

这一部分介绍描述统计、估计、置信区间、假设检验和一些模型。
参考:
- McNicholas and Tait(2019) Data Science Using Julia, CRC Press.
- Jose Storopoli, Rik Huijzer, Lazaro Alonso(2022) Julia Data Science.
https://cn.julialang.org/JuliaDataScience/
using DataFrames, CSV, DataFramesMeta
using CategoricalArrays
using Statistics13.2 描述统计
13.2.1 描述统计函数来源
Julia标准库包含一个Statistics包,
包含了均值、中位数、分位数、标准差、方差、相关系数等函数。
在一个统计分析项目中,
统计学家对手头的数据往往只有大致的了解,
但是每个变量是什么类型、能取什么样的值,
是分类变量还是连续变量,
分布情况,
变量之间的关系如何,
观测有无明显的分组,
这些都需要了解。
这样的工作称为探索性数据分析(EDA)。
Julia的一些函数可以用来进行这样的分析。
设x是数值型向量,
或者用skipmissing()处理过的含有missing值的向量。
Base标准库、Statistics标准库和StatsBase包中的函数提供了一些简单概括函数,
如求和、平均、标准差等。
为了查看某个函数有哪些方法以及各个方法来自那些源文件,
可以调用methods()函数,如:
using Statistics, StatsBase
methods(mean)13.2.2 矩统计量
sum(x)求和,prod(x)求乘积。
mean(x)求均值,median(x)求中位数。StatsBases.mode(x)求众数。StatsBases.modes(x)求所有众数。
std(x)求标准差,var(x)求方差,StatsBase.variation(x)求变异系数,StatsBase.mad(x)求平均绝对偏差,StatsBase.iqr(x)返回四分位间距(或称四分位极差),
即四分之三分位数减去四分之一分位数。
StatsBase.skewness(x)计算偏度,StatsBase.kurtosis(x)计算超额峰度。
从源程序看,偏度计算公式为
skewness=1𝑛∑(𝑥𝑖−𝑥¯)3(1𝑛∑(𝑥𝑖−𝑥¯)2)3/2
峰度计算公式类似,是标准化的四阶矩减去3。
13.2.3 分位数和秩统计量
minimum(x)求最小值,maximum(x)求最大值。StatsBase.quantile(x)返回五数概括(最小值、四分之一分位数、中位数、
四分之三分位数、最大值),StatsBase.summarystats(x)返回均值和五数概括。Statistics.quantile(x, p)返回对应于概率p的分位数。StatsBase.quantilerank(x, v)返回数值v在样本x中所处的分位数位置,
在[0,1]之间取值。
如
5-element Vector{Float64}:
0.001956632911187417
0.248179329108444
0.4960556756040693
0.7362452742276865
0.9999817184061042quantile(rand(1000), [0.01, 0.99])2-element Array{Float64,1}:
0.007649440987338958
0.9893726990807745其中rand()函数用来生成标准均匀分布随机数向量。
有几个求秩得分的函数。ordinalrank()返回同名次时不同秩的结果(如1234),competerank()返回同名次时同秩的结果,
且后续名次不变(如1224),densrank()返回同名次时同秩的结果,
但后续名次不变(如1223),tiedrank()返回同名次时平均秩的结果(如1.0,2.5,2.5,4.0)。
加选项reverse=true可以按从大到小求名次。
StatsBase.zscore(x)返回x的Z分数。
StatsBase.ordinalrank([3,1,2,4,2]) |> show
## [4, 1, 2, 5, 3]StatsBase.competerank([3,1,2,4,2]) |> show
## [4, 1, 2, 5, 2]StatsBase.denserank([3,1,2,4,2]) |> show
## [3, 1, 2, 4, 2]StatsBase.tiedrank([3,1,2,4,2]) |> show
## [4.0, 1.0, 2.5, 5.0, 2.5]13.2.4 频数统计
对整数向量x,sort(unique(x))获得x的所有不同值,
而StatsBase.counts(x)获得这些从x最小值到x最大值的这些整数各自的出现次数,StatsBase.proportions(x)获得这些值的出现比例。
保险起见,用StatsBase.counts(x, levels)指定可取值范围进行计数,
其中levels需要是一个范围。
用StatsBase.counts(x, k)指定对1:𝑘计数。
对一般向量,
可以用count(xi -> xi == gk for xi in x)这样的写法获得值gk的计数。
如:
x = [1,3,4,1,3,1]
g = unique(x); show(g)
## [1, 3, 4]
[count(xi -> xi==gk, x) for gk in g] |> show
## [3, 2, 1]对一般向量x,
可以用StatsBase.countmap(x)函数获得不同值到对应计数的字典,StatsBase.propotionmap(x)获得不同值到对应的比例的字典。
如:
x = [1,3,4,1,3,1]
@show sort(unique(x));
## sort(unique(x)) = [1, 3, 4]
@show StatsBase.counts(x);
## StatsBase.counts(x) = [3, 0, 2, 1]
@show StatsBase.proportions(x);
## StatsBase.proportions(x) =
## [0.5, 0.0, 0.3333333333333333, 0.16666666666666666]
@show StatsBase.countmap(x);
## StatsBase.countmap(x) = Dict(4 => 1, 3 => 2, 1 => 3)StatsBase的Histogram类型可以用来保存直方图数据,
包括分组、频数、区间开闭,
用fit函数进行计数获得Histogram结果。
如:
StatsBase.fit(Histogram, [1, 2, 3, 2, 2, 3],
[0.5,1.5,2.5,3.5])Histogram{Int64, 1, Tuple{Vector{Float64}}}
edges:
[0.5, 1.5, 2.5, 3.5]
weights: [1, 3, 2]
closed: left
isdensity: false默认使用左闭右开区间,
可加选项closed=:right选择左开右闭区间。
支持用merge或merge!合并两个直方图数据。
可以用norm计算直方图的面积。
用normalize或normalize!标准化为密度等形式。
StatsBase.ecdf(x)计算经验分布函数,
注意返回结果是一个定义在实数轴上的函数。
13.2.5 相关系数
对向量x, y, cor(x,y)计算相关系数,StatsBase.corspearman(x, y)计算Spearman秩相关系数,StatsBase.corkendall(x, y)计算Kendall τ统计量。
StatsBase.autocor(x)计算看成时间序列的向量x的自相关函数列(ACF)。StatsBase.autocov(x)计算自协方差函数值。StatsBase.crosscor(x, y)计算互相关系数函数值,StatsBase.crosscov(x, y)计算互协方差函数值。StatsBase.pacf(x)计算偏相关系数函数值。
对矩阵𝑋,cov(X)计算样本协方差阵,cor(X)计算样本相关系数矩阵。
13.2.6 加权
StatsBase包定义了各种针对观测的加权,
可以计算加权统计量。
比如,counts可以使用counts(x, FrequencyWeights(nf))使得x的每个值代表nf中对应个数的值。
13.2.7 距离
StatsBase包定义了各种距离,
如L2dist(‖𝑥−𝑦‖2), sqL2dist((‖𝑥−𝑦‖22),L1dist(‖𝑥−𝑦‖1),Linfdist(‖𝑥−𝑦‖∞),meanad(mean(abs(x-y))),msd(mean(abs(x - y).^2)),rmsd(sqrt(msd(x, y))),
等等。
13.2.8 StatsBase中其它函数
rle()用来寻找连并计数。如:
rle([3,3,1,1,1,2,2])
## ([3, 1, 2], [2, 3, 2])结果表示依次连续的3有2个,1有3个,2有2个。
从中央的结果可以恢复原来的序列,如:
inverse_rle([3, 1, 2], [2, 3, 2]) |> show
## [3, 3, 1, 1, 1, 2, 2]这起到了R中rep函数的效果。
levelsmap(x)将x中每个不同值映射到一个唯一编号。如:
levelsmap([4,1,4,1,2]) |> show
## Dict(4 => 1, 2 => 3, 1 => 2)indexmap(x)则将每个不同值映射到它第一次出现的下标。如:
indexmap([4,1,4,1,2]) |> show
## Dict(4 => 1, 2 => 5, 1 => 2)indicatormat(x,k)将x中的每个值映射为一列单位向量,
1所在行数代表该值。如:
indicatormat([2,1,2,3], 3)3×4 Matrix{Bool}:
0 1 0 0
1 0 1 0
0 0 0 1pairwise(f, x, y)执行类似外积的操作,
对x和y的所有两两组合计算f的值。如:
pairwise(*, [2,3,5],[7,9])3×2 Matrix{Int64}:
14 18
21 27
35 45StatsBase和StatsAPI包定义了许多从回归模型提取信息的函数,
如aic等。
13.3 分布
Distributions包提供了各种分布,
分布的数字特征,
与分布有关的密度、分布函数、特征函数、矩母函数等,
以及各种分布的随机数发生器。
支持对分布进行估计,
还可以将分布进行组合或变换。
参见:
- https://juliastats.org/Distributions.jl/latest/
using Distributions, Random13.3.1 介绍
用Normal(), Cauchy()等函数定义某种分布。
如:
dn = Normal(0, 1)
## Normal{Float64}(μ=0.0, σ=1.0)则dn表示标准正态分布。也可以简写成Normal()。
对此分布,
可以抽样,
可以查询其数字特征:
mean(dn)
## 0.0
std(dn)
## 1.0quantile.(dn, [0.975, 0.995])2-element Vector{Float64}:
1.9599639845400576
2.5758293035489053用Normal(a, b)可以生成N(𝑎,𝑏2)分布。
支持的分布可以分为一元随机变量分布、多元随机变量分布和随机矩阵分布(如Wishart分布)。
又可以分为离散分布和连续型分布。
可以用fieldname求某种分布的参数组成,如:
fieldnames(Normal)
## (:μ, :σ)可以用parmas()求某个具体分布的参数:
可以用fit指定某种分布对样本进行拟合。如:
fit(Normal, [1,3,3,4,4,4,5,6])
## Normal{Float64}(μ=3.75, σ=1.3919410907075054)fit(Gamma, [1,3,3,4,4,4,5,6])
## Gamma{Float64}(α=5.058259967168249,
## θ=0.7413616588194757)13.3.2 与分布有关的函数
Distributions包不仅包含了密度函数、对数密度函数、分布函数、分位数函数、随机数函数等与分布有关的函数,
还可以输出每个参数分布的各种矩的理论值,
计算矩母函数和特征函数,
给定观测样本后计算参数的最大似然估计,
用共轭先验计算后验分布,对参数作最大后验密度估计等。
比R提供了更多的分布类型和更多的函数类型。
分布类型包括一元随机变量(Univariate)、随机向量(Multivariate)、随机矩阵(Matrixvariate),
又可分为离散型(Discrete)和连续型(Continuous)。
分布类型的大类名称包括:
- DiscreteUnivariateDistribution
- ContinuousUnivariateDistribution
- DiscreteMultivariateDistribution
- ContinuousMultivariateDistribution
- DiscreteMatrixDistribution
- ContinuousMatrixDistribution
Distributions包中定义了各种概率分布。
例如,Binomial(n, p)表示二项分布,Normal(μ, σ)表示正态分布分布,Multinomial(n, p)表示多项分布,Wishart(nu, S)表示Wishart分布。
可以从一元分布生成截断分布(truncated),
如Truncated(Normal(mu, sigma), l, u)。
用params(distribution)返回一个分布的参数,如
params(Binomial(10, 0.2))
## (10, 0.2)rand(distribution, n)生成n个指定分布的随机数,
对一元分布,结果是一维数组,
连续型分布的元素类型是Float64,
离散型分布的元素类型是Int。
对多元分布,
结果是矩阵,每列为一个抽样。
对随机矩阵分布,
结果是元素为矩阵的数组。
有一些函数用来返回分布的特征量,
对一元分布,有:
maximum()分布的定义域上界minimum()分布的定义域下界mean()期望值var()方差std()标准差,median()中位数modes()众数(可有多个)mode()第一个众数skewness()偏度kurtosis()峰度,正态为0entropy()分布的熵
用pdf(distribution, x)计算分布密度(概率质量)函数在x处的值,
如果x是数组,结果返回数组;
如果x是数组且函数写成pdf!(distribution, x),则结果保存在x中返回。logpdf()计算其密度函数的自然对数值。
用cdf(distribution, x)计算分布函数在x处的值,logcdf计算其对数值,ccdf计算1减分布函数值,logccdf计算其对数值。
用quantile(distribution, p)计算分位数函数在p处的值。
类似于pdf,这些函数一般支持加点格式的向量化,
输入x为向量时返回向量,
写成以叹号结尾的函数名时,
输入为向量则结果保存在输入向量的存储中返回。
可这样向量化的函数包括pdf, logpdf, cdf, logcdf, ccdf, logccdf, quantile, cquantile, invlogcdf, invlogccdf。
用mgf(distribution, t)计算矩母函数在t处的值,
用cf(distribution, t)计算特征函数在t处的值。
比如,计算N(10,22)的0.5和0.975分位数:
quantile.(Normal(10, 2), [0.5, 0.975]) |> show
## [10.0, 13.919927969080115]10 .+ 2 .* quantile.(Normal(), [0.5, 0.975]) |> show
## [10.0, 13.919927969080115]比如,对标准正态分布密度作曲线图:
using CairoMakie
CairoMakie.activate!()
let
x = -3:0.1:3
y = pdf.(Normal(), x)
lines(x, y)
end

用rand(distrbution)生成指定分布的一个抽样,
用rand(distrbution, n)生成指定分布的n个抽样,
用rand!(distribution, x)生成指定分布的多个抽样保存在数组x中返回。
用fit(distributionname, x)作参数估计,
一般都是最大似然估计,也可以用fit_mle()规定使用最大似然估计。
比如,
模拟生成N(10,22)样本,然后做参数估计:
Random.seed!(101); x=rand(Normal(10, 2), 30)
fit(Normal, x)
## Normal{Float64}(μ=9.903033995978664,
## σ=2.237003990130135)fit_mle(Normal, x)
## Normal{Float64}(μ=9.903033995978664,
## σ=2.237003990130135)13.3.3 支持的分布
这里列举出Julia的Distributions包支持的分布。
13.3.3.1 连续型一元分布
Arcsine(a,b)Beta(α,β)BetaPrime(α,β)Biweight(μ, σ)Chi(ν)Chisq(ν)Cosine(μ, σ)Epanechnikov(μ, σ)Erlang(α,θ)Exponential(θ)FDist(ν1, ν2)Frechet(α,θ)Gamma(α,θ)GeneralizedExtremeValue(μ, σ, ξ)GeneralizedPareto(μ, σ, ξ)Gumbel(μ, θ)InverseGamma(α, θ)InverseGaussian(μ,λ)Kolmogorov()KSDist(n)KSOneSided(n)Laplace(μ,θ)Levy(μ, σ)Logistic(μ,θ)LogNormal(μ,σ)NoncentralBeta(α, β, λ)NoncentralChisq(ν, λ)NoncentralF(ν1, ν2, λ)NoncentralT(ν, λ)Normal(μ,σ)NormalCanon(η, λ)NormalInverseGaussian(μ,α,β,δ)Pareto(α,θ)Rayleigh(σ)SymTriangularDist(μ,σ)TDist(ν)TriangularDist(a,b,c)Triweight(μ, σ)Uniform(a,b)VonMises(μ, κ)Weibull(α,θ)
13.3.3.3 截断分布
设distribution为一个一元分布,
用
truncated(distribution; lower=l, upper=u)可以返回一个截断分布,其中l为下界,u为上界。
可以仅输入lower,表示左截断,
或仅输入upper,表示右截断。
特别地,TruncatedNormal(mu, sigma, l, u)表示截断正态分布。
截断分布仍支持密度、分布函数、分位数函数等,
但一般不支持均值等统计量,
因为没有一般的计算方法。
13.3.3.4 删失分布
一个随机变量𝑋如果在𝑏右删失,
就是当𝑋>𝑏时不能记录𝑋的具体值,
仅知道𝑋>𝑏。
左删失类似。
也可以是左右都删失。
如果𝑋是连续分布,
则删失分布是对应的截断分布与删失界限处的离散分布的混合分布。
区间删失是仅知道𝑋属于某个区间而不知道具体值,
这里没有支持这种类型。
用
censored(distribution; lower=l, upper=u)定义删失分布。
13.3.4 混合分布
通过MixtureModel()函数构造。
如:
let
d = MixtureModel(Normal[
Normal(0, 0.3), Normal(1, 0.1)],
[0.7, 0.3])
x = -2:0.01:2
y = pdf.(d, x)
m = mean(d)
s = std(d)
lines(x, y, axis=(; title="mean: $(m) std: $(s)"))
end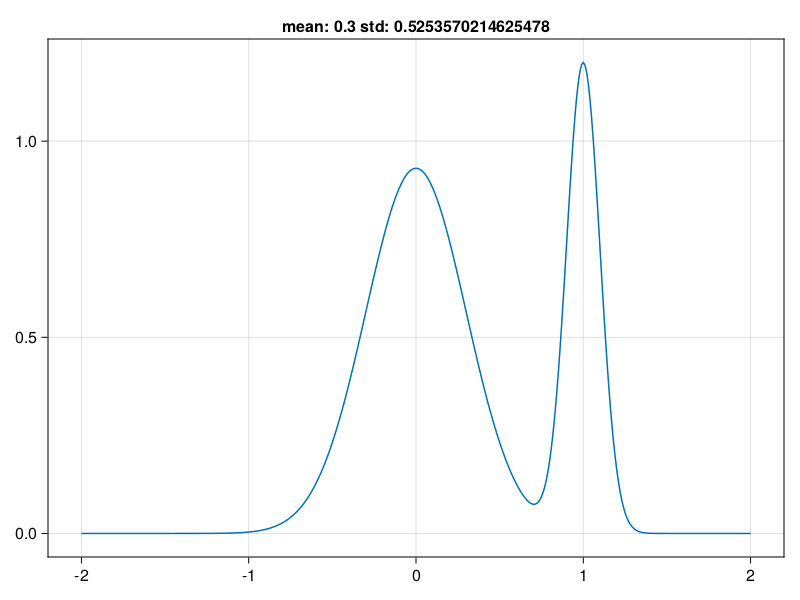
混合模型估计需要单独的程序,
比如GaussianMixtures包。
13.3.5 分布卷积
两个独立随机变量之和的分布密度是原分布密度的卷积。
Distributions包对若干和的分布已知的基础分布定义了convolve(d1, d2)函数。
如正态分布、二项分布、几何分布、泊松分布、指数分布、伽马分布等。
13.3.6 分布拟合
fit(D, x)对分布类型D和输入样本x拟合分布D的参数估计。
一般采用最大似然估计方法。
也可以用fit_mle(D, x)要求使用最大似然估计。
也支持最大后验估计。
13.4 置信区间和假设检验
HypothesisTests包提供了基本的置信区间和假设检验计算。
13.4.1 单正态总体方差已知时均值的Z检验
OneSampleZTest()函数执行此检验。
例13.1 设有50个生产出的高尔夫球样品,
想检验平均飞行距离是否等于295码。
设总体标准差已知,𝜎=12,
质量检验时飞行距离服从正态分布。
取检验水平𝛼=0.05。
数据为:
x = [303, 282, 289, 298, 283,
317, 297, 308, 317, 293,
284, 290, 304, 290, 311,
305, 277, 278, 301, 304,
300, 293, 300, 276, 318,
303, 309, 293, 316, 302,
295, 294, 291, 297, 300,
299, 303, 299, 282, 318,
296, 285, 288, 279, 310,
315, 292, 303, 301, 292]获得检验结果:
using HypothesisTests, Statistics
tres11 = OneSampleZTest(
mean(x), # 样本均值
12.0, # 已知的标准差
length(x), # 样本量
295.0) # 要比较的mu0One sample z-test
-----------------
Population details:
parameter of interest: Mean
value under h_0: 295.0
point estimate: 297.6
95% confidence interval: (294.3, 300.9)
Test summary:
outcome with 95% confidence: fail to reject h_0
two-sided p-value: 0.1255
Details:
number of observations: 50
z-statistic: 1.5320646925708663
population standard error: 1.697056274847714结果中已经显示了𝜇的95%置信区间为(294.3,300.9),
检验的双侧p值为0.1255。
可以用confint()函数从以上检验结果中抽取置信区间,
置信区间不依赖于检验所用的𝜇0:
confint(tres11)
## (294.2738308215608, 300.92616917843924)可以用pvalue()函数从检验结果中提取p值,如
pvalue(tres11)
## 0.12550647143746582在pvalue()函数中可以用tail = :left指定左侧检验,
用tail = :right指定右侧检验。如
pvalue(tres11, tail = :right)
## 0.06275323571873291如果总体分布未知,
样本量很大,
也可以使用Z检验,
这时只要使用OneSampleZTest(x, mu0)即可,
不需要已知总体方差。
13.4.2 单正态总体均值的t检验
用OneSampleTTest()函数执行此检验。
例13.2 对前面的高尔夫球数据,
若方差未知,
进行同样的均值检验。
tres12 = OneSampleTTest(x, 295.0)One sample t-test
-----------------
Population details:
parameter of interest: Mean
value under h_0: 295.0
point estimate: 297.6
95% confidence interval: (294.4, 300.8)
Test summary:
outcome with 95% confidence: fail to reject h_0
two-sided p-value: 0.1101
Details:
number of observations: 50
t-statistic: 1.6273368231294536
degrees of freedom: 49
empirical standard error: 1.5977024320018072仍可使用confint()提取置信区间,
用pvalue()提取p值。
13.4.4 独立两组均值比较
假设方差未知但是相等时,
用EqualVarianceTTest函数。
例13.3 设有两个银行营业所,
分别随机抽查了若干个存款账户余额,
比较这两个银行营业所存款账户余额平均值有无显著差异。
数据为:
# 两样本均值比较和置信区间
x = [1263, 897, 849, 891, 964,
810, 877, 899, 847, 1070,
1252, 920, 1256, 1196, 1150,
1024, 1016, 1126, 1289, 1220,
912, 1026, 786, 989, 1133,
990, 999, 1049]
y = [996.7, 897, 912, 894.9, 785,
750.7, 882.2, 1110, 907.2, 1226.1,
762.1, 835.5, 1048, 773.8, 807,
972, 980, 876.6, 943, 992.7,
704.3, 962.9]进行检验:
tres31 = EqualVarianceTTest(x, y)Two sample t-test (equal variance)
----------------------------------
Population details:
parameter of interest: Mean difference
value under h_0: 0
point estimate: 115.014
95% confidence interval: (35.04, 195.0)
Test summary:
outcome with 95% confidence: reject h_0
two-sided p-value: 0.0057
Details:
number of observations: [28,22]
t-statistic: 2.891462996309788
degrees of freedom: 48
empirical standard error: 39.77696982822245仍可用confint提取𝑥¯−𝑦¯的置信区间,
用pvalue()提取检验p值。
假设方差未知也不一定相等时,
使用Satterthwaite近似两样本t检验法,
Julia函数为UnequalVarianceTTest。
比如,
上面的例子若不一定方差相等,
可检验为:
tres32 = UnequalVarianceTTest(x, y)Two sample t-test (unequal variance)
------------------------------------
Population details:
parameter of interest: Mean difference
value under h_0: 0
point estimate: 115.014
95% confidence interval: (36.78, 193.3)
Test summary:
outcome with 95% confidence: reject h_0
two-sided p-value: 0.0048
Details:
number of observations: [28,22]
t-statistic: 2.956018810804808
degrees of freedom: 47.805020632402844
empirical standard error: 38.9082897386307313.5 与R软件交互
Julia语言的历史较短,
统计和机器学习方面的功能还不完整,
而R语言则有很长的历史,
统计学者在发表算法时最常用的是R语言,
所以从Julia中调用R软件的功能是很有用的。
13.5.1 从Julia中访问R数据框
Julia语言的第三方库RDatasets提供了基本R和一些扩展包中的例子数据框,
现在有超过700个。
用RDatasets.packages()可以返回支持的R扩展包的数据框,
用RDatasets.datasets()函数可以返回能提供的R的数据框的信息的数据框,
如:
using DataFrames, RDatasets
rds = RDatasets.datasets()
size(rds)
## (733, 5)
first(rds, 3)用RDatasets.dataset()函数指定某个R包和数据框名就可以用Julia数据框格式返回该数据。
如:
rds[occursin.("crab", rds[:,:Dataset]), :]
crabs = RDatasets.dataset("MASS", "crabs")
size(crabs)
## (200, 8)
first(crab, 3)Julia的第三方库RData可以直接读入R特有的.RData和.rda文件,
其中保存的变量一般是数据框,也支持R向量转换为Julia向量,R因子转换为Julia的类别数组。RData.load()载入一个文件并转换为Julia词典对象,
词典条目为变量名和相应的对象,
加convert=TRUE选项可以转换为Julia对象。
如:
using DataFrames, RData
fi = RData.load("D:\\disk\\course\\fints\\ftsnotes\\GOOG.RData")
keys(fi)
## "GOOG"
d1 = fi["GOOG"]
size(d1)
## (2784, 6)
typeof(d1)
## Matrix{Float64}
d1[1:5,:]13.5.2 从Julia中调用R程序
Julia的第三方库RCall提供了调用R的功能。
从文档看,
这些功能还远远不够友好,
一般用户还是分别使用两个软件更好。
在安装RCall时,
可以查找已安装的R软件,
比如在Windows系统中会查找系统注册表;
如果找不到或R版本更新时,
可以设置ENV["R_HOME"]="R可执行文件路径",
然后重建RCall包。
用using RCall在后台打开一个R会话。
可以在Julia命令行启动一个R命令行,
只要用$命令;
用退格键退出R命令行。
在这个R命令行可以用$替换格式访问Julia中的变量。
如:
julia> using RCall
julia> xjulia = 5
julia> $
R> y <- 1:$xjulia; print(y)
## [1] 1 2 3 4 5可以用@rput宏将Julia变量传递给R变量,
用@rget宏将R变量传回Julia变量。
如:
xjulia = 5
@rput xjulia
R"ya <- 1:xjulia"
@rget ya; show(ya)
## [1, 2, 3, 4, 5]可以用R"expr"这种格式执行简短的R代码,
如R"rnorm(5)"。
代码中可以用$替换格式访问Julia变量,
如:
x = rand(5)
R"t.test($x)"RObject{VecSxp}
One Sample t-test
data: `#JL`$x
t = 2.5274, df = 4, p-value = 0.06484
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
-0.03777735 0.80460594
sample estimates:
mean of x
0.3834143reval()函数将输入字符串作为R对象解析。
用rcall()函数构造对R的函数的调用。
用rcopy()函数将R结果转换为Julia对象。
用robject()函数将Julia对象转换为R对象。
13.6 线性回归
设class19.csv中有如下内容:
name,sex,age,height,weight
Sandy,F,11,130,23
Karen,F,12,143,35
Kathy,F,12,152,38
Alice,F,13,144,38
Becka,F,13,166,44
Tammy,F,14,160,46
Gail,F,14,163,41
Sharon,F,15,159,51
Mary,F,15,169,51
Thomas,M,11,146,39
James,M,12,146,38
John,M,12,150,45
Robert,M,12,165,58
Jeffrey,M,13,159,38
Duke,M,14,161,46
Alfred,M,14,175,51
William,M,15,169,51
Guido,M,15,170,60
Philip,M,16,183,68读入为数据框,并将sex转换为分类变量:
using CSV, DataFrames, CategoricalArrays
d_class = CSV.read("class19.csv", DataFrame,
types=Dict(
"name" => String,
"sex" => String,
"height" => Float64,
"weight" => Float64))
d_class[:, :sex] = categorical(d_class[:, :sex]);作体重对身高的线性回归:
lmr = lm(@formula(weight ~ height), d_class)StatsModels.TableRegressionModel{LinearModel{GLM.LmResp{Vector{Float64}},
GLM.DensePredChol{Float64, LinearAlgebra.CholeskyPivoted{Float64,
Matrix{Float64}}}}, Matrix{Float64}}
weight ~ 1 + height
Coefficients:
────────────────────────────────────────────────────────────────────────────
Coef. Std. Error t Pr(>|t|) Lower 95% Upper 95%
────────────────────────────────────────────────────────────────────────────
(Intercept) -64.8308 14.4779 -4.48 0.0003 -95.3766 -34.285
height 0.695278 0.0910989 7.63 <1e-06 0.503076 0.887479
────────────────────────────────────────────────────────────────────────────线性回归结果显示了系数估计、系数估计的标准误差,
检验系数等于0的t统计量和p值,
系数的95%置信度的置信区间。
考虑性别差异,
取不同性别用不同截距项,
但身高斜率项相同的模型,
称为平行线模型:
lmr2 = lm(@formula(weight ~ sex + height), d_class)StatsModels.TableRegressionModel{LinearModel{GLM.LmResp{Vector{Float64}},
GLM.DensePredChol{Float64, LinearAlgebra.CholeskyPivoted{Float64,
Matrix{Float64}}}}, Matrix{Float64}}
weight ~ 1 + sex + height
Coefficients:
────────────────────────────────────────────────────────────────────────────
Coef. Std. Error t Pr(>|t|) Lower 95% Upper 95%
────────────────────────────────────────────────────────────────────────────
(Intercept) -60.0011 14.6657 -4.09 0.0009 -91.0911 -28.9111
sex: M 3.12519 2.39842 1.30 0.2110 -1.95924 8.20962
height 0.654409 0.0946336 6.92 <1e-05 0.453794 0.855023
────────────────────────────────────────────────────────────────────────────上面的结果中截距项是女生组的截距,
而男生组的截距项是(Intercept)的值加sex: M的值。
可以用如下方法直接得到两组的截距项:
lmr2b = lm(@formula(weight ~ -1 + sex + height), d_class)StatsModels.TableRegressionModel{LinearModel{GLM.LmResp{Vector{Float64}},
GLM.DensePredChol{Float64, LinearAlgebra.CholeskyPivoted{Float64,
Matrix{Float64}}}}, Matrix{Float64}}
weight ~ 0 + sex + height
Coefficients:
───────────────────────────────────────────────────────────────────────
Coef. Std. Error t Pr(>|t|) Lower 95% Upper 95%
───────────────────────────────────────────────────────────────────────
sex: F -60.0011 14.6657 -4.09 0.0009 -91.0911 -28.9111
sex: M -56.8759 15.4472 -3.68 0.0020 -89.6226 -24.1293
height 0.654409 0.0946336 6.92 <1e-05 0.453794 0.855023
───────────────────────────────────────────────────────────────────────韭菜热线原创版权所有,发布者:风生水起,转载请注明出处:https://www.9crx.com/75685.html




