

32 R相关与回归
本章所用例子数据下载:
32.1 相关分析
考虑连续型随机变量之间的关系。相关系数定义为
ρ(X,Y)=E[(X−EX)(Y−EY)]Var(X)Var(Y)‾‾‾‾‾‾‾‾‾‾‾‾‾√
又称Pearson相关系数。
−1≤ρ≤1。ρ接近于+1表示X和Y有正向的相关; ρ接近于−1表示X和Y有负向的相关。
相关系数代表的是线性相关性, 对于X和Y的其它相关可能反映不出来, 比如X∼N(0,1),Y=X2, 有ρ(X,Y)=0。
给定样本(Xi,Yi),i=1,2,…,n,样本相关系数为
r=∑ni=1(Xi−X¯)(Yi−Y¯)∑ni=1(Xi−X¯)2∑ni=1(Yi−Y¯)2‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√
用散点图和散点图矩阵直观地查看变量间的相关。
例如,线性相关的模拟数据的散点图:
set.seed(1)
nsamp <- 30
x <- runif(nsamp, -10, 10)
y <- 20 + 0.5*x + rnorm(nsamp,0,0.5)
plot(x, y)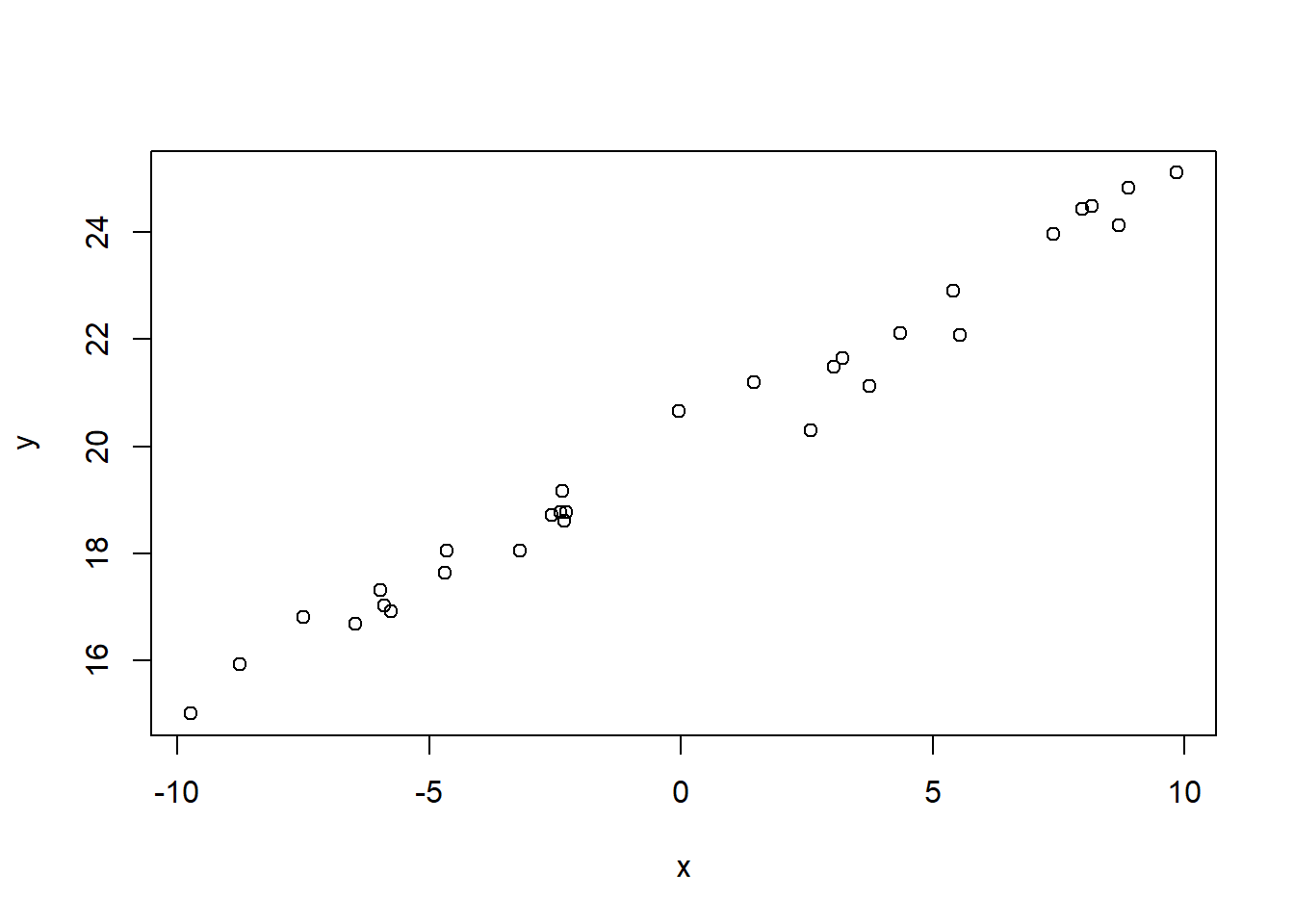

图32.1: 线性相关数据
二次曲线相关的模拟数据散点图:
set.seed(1)
y2 <- 0.5*x^2 + rnorm(nsamp,0,2)
plot(x, y2)
图32.2: 二次曲线相关数据
指数关系的例子:
set.seed(1)
y3 <- exp(0.2*(x+10)) + rnorm(nsamp,0,2)
plot(x, y3)
图32.3: 指数关系相关数据
对数关系的例子:
set.seed(1)
y4 <- log(10*(x+12)) + rnorm(nsamp,0,0.1)
plot(x, y4)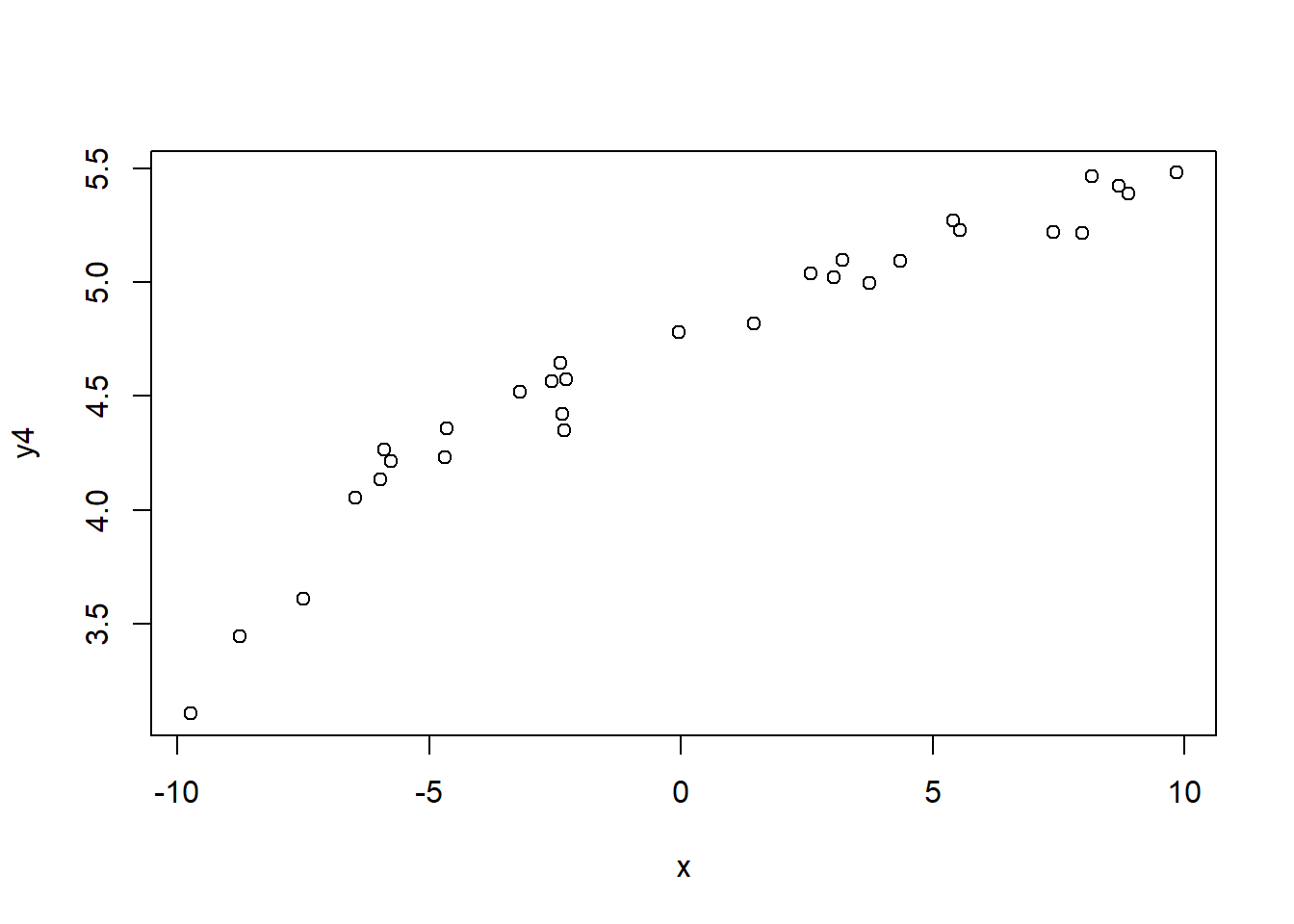
图32.4: 对数关系相关数据
32.1.1 相关系数的性质
- 取值−1≤r≤1。
- r>0表示正线性相关; r<0表示负线性相关。
- 当r=1时(xi,yi),i=1,…,n这n个点完全在一条正斜率的直线上, 属于确定性关系。
- 当r=−1时(xi,yi),i=1,…,n这n个点完全在一条负斜率的直线上, 属于确定性关系。
- 计算相关系数时与x,y的次序或记号无关。
- 如果对变量x或者y分别乘以倍数,再分别加上不同的平移量, 相关系数不变。 即:a+bx与c+dy的相关系数, 等于x,y的相关系数。 这样,相关系数不受单位、量纲的影响。 相关系数是无量纲的。
- 如果x和y之间是非线性相关, 相关系数不一定能准确反映其关系, 只能作为一定程度的近似。
设变量X和Y的样本存放于R向量x和y中, 用cor(x,y)计算样本相关系数。
set.seed(1)
x <- runif(30, 0, 10)
xx <- seq(0, 10, length.out = 100)
y <- 40 - (x-7)^2 + rnorm(30)
yy <- 40 - (xx-7)^2
plot(x, y, pch=16)
lines(xx, yy)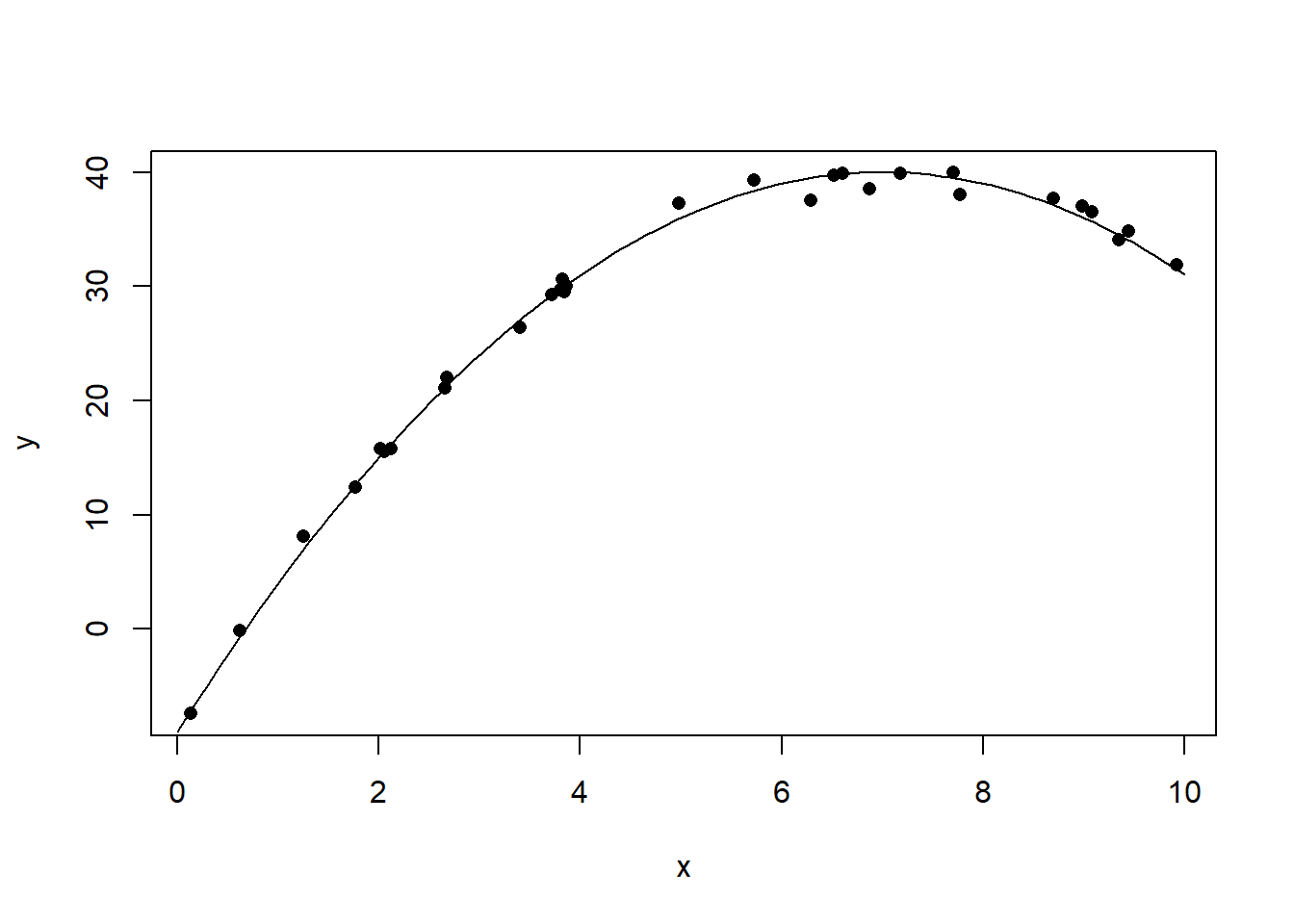
图32.5: 曲线相关数据的相关系数例1
cor(x, y)## [1] 0.8244374x <- runif(30, 0, 10)
xx <- seq(0, 10, length.out = 100)
y <- 40 - (x-5)^2 + rnorm(30)
yy <- 40 - (xx-5)^2
plot(x, y, pch=16)
lines(xx, yy)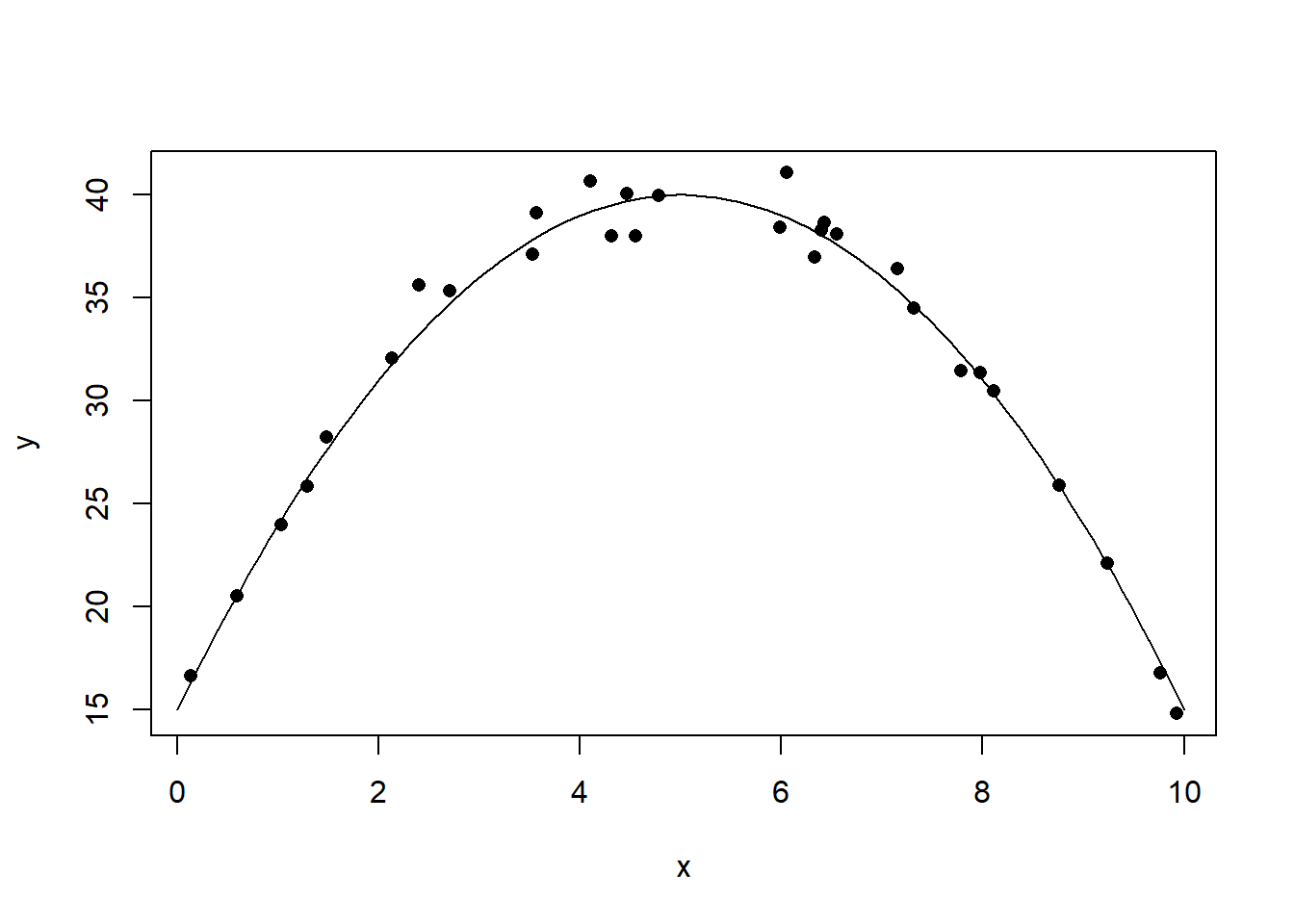
图32.6: 曲线相关数据的相关系数例2
cor(x, y)## [1] -0.042684x <- runif(30, 0, 10)
xx <- seq(0, 10, length.out = 100)
y <- 40*exp(-x/2) + rnorm(30)
yy <- 40*exp(-xx/2)
plot(x, y, pch=16)
lines(xx, yy)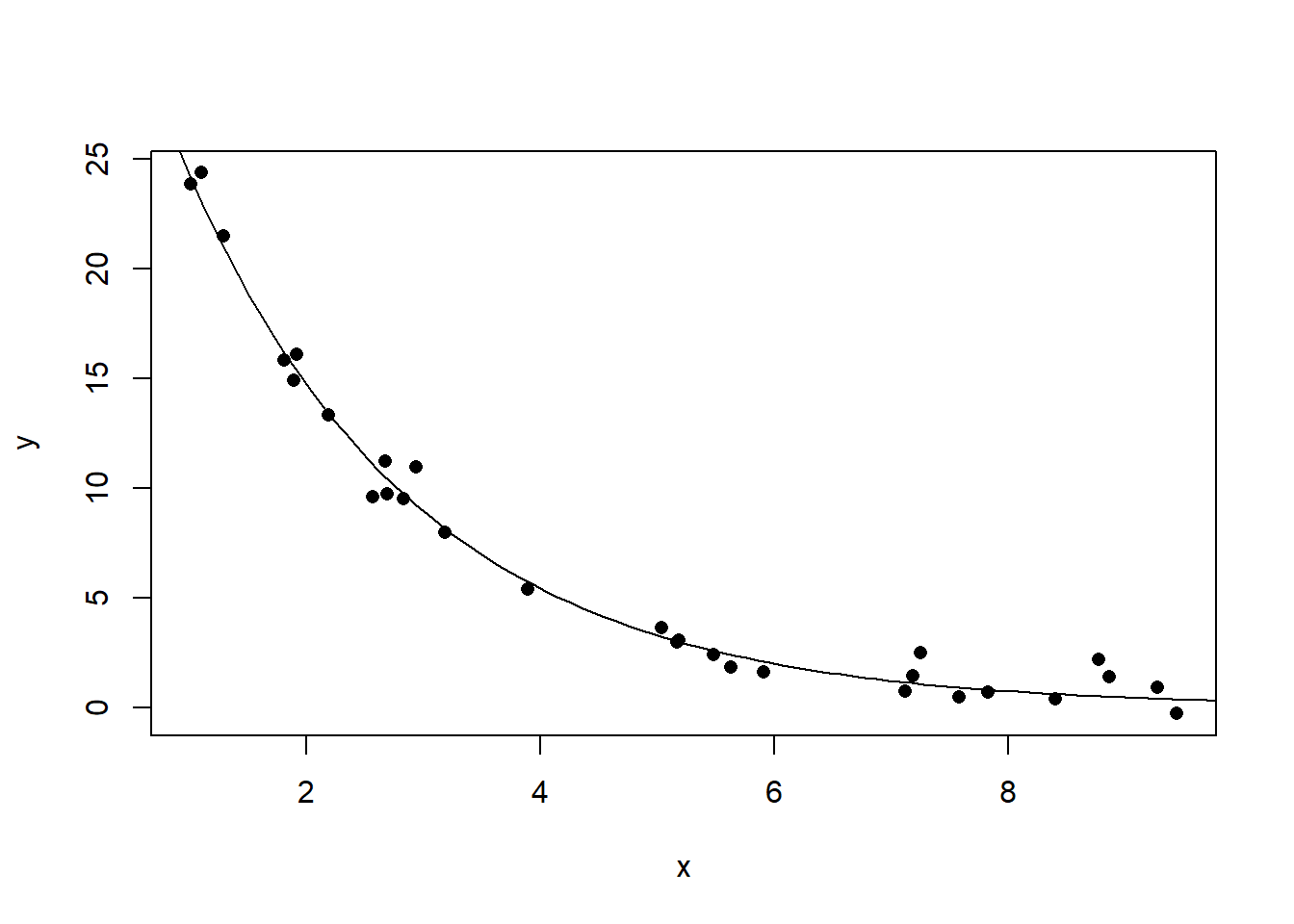
图32.7: 曲线相关数据的相关系数例3
cor(x, y)## [1] -0.884111732.1.2 相关与因果
相关系数是从数据中得到的x和y两个变量关系的一种描述, 不能直接引申为因果关系。
例如,增加身高,不一定增长体重。
实际中有许多错误理解相关与因果性的例子。 例如:研究发现喝咖啡的人群比不喝咖啡的人群心脏病发病率高。 于是断言喝咖啡导致心脏病危险增加。 进一步研究更多的因素发现, 喝咖啡放糖很多的人心脏病发病率才增高了。
32.1.3 相关系数大小
- 相关系数绝对值在0.8以上认为高度相关。
- 在0.5到0.8之间认为中度相关。
- 在0.3到0.5之间认为低度相关。
- 在0.3以下认为不相关或相关性很弱以至于没有实际价值。
- 当然,在特别重要的问题中, 只要经过检验显著不等于零的相关都认为是有意义的。
32.1.4 相关系数的检验
相关系数r是总体相关系数ρ的估计。
H0:ρ=0⟷Ha:ρ≠0
检验统计量
t=rn−2‾‾‾‾‾√1−r2‾‾‾‾‾‾√当总体(X,Y)服从二元正态分布且H0:ρ=0成立时, t服从t(n−2)分布。 设t统计量值为t0,p值为
P(|t(n−2)|>|t0|)
在R中用cor.test(x,y)计算检验。
例如:
cor.test(d.class$height, d.class$weight)##
## Pearson's product-moment correlation
##
## data: d.class$height and d.class$weight
## t = 7.5549, df = 17, p-value = 7.887e-07
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.7044314 0.9523101
## sample estimates:
## cor
## 0.8777852得身高与体重的相关系数为0.88,检验的p值为7.887e-07, 95%置信区间为[0.70,0.95]。
可以用ggstatsplot包将相关系数检验进行图示:
library(ggstatsplot)## You can cite this package as:
## Patil, I. (2021). Visualizations with statistical details: The 'ggstatsplot' approach.
## Journal of Open Source Software, 6(61), 3167, doi:10.21105/joss.03167ggscatterstats(
data = d.class,
x = height,
y = weight,
xlab = "身高",
ylab = "体重",
title = "体重与身高的相关性"
)## Registered S3 method overwritten by 'ggside':
## method from
## +.gg ggplot2## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.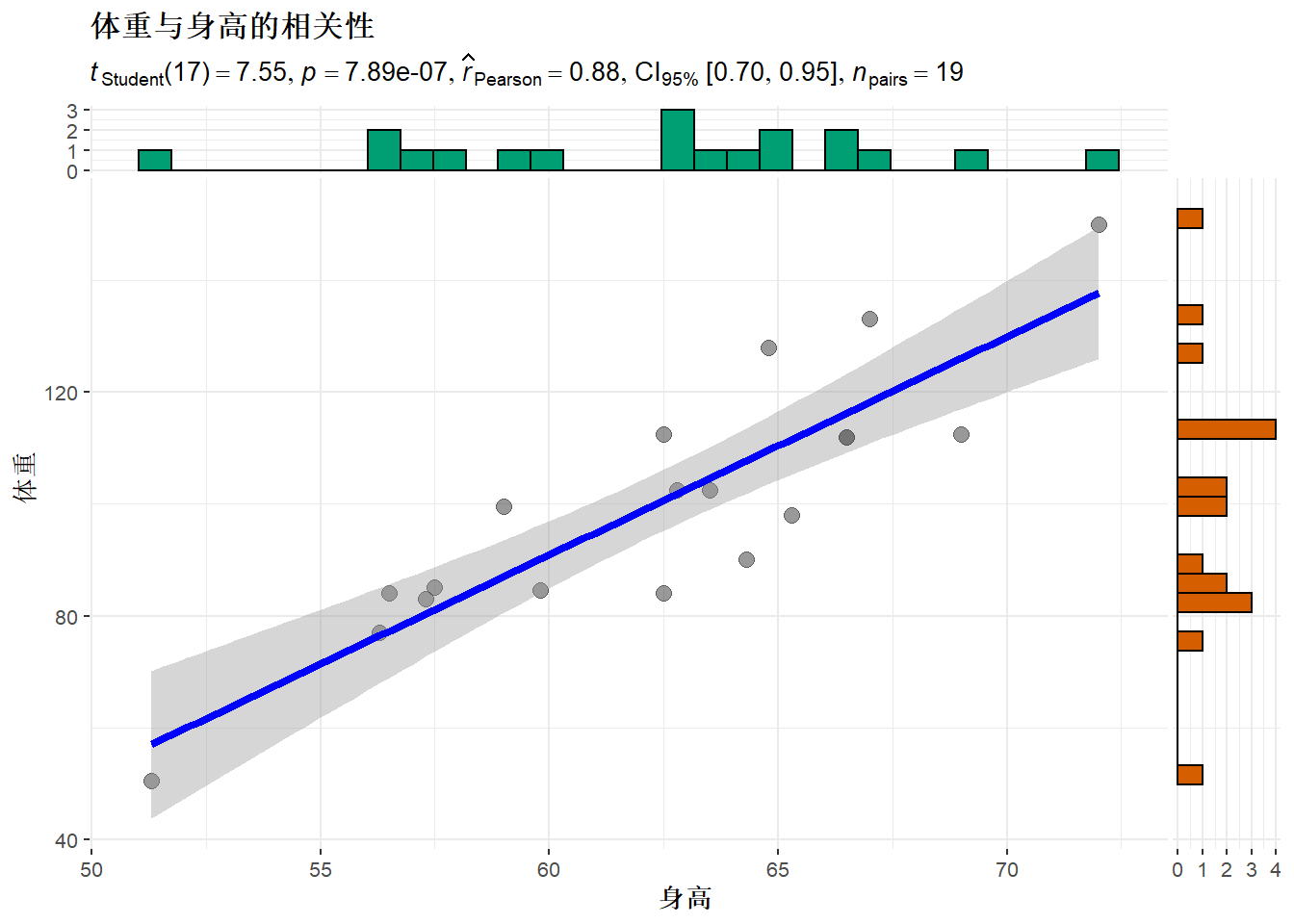
再例如:
set.seed(1)
nsamp <- 30
x <- runif(nsamp, -10, 10)
y <- 0.5*x^2 + rnorm(nsamp,0,2)
cor.test(x, y)##
## Pearson's product-moment correlation
##
## data: x and y
## t = 0.93076, df = 28, p-value = 0.3599
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## -0.1994815 0.5021658
## sample estimates:
## cor
## 0.1732378得x与y的样本相关系数为0.17, p值为0.36,不显著。
32.1.4.1 相关系数检验的功效和样本量
pwr包的pwr.r.test()可以计算相关系数检验的功效和样本量。 用相关系数绝对值作为效应大小, 常用值为:
- 小:0.1;
- 中: 0.3;
- 大: 0.5。
比如,样本量为30, 检验“大”的效应, 计算其功效:
library(pwr)## Warning: package 'pwr' was built under R version 4.2.2cohen.ES(test = "r", size = "large")##
## Conventional effect size from Cohen (1982)
##
## test = r
## size = large
## effect.size = 0.5pwr.r.test(
r = 0.5,
n = 30,
alternative = "two.sided"
)##
## approximate correlation power calculation (arctangh transformation)
##
## n = 30
## r = 0.5
## sig.level = 0.05
## power = 0.8250298
## alternative = two.sided功效为83%。
检验“小”的效应, 功效为80%, 需要的样本量:
cohen.ES(test = "r", size = "small")##
## Conventional effect size from Cohen (1982)
##
## test = r
## size = small
## effect.size = 0.1pwr.r.test(
r = 0.1,
power = 0.80,
alternative = "two.sided"
)##
## approximate correlation power calculation (arctangh transformation)
##
## n = 781.7516
## r = 0.1
## sig.level = 0.05
## power = 0.8
## alternative = two.sided需要的样本量为782。
32.1.5 相关阵
如果x是一个仅包含数值型列的数据框, 则cor(x)计算样本相关系数矩阵; var(x)计算样本协方差阵。
corrgram::corrgram()可以绘制相关系数矩阵的图形, 用颜色和阴影浓度代表相关系数正负和绝对值大小, 用饼图中阴影部分大小代表相关系数绝对值大小。 如:
library(corrgram)
corrgram(
baseball[,c("Assists","Atbat","Errors","Hits","Homer","logSal",
"Putouts","RBI","Runs","Walks","Years")],
order=TRUE, main="Baseball data PC2/PC1 order",
lower.panel=panel.shade, upper.panel=panel.pie)
图32.8: 相关阵图形
其中选项order=TRUE重排各列的次序使得较接近的列排列在相邻位置。
ggcorrplot包也提供了类似的功能:
library(ggcorrplot)
baseball |>
select(all_of(c(
"Assists","Atbat","Errors","Hits","Homer","logSal",
"Putouts","RBI","Runs","Walks","Years"))) |>
cor(use="pairwise.complete.obs") |>
ggcorrplot(hc.order=TRUE)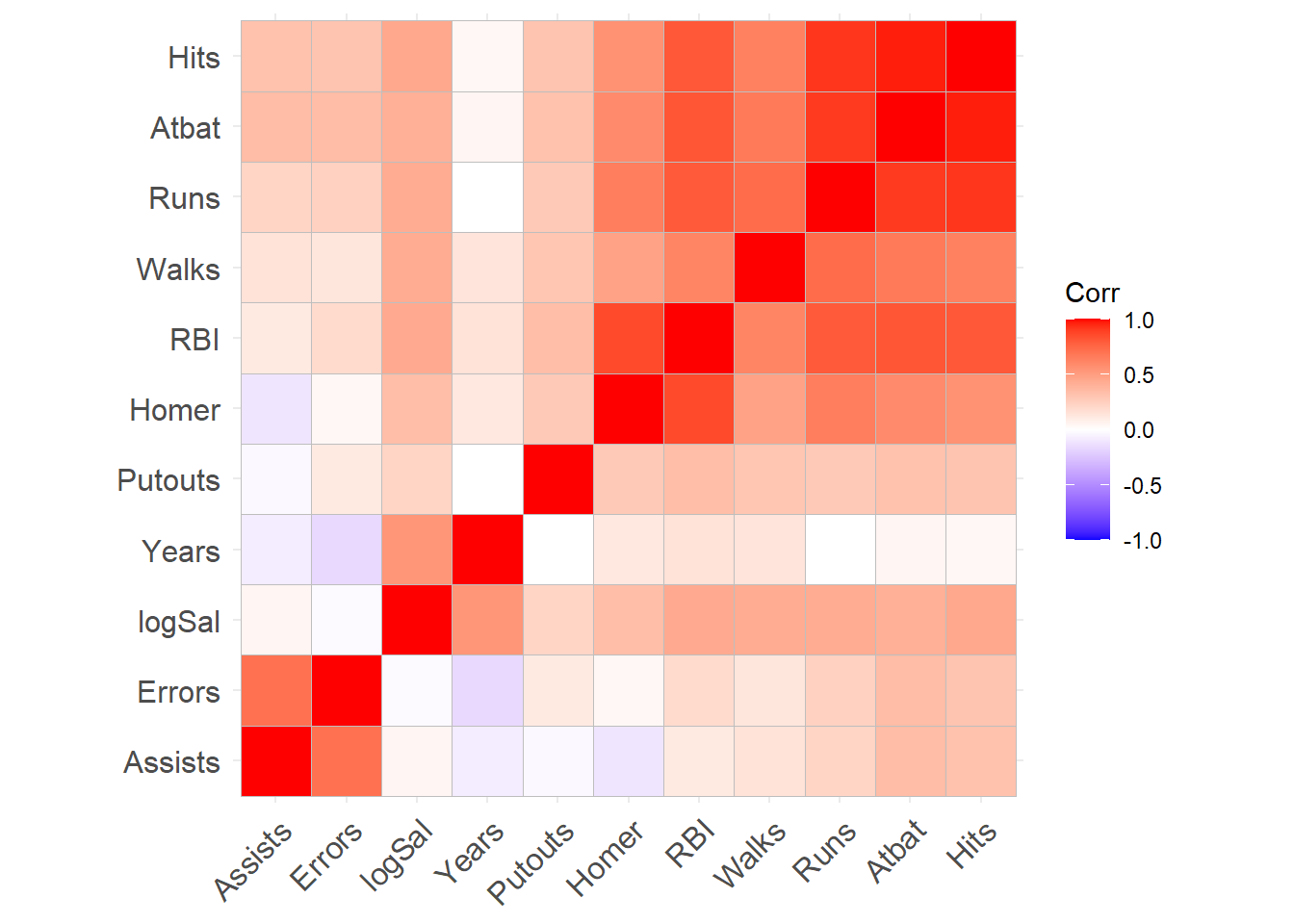
图32.9: 相关阵图形(ggcorrplot)
ggstatsplot包也提供了这样的功能, 并且进行检验:
library(ggstatsplot)
ggcorrmat(
data = baseball[,c("Assists","Atbat","Errors","Hits","Homer","logSal",
"Putouts","RBI","Runs","Walks","Years")]
)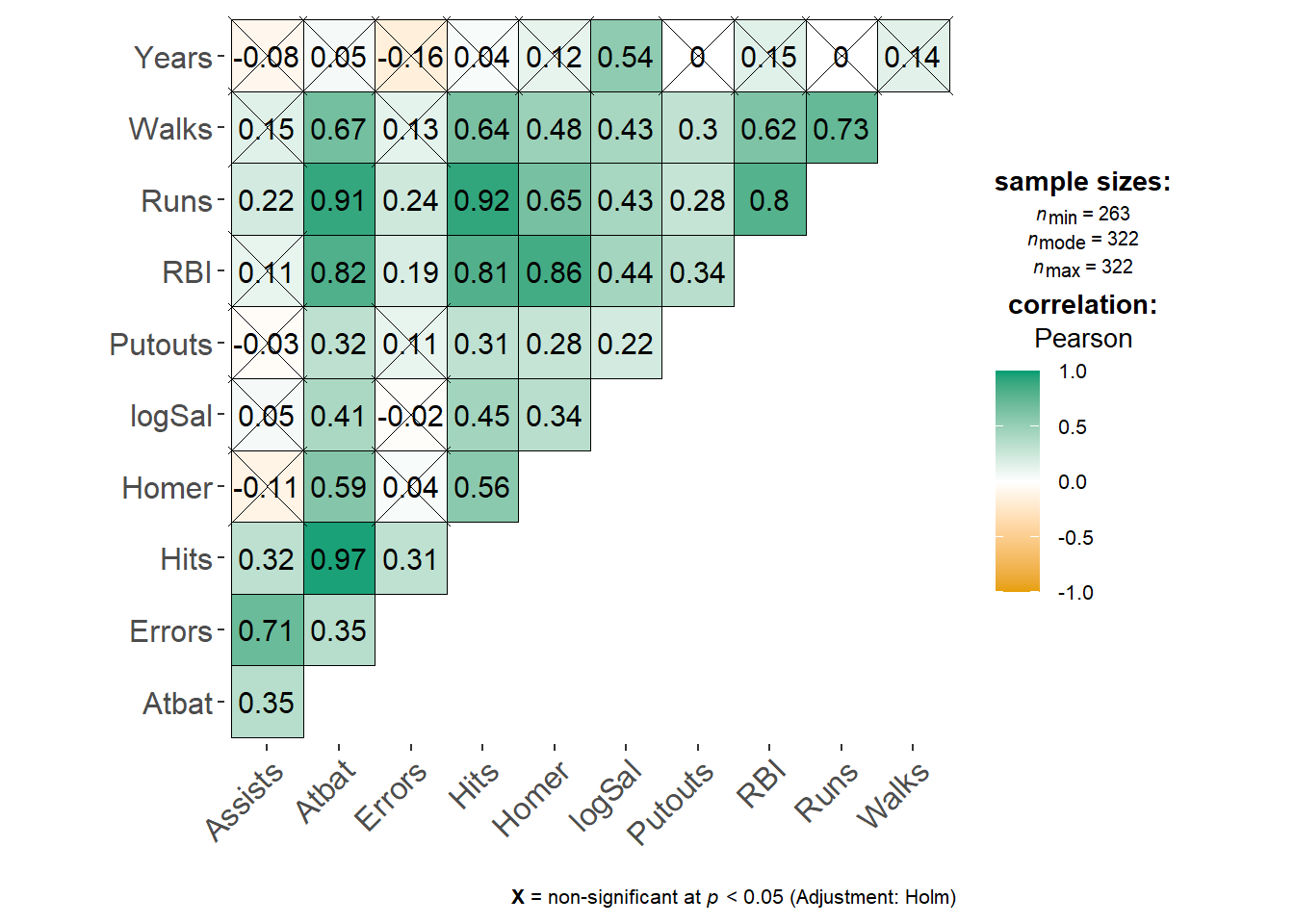
图32.10: 相关阵图形(ggstatsplot)
32.1.6 Spearman秩相关系数
Spearman秩相关系数也成为Spearman rho系数, 是两个变量的秩统计量的相关系数。 计算如:
cor.test(d.class$height, d.class$weight,
method="spearman")## Warning in cor.test.default(d.class$height, d.class$weight, method =
## "spearman"): Cannot compute exact p-value with ties##
## Spearman's rank correlation rho
##
## data: d.class$height and d.class$weight
## S = 164.43, p-value = 2.983e-06
## alternative hypothesis: true rho is not equal to 0
## sample estimates:
## rho
## 0.8557611秩相关系数值为0.8558。
32.1.7 Kendall tau系数
当变量(X,Y)正相关性很强时, 任意两个观测的X值的大小顺序应该与Y值的大小顺序相同; 如果独立, 一对观测的X值比较和Y值比较顺序相同与顺序相反的数目应该基本相同。 Kandall tau系数也是取值于[−1,1]区间, 用这样的思想表示两个变量的相关性和正负。
如:
cor.test(d.class$height, d.class$weight,
method="kendall")## Warning in cor.test.default(d.class$height, d.class$weight, method = "kendall"):
## Cannot compute exact p-value with ties##
## Kendall's rank correlation tau
##
## data: d.class$height and d.class$weight
## z = 4.2136, p-value = 2.513e-05
## alternative hypothesis: true tau is not equal to 0
## sample estimates:
## tau
## 0.7142984Kendall tau系数的值为0.7143。
32.2 一元回归分析
32.2.1 模型
考虑两个变量Y与X的关系,希望用X值的变化解释Y值的变化。 X称为自变量(independent variable),Y称为因变量(response variable)。
假设模型
Y=a+bX+ε,ε∼N(0,σ2)
在回归分析理论中通常假定X是非随机的, 因变量Y的随机性来自误差项ε。 实际应用中X常常也是随机的。
设观测值为(Xi,Yi),i=1,2,…,n,假设观测值满足上模型。 即
Yi=a+bXi+εi,εi iid ∼N(0,σ2).
32.2.2 最小二乘法
直观上看,要找最优的直线y=a+bx使得直线与观测到的点最接近。 例如:
set.seed(1)
nsamp <- 30
x <- runif(nsamp, -10, 10)
y <- 20 + 0.5*x + rnorm(nsamp,0,0.5)
plot(x, y)
abline(lm(y ~ x), col="red", lwd=2)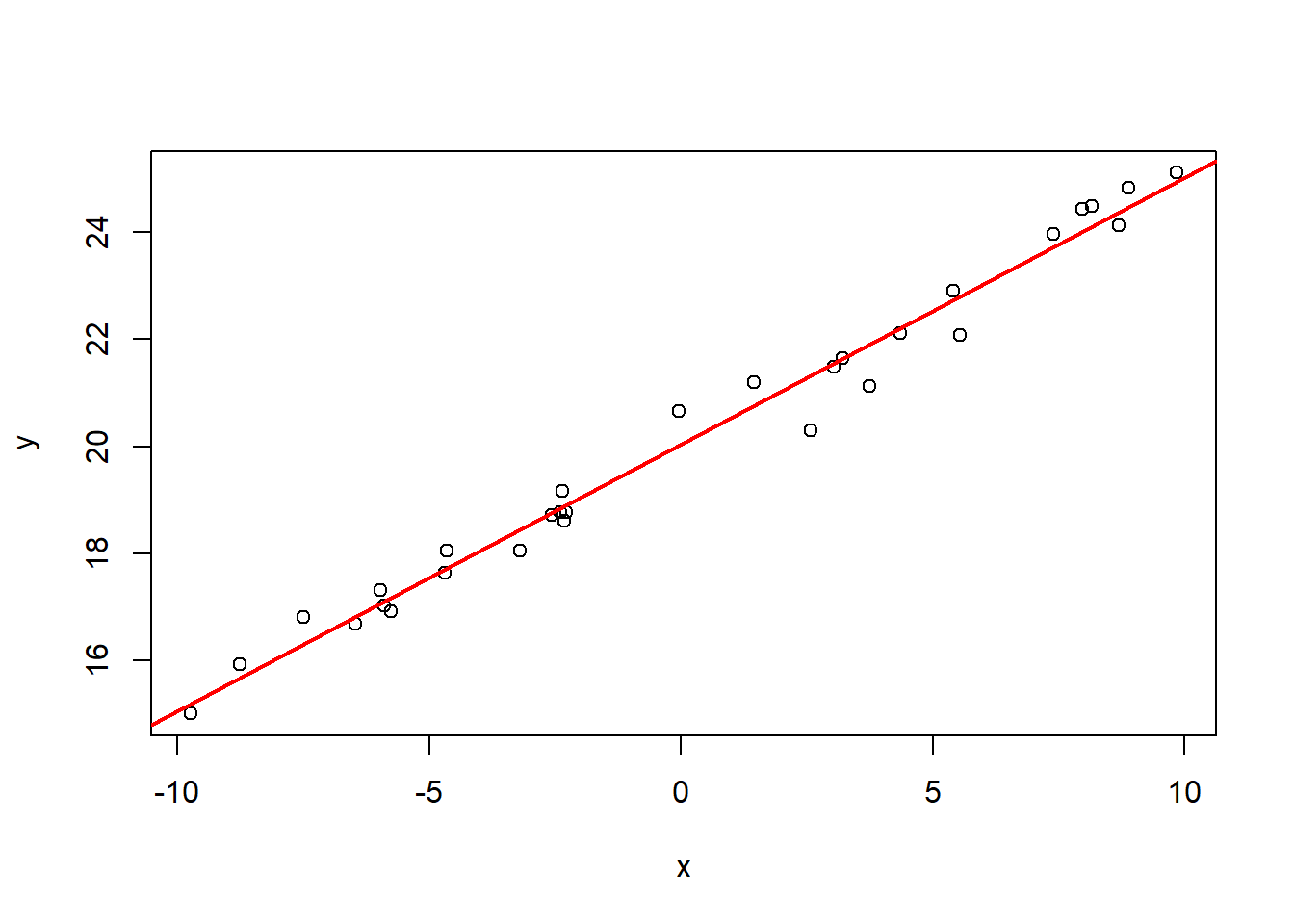
图32.11: 一元线性回归最小二乘估计
a,b的解用最小二乘法得到:
mina,b∑i=1n(yi−a−bxi)2
最小二乘解表达式为
b̂ =â =∑i(xi−x¯)(yi−y¯)∑i(xi−x¯)2=rxySySxy¯−b̂ x¯
其中rxy为X与Y的样本相关系数, Sx与Sy分别为X和Y的样本标准差。
随机误差方差σ2的估计取为
σ̂ 2=1n−2∑i(yi−â −b̂ xi)2
标准误差: 为衡量â 和b̂ 的估计精度, 计算SE(â )和SE(b̂ )。
估计结果:
- 系数估计â , b̂ 以及相应的标准误差估计SE(â )和SE(b̂ );
- 拟合值(预测值)ŷ i=â +b̂ xi,i=1,2,…,n
- 残差ei=yi−ŷ i,i=1,2,…,n
- SSE=∑ie2i 称为残差平方和,残差平方和小则拟合优。
32.2.3 回归有效性
32.2.3.1 拟合优度指标
按照最小二乘估计公式,只要x1,x2,…,xn不全相等, 不论x,y之间有没有相关关系, 都能计算出参数估计值。 得到的回归直线与观测数据的散点之间的接近程度代表了回归结果的优劣。
残差平方和为
SSE=∑i=1n(yi−â −b̂ xi)2.
残差平方和越小, 说明回归直线与观测数据点吻合得越好。 均方误差为
MSE=1n∑i=1n(yi−â −b̂ xi)2.
y是因变量, 因变量的数据的离差平方和
SST=∑i=1n(yi−y¯)2
代表了因变量的未知变动大小, 需要对这样的变动用自变量进行解释, 称SST为总平方和。
可以证明如下平方和分解公式:
SST=SSR+SSE.
其中SSR称为回归平方和。
令ŷ i=β̂ 0+β̂ 1xi称为第i个拟合值, 回归平方和为
SSR=∑i=1n(ŷ i−y¯)2=b̂ 2∑i=1n(xi−x¯)2.
在总平方和中, 回归平方和是能够用回归斜率与自变量的变动解释的部分, 残差平方和是自变量不能解释的变动。 分解中,回归平方和越大,误差平方和越小, 拟合越好。 令
R2=SSRSST=1−SSESST.
称为回归的复相关系数,或判定系数。
0≤R2≤1。判定系数越大,回归拟合越好。 R2=1时,观测点完全落在一条直线上面。 一元回归中R2是x和y的样本相关系数的平方。 在多元回归时只能用复相关系数。
估计误差项方差σ2为
σ̂ 2=1n−2∑i=1n(yi−â −b̂ xi)2=1n−2SSE.
σ̂ 是σ的估计, R的回归结果中显示为“residual standard error”(残差标准误差)。 σ̂ 是残差ei=yi−ŷ i的标准差的一个粗略估计。
32.2.3.2 线性关系显著性检验
当b=0时,模型退化为Y=a+ε,X不出现在模型中, 说明Y与X不相关。检验
H0:b=0⟷Ha:b≠0
取统计量
F=SSRSSE/(n−2)
检验p值为P(F(1,n−2)>c)(设c为F统计量的值)。 取检验水平α, p值小于等于α时拒绝H0, 认为y与x有显著的线性相关关系, 否则认为y与x没有显著的线性相关关系。
也可以使用t统计量
t=b̂ SE(b̂ )
其中
SE(b̂ )=σ̂ /∑i=1n(xi−x¯)2‾‾‾‾‾‾‾‾‾‾‾⎷设t统计量的值为c, 检验p值为P(|t(n−2)|>|c|)。
32.2.4 R程序
设数据保存在数据框d中,变量名为y和x,用R的lm()函数计算回归,如:
set.seed(1)
nsamp <- 30
x <- runif(nsamp, -10, 10)
y <- 20 + 0.5*x + rnorm(nsamp,0,0.5)
d <- data.frame(x=x, y=y)
lm1 <- lm(y ~ x, data=d); lm1##
## Call:
## lm(formula = y ~ x, data = d)
##
## Coefficients:
## (Intercept) x
## 20.0388 0.4988结果只有回归系数。需要用summary()显示较详细的结果。如
summary(lm1)##
## Call:
## lm(formula = y ~ x, data = d)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.03030 -0.16436 -0.05741 0.29511 0.64046
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 20.03883 0.07226 277.3 <2e-16 ***
## x 0.49876 0.01244 40.1 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.3956 on 28 degrees of freedom
## Multiple R-squared: 0.9829, Adjusted R-squared: 0.9823
## F-statistic: 1608 on 1 and 28 DF, p-value: < 2.2e-16结果中H0:b=0的检验结果p值为<2e−16。 这个结果可以从输出最后一行的F统计量检验结果看到, 也可以从稀疏估计中自变量x所在行的t检验结果看到。
又如对d.class数据集,建立体重对身高的回归方程:
lm2 <- lm(weight ~ height, data=d.class)
summary(lm2)##
## Call:
## lm(formula = weight ~ height, data = d.class)
##
## Residuals:
## Min 1Q Median 3Q Max
## -17.6807 -6.0642 0.5115 9.2846 18.3698
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -143.0269 32.2746 -4.432 0.000366 ***
## height 3.8990 0.5161 7.555 7.89e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 11.23 on 17 degrees of freedom
## Multiple R-squared: 0.7705, Adjusted R-squared: 0.757
## F-statistic: 57.08 on 1 and 17 DF, p-value: 7.887e-07身高对体重的影响是显著的(p值7.89e-7)。
32.2.5 回归诊断
除了系数的显著性检验以外, 对误差项是否符合回归模型假定中的独立性、方差齐性、正态性等, 可以利用回归残差进行一系列的回归诊断。 还可以计算一些异常值、强影响点的诊断。
对n组观测值,回归模型为
yi=a+bxi+εi.
拟合值为
ŷ i=â +b̂ xi.残差(residual)为
ei=yi−ŷ i.
残差相当于模型中的随机误差, 但仅在模型假定成立时才是随机误差的合理估计。 所以残差能够反映违反模型假定的情况。
ei有量纲,不好比较大小。 定义标准化残差(内部学生化残差):
ri=eiSe1−1n−(xi−x¯)2∑nk=1(xk−x¯)2‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√.
样本量较大时标准化残差近似服从标准正态分布, 于是取值于[−2,2]范围外的点是可疑的离群点。
R中用residuals()从回归结果计算残差, 用rstandard()从回归结果计算标准化残差。
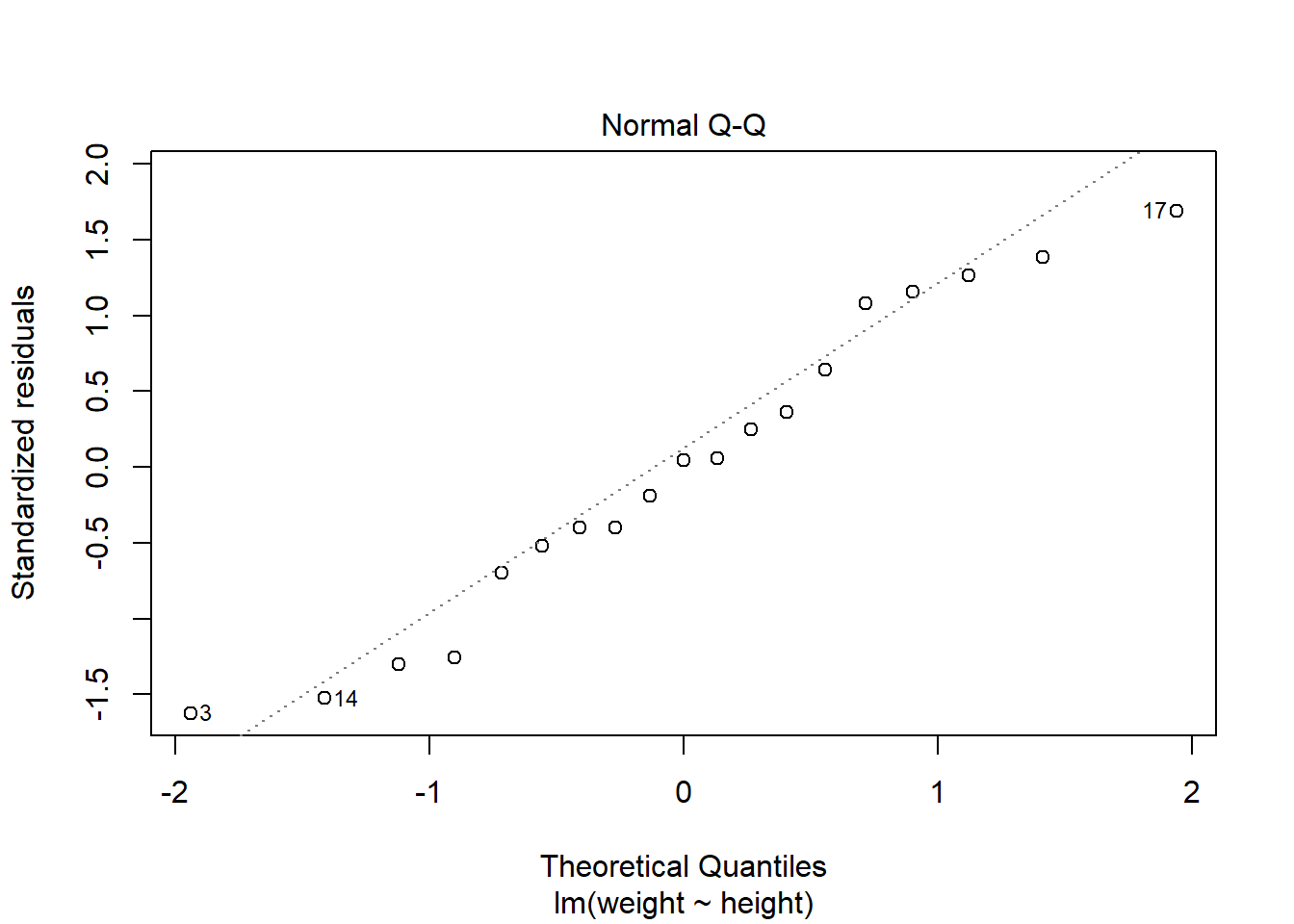
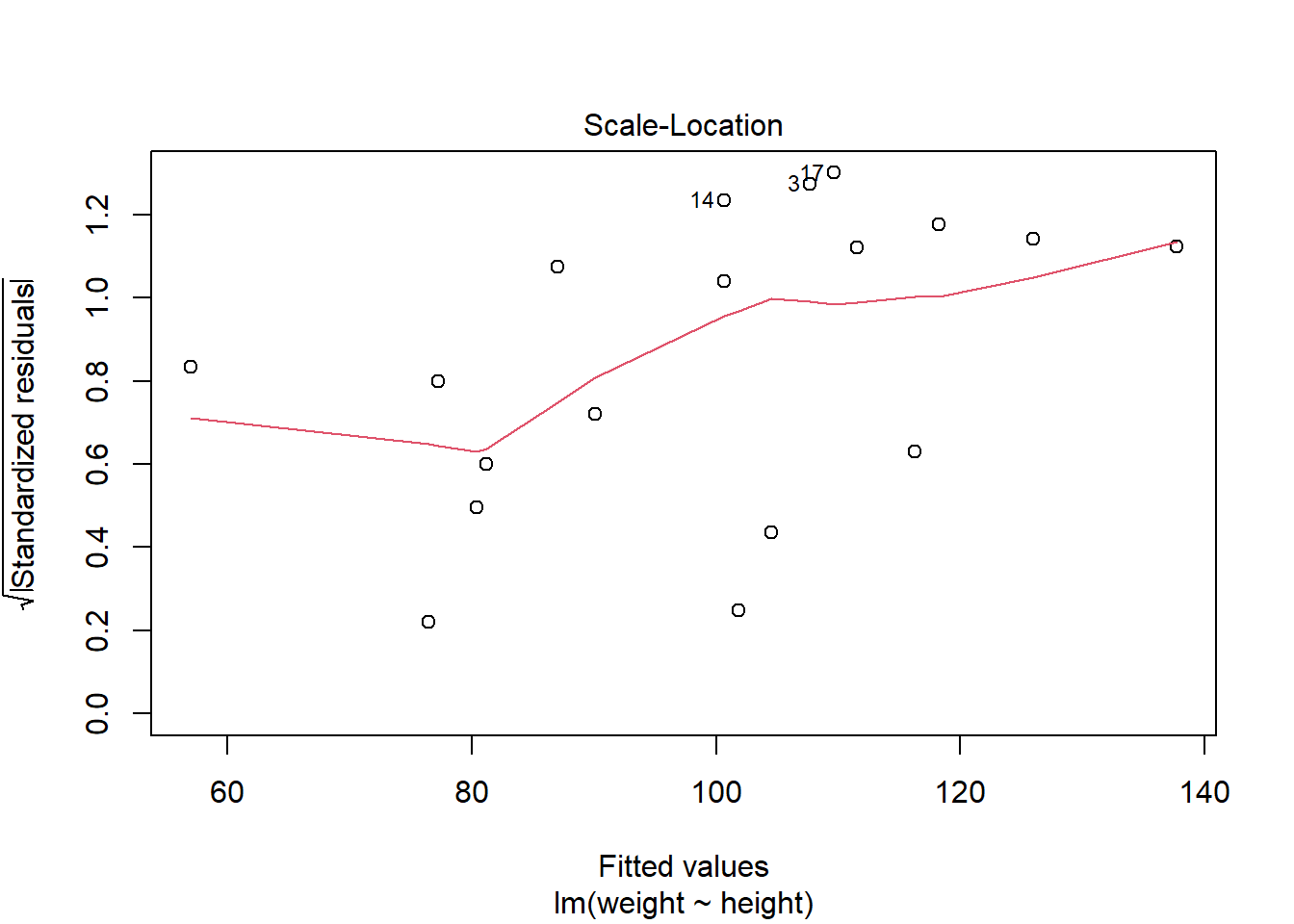
R中plot(lmres)(lmres为回归结果变量)可以做简单回归诊断。
plot(lm2)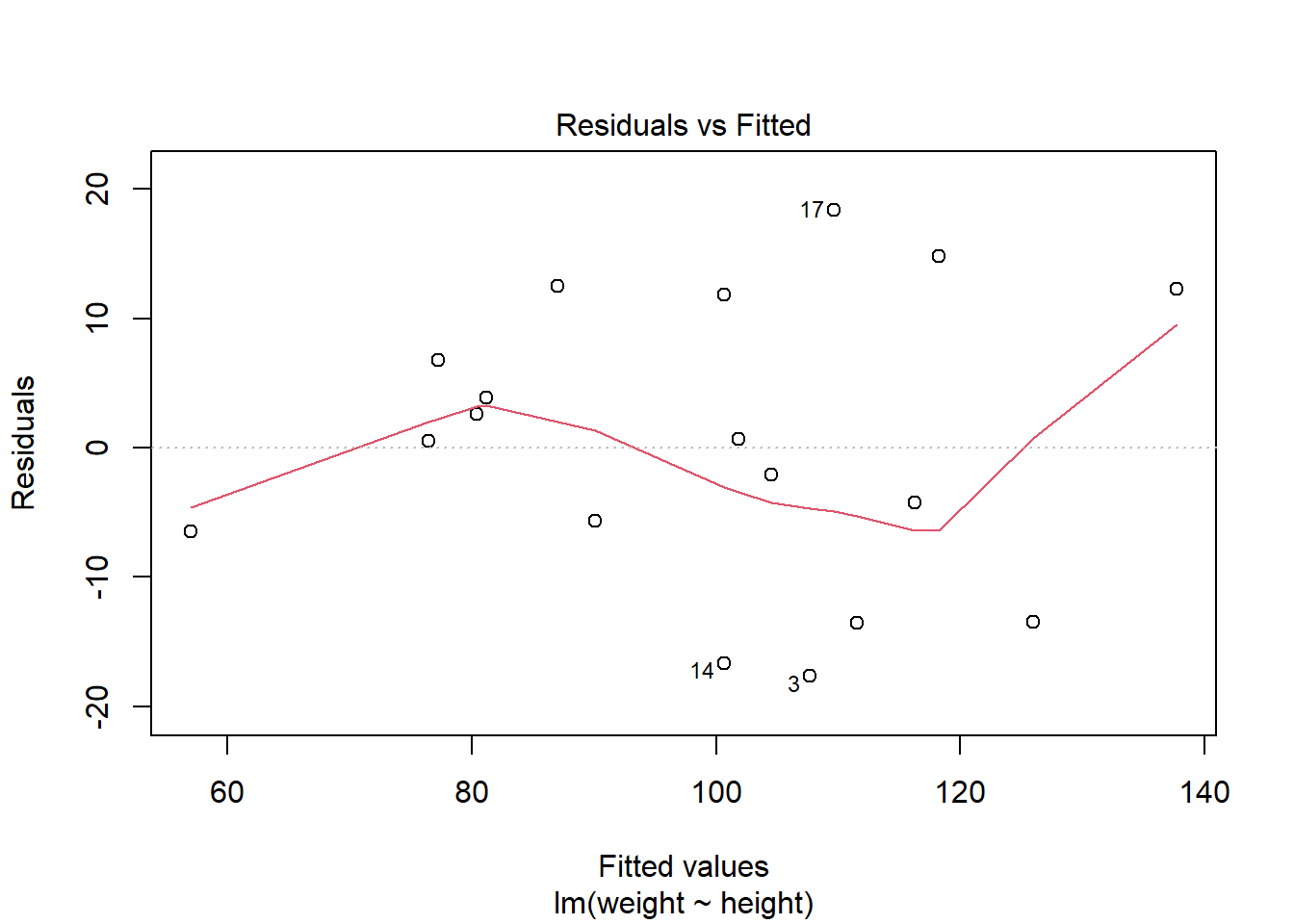
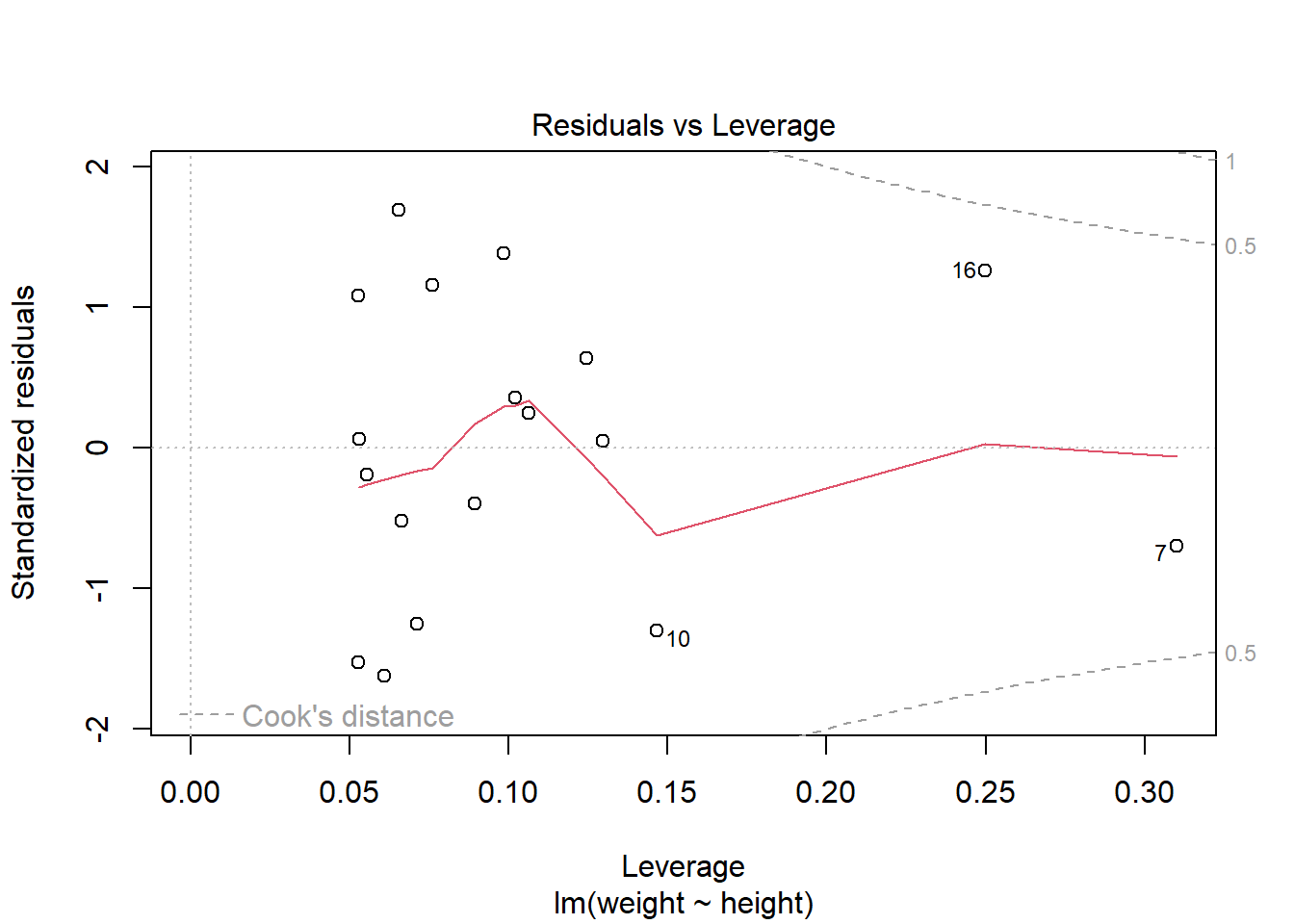
第一幅图是残差对预测值散点图, 散点应该随机在0线上下波动,不应该有曲线模式、分散程度增大模式、 特别突出的离群点等情况。
第二幅图是残差的正态QQ图, 散点接近于直线时可以认为模型误差项的正态分布假定是合理的。
第三幅图是误差大小(标准化残差绝对值的平方根)对拟合值的图形, 可以判断方差齐性假设(方差σ2不变)。
第四个幅是残差对杠杆量图,并叠加了Cook距离等值线。 杠杆量代表了回归自变量对结果的影响大小, 超过4/n的值是需要重视的。 Cook距离考察删去第i个观测对回归结果的影响, 如果有超出两条虚线范围之外的点, 就可能是强影响点。
显示残差与标准化残差:
knitr::kable(cbind("残差"=residuals(lm2),
"标准化残差"=rstandard(lm2)),
digits=2)| 残差 | 标准化残差 |
|---|---|
| 6.73 | 0.64 |
| -13.58 | -1.26 |
| -17.68 | -1.63 |
| 0.51 | 0.05 |
| -5.64 | -0.52 |
| -4.26 | -0.40 |
| -6.49 | -0.70 |
| 11.84 | 1.08 |
| 0.67 | 0.06 |
| -13.51 | -1.30 |
| -2.06 | -0.19 |
| 14.79 | 1.39 |
| 2.61 | 0.25 |
| -16.66 | -1.52 |
| 12.48 | 1.16 |
| 12.30 | 1.26 |
| 18.37 | 1.69 |
| 3.83 | 0.36 |
| -4.26 | -0.40 |
可以用ei或ri作为纵坐标, xi或者ŷ i作为横坐标, 作残差图。
下面给出残差图的几种常见的缺陷:
非线性:
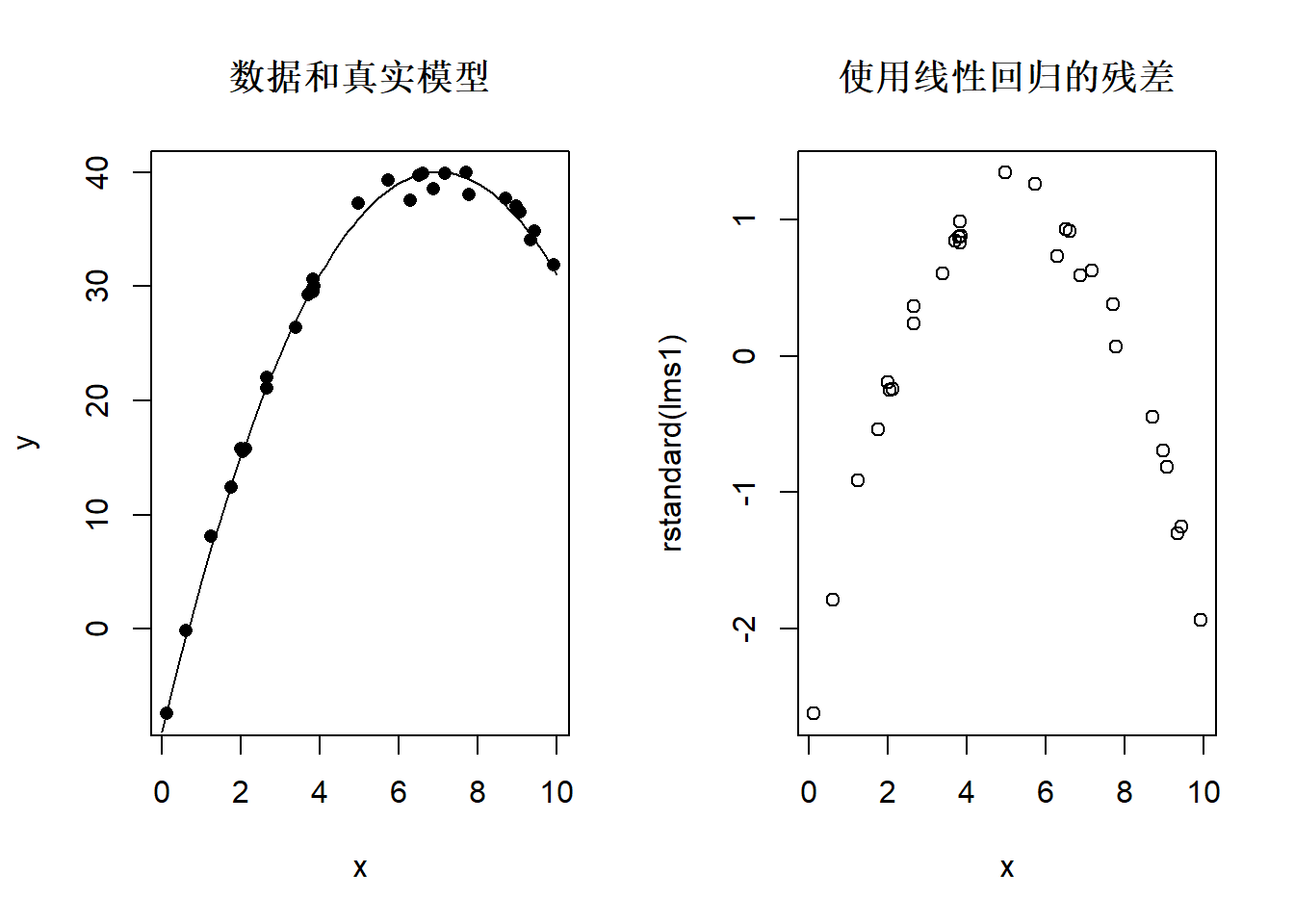
图32.12: 残差中非线性模式
异方差:
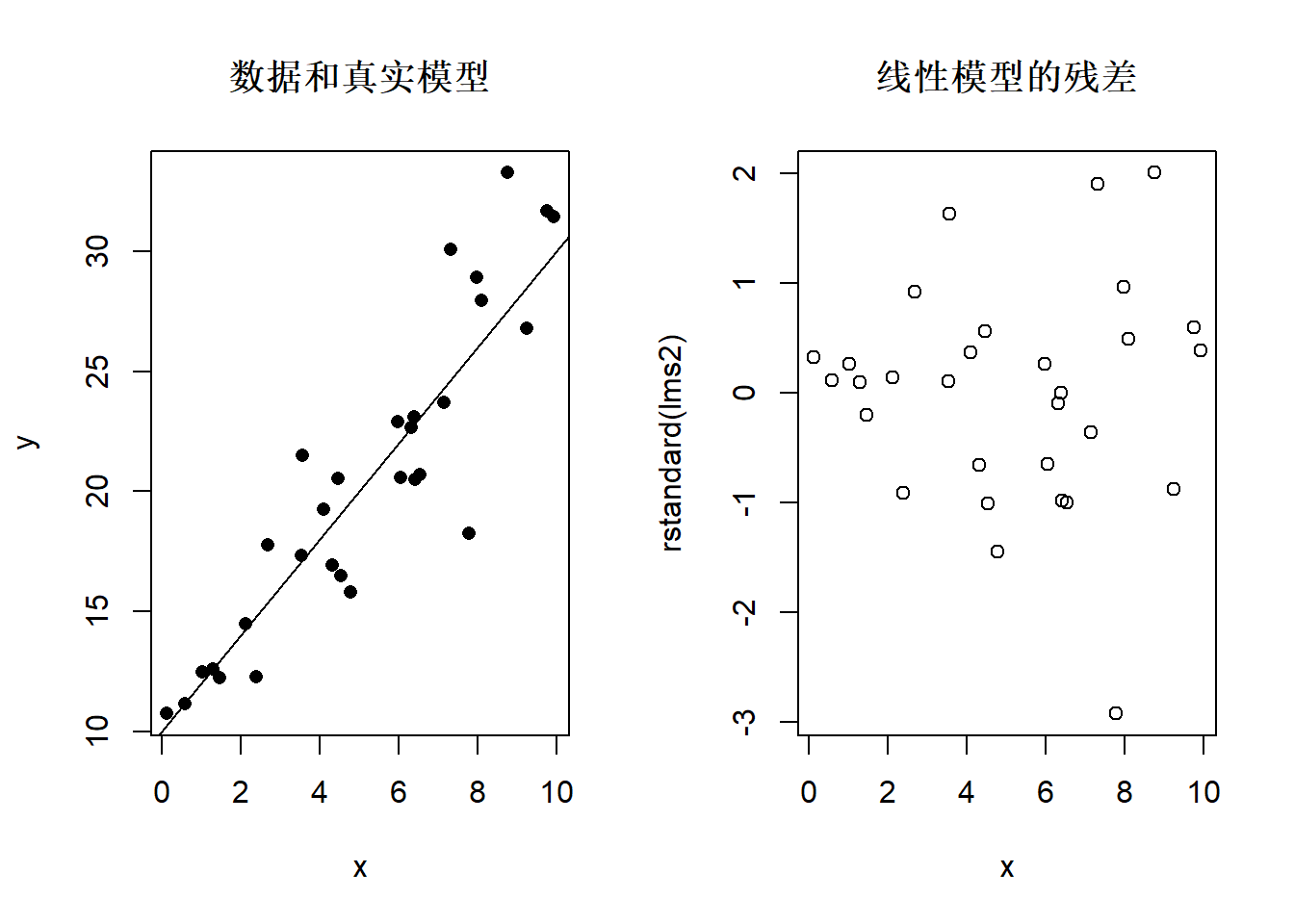
图32.13: 异方差情况下的残差图
car::ncvTest()检验方差齐性。零假设是方差齐性成立。 如
car::ncvTest(lms2)## Non-constant Variance Score Test
## Variance formula: ~ fitted.values
## Chisquare = 4.182918, Df = 1, p = 0.040833当数据随时间变化时,还需要考虑前后是否有序列自相关。 自相关残差图形例子:
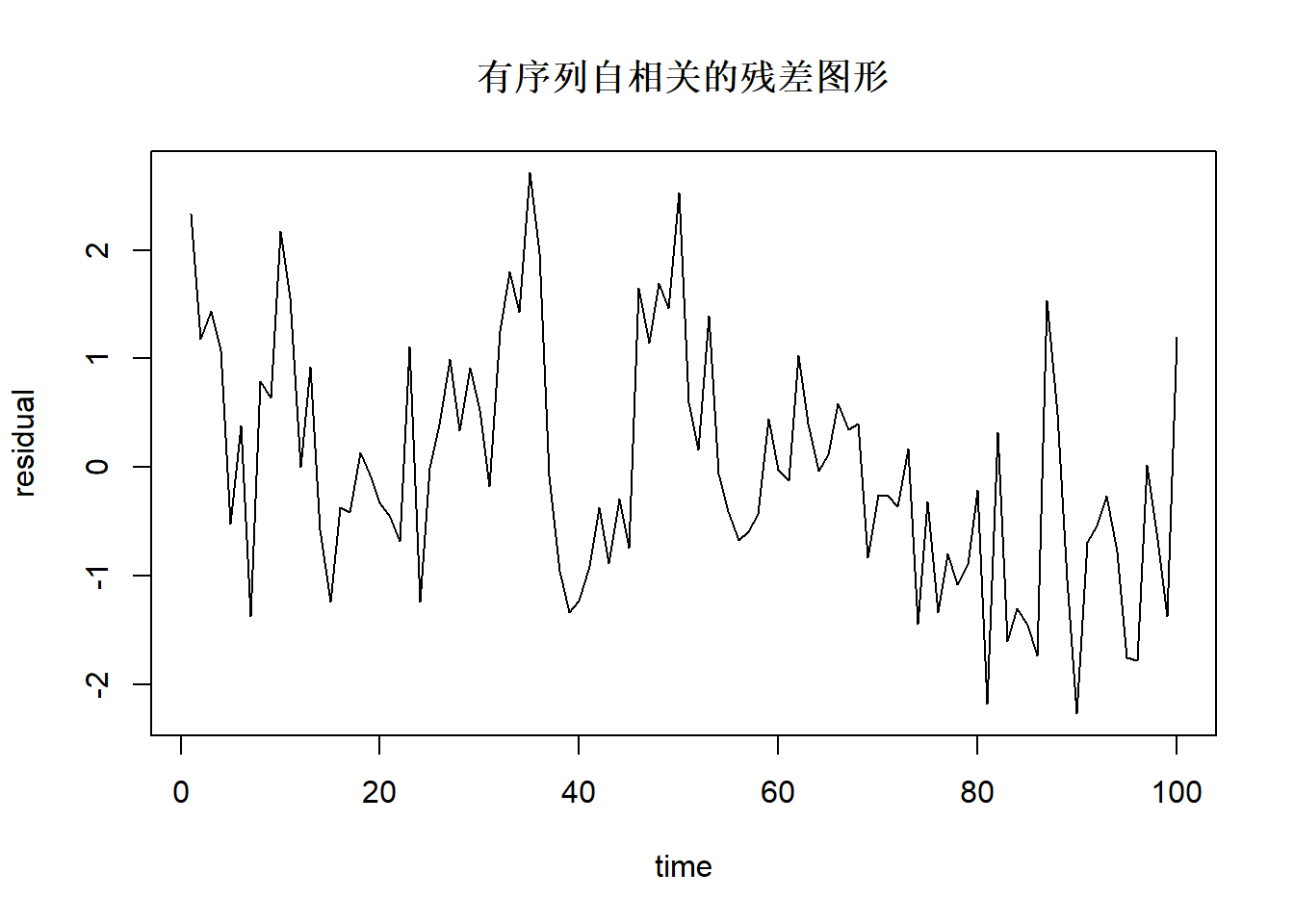
图中横坐标是观测序号。
用Durbin-Watson检验(DW检验)可以检验残差中是否有序列自相关, 零假设是没有序列自相关。 R中用car::durbinWatsonTest()检验。 序列自相关检验仅当数据中数据是沿时间等间隔记录时有意义。 如
car::durbinWatsonTest(lms3)## lag Autocorrelation D-W Statistic p-value
## 1 0.4736699 0.9937971 0
## Alternative hypothesis: rho != 0也可以对回归残差绘制ACF图, 如果除了横坐标0之外都落在两条水平界限内则认为没有序列自相关, 如果有明显超出界限的就认为有序列自相关。 如
forecast::Acf(residuals(lms3), lag.max = 10, main="")## Registered S3 method overwritten by 'quantmod':
## method from
## as.zoo.data.frame zoo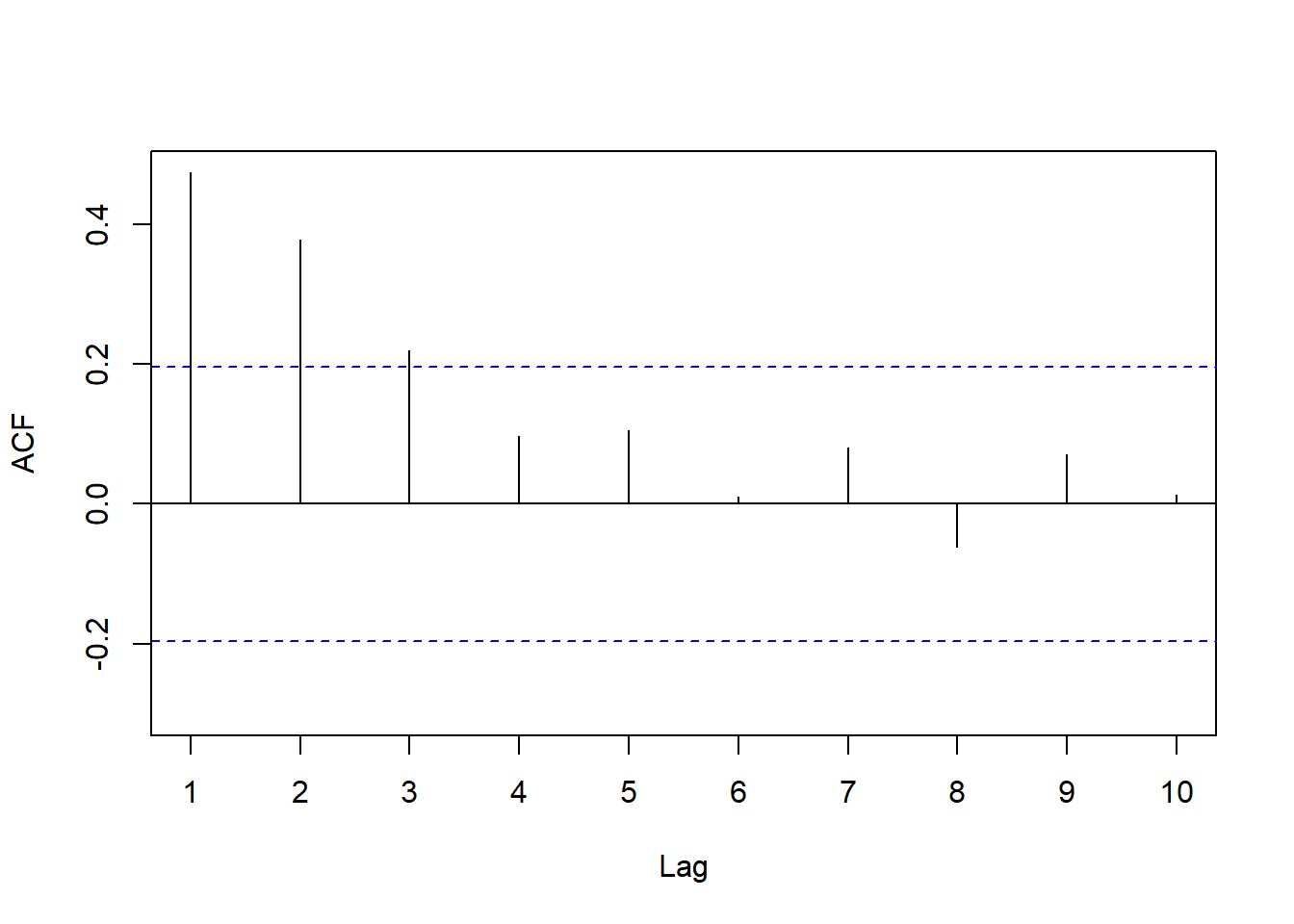
32.2.6 预测区间
设X取x0,Y的预测值为ŷ 0=â +b̂ x0。 置信水平为1−α的预测区间为
ŷ 0±λσ̂ 1+1n+(x¯−x0)2∑i(xi−x¯)2‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√.
其含义是P(y0∈预测区间)=1−α。 λ是标准正态分布双侧α分位数qnorm(1 - alpha/2)。
用predict(lmres)得到ŷ i,i=1,…,n的值, lmres表示回归结果变量。
用predict(lmres, interval="prediction") 同时得到预测的置信区间, 需要的话加入level=选项设定置信度。
回归的置信区间有两种, 上述的区间是“预测区间”(CLI), 使得P(y0∈预测区间)=1−α; 另一种区间称为均值的置信区间(CLM), 使得P(Ey0∈均值置信区间)=1−α。
32.2.7 控制
如果需要把Y的值控制在[yl,yu]范围内,问如何控制X的范围, 可以求解x0的范围使上面的置信区间包含在[yl,yu]内。
近似地可以解不等式
â +b̂ x0−z1−α2σ̂ ≥â +b̂ x0+z1−α2σ̂ ≤ylyu
其中z1−α2为标准正态分布双侧α分位数 (用qnorm(1-alpha/2)计算)。
韭菜热线原创版权所有,发布者:风生水起,转载请注明出处:https://www.9crx.com/79640.html




