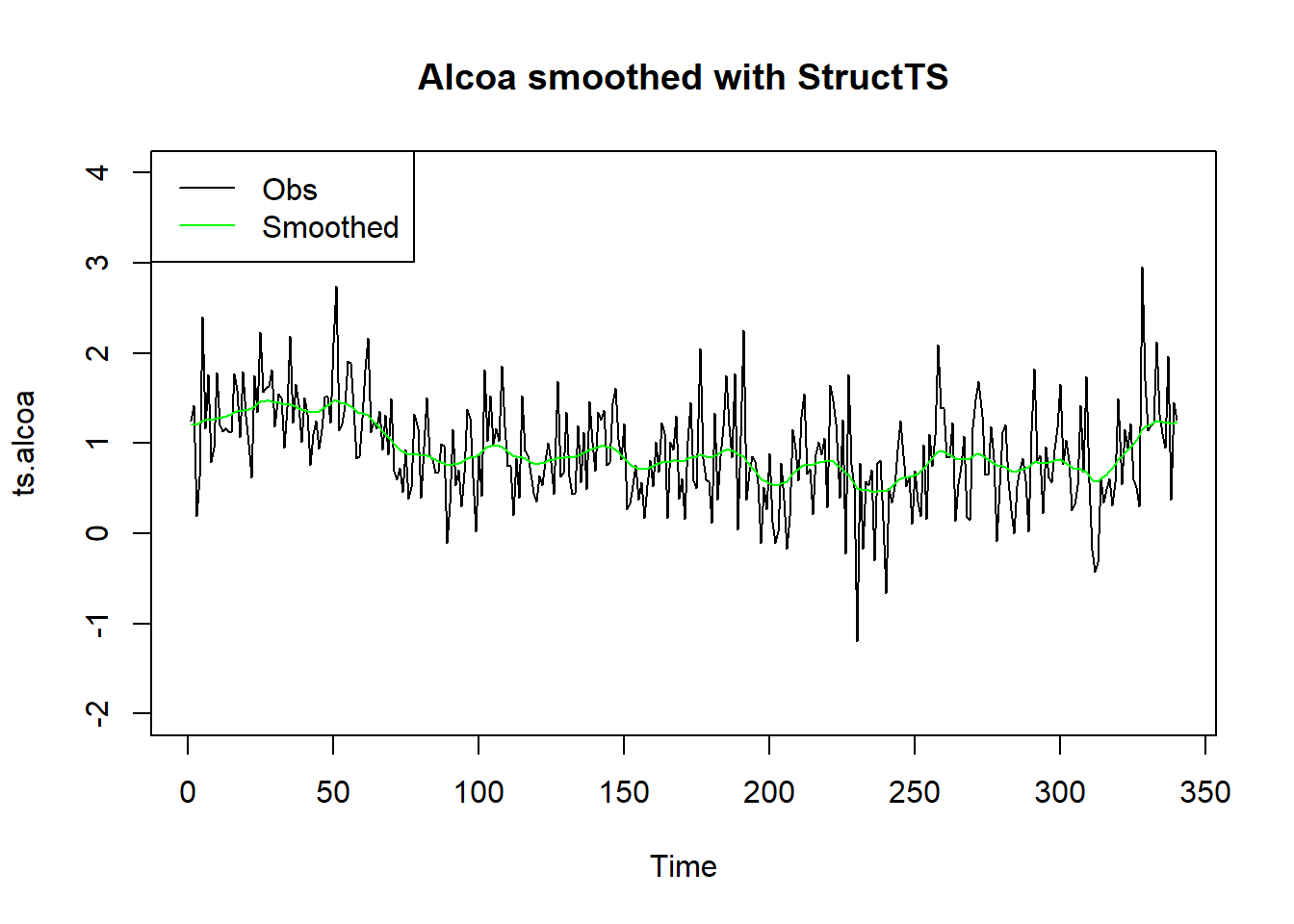
对StructTS()的结果,
用tsSmooth()可以提取平滑结果,
用fitted()可以提取滤波结果。
可以用predict()或者forecast::forecast()进行预报。
27.8 扰动的平滑
有了所有观测值{y1,y2,…,yn}以后,
不仅可以利用这些信息估计状态μt,
得到平滑状态和平滑方差,
还可以估计et和ηt的条件分布,
这个问题称为扰动的平滑。
估计et和ηt在Yn下的条件期望和条件方差,
可以用来进行模型诊断,
查找状态的突变点(对局部水平模型相当于水平的跳跃点或变点),
查找观测误差的异常值。
记
ê t=E(et|y1:n),η̂ t=E(ηt|y1:n), t=1,2,…,n.
因为et=yt−μt,
在y1:n条件下yt已知,
所以
et|y1:n∼N(yt−μt|n,Σt|n)=N(yt−μ̂ t,Vt).
对ηt,
易见
η̂ t=E(μt+1|y1:n)−E(μt|y1:n)=μt+1|n−μt|n=μ̂ t+1−μ̂ t,
但ηt|y1:n的条件方差公式需要用到平滑的协方差。
27.8.1 观测方程扰动的递推平滑公式
从计算效率出发,
为了获得et和ηt在y1:n下的条件分布,
直接从rt和Nt计算更简单。
关于et|y1:n的公式为
E(et|y1:n)=Var(et|y1:n)=σ2e(F−1tvt−Ktrt),σ2e−σ4e(1Ft+K2tNt),t=n,n−1,…,2,1.
证明:
由于Ft=Pt+σ2e,
Kt=PtFt,
Lt=1−Kt=σ2eFt,
有
E(et|y1:n)======E(yt−μt|y1:n)=yt−μt|nyt−at−Ptrt−1vt−Pt[vtFt+Ltrt](1−PtFt)vt−PtLtrtσ2eFtvt−Ptσ2eFtrtσ2e(vtFt−Ktrt).
记
ut=vtFt−Ktrt=σ−2eE(et|y1:n),
称ut为平滑误差(smoothing error)。
为了求Var(et|y1:n),
注意在联合正态分布下条件分布的方差是非随机的,
由公式Var(Y)=E[Var(Y|X)]+Var[E(Y|X)],
以及vt与rt独立,
Var(rt)=Nt,可得
Var(et|y1:n)==E[Var(et|y1:n)]=Var(et)−Var[E(et|y1:n)]σ2e−σ4e(1Ft+K2tNt).
27.8.2 状态方程扰动的递推平滑公式
对ηt|y1:n有
E(ηt|y1:n)=Var(ηt|y1:n)=σ2ηrt,σ2η−σ4ηNt, t=n,n−1,…,2,1.
rt与ηt|y1:n的关系也说明了rt和Nt的一个解释,
rt是平滑的状态扰动项的常数倍,
其无条件方差Nt是平滑的状态扰动方差的常数倍。
证明:
E(ηt|y1:n)=====E(μt+1−μt|y1:n)=μt+1|n−μt|nat+1+Pt+1rt−at−Ptrt−1(at+1−at)+(Ptσ2eFt+σ2η)rt−Pt(vtFt+σ2eFtrt)Ktvt+(Ktσ2e+σ2η)rt−Ktvt−σ2eKtrtσ2ηrt.
而
Var(ηt|y1:n)===E[Var(ηt|y1:n)]Var(ηt)−Var[E(ηt|y1:n)]σ2η−σ4ηNt.
27.9 缺失值处理和预测
一般的时间序列模型都很难处理出现在时间区间内部的缺失值。
状态空间模型的一大优势就是可以比较容易的允许观测有缺失值。
在局部水平模型中,
设{yt}ℓ+ht=ℓ+1缺失。
状态空间模型可以用多种方法解决缺失值问题,
这里使用不改变时间步数和模型形式的方法。
对t∈{ℓ+1,…,ℓ+h},
有
μt=μt−1+ηt−1=⋯=μℓ+1+∑j=ℓ+1t−1ηj,
这里约定求和下标下限大于下标上限时和为0。
于是
E(μt|Yt−1)=Var(μt|Yt−1)=E(μt|Yℓ)=aℓ+1,Var(μt|Yℓ)=Pℓ+1+(t−ℓ−1)σ2η,
于是有递推式
at=Pt=μt|t−1=μt−1|t−2=at−1,Σt|t−1=Pt−1+σ2η, t=ℓ+2,…,ℓ+h.(27.20)(27.21)
所以,局部水平模型有缺失值时仍可使用(27.11)进行滤波计算,
但是对缺失的yt,
应该相应地取vt=0, Kt=0。
这也符合常识,
因为观测缺失时就没有新息vt的信息,
也没有卡尔曼增益Kt。
实际上,
在已知y1,y2,…,yn后对yn+1,…,yn+h进行预测时,
最优线性无偏估计得到的预测公式,
与设yn+1,…,yn+h为缺失值,
令vn+1=⋯=vn+h=Kn+1=⋯=Kn+h=0后进行滤波计算的计算公式完全相同。
所以预测问题可以看成有缺失值时的滤波问题的特例。
这时
E(yn+j|y1:n)=Var(yn+j|y1:n)=E(μn+j|y1:n)=an+1,Var(μn+j|y1:n)+σ2e=Pn+(j−1)σ2η+σ2e.
27.10 初值分布参数选取
卡尔曼滤波计算需要假定已知μ1∼N(a1,P1)。
实际中a1和P1是未知的。
利用滤波公式得
v1=a2=→P2==→y1−a1,F1=P1+σ2e,a1+P1F1v1=a1+P1F1(y1−a1)y1(P1→∞),P1(1−P1P1+σ2e)+σ2ηP1P1+σ2eσ2e+σ2ησ2e+σ2η(P1→∞),
因此P1→∞时相当于认为y1是非随机的确定值,
而μ1∼N(y1,σ2e)。
这种初始化方法称为扩散(diffuse)初始化或者扩散先验。
扩散先验相当于对初始状态分布没有任何知识。
对于取扩散先验时的平滑问题,
t=n,n−1,…,2的反向递推仍完全原样进行。
对t=1,
利用L1=1−K1=F−11σ2e,
F1=P1+σ2e,得
μ̂ 1===→V1===→μ1|n=a1+P1r0a1+P1[1P1+σ2ev1+(1−P1P1+σ2e)r1]a1+P1P1+σ2e(v1+σ2er1)a1+v1+σ2er1=y1+σ2er1(P1→∞),Σ1|n=P1−P21[1P1+σ2e+(1−P1P1+σ2e)2N1]P1(1−P1P1+σ2e)−(1−P1P1+σ2e)2P1N1(P1P1+σ2e)σ2e−(P1P1+σ2e)2σ4eN1σ2e−σ4eN1(P1→∞).
另一种想法是将μ1也作为一个未知参数参与到最大似然估计中。
27.11 模型参数估计
滤波和平滑算法都是假定模型参数σ2e和σ2η已知的。
为了估计参数可以使用最大似然估计法,
计算似然函数时可以利用滤波算法进行计算。
(y1,y2,…,yn)的似然函数为
==py(y1,y2,…,yn|σ2e,σ2η)py(y1|σ2e,σ2η)∏t=2npy(yt|Yt−1,σ2e,σ2η)pv(v1|σ2e,σ2η)∏t=2Tpv(vt|σ2e,σ2η),
其中y1∼N(a1,P1),
vt∼N(0,Ft),
设a1,P1已知,
可得对数似然函数为
lnL(σ2e,σ2η)=−n2ln(2π)−12∑t=1n(lnFt+v2tFt).
给定初始值a1,P1以及一组参数值σ2e,σ2η
就可以用卡尔曼滤波算法计算出vt,Ft从而得到对数似然函数值。
具体计算可以用R的statespacer扩展包,
KFAS, bssm扩展包等,
还有许多其它软件也可以进行状态空间模型建模。
韭菜热线原创版权所有,发布者:风生水起,转载请注明出处:https://www.9crx.com/74894.html




