

上一章的局部水平模型是线性高斯状态空间模型的一个简单特例。
本章给出状态空间模型,
举例说明这种模型能够表示的其它模型,
如ARIMA模型,结构时间序列模型,
时变回归模型,有自相关误差的回归模型,
随机波动率模型等,
并给出滤波、平滑、预报公式和参数估计方法。
参考:
- (Durbin and Koopman 2012)
- (Tsay 2010)
- (Beijers 2020)
28.1 状态空间模型的公式
28.1.1 线性高斯状态空间模型
状态空间模型有许多不同的表达形式,
按照(Durbin and Koopman 2012)的公式,
线性高斯模型为:
yt=αt+1=Ztαt+εt, εt∼N(0,Ht),Ttαt+Rtηt, ηt∼N(0,Qt),(28.1)(28.2)
其中yt是t时刻的观测值,
为p×1向量;
αt时t时刻系统的状态,
是不可观测的m×1随机向量,
第一个方程称为观测方程,第二个方程称为状态方程。
{εt}和{ηt}相互独立,
都是独立同分布向量白噪声列,
εt为p×1随机向量,
ηt为r×1随机向量,r≤m。
设各矩阵Zt,Tt,Rt,Ht,Qt已知,
Zt和Tt−1允许依赖于y1,…,yt−1,
初始状态α1服从N(a1,P1),
设a1,P1已知,
α1与{εt}和{ηt}独立。
当参数未知时,
设ψ为未知参数,
矩阵Zt,Tt,Rt,Ht,Qt可以依赖于未知参数ψ。
模型中的Rt常常是单位阵,r=m,
有些教材的模型就没有Rt这一项。
包含Rt的好处是,
Rt常常是单位阵Im的某些列组成的一个m×r矩阵,
称为选择矩阵,
这允许某些状态分量对应的方程误差为0,
同时ηt的方差阵Qt还可以是满秩的r×r正定阵,
如果没有Rt矩阵Qt就可能不满秩。
如果Rt是一般的m×r矩阵,
关于状态空间模型的大部分结论仍成立。
28.1.2 推广的状态空间模型
可以将线性高斯的状态空间模型,
推广到状态方程仍为线性高斯形式,
而观测方程的分布为非高斯分布,
或者观测方程中观测变量与状态变量的关系非线性,
更进一步可以推广到状态方程的关系也非线性,
分布为非高斯分布。
较一般的非线性、非高斯状态空间模型形式为:
yt∼αt+1∼ft(αt;β),gt(αt;θ),
其中ft(⋅), g(⋅)是密度函数或概率质量函数,
β和θ是超参数。
这样的模型一般需要用MCMC、序贯重要抽样等随机模拟方法进行滤波、平滑和估计。
28.2 一元结构时间序列模型
下面给出多种时间序列模型的状态空间模型表示和R程序应用。
前一章的局部水平模型是一元结构时间序列模型的特例。
在局部水平模型中增加一个斜率νt项,变成
yt=μt+1=νt+1=μt+et,μt+νt+ξt,νt+ζt,
写成状态空间模型,为
yt=(μt+1νt+1)=(1 0)(μtνt)+et,(1011)(μtνt)+(ξtζt).
再增加一个季节项γt,
季节项有多种模型可选,
比如γt=−∑s−1j=1γt−j+ωt,
或者同一季度的随机游动,
或者三角多项式形式的表达式。
这里用
yt=μt+1=νt+1=γt+1=μt+γt+et,μt+νt+ξt,νt+ζt,−∑j=1s−1γt+1−j+ωt
写成SSM形式,
αt=yt=αt+1=(μt,νt,γt,…,γt−s+2)T,(1,0,1,0,…,0)αt+et,Ttαt+Rtηt.
例如,当s=4(季度数据)时,
αt=yt=⎛⎝⎜⎜⎜⎜⎜⎜μt+1νt+1γt+1γtγt−1⎞⎠⎟⎟⎟⎟⎟⎟=(μt,νt,γt,γt−1,γt−2)T,(1,0,1,0,0)αt+et,⎛⎝⎜⎜⎜⎜⎜100001100000−11000−10100−100⎞⎠⎟⎟⎟⎟⎟⎛⎝⎜⎜⎜⎜⎜⎜μtνtγtγt−1γt−2⎞⎠⎟⎟⎟⎟⎟⎟+⎛⎝⎜⎜⎜⎜⎜100000100000100⎞⎠⎟⎟⎟⎟⎟⎛⎝⎜⎜ξtζtωt,⎞⎠⎟⎟,⎛⎝⎜⎜ξtζtωt,⎞⎠⎟⎟∼N(0,diag(σ2ξ,σ2ζ,σ2ω)).
模型中可以加入商业周期项ct,
可以增加若干个回归自变量,可以增加干预变量如:
wt=I{t≥τ}。
28.2.1 Alcoa现实波动率的局部水平模型
例28.1 考虑Alcoa股票日现实波动率数据的局部水平模型,
时间期间为2003-01-02到2004-05-07,
共340个观测。
读入数据:
da <- readr::read_table("aa-3rv.txt",
col_names=FALSE)##
## ── Column specification ────────────────────────────────────────────────────────
## cols(
## X1 = col_double(),
## X2 = col_double(),
## X3 = col_double()
## )ts.alcoa <- ts(log(da[[2]]))使用局部水平模型,状态空间模型为:
yt=μt+1=μt+et,μt+ηt.
使用statespacer包进行估计,
这个包直接支持对结构时间序列模型进行简化的模型设定:
library(statespacer)
ssr1 <- statespacer(
y = cbind(as.vector(ts.alcoa)),
local_level_ind = TRUE,
initial = rep(0.5*log(var(ts.alcoa)), 2),
verbose = TRUE)## Starting the optimisation procedure at: 2023-05-26 09:26:37## initial value 1.022439
## iter 10 value 0.765458
## iter 20 value 0.764395
## final value 0.764395
## converged## Finished the optimisation procedure at: 2023-05-26 09:26:37## Time difference of 0.0184540748596191 secsc("Var_obs"=ssr1$system_matrices$H$H,
"Var_level"=ssr1$system_matrices$Q$level)## Var_obs Var_level
## 0.230623632 0.005404681超参数估计为
σ2e=0.2306, σ2η=0.005405.
做原始序列与平滑得到的趋势(水平值)的时间序列图,
包括95%预测区间:
smsd <- sqrt(ssr1$smoothed$V[1,1,])
plot(ts.alcoa, ylim=c(-1.5, 3))
lines(as.vector(time(ts.alcoa)),
ssr1$smoothed$level, col="green")
lines(as.vector(time(ts.alcoa)),
ssr1$smoothed$level - 1.96*smsd,
lty=2, col="cyan")
lines(as.vector(time(ts.alcoa)),
ssr1$smoothed$level + 1.96*smsd,
lty=2, col="cyan")
legend("bottomleft", lty=c(1,1,2),
col=c("black", "green", "cyan"),
legend=c("Obs", "Smoothed", "95% CL"))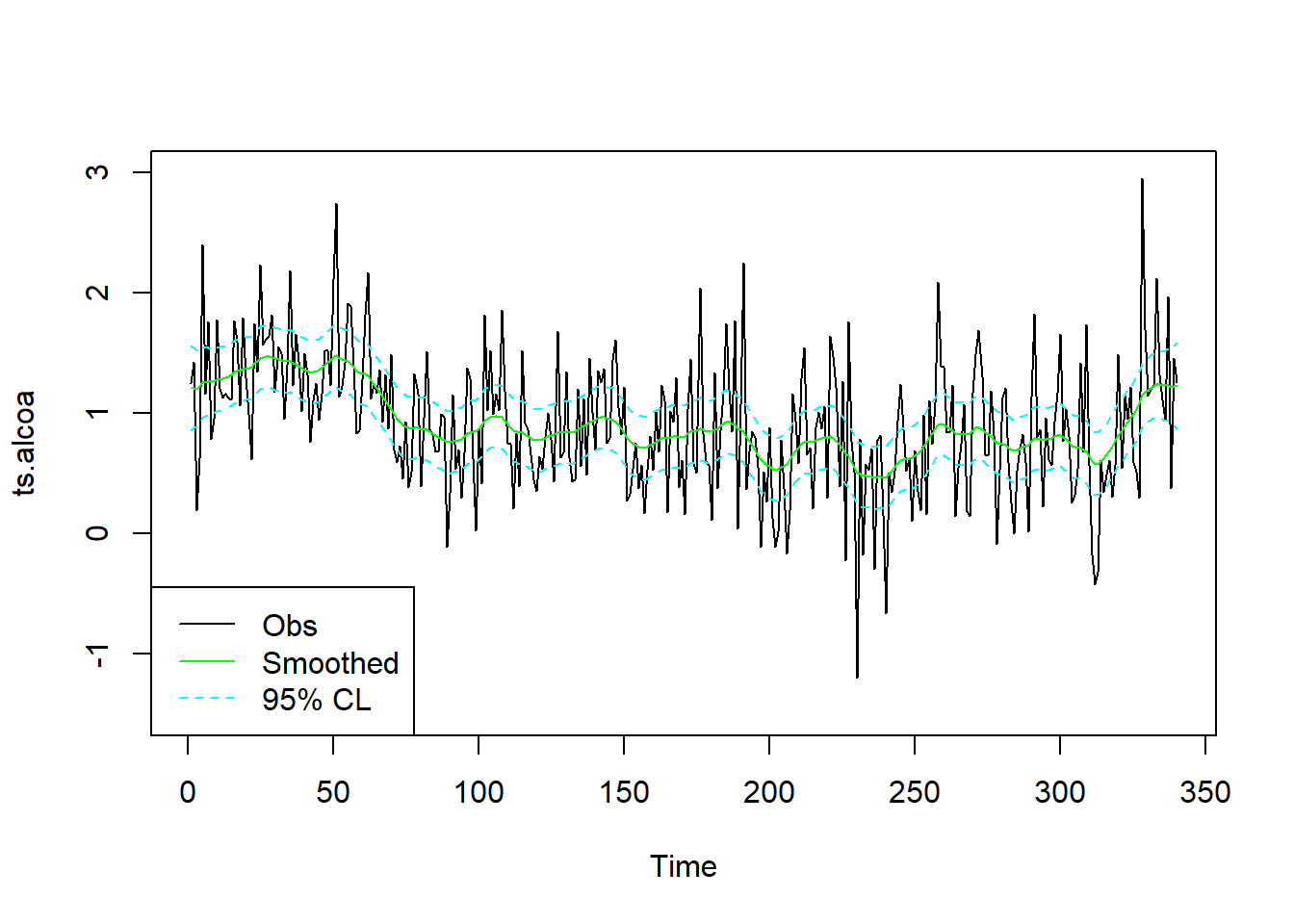

下面改用KFAS包进行估计。
这个包也支持对结构时间序列模型进行简化的模型设定。
library(KFAS)
## 模型设定
kfas01a <- SSModel(
ts.alcoa ~ SSMtrend(
1, Q=list(matrix(NA))),
H=matrix(NA))
## 超参数估计
kfas01b <- fitSSM(
kfas01a, rep(log(var(ts.alcoa)), 2), method="BFGS")
c("Var_obs"=c(kfas01b$model$H),
"Var_level"=c(kfas01b$model$Q))## Var_obs Var_level
## 0.230651733 0.005404091## 用估计的超参数进行滤波平滑
kfas01c <- KFS(kfas01b$model)超参数估计结果与statespacer基本一致。
计算两个包的平滑结果的最大差距:
c("水平值平滑差距"=max(abs(c(ssr1$smoothed$level) - c(kfas01c$muhat))),
"水平值平滑方差差距"=max(abs(c(ssr1$smoothed$V) - c(kfas01c$V_mu))))## 水平值平滑差距 水平值平滑方差差距
## 3.475598e-05 9.103878e-07可见statespacer和KFAS两个包的平滑结果是一致的。
dlm包也可以实现这个模型。
在超参数σ2e和σ2η已知时,
可以指定模型如下:
library(dlm)
dlm(
FF = 1, # $Z_t$矩阵
V = 0.8, # $\sigma_e^2$
GG = 1, # $T_t$矩阵
W = 0.1, # $\sigma_{\eta}^2$
m0 = 0, # 与$a_1$作用相同,为$\mu_0$期望
C0 = 100 # 与$P_1$作用相同,为$\mu_0$方差
)## $FF
## [,1]
## [1,] 1
##
## $V
## [,1]
## [1,] 0.8
##
## $GG
## [,1]
## [1,] 1
##
## $W
## [,1]
## [1,] 0.1
##
## $m0
## [1] 0
##
## $C0
## [,1]
## [1,] 100也可以用dlmModPoly()指定这样的局部水平模型:
dlmModPoly(
order = 1, # 局部水平模型
dV = 0.8, # $\sigma_e^2$
dW = 0.1, # $\sigma_{\eta}^2$
C0 = 100 # 与$P_1$作用相同,为$\mu_0$方差
)## $FF
## [,1]
## [1,] 1
##
## $V
## [,1]
## [1,] 0.8
##
## $GG
## [,1]
## [1,] 1
##
## $W
## [,1]
## [1,] 0.1
##
## $m0
## [1] 0
##
## $C0
## [,1]
## [1,] 100为了对超参数进行最大似然估计,
需要自定义一个给定超参数后输出dlm模型的函数:
buildFun <- function(para){
dlmModPoly(
order = 1,
dV = exp(para[[1]]),
dW = exp(para[[2]])
)
}注意模型中并没有输入数据。
用dlmMLE()函数输入数据后对超参数进行最大似然估计:
fit_dlm <- dlmMLE(
ts.alcoa, # 输入的观测值序列
parm = c(0, 0), # 超参数对数值的初值
build = buildFun
)
fit_dlm$conv## [1] 0获得估计的超参数对应的dlm模型:
dlm_al <- buildFun(fit_dlm$par)估计的超参数值:
c("Var_obs"=V(dlm_al),
"Var_level"=W(dlm_al))## Var_obs Var_level
## 0.23065283 0.00540346估计结果与statespacer和KFAS结果基本相同。
为了获得滤波结果,
可以调用dlmFilter(dlm_al),
平滑结果使用dlmSmooth(dlm_al),
从结果中可以很容易地提取滤波估计与平滑估计,
但是条件分布方差阵估计使用了奇异值分解表示,
提取时要使用dlmSvd2var()函数转换为方差阵。
○○○○○
28.2.2 尼罗河流量带变点的局部水平模型
例28.2 考虑尼罗河1871-1970年的年流量数据,
单位是108立方米,
在1898-1899年有明显的变点。
用局部水平模型建模并考虑变点的拟合。
基本R的datasets包中Nile变量为长度100的时间序列:
plot(Nile, main="Annual flow of Nile")
abline(v = c(1898, 1899), lty=3, col="yellow")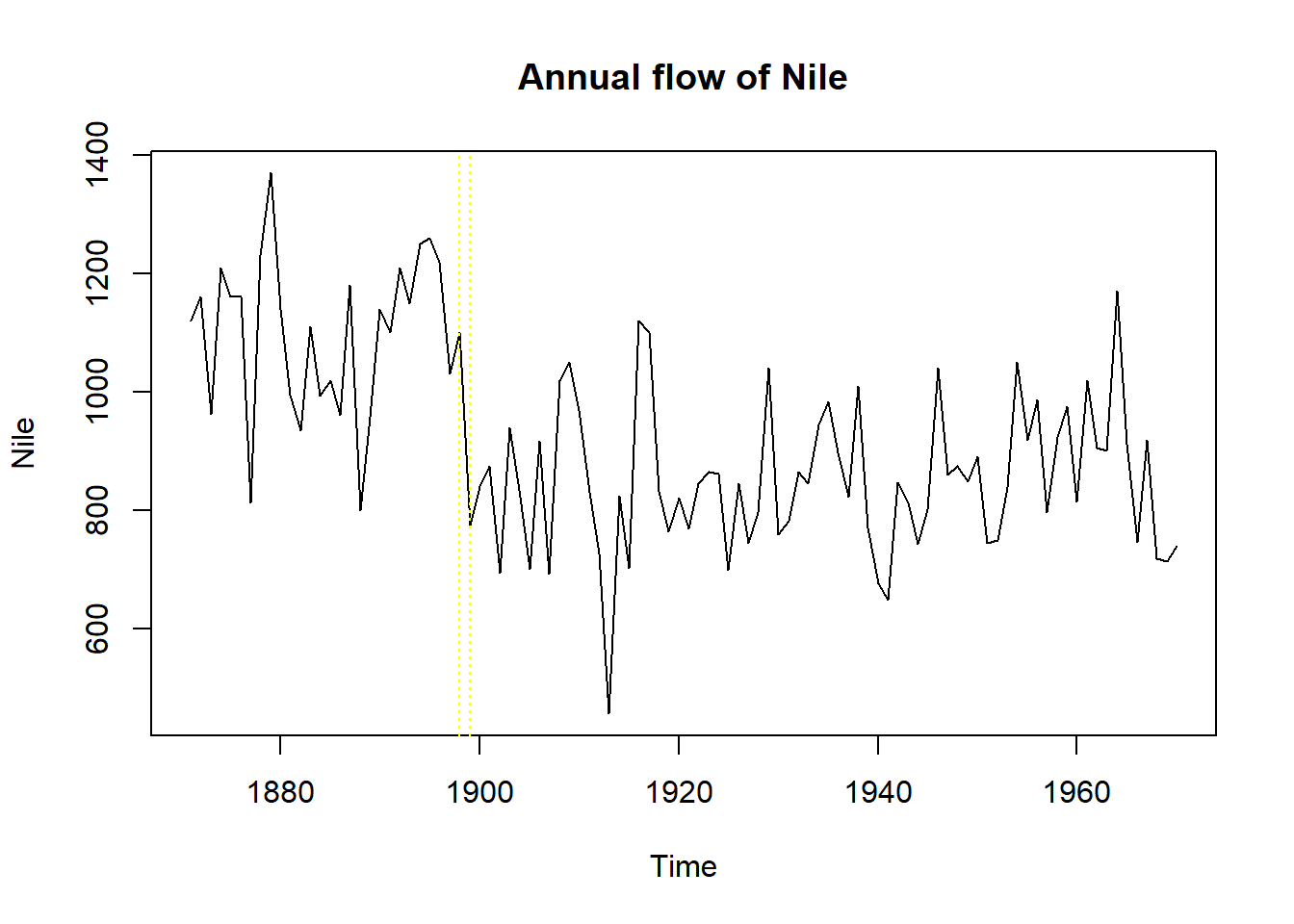
使用dlm包,
输入超参数建立dlm模型的函数:
library(dlm)
buildFun <- function(para){
mod <- dlmModPoly(
order = 1,
dV = exp(para[[1]]) # $\sigma_e^2$,非时变
)
mod$JW <- matrix(1) # 示性函数,表示$\sigma_{\eta_t}^2$时变
# mod$X: 用来保存时变的成分
mod$X <- cbind(rep(exp(para[[2]]), length(Nile)))
# 给t=1898年的观测的$\eta_t$方差放大
jj <- which(time(Nile) == 1899)[1]
mod$X[jj,1] <- mod$X[jj,1] * (1 + exp(para[[3]]))
mod
}在上面的模型中,
状态方差的扰动项ηt的方差是时变的,
但仅在1899年与其它年份不同。
为了容许模型中的矩阵时变,
在dlm中用JW作为示性函数,
表示状态方程的扰动项方差阵那些元素是时变的,
然后将时变的内容保存在X矩阵中,
矩阵的行数等于观测长度n。
用第三个钞参数表示1899年的状态方程扰动项方差放大倍数(对数尺度)。
三个超参数的最大似然估计:
fit_nile <- dlmMLE(
Nile,
parm = c(0, 0, 0),
build = buildFun)
fit_nile$conv## [1] 0获取估计的模型:
dlm_nile <- buildFun(fit_nile$par)σ2e估计:
## [,1]
## [1,] 16300.33除去变点以外的所有观测的ηt方差估计,
以及1899年的ηt方差估计:
dlm_nile$X[c(1, which(time(Nile) == 1899)[1]), 1]## [1] 2.792224e-02 6.048379e+04可以看出,
非变点处的ηt的标准差,
与观测yt的取值范围相比,
基本上等于0。
计算滤波和平滑估计:
filt_nile <- dlmFilter(Nile, dlm_nile)
sm_nile <- dlmSmooth(filt_nile)提取平滑估计:
sme_nile <- dropFirst(sm_nile$s)提取平滑分布方差:
smv_nile <- dlmSvd2var(sm_nile$U.S, sm_nile$D.S) |>
unlist() |>
dropFirst()作原始序列图,
添加平滑结果曲线(红色),
平滑区间(绿色):
plot(Nile, type="o", main="Smoothed Nile Flow")
lines(sme_nile, col="red")
lines(sme_nile - 1.96 * sqrt(smv_nile), lty=3, col="green")
lines(sme_nile + 1.96 * sqrt(smv_nile), lty=3, col="green")
abline(v=c(1898, 1899), lty=3, col="yellow")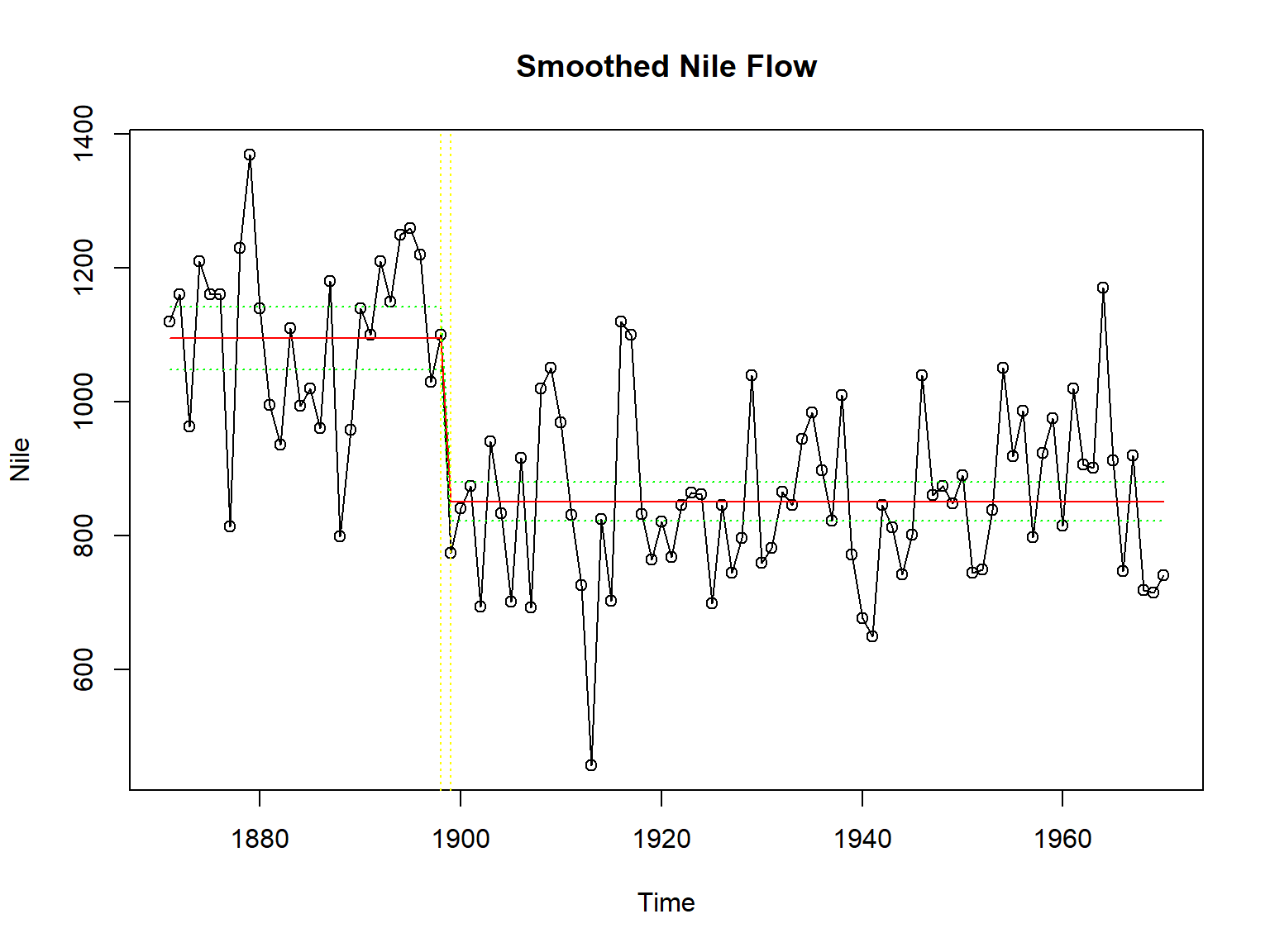
这个模型中的ηt的方差是时变的,
水平在1898到1999之间有一个变点,
在变化之前的ηt的方差基本恒定,
水平也基本恒定,
变化之后也是如此。
○○○○○
28.2.3 英国燃气消耗量结构时间序列建模
基本R的datasets包的UKgas变量保存了英国1960年到1986年的季度燃气消耗时间序列。
使用结构时间序列建模,
需要有趋势部分和季节部分,
dlm包支持这样的模型设定。
plot(UKgas, main="UK quarterly gas consumption")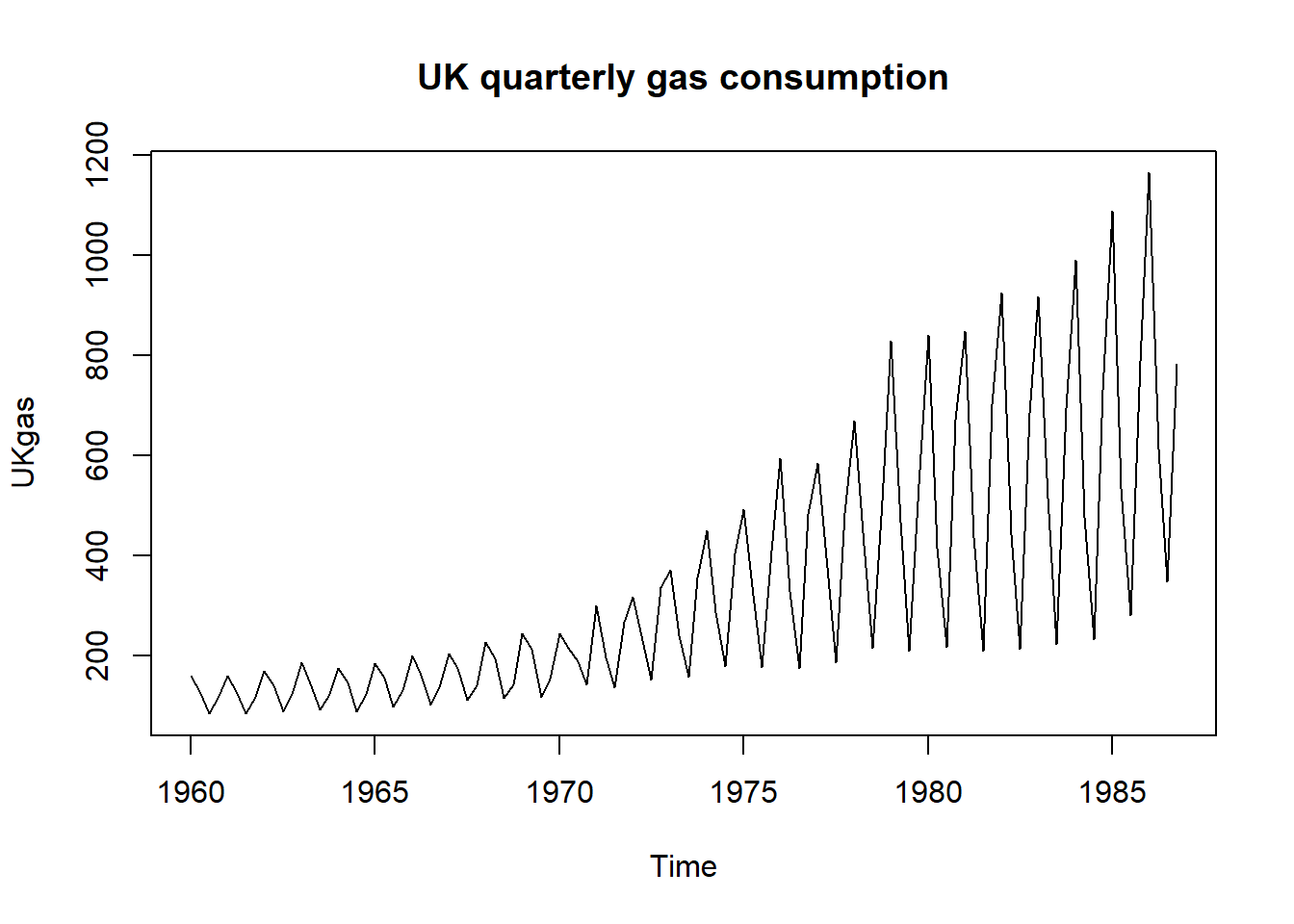
因为趋势与季节部分呈现乘性的组合,
改用对数值:
plot(log(UKgas), main="UK quarterly gas consumption(log scale)")
指定模型:
library(dlm)
lGas <- log(UKgas)
dlmGas <- dlmModPoly() + dlmModSeas(4)函数dlmModPoly()会指定一个有局部水平和水平的增量(时变斜率)的模型,dlmModSeas(4)指定季节模型,
用加号表示这两部分的状态分别建模,
在观测方程中将两部分结果相加。
拟合模型:
buildFun <- function(para){
dlmGas <- dlmModPoly() + dlmModSeas(4)
# 仅指定了时变斜率和季节项的方差,
# 没有指定局部水平的方差
diag(W(dlmGas))[2:3] <- exp(para[1:2])
V(dlmGas) <- exp(para[3])
dlmGas
}
fit_gas <- dlmMLE(
lGas,
parm = log(c(10^-5, 10^-3, 10^-3)),
build = buildFun )
fit_gas$conv## [1] 0估计得到的模型:
dlmGas <- buildFun(fit_gas$par)观测方程方差:
## [1] 0.001822492状态方程方差:
## [1] 7.901263e-06 3.308590e-03获取平滑得到的水平、季节项:
sm_gas <- dlmSmooth(lGas, mod=dlmGas)
da_tmp <- cbind(
lGas,
dropFirst(sm_gas$s[, c(1,3)]))
colnames(da_tmp) <- c("Gas", "Trend", "Seasonal")
plot(da_tmp, type="o",
main = "UK gas consumption structral model")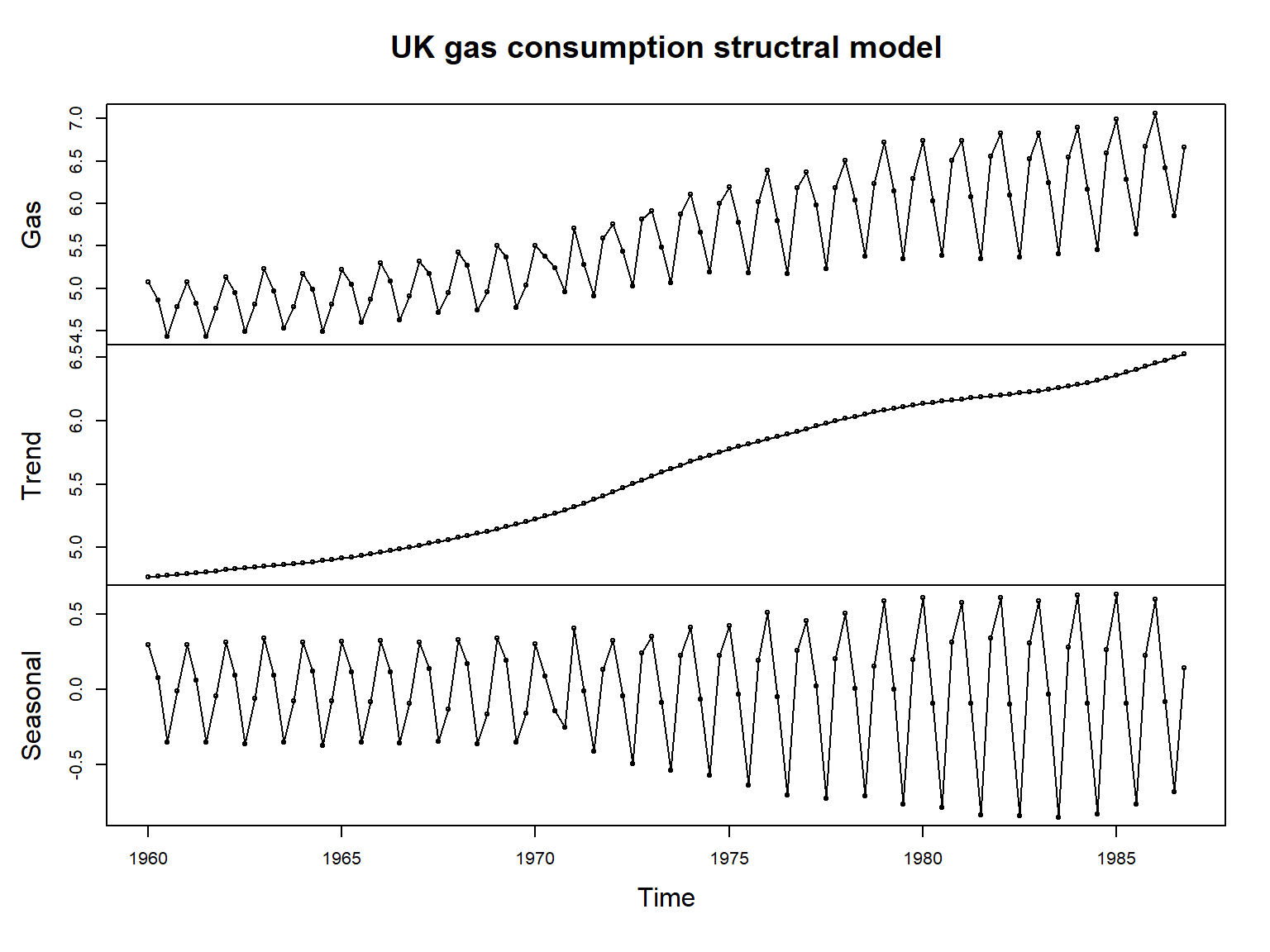
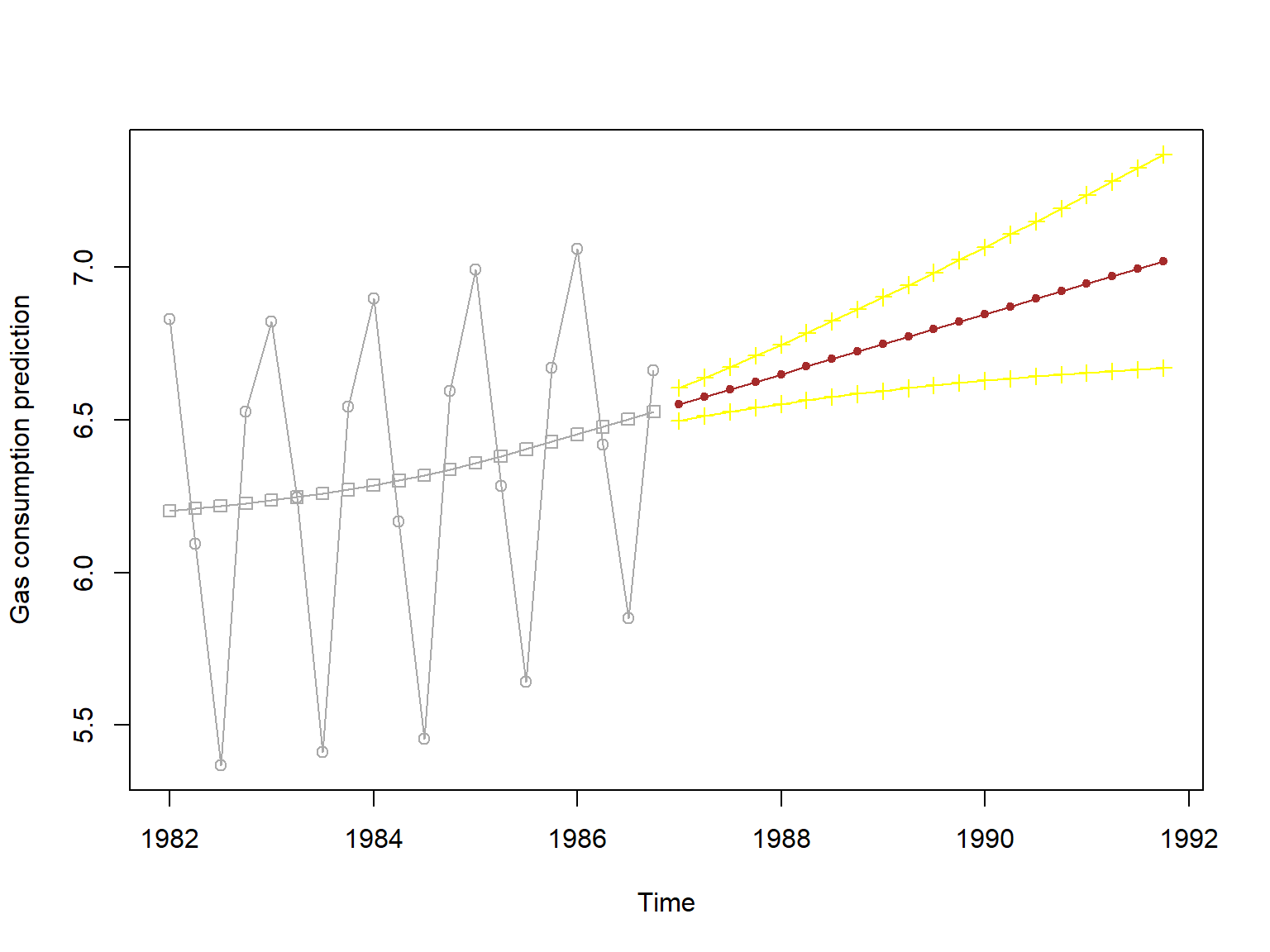
预报分布的均值和方差可以用dlmForecast()获得。
下面的预测区间是90%置信度的。
filt_gas <- dlmFilter(lGas, mod = dlmGas)
fore_gas <- dlmForecast(filt_gas, nAhead = 20)
# 预测
gas_pred20 <- fore_gas$a[,1]
# 预测标准误差
gas_predse <- fore_gas$R |>
sapply(\(x) sqrt(x[1,1]))
# 将末尾一段与预测结果连接
da_tmp <- ts.union(
window(lGas, start=c(1982,1)),
window(sm_gas$s[,1], start=c(1982,1)),
gas_pred20,
gas_pred20 - 1.645*gas_predse,
gas_pred20 + 1.645*gas_predse)
plot(da_tmp, plot.type = "single",
type = "o",
pch = c(1, 0, 20, 3, 3),
col = c("darkgrey", "darkgrey",
"brown", "yellow", "yellow"),
ylab = "Gas consumption prediction"
)
使用dlm发现,
如果在dlmMLE()中使用parm=rep(0, 3),
则将原始数据作自然对数变换的结果比较好,
状态方程扰动方差和观测方程扰动方差很小,
但改为常用对数变换时,
状态方程扰动项方差会增大一两个数量级,
使得上图中的预测区间会大得不可接受。
如果在dlmMLE()中人为取parm为较合适的初值,
就可以得到与自然对数变换相同的结果,
这说明dlm计算最大似然估计可能不太可靠,
很可能落入局部极值点。dlmMLE()的结果会依赖于参数的初始值parm的选择。
28.3 ARMA和ARIMA模型
考虑ARMA(p,q)模型,
取r=max(p,q+1),
则模型可以写成
yt=∑j=1rϕjyt−j+ζt+∑j=1r−1θjζt−j,
其中某些系数可以为0。
将此模型写成状态空间模型形式,
有多种不同形式,
这里给出一种形式比较复杂但计算方便的表达形式:
αt=yt=αt+1=⎛⎝⎜⎜⎜⎜⎜⎜ytϕ2yt−1+⋯+ϕryt−(r−1)ϕ3yt−1+⋯+ϕryt−(r−2)⋮ϕryt−1+θ1ζt+⋯+θr−1ζt−(r−2)+θ2ζt+⋯+θr−1ζt−(r−3)⋮+θr−1ζt⎞⎠⎟⎟⎟⎟⎟⎟(1,0,0,…,0)αt⎛⎝⎜⎜⎜⎜⎜⎜ϕ1ϕ2⋮ϕr−1ϕr10⋮000100⋯⋯⋱⋯⋯00⋮10⎞⎠⎟⎟⎟⎟⎟⎟αt+⎛⎝⎜⎜⎜⎜⎜⎜1θ1θ2⋮θr−1⎞⎠⎟⎟⎟⎟⎟⎟ζt+1.
对一个ARIMA(2,1,1),
模型
y∗t=y∗t=yt−yt−1,ϕ1y∗t−1+ϕ2y∗t−2+ζt+θ1ζt−1,
可以写成
αt=yt=αt+1=⎛⎝⎜⎜⎜yt−1y∗tϕ2y∗t−1+θ1ζt⎞⎠⎟⎟⎟(1,1,0)αt⎛⎝⎜⎜1001ϕ1ϕ2010⎞⎠⎟⎟αt+⎛⎝⎜⎜01θ1⎞⎠⎟⎟ζt+1
观测方程没有观测误差。
更一般的ARIMA以及带有乘性季节部分的ARIMA都可以类似表示。
将ARIMA模型表示成状态空间模型以后,
好处是状态空间模型的一系列工具都可以用在ARIMA的模型推断中,
比如SSM的精确最大似然估计和初始化方法都可以使用。
现在的估计ARIMA模型的软件中许多都是利用状态空间模型形式进行估计和推断。
反过来,
许多状态空间模型的观测值也服从ARIMA模型,
比如局部趋势模型,
带有斜率项的局部趋势模型等,
加入了季节项的结构时间序列模型等。
但是,结构时间序列模型转换成ARIMA模型会丢失一些有可解释含义的信息。
状态空间模型的优点:
- 状态空间模型更灵活,
能够将随着时间增加的已知的机制变化添加到模型中,
而ARIMA则很难修改; - 容易处理缺失值;
- 很容易增加额外的解释变量,
有回归自变量时允许回归系数为时变系数,
很容易进行日历调整; - 预测不需要单独的理论;
- 不要求平稳或者差分后平稳。
另一方面,
ARIMA模型则无法将趋势成分、季节项成分提取出来,
要求差分后平稳,
而经济和金融中许多数据是差分后也不平稳的。
例28.3 考虑太阳黑子数的ARMA建模。
数据为1700-1988的年数据。
数据:
library(datasets)
ts.ss <- window(sunspot.year, start = 1770, end = 1869)
plot(ts.ss)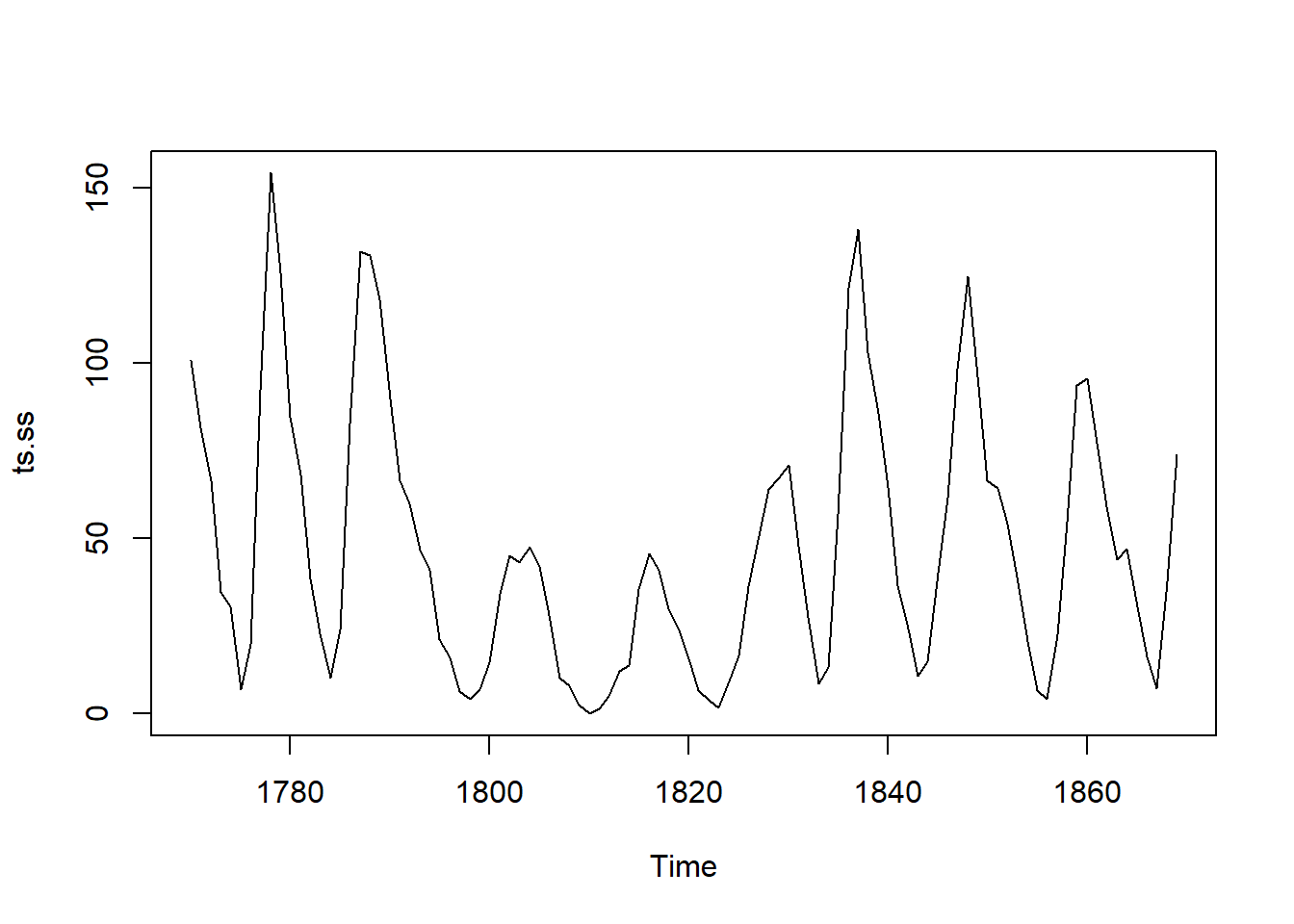
可以看出,数据有周期性。
用R的arima函数建立AR(3)模型:
ss1 <- arima(
ts.ss, order=c(3,0,0))
ss1##
## Call:
## arima(x = ts.ss, order = c(3, 0, 0))
##
## Coefficients:
## ar1 ar2 ar3 intercept
## 1.5471 -0.9915 0.2004 48.5119
## s.e. 0.0983 0.1545 0.0990 6.0560
##
## sigma^2 estimated as 220.2: log likelihood = -412.94, aic = 835.88估计的模型为
(1−1.5471B+0.9915B2−0.2004B3)(yt−48.5119)=et, et∼WN(0,220.2).
模型诊断:
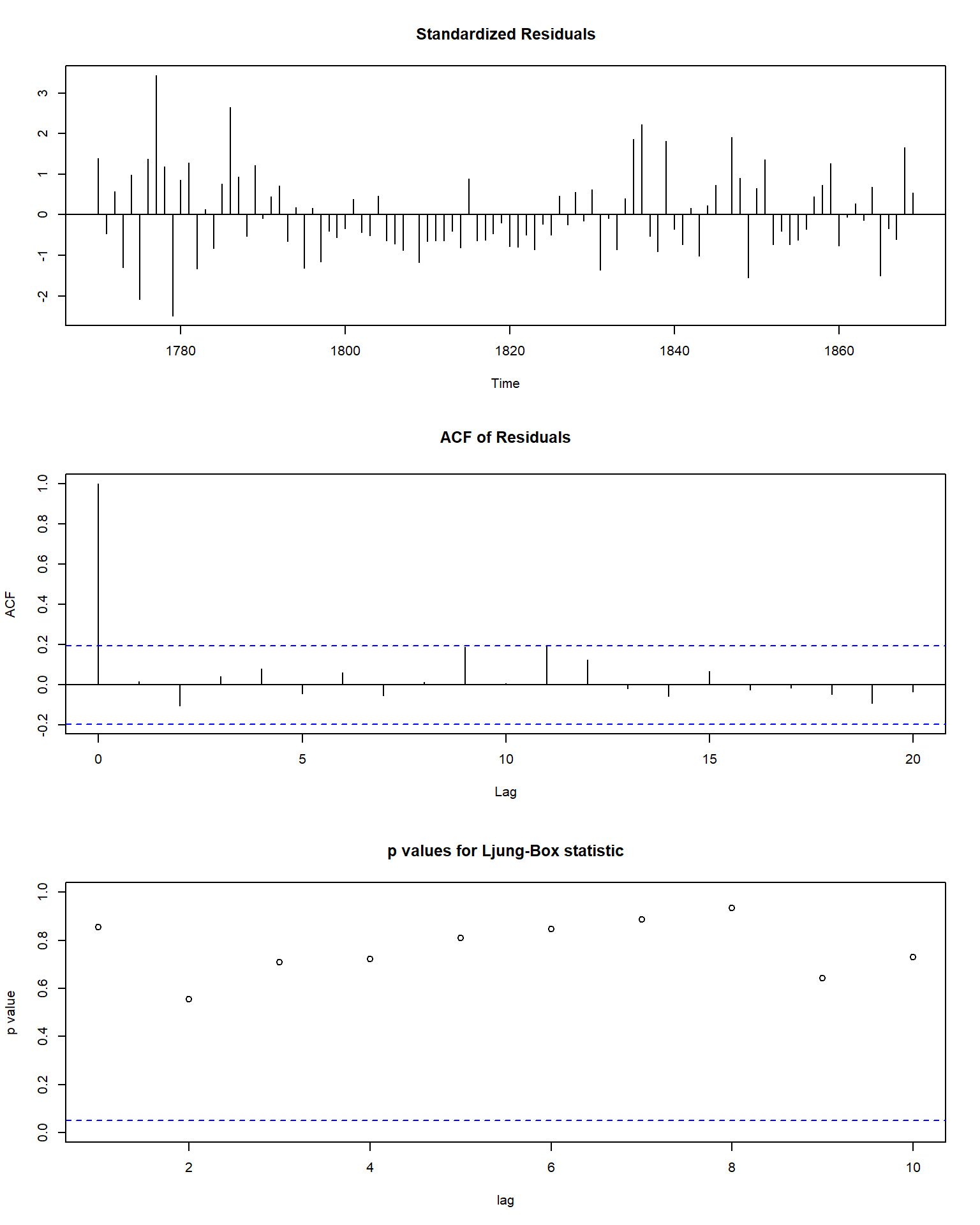
从模型诊断看是合适的。
估计的AR(3)中特征多项式的根和复根对应的周期:
rt1 <- polyroot(c(1, -coef(ss1)[1:3])); rt1## [1] 1.045502+0.808659i 1.045502-0.808659i 2.855749-0.000000i## [1] 4.753712求出的周期与实际观察到的大约11年周期不符。
用statespacer包将AR(3)估计成状态空间模型,
此包直接支持恢复ARIMA参数:
library(datasets)
library(statespacer)
mat.suns <- matrix(window(
sunspot.year, start = 1770, end = 1869))
fit <- statespacer(
y = mat.suns,
H_format = matrix(0),
# H是观测方程的误差方差阵
local_level_ind = TRUE,
arima_list = list(c(3,0,0)),
format_level = matrix(0),
# format_level是结构时间序列模型中水平值$\mu_t$的方程的误差方差阵
initial = c(0.5*log(var(mat.suns)), 0, 0, 0),
verbose=TRUE)## Starting the optimisation procedure at: 2023-05-26 09:26:40## initial value 5.022561
## iter 10 value 4.114363
## final value 4.111163
## converged## Finished the optimisation procedure at: 2023-05-26 09:26:40## Time difference of 0.0616450309753418 secs构造ARMA的结果:
arma_coeff <- rbind(
fit$system_matrices$AR$ARIMA1,
fit$standard_errors$AR$ARIMA1
)
arma_coeff <- cbind(
arma_coeff,
c(fit$smoothed$level[1],
sqrt(fit$system_matrices$Z_padded$level %*%
fit$smoothed$V[,,1] %*%
t(fit$system_matrices$Z_padded$level))
)
)
rownames(arma_coeff) <- c("coefficient", "std_error")
colnames(arma_coeff) <- c("ar1", "ar2", "ar3", "intercept")
arma_coeff## ar1 ar2 ar3 intercept
## coefficient 1.55976415 -1.005462 0.2129622 48.605905
## std_error 0.09962468 0.155982 0.1003591 6.358039与arima()函数结果相近但不完全相同。
例28.4 考虑航空乘客数的建模,1949-1961年的月度数据,
用ARIMA(0,1,1)(0,1,1)12模型。
将数据取自然对数,
用arima()建模:
ap01 <- arima(
log(AirPassengers),
order=c(0,1,1),
seasonal=list(order=c(0,1,1), frequency=12))
ap01##
## Call:
## arima(x = log(AirPassengers), order = c(0, 1, 1), seasonal = list(order = c(0,
## 1, 1), frequency = 12))
##
## Coefficients:
## ma1 sma1
## -0.4018 -0.5569
## s.e. 0.0896 0.0731
##
## sigma^2 estimated as 0.001348: log likelihood = 244.7, aic = -483.4模型为:
(1−B)(1−B12)lnyt=(1−0.4018B)(1−0.5569B12)et, et∼WN(0,0.001348).
利用statespacer计算:
mat.ap <- matrix(log(AirPassengers))
# 模型设定列表
sarima_list <- list(list(
s = c(12, 1), ar = c(0, 0), i = c(1, 1), ma = c(1, 1) ))
# 拟合模型
fit <- statespacer(
y = mat.ap,
H_format = matrix(0),
sarima_list = sarima_list,
initial = c(0.5*log(var(diff(mat.ap))), 0, 0),
verbose = TRUE)## Starting the optimisation procedure at: 2023-05-26 09:26:40## initial value -1.034434
## final value -1.616321
## converged## Finished the optimisation procedure at: 2023-05-26 09:26:41## Time difference of 0.461006164550781 secs提前估计的参数:
arma_coeff <- rbind(
c(fit$system_matrices$SMA$SARIMA1$S1,
fit$system_matrices$SMA$SARIMA1$S12),
c(fit$standard_errors$SMA$SARIMA1$S1,
fit$standard_errors$SMA$SARIMA1$S12) )
rownames(arma_coeff) <- c("coefficient", "std_error")
colnames(arma_coeff) <- c("ma1 s = 1", "ma1 s = 12")
arma_coeff## ma1 s = 1 ma1 s = 12
## coefficient -0.40188859 -0.55694248
## std_error 0.08963614 0.07309788goodness_fit <- rbind(
fit$system_matrices$Q$SARIMA1,
fit$diagnostics$loglik,
fit$diagnostics$AIC
)
rownames(goodness_fit) <- c("Variance", "Loglikelihood", "AIC")
goodness_fit## [,1]
## Variance 0.001347882
## Loglikelihood 232.750284785
## AIC -3.010420622结果与arima()结果相同。
28.4 回归模型
28.4.1 常系数回归模型
考虑回归模型
yt=Xtβ+et, et∼ iid N(0,Ht), t=1,2,…,n,
其中Xt为1×k非随机的已知值,
β是k×1未知的回归系数向量。
可以写成状态空间模型:
αt=αt+1=yt=β,Iαt,Xtαt+et.
状态方程没有误差。
这个回归问题的加权最小二乘解为
β̂ =(∑i=1nXTtH−1tXt)−1∑i=1nXTtH−1tyt.
写成状态空间模型后,
用滤波算法对αt=β进行估计,
等价于对β进行递推改进估计,
相当于递推的最小二乘估计。
28.4.2 变系数回归模型
考虑变系数的回归模型
yt=Xtβt+et, et∼ iid N(0,Ht), t=1,2,…,n,
其中的随时间而变化的回归系数可以用如下的随机游动建模:
βt+1=βt+ηt,
这样,以βt为状态向量,
就可以将变系数回归模型写成简单的状态空间形式:
yt=βt+1=Xtβt+et,Iβt+Iηt.
这样的模型可以用标准的状态空间模型工具进行估计和推断。
28.4.3 带有ARMA误差的回归模型
设
yt=Xtβ+ξt,
ξt服从ARMA模型,
可以写成状态空间形式,
状态方程为
αt+1=Tαt+Rηt,
则yt可以写成状态空间模型形式,
状态变量为α∗t,
模型为
α∗t=yt=α∗t+1=(βαt),(Xt,1,0,…,0)α∗t,(Ik00T)α∗t+(0R)ηt,
可以用状态空间模型的工具进行估计和推断。
28.4.4 Seatbelts数据建模
R的datasets包的Seatbelts数据是一个多元时间序列,
为月度数据,
保存了英国1969年到1984年与道路交通事故有关的数据。
分量含义:
- DriversKilled: 小汽车交通事故死亡人数。
- drivers: 小汽车交通事故死亡以及重伤人数。
- front: 前排驾乘人员死亡和重伤人数。
- rear: 后排乘客死亡和重伤人数。
- kms: 已行驶里程。
- PetroPrice: 汽油价格。
- VanKilled: 小型厢式载货汽车司机死亡人数。
- law: 强制安全带法律是否已实施的0-1变量,从1983-01-31起实行。
28.4.4.1 数据预处理
因为取正值的变量建模时比较受限制,
所以将这些变量取对数值。
library(statespacer)
library(datasets)
da <- as.xts(Seatbelts) |> coredata()
for(v in c("drivers", "front", "rear", "PetrolPrice", "kms"))
da[, v] <- log(da[,v])28.4.4.2 确定性水平和季节项、有回归自变量的一元模型
以小汽车交通事故死亡、重伤人数(对数值)为因变量。
以汽油价格(对数值)和是否实行了安全带法令为自变量。
模型为
yt=μt+1=γt+1=μt+γt+β1x1t+β2x2t+et,μt,−∑j=111γt+1−j.
y <- cbind(da[,"drivers"])
ssmr1 <- statespacer(
y = y, # 因变量
local_level_ind = TRUE, # 是否有局部水平项
# 设置局部水平项误差方差为零,从而非随机:
format_level = matrix(0),
BSM_vec = 12, # 季节项的周期
# 设置季节项误差项方差为零,从而非随机:
format_BSM_list = list(matrix(0)),
# 添加的外生自变量,每个因变量分量需要输入一个自变量矩阵,
# 所以即使是一元因变量也需要用列表
addvar_list = list(as.matrix(
da[, c("PetrolPrice", "law")])),
method = "BFGS",
# 唯一的方差参数$\sigma_e^2$的初值,
# 算法中使用其对数值的2倍以确保取正值
initial = 0.5 * log(var(c(y))),
verbose = TRUE)## Starting the optimisation procedure at: 2023-05-26 09:26:42## initial value -0.443442
## final value -0.735372
## converged## Finished the optimisation procedure at: 2023-05-26 09:26:42## Time difference of 0.0513920783996582 secs观测误差方差σ2e估计:
ssmr1$system_matrices$H$H[1,1]## [1] 0.007402481非随机的局部水平μ的平滑估计:
ssmr1$smoothed$level[1,1]## [1] 6.401571第一个自变量,即汽油价格对数值,的回归系数:
ssmr1$smoothed$addvar_coeff[1, 1]## [1] -0.4521301第二个自变量,即强制安全带法令是否实行,的回归系数,
和相应标准误差估计,
t统计量值:
c(coef = ssmr1$smoothed$addvar_coeff[1, 2],
se = ssmr1$smoothed$addvar_coeff_se[1, 2],
tstat = ssmr1$smoothed$addvar_coeff[1, 2] /
ssmr1$smoothed$addvar_coeff_se[1, 2])## coef se tstat
## -0.19713947 0.02072792 -9.51081922由此计算的法令影响的t统计量低于−2,
在0.05水平下显著,
认为法令生效后水平伤亡水平显著降低。
下面将原始数据与平滑拟合结果(包括局部水平、季节项与自变量作用)作图:
plot(da[, c("drivers")], type = "l", ylim = c(6.95, 8.1),
xlab = "year", ylab = "logarithm of drivers")
lines(seq(tsp(Seatbelts)[1], tsp(Seatbelts)[2], 1/tsp(Seatbelts)[3]),
ssmr1$smoothed$level
+ ssmr1$smoothed$BSM12
+ ssmr1$smoothed$addvar,
type = 'l', col = "red")
legend("topright",
c("log(drivers)", "Smoothed fit"),
lty = c(1,1), lwd=c(2.5, 2.5), col = c("black", "red"))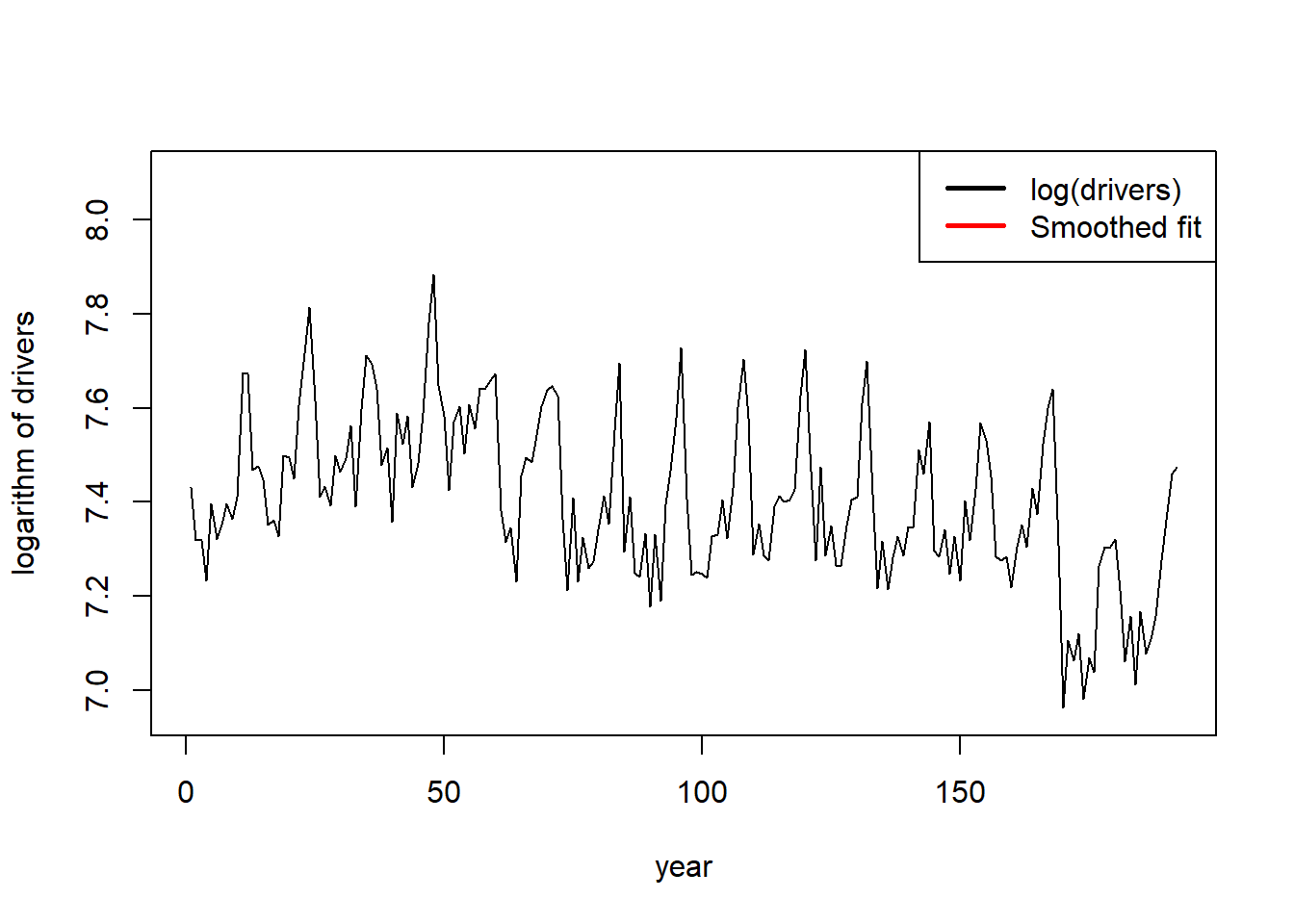
28.4.4.3 随机水平和季节项、有回归自变量的一元模型
模型为
yt=μt+1=γt+1=μt+γt+β1x1t+β2x2t+et,μt+ηt,−∑j=111γt+1−j+ζt.
和确定性的μ, γt相比,
程序只需将零方差改为非零方差:
y <- cbind(da[,"drivers"])
ssmr2 <- statespacer(
y = y, # 因变量
local_level_ind = TRUE, # 是否有局部水平项
# 设置局部水平项误差方差为非零,从而随机:
format_level = matrix(1),
BSM_vec = 12, # 季节项的周期
# 设置季节项误差项方差为零,从而随机:
format_BSM_list = list(matrix(1)),
# 添加的外生自变量,每个因变量分量需要输入一个自变量矩阵,
# 所以即使是一元因变量也需要用列表
addvar_list = list(as.matrix(da[, c("PetrolPrice", "law")])),
method = "BFGS",
# 唯一的方差参数$\sigma_e^2$的初值,
# 算法中使用其对数值的2倍以确保取正值
initial = log(var(as.vector(y))),
verbose = TRUE)## Warning: Number of initial parameters is less than the required amount of
## parameters (3), recycling the initial parameters the required amount of times.## Starting the optimisation procedure at: 2023-05-26 09:26:42## initial value -0.172423
## iter 10 value -0.893962
## iter 20 value -0.915493
## iter 30 value -0.915515
## final value -0.915517
## converged## Finished the optimisation procedure at: 2023-05-26 09:26:43## Time difference of 0.770241975784302 secs程序中还修改了原来的迭代初值,
原来的迭代初值导致迭代过程出错。
初值需要三个方差参数对应的初值,
这里只给了一个初值,
就重复利用。
估计结果:
## 观测误差方差估计
ssmr2$system_matrices$H$H[1,1]## [1] 0.003786183## 局部水平的系统方程的误差方差估计
ssmr2$system_matrices$Q$level[1,1]## [1] 0.0002676875## 季节项的系统方程的误差方差估计
ssmr2$system_matrices$Q$BSM12[1,1]## [1] 1.161438e-06## 关于汽油价格对数值这一自变量的回归系数估计
ssmr2$smoothed$addvar_coeff[1, 1]## [1] -0.2913944第二个自变量,即强制安全带法令是否实行,的回归系数,
和相应标准误差估计,
t统计量值:
c(coef = ssmr2$smoothed$addvar_coeff[1, 2],
se = ssmr2$smoothed$addvar_coeff_se[1, 2],
tstat = ssmr2$smoothed$addvar_coeff[1, 2] /
ssmr2$smoothed$addvar_coeff_se[1, 2])## coef se tstat
## -0.23773735 0.04631717 -5.13281209结果表明法令生效后伤亡水平显著降低。
原始数据与拟合结果(拟合结果是平滑结果,
利用了平滑的局部水平与自变量线性组合):
plot(da[, c("drivers")], type = "l", ylim = c(6.95, 8.1),
xlab = "year", ylab = "logarithm of drivers")
lines(seq(tsp(Seatbelts)[1], tsp(Seatbelts)[2], 1/tsp(Seatbelts)[3]),
ssmr2$smoothed$level
+ ssmr2$smoothed$BSM12
+ ssmr2$smoothed$addvar,
type = 'l', col = "red")
legend("topright",
c("log(drivers)", "smoothed fit"),
lty = c(1,1), lwd=c(2.5, 2.5), col = c("black", "red"))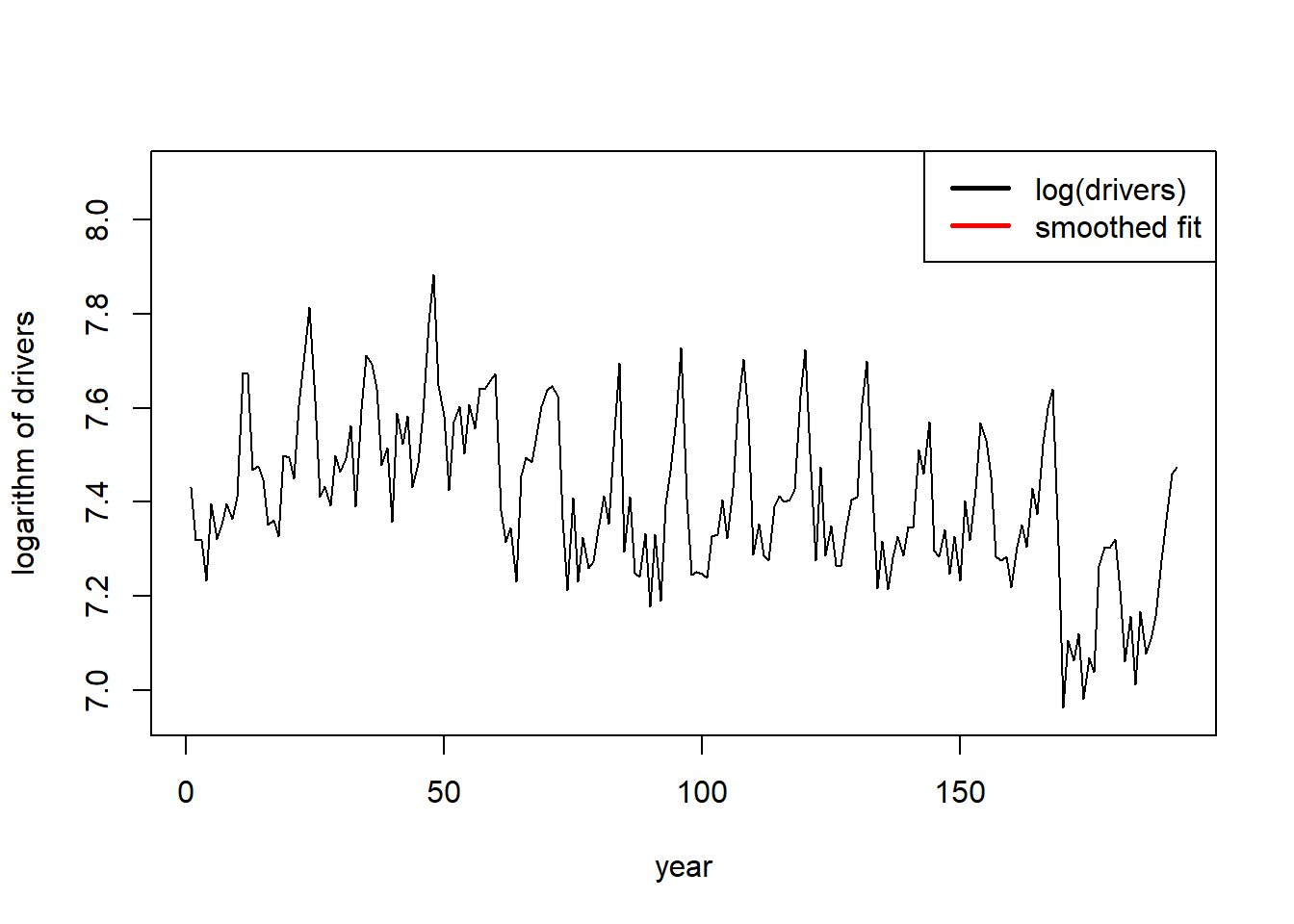
与非随机的水平和季节项的拟合结果比较,
随机的水平和季节项使得拟合结果更贴近原始数据。
实际上,从季节项的系统方程的误差方差10−6级别可以看出季节项的随机性很小,
下面作平滑估计的季节项图形:
plot(seq(tsp(Seatbelts)[1], tsp(Seatbelts)[2], 1/tsp(Seatbelts)[3]),
ssmr2$smoothed$BSM12,
type = "l", ylim = c(-0.2, 0.3),
xlab = "year", ylab = "stochastic seasonal")
abline(h = 0)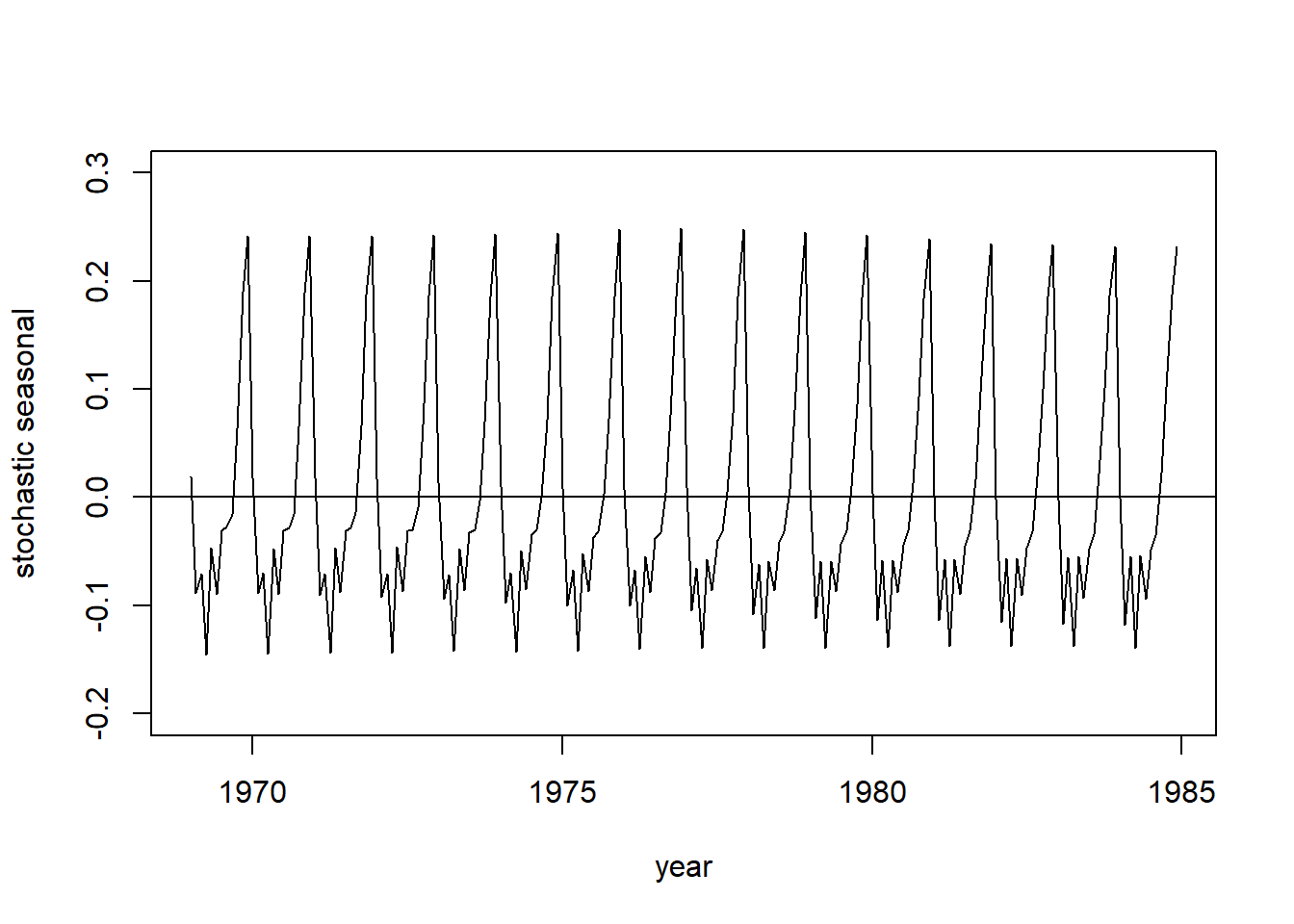
我们将随机的季节项改为非随机:
y <- cbind(da[,"drivers"])
ssmr3 <- statespacer(
y = y, # 因变量
local_level_ind = TRUE, # 是否有局部水平项
# 设置局部水平项误差方差为非零,从而随机:
format_level = matrix(1),
BSM_vec = 12, # 季节项的周期
# 设置季节项误差项方差为零,从而非随机:
format_BSM_list = list(matrix(0)),
# 添加的外生自变量,每个因变量分量需要输入一个自变量矩阵,
# 所以即使是一元因变量也需要用列表
addvar_list = list(as.matrix(
da[, c("PetrolPrice", "law")])),
method = "BFGS",
# 唯一的方差参数$\sigma_e^2$的初值,
# 算法中使用其对数值的2倍以确保取正值
initial = log(var(c(y))),
verbose = TRUE)## Warning: Number of initial parameters is less than the required amount of
## parameters (2), recycling the initial parameters the required amount of times.## Starting the optimisation procedure at: 2023-05-26 09:26:44## initial value -0.577129
## iter 10 value -0.912856
## final value -0.912859
## converged## Finished the optimisation procedure at: 2023-05-26 09:26:44## Time difference of 0.247884035110474 secs估计结果:
## 观测误差方差估计
ssmr3$system_matrices$H$H[1,1]## [1] 0.004033516## 局部水平的系统方程的误差方差估计
ssmr3$system_matrices$Q$level[1,1]## [1] 0.0002681651## 关于汽油价格对数值这一自变量的回归系数估计
ssmr3$smoothed$addvar_coeff[1, 1]## [1] -0.2767301第二个自变量,即强制安全带法令是否实行,的回归系数,
和相应标准误差估计,
t统计量值:
c(coef = ssmr3$smoothed$addvar_coeff[1, 2],
se = ssmr3$smoothed$addvar_coeff_se[1, 2],
tstat = ssmr3$smoothed$addvar_coeff[1, 2] /
ssmr3$smoothed$addvar_coeff_se[1, 2])## coef se tstat
## -0.2375904 0.0464483 -5.1151578结果表明法令生效后伤亡水平显著降低。
比较三个模型的AIC:
c(ssmr1$diagnostics$AIC,
ssmr2$diagnostics$AIC,
ssmr3$diagnostics$AIC)## [1] -1.314494 -1.653950 -1.659052第三个模型的AIC最小。
28.4.4.4 前后座驾乘人员同时建模的二元模型
考虑前座驾乘人员和后座乘客死亡、重伤人数对数的二元模型,
都以汽油价格对数值、行驶里程对数值和安全带法令为自变量。
y <- da[,c("front", "rear")]
Xmat <- da[,c("PetrolPrice", "kms", "law")]
ssmr4 <- statespacer(y = y, # 输入数据是两列矩阵,二元时间序列
# 观测方程误差项方差阵格式,这里是无限制的二阶方差阵
H_format = matrix(1,2,2),
local_level_ind = TRUE,
# 局部水平的系统方程的误差项方差设置,无限制:
format_level = matrix(1, 2, 2),
BSM_vec = 12,
# 季节项的系统方程的误差项方差设置,设置为零,表示非随机季节项
format_BSM_list = list(matrix(0, 2, 2)),
# 每个因变量所需的自变量矩阵:
addvar_list = list(Xmat, Xmat),
method = "BFGS",
initial = 0.5 * log(diag(var(y))),
verbose = TRUE)## Warning: Number of initial parameters is less than the required amount of
## parameters (6), recycling the initial parameters the required amount of times.## Starting the optimisation procedure at: 2023-05-26 09:26:45## initial value 0.389588
## iter 10 value -1.583525
## iter 20 value -1.676129
## iter 30 value -1.676530
## final value -1.676537
## converged## Finished the optimisation procedure at: 2023-05-26 09:26:56## Time difference of 11.4353930950165 secs观测方程误差方差阵估计:
ssmr4$system_matrices$H$H## [,1] [,2]
## [1,] 0.005402166 0.004449533
## [2,] 0.004449533 0.008566858局部水平的系统方程的误差方差阵估计:
ssmr4$system_matrices$Q$level## [,1] [,2]
## [1,] 0.0002556392 0.0002247045
## [2,] 0.0002247045 0.00023195616个回归系数及相应的t统计量:
data.frame(
x1 = c("front PetrolPrice", "front kms", "front law",
"rear PetrolPrice", "rear kms", "rear law"),
x2 = ssmr4$smoothed$addvar_coeff[1,],
x3 = ssmr4$smoothed$addvar_coeff[1,]
/ ssmr4$smoothed$addvar_coeff_se[1,]) |>
knitr::kable(
col.names=c("", "Coef", "t stat"),
digits=4 )| Coef | t stat | |
|---|---|---|
| front PetrolPrice | -0.3076 | -2.8986 |
| front kms | 0.1518 | 1.1678 |
| front law | -0.3370 | -6.8466 |
| rear PetrolPrice | -0.0858 | -0.7639 |
| rear kms | 0.5504 | 3.7927 |
| rear law | 0.0009 | 0.0171 |
与常识一致的是,
后排乘客的伤亡数并不受安全带法令的影响。
汽油价格上升对前排驾乘人员伤亡数有抑制作用。
行驶里程数对前排驾乘人员伤亡数没有显著影响,
但对后排乘客伤亡有正向的影响。
程序中还可以限制某个方差阵的秩,
比如取format_level为
(1100)
可以限制水平的系统方差的误差方差阵(2×2方差阵)为秩等于1。
28.4.5 动态Nelson-Siegel模型
考虑如下的关于利率期限结构的动态Nelson-Siegel模型:
yt(τ)=β1t+β2t(1−e−λτλτ)+β3t(1−e−λτλτ−e−λτ)+et(τ),τ=3,6,12,24,36,60,84,120, t=1,2,…,n.
其中λ是未知参数,
τ是贷款期限,
yt(τ)是t时刻期限为τ的贷款利息。
设各et(τ)相互独立,
服从N(0,σ2e);
β1t, β2t, β3t是时变的回归系数,
设其服从一阶向量自回归模型:
βt+1=(I−Φ)μ+Φβt+ηt,
其中βt=(β1t,β2t,β3t)T,
μ为βt的均值,
Φ为3×3的回归系数矩阵,
设ηt∼N(0,Ση),
β1∼N(μ,Pβ),
初始分布中的Pβ也满足平稳性条件
Pβ−ΦPβΦT=Ση.
因为对每个t有8个不同的τ对应的观测值yt(τ),
将这8个观测值写成一个8×1观测值向量yt。
对包含期望值μ的VAR(1)模型,
可转换成如下的状态方程:
αt=(βt+1μ)=(βtμ),(Φ0I−ΦI)(βtμ)+(I0)ηt, ηt∼N(0,Ση).
令τ=(3,6,12,24,36,60,84,120)T,
观测方程可以写成
yt=(Z(1)08×3)αt+et, et∼N(0,σ2eI8),
其中Z(1)是8×3矩阵,
第一列元素都等于1,
第二列元素为各1−e−λτλτ值,
第三列元素为各1−e−λτλτ−e−λτ值。
这样将DNS(动态Nelson-Siegel)模型写成了状态空间形式,
可以用statespacer包进行估计和平滑。
如果不用状态空间模型方法,
可以先对每个t的8个观测回归得到3个系数在t时刻的估计值,
然后再对估计的βjt建模,
这样的做法不能充分利用模型结构。
statespacer包对于ARIMA、结构时间序列模型都有一些方便的模型参数规定方式和输出方式,
对于更一般的模型就需要用户指定需要各个矩阵和初始值。
示例所用的数据是YieldCurve扩展包中的FedYieldCurve数据集。
取1984-12-31到2000-12-01的数据子集。
数据是192×8矩阵,
有192天(对应t),8个期限(对应τ)。
library(statespacer)
library(YieldCurve, quietly=TRUE, warn.conflicts=FALSE)## Warning: package 'YieldCurve' was built under R version 4.2.3data(FedYieldCurve)
str(FedYieldCurve)## An 'xts' object on 1981-12-31/2012-11-30 containing:
## Data: num [1:372, 1:8] 12.9 14.3 13.3 13.3 12.7 ...
## - attr(*, "dimnames")=List of 2
## ..$ : NULL
## ..$ : chr [1:8] "R_3M" "R_6M" "R_1Y" "R_2Y" ...
## Indexed by objects of class: [Date] TZ:
## xts Attributes:
## NULLxts.yc <- FedYieldCurve["1984-12-31/2000-12-01"]
date.yc <- index(xts.yc)
y.yc <- coredata(xts.yc)
plot(xts.yc, multi.panel=FALSE)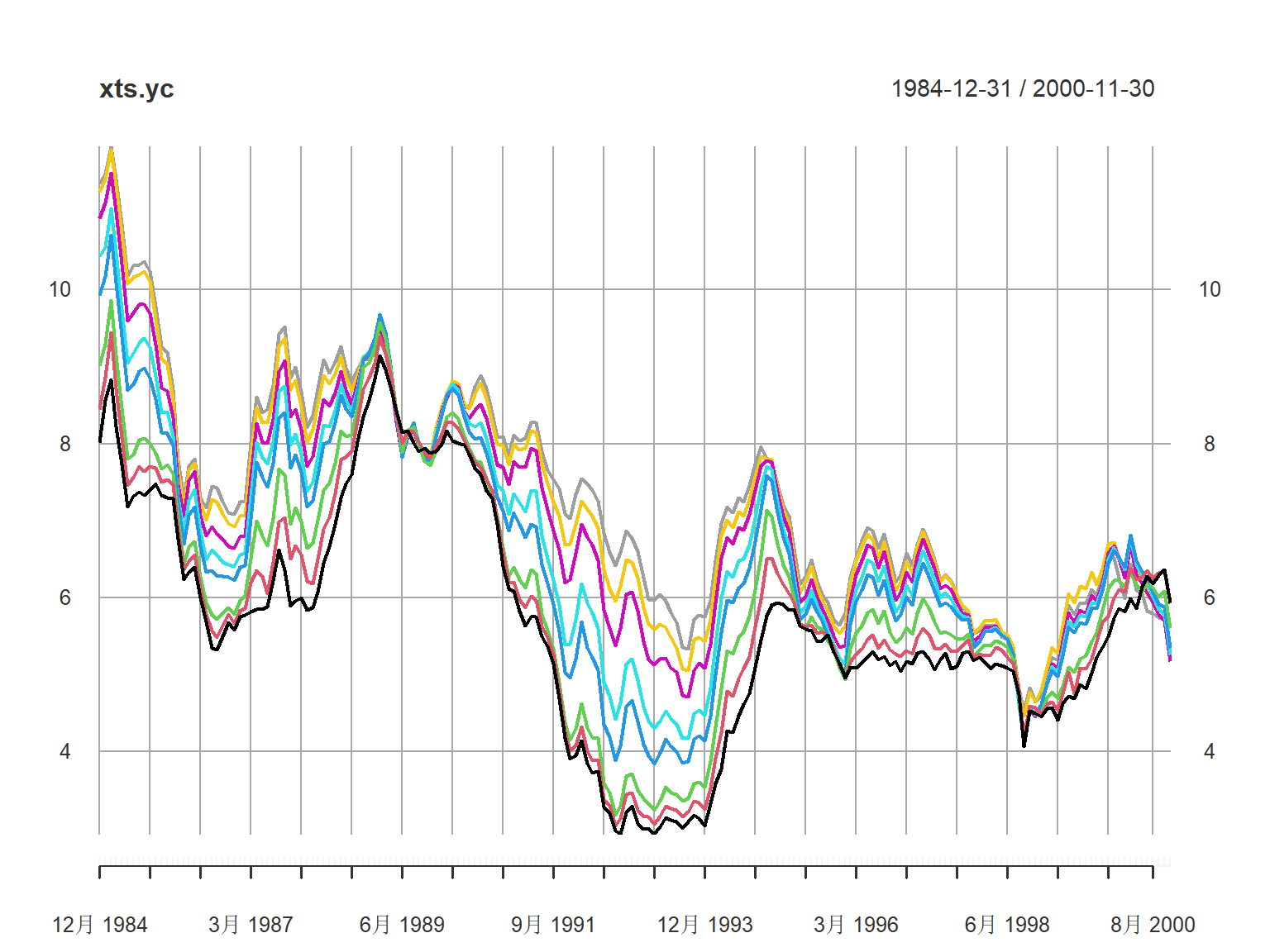
需要自己指定模型的各个矩阵和初值。
## 保存自定义设置用的列表
spec <- list()
## 自己规定H矩阵(观测误差的方差阵)
spec$H_spec <- TRUE
## 状态向量维数,3个beta, 3个常数beta均值
spec$state_num <- 6
## 待估参数个数20个,包括:
## 1个 - $\lambda$
## 1个 - $\sigma_e^2$
## 6个 - $\Sigma_{\boldsymbol\eta}\ 3 \times 3$对称阵
## 9个 - $\Phi_{3\times 3}$矩阵
## 3个 - $\boldsymbol\mu$
spec$param_num <- 20
## 状态方程中$R$矩阵不起作用,方差结构直接编写在矩阵$Q$中
spec$R <- diag(1, 6, 6) # $I_6$
## 初始状态$\boldsymbol\alpha_1$的方差,元素都取为0,因为平稳
spec$P_inf <- matrix(0, 6, 6)
## 指定状态向量中不输出到观测的分量,
## 当压缩观测向量为标量时可提高计算效率
spec$state_only <- 4:6模型要估计的参数(超参数)为λ,
σ2e,
对称的(Ση)3×3,
Φ3×3,
μ3×1。
对于必须取正值的参数,
将其迭代计算的参数取自然对数后除以2。
对于要求正定的Ση,
将其做Cholesky分解LDLT,
其中D是对角元素为正值的对角阵,
L是对角元素都等于1的下三角阵,
用D和L的6个元素来作为待估参数。
statespacer提供了Cholesky函数将这样编码的参数转换成正定矩阵。
对向量自回归系数矩阵Φ,
要求其满足平稳性条件,
statespacer包的CoeffARMA()函数用来改造输入的系数矩阵使其满足条件。
因为模型的各个重要矩阵、初始值等都需要编程计算而不是常数值,
所以将自定义设定的sys_mat_fun元素设置为一个自定义函数:
spec$sys_mat_fun <- function(param) {
## 输入20个参数,具体意义见前面注释和说明
# 8个期限,即$\tau$值
maturity <- c(3, 6, 12, 24, 36, 60, 84, 120)
# 从取了对数的参数值恢复$\lamabda$的值
lambda <- exp(2 * param[1])
# \sigma_e^2的值
sigma2 <- exp(2 * param[2])
# H是观测方程的误差向量的协方差阵参数。
# 注意每个$t$对应的观测值是$8\times 1$向量。
H <- sigma2 * diag(1, 8, 8)
# 观测方程的Z矩阵,一个$8 \times 6$矩阵,
# 前三列对应于$\beta_{1t}$, $\beta_{2t}$, $\beta_{3t}$
# 后三列对应于$\beta$的三个均值,系数为0
lambda_maturity <- lambda * maturity
ze <- exp(-lambda_maturity)
Z <- matrix(1, 8, 3)
Z[, 2] <- (1 - ze) / lambda_maturity
Z[, 3] <- Z[, 2] - ze
# 状态方程的误差方差阵($6 \times 6$)的左上角$3 \times 3$部分
# 使用6个参数
Q <- Cholesky(
param = param[3:8],
decompositions = FALSE,
format = matrix(1, 3, 3))
# 从输入的9个矩阵元素生成满足平稳性条件的向量自回归系数矩阵$\Phi$
Tmat <- CoeffARMA(
A = array(param[9:17], dim = c(3, 3, 1)),
variance = Q,
ar = 1, ma = 0)$ar[,,1]
# 生成初始状态$\boldsymbol\alpha_1$的方差阵,确保其满足平稳性条件
T_kronecker <- kronecker(Tmat, Tmat)
Tinv <- solve(
diag(1, dim(T_kronecker)[1],
dim(T_kronecker)[2]) - T_kronecker)
vecQ <- matrix(Q)
vecPstar <- Tinv %*% vecQ
P_star <- matrix(vecPstar, dim(Tmat)[1], dim(Tmat)[2])
## 添加对应于常数均值的部分
# 在观测方程的矩阵Z中增加对应于常数均值的3列
Z <- cbind(Z, matrix(0, 8, 3))
# 在状态方程的误差方差阵中增加对应于常数均值的部分,都是0
Q <- BlockMatrix(Q, matrix(0, 3, 3))
# 在6维的状态方程中,设置转移矩阵$T$
Tmat <- cbind(Tmat, diag(1, 3, 3) - Tmat)
Tmat <- rbind(Tmat, cbind(matrix(0, 3, 3), diag(1, 3, 3)))
# 初始状态的方差阵中对应于常数均值部分方差和协方差为0
P_star <- BlockMatrix(P_star, matrix(0, 3, 3))
# $\beta$的均值是最后的3个待估参数,
# 也作为$t=1$时$\beta$的初始分布均值
a1 <- matrix(param[18:20], 6, 1)
# 函数返回模型所需的所有系统矩阵
return(list(
H = H, # 观测误差随机向量的方差阵
Z = Z, # 观测方程的观测矩阵
Tmat = Tmat, # 状态方程的状态转移矩阵
Q = Q, # 状态方程的误差随机向量的方差阵
a1 = a1, # 初始状态的均值
P_star = P_star)) # 初始状态的方差阵
}为了从估计的参数(超参数)提取某些成分,
可以提供一个transform_fun函数:
spec$transform_fun <- function(param) {
lambda <- exp(2 * param[1])
sigma2 <- exp(2 * param[2])
means <- param[18:20]
return(c(lambda, sigma2, means))
}下面给20个参数设置算法迭代初值:
initial <- c(
-1, # $0.5 \ln\lambda$
-2, # $0.5 \ln\sigma_e^2$
# $\Sigma_{\boldsymbol\eta}$的LDL分解中D的对角元素的0.5倍对数值
-1, -1, -1,
# $\Sigma_{\boldsymbol\eta}$的LDL分解中L的元素值
0, 0, 0,
# VAR(1)模型系数矩阵
1, 0, 0,
0, 1, 0,
0, 0, 1,
# 三个beta的均值
0, 0, 0) fit <- statespacer(
y = y.yc,
self_spec_list = spec,
collapse = TRUE,
initial = initial,
method = "BFGS",
control = list(maxit = 200),
verbose = TRUE)## Starting the optimisation procedure at: 2023-05-26 09:27:02## initial value 18.089728
## iter 10 value -6.160531
## iter 20 value -6.760946
## iter 30 value -6.953583
## iter 40 value -6.990606
## iter 50 value -6.996315
## iter 60 value -6.999004
## iter 70 value -7.002370
## iter 80 value -7.004278
## iter 90 value -7.005021
## iter 100 value -7.005174
## iter 110 value -7.005240
## iter 120 value -7.005375
## iter 130 value -7.005400
## iter 140 value -7.005430
## iter 150 value -7.005440
## iter 160 value -7.005462
## final value -7.005470
## converged## Finished the optimisation procedure at: 2023-05-26 09:27:16## Time difference of 13.7717099189758 secs算法有可能在中间因矩阵不可逆而中断,
这时可以修改初值。
模型估计一次需要大约半分钟。
将计算系统矩阵的函数改写为C++版本可能会加快速度。
平滑得到的β1t的时间序列图形:
plot(date.yc, fit$smoothed$a[, 1], type = 'l',
xlab = "year", ylab = "Level of yield curve")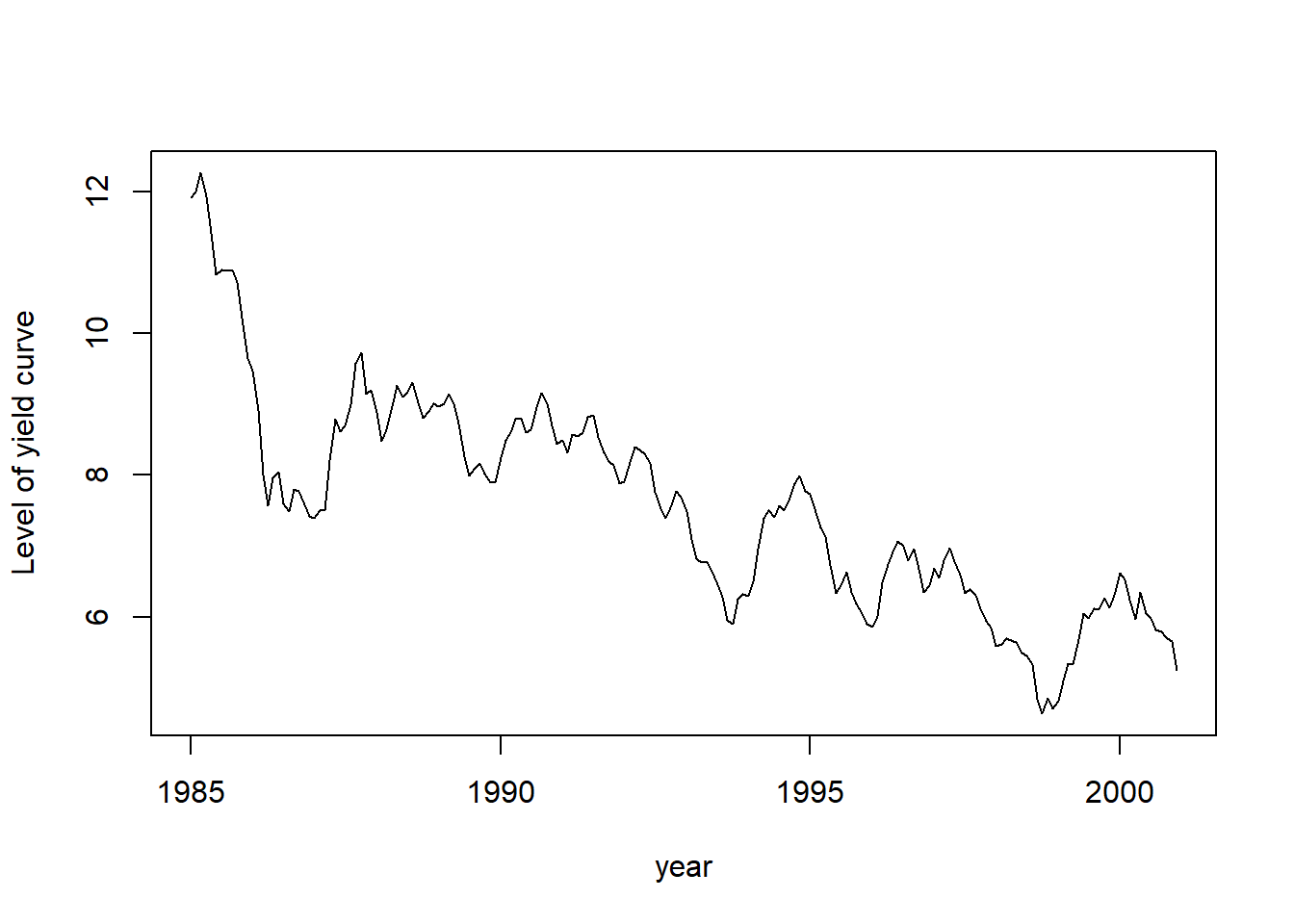
平滑得到的β2t的时间序列图形:
plot(date.yc, fit$smoothed$a[, 2], type = 'l',
xlab = "year", ylab = "Slope of yield curve")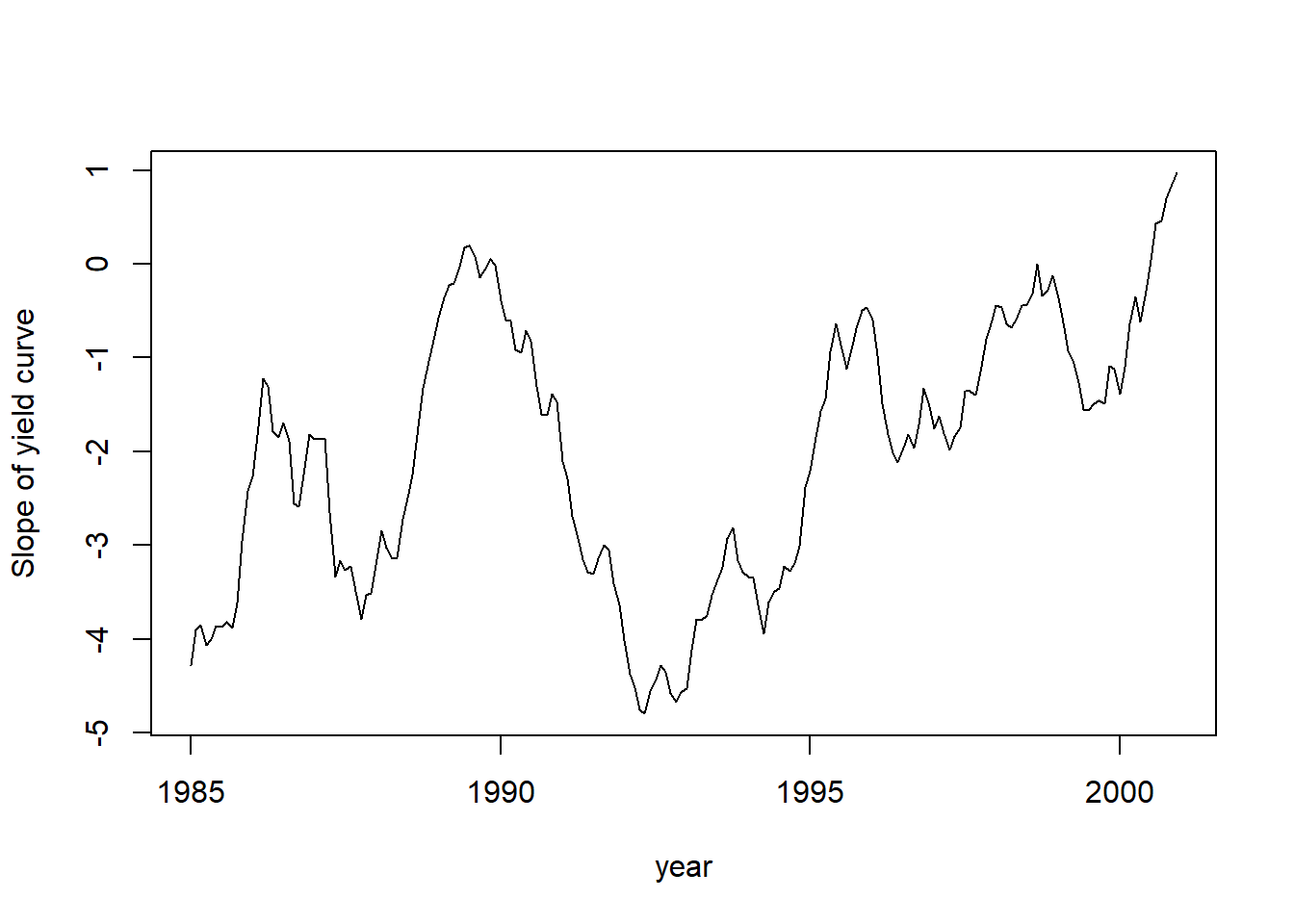
平滑得到的β3t的时间序列图形:
plot(date.yc, fit$smoothed$a[, 3], type = 'l',
xlab = "year", ylab = "Shape of yield curve")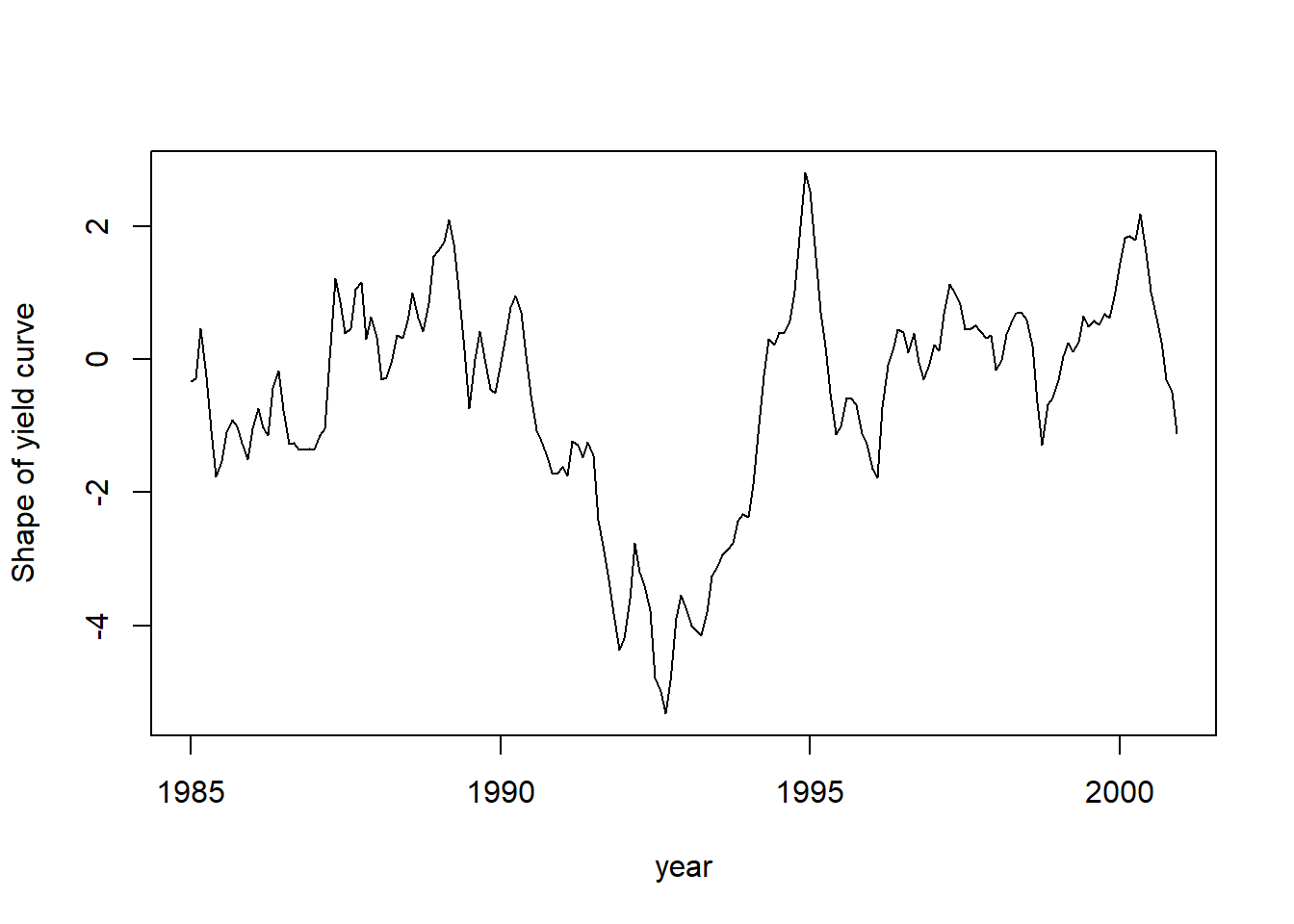
获取估计的参数:
parameters <- data.frame(
Parameter = c("lambda", "sigma2", "mu1", "mu2", "mu3"),
Value = fit$system_matrices$self_spec,
SE = fit$standard_errors$self_spec
)
knitr::kable(parameters, digits=4)| Parameter | Value | SE |
|---|---|---|
| lambda | 0.0789 | 0.0017 |
| sigma2 | 0.0035 | 0.0002 |
| mu1 | 8.2277 | 2.0759 |
| mu2 | -2.2748 | 1.4364 |
| mu3 | -0.4256 | 0.7191 |
向量自回归系数矩阵:
fit$system_matrices$T$self_spec[1:3, 1:3]## [,1] [,2] [,3]
## [1,] 0.98488006 -0.01776100 0.005741521
## [2,] -0.01980538 0.94678326 0.062497259
## [3,] -0.03354339 -0.04024349 0.964429517状态方程误差方差阵:
fit$system_matrices$Q$self_spec[1:3, 1:3]## [,1] [,2] [,3]
## [1,] 0.06723244 -0.05232934 0.06856474
## [2,] -0.05232934 0.07118337 -0.04047250
## [3,] 0.06856474 -0.04047250 0.2409775928.4.6 时变系数CAPM模型
28.4.6.1 模型
考虑时变系数的资产定价模型(CAPM):
rt=β0,t+1=β1,t+1=β0t+β1trM,t+et, et∼ iid N(0,σ2e),β0,t+ut, ut∼ iid N(0,σ2u),β1,t+vt, vt∼ iid N(0,σ2v),
其中{et}, {ut}, {vt}相互独立,
rt是某金融资产的超额收益率,
rM,t是市场的超额收益率。
可以写成状态空间模型
rt=(β0,t+1β1,t+1)=(1,rM,t)(β0tβ1t)+et,(1001)(β0,tβ1,t)+(utvt).
令状态变量αt=(β0t,β1t)T,
观测变量为rt,且
Zt=Tt=Qt=(1,rM,t),Ht=σ2e,I2,Rt=I,ηt=(ut,vt)T,(σ2u00σ2v),
则时变系数CAPM对应于状态空间模型
rt=αt+1=Ztαt+et, et∼N(0,Ht),Ttαt+Rtηt, ηt∼N(0,Qt).
28.4.6.2 通用动力的例子
例28.5 考虑通用动力(GM)股票的月度超额收益率rt的CAPM模型,
时间为1990年1月到2003年12月,
以标普500超额收益率为市场超额收益率rM,t。
数据(收益率单位:百分之一):
da_gm <- readr::read_table(
"m-fac9003.txt",
col_types = cols(.default=col_double()))[,c("GM", "SP5")]
nda <- nrow(da_gm)
ts.gm <- ts(as.matrix(da_gm),
start=c(1990, 1), frequency=12)
plot(as.xts(ts.gm),
main="GM和标普500的月度超额收益率(%)")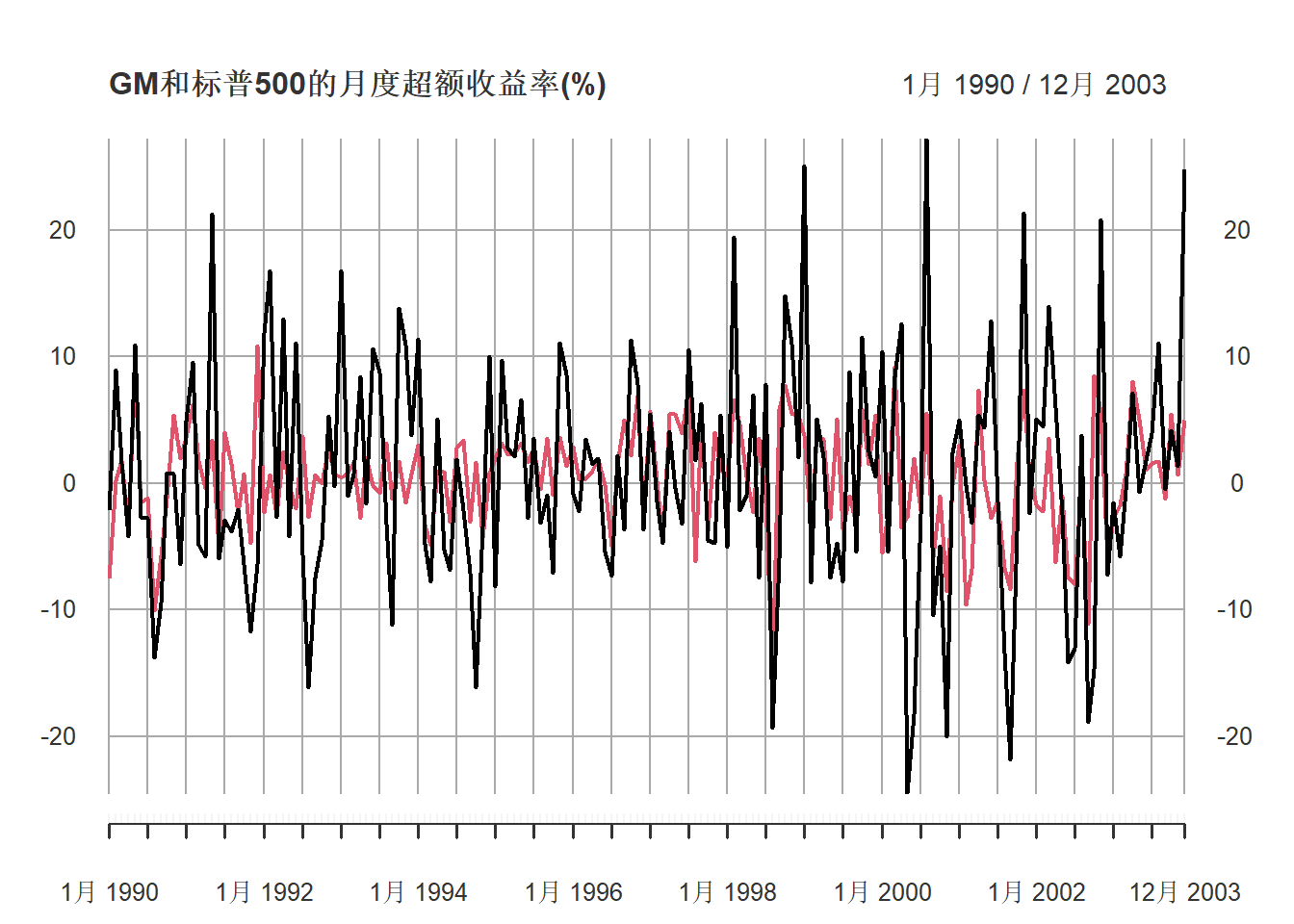
28.4.6.3 滚动计算回归的简单做法
尝试滚动地进行线性回归,
取固定的拟合时间窗口为24个月,
获得动态的系数估计:
wh <- 24 # 滚动窗口
n <- nrow(da_gm)
betamat <- matrix(NA, n, 2)
for(t in wh:n){
tind <- (t-wh+1):t
betamat[t,] <-
lm(GM ~ SP5, data=da_gm[tind,]) |>
coef()
}
ts.beta <- ts(
betamat, start=c(1990, 1), frequency=12)
plot(ts.beta)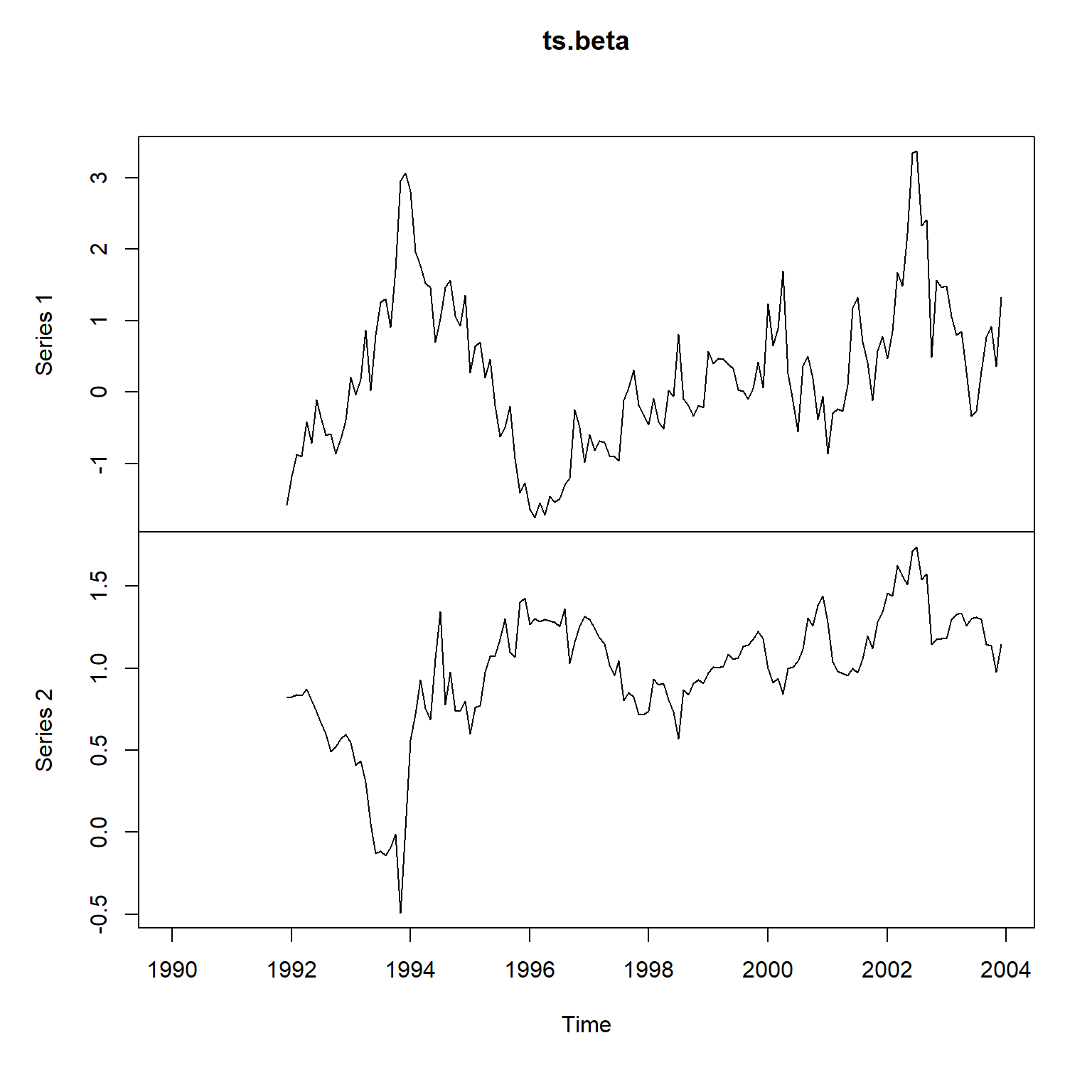
这个结果可以作为基准。
28.4.6.4 使用KFAS包拟合时变系数回归模型
statespacer包没有提供时变系数回归模型,
而Zt依赖于t时statespacer包没有提供自定义方法。
使用KFAS包。
这个包提供了SSMregression()函数,
可以指定带有随机游动斜率的回归模型,
但不支持随机截距项,
尝试使用自定义的对应于截距项的自变量会使得滤波平滑失败。
我们使用SScustom()直接指定各个矩阵。
library(KFAS)
# 将每一行是一个$Z_t$值的矩阵,
# 转换成$1 \times m \times n$的数组,
# $m$是状态空间维数,$n$是样本量
dim2to3 <- function(M){
M <- t(M)
dim(M) <- c(1, dim(M))
M
}
# Zt: 用三维数组表示的$Z_t, t=1,2,\dots,n$,
# 第三下标代表$t$,
# Zt[,,t]是$1 \times m$矩阵$Z_t$
Zt <- dim2to3(cbind(1, da_gm[["SP5"]]))
mod_gm <- SSModel(
da_gm$GM ~ SSMcustom(
Z = Zt, # 观测方程的载荷阵
T = diag(2), # 状态方程的转移矩阵
# 状态的初始值
a1 = c(0, 1),
# Q是状态方程扰动项方差阵
Q = diag(NA, 2)),
# H是观测方程误差方差阵
H = NA)
fit_gm <- fitSSM(
mod_gm,
inits = c(0,0,0),
method="BFGS") #"Nelder-Mead")
fit_gm$optim.out$value## [1] 589.0349估计的随机截距和随机斜率的扰动标准差:
sqrt(diag(fit_gm$model$Q[,,1]))## [1] 0.0043620203 0.0006551979估计的回归误差项标准差:
sqrt(fit_gm$model$H[,,1])## [1] 8.108269计算平滑结果:
res_gm <- KFS(fit_gm$model)GM原始值与拟合值(使用平滑)的曲线:
plot(ts.gm[,"GM"], main="GM and fitted")
lines(as.vector(time(ts.gm)),
c(fitted(res_gm, filtered=FALSE)),
col="red")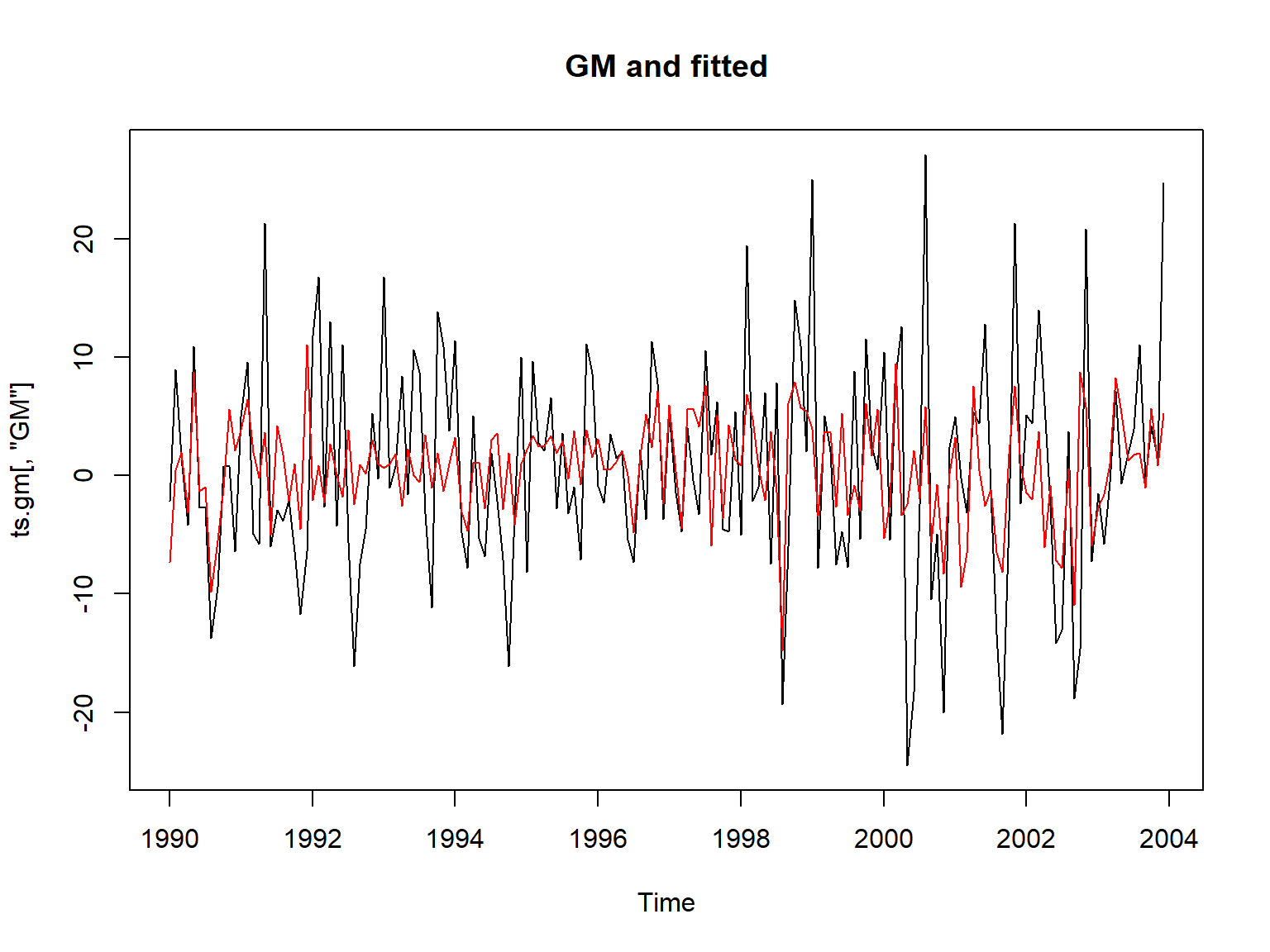
如果前面的程序中没有指定a1 = c(0, 1),
即初始的随机截距、随机斜率,
则拟合上图在左端的拟合效果很差。
估计的时变截距项和时变斜率项:
states <- as.matrix(coef(res_gm))
states[,2] <- states[,1] + states[,2]
states <- states[,2:3]
plot(ts(states, start=c(1990, 1), frequency=12))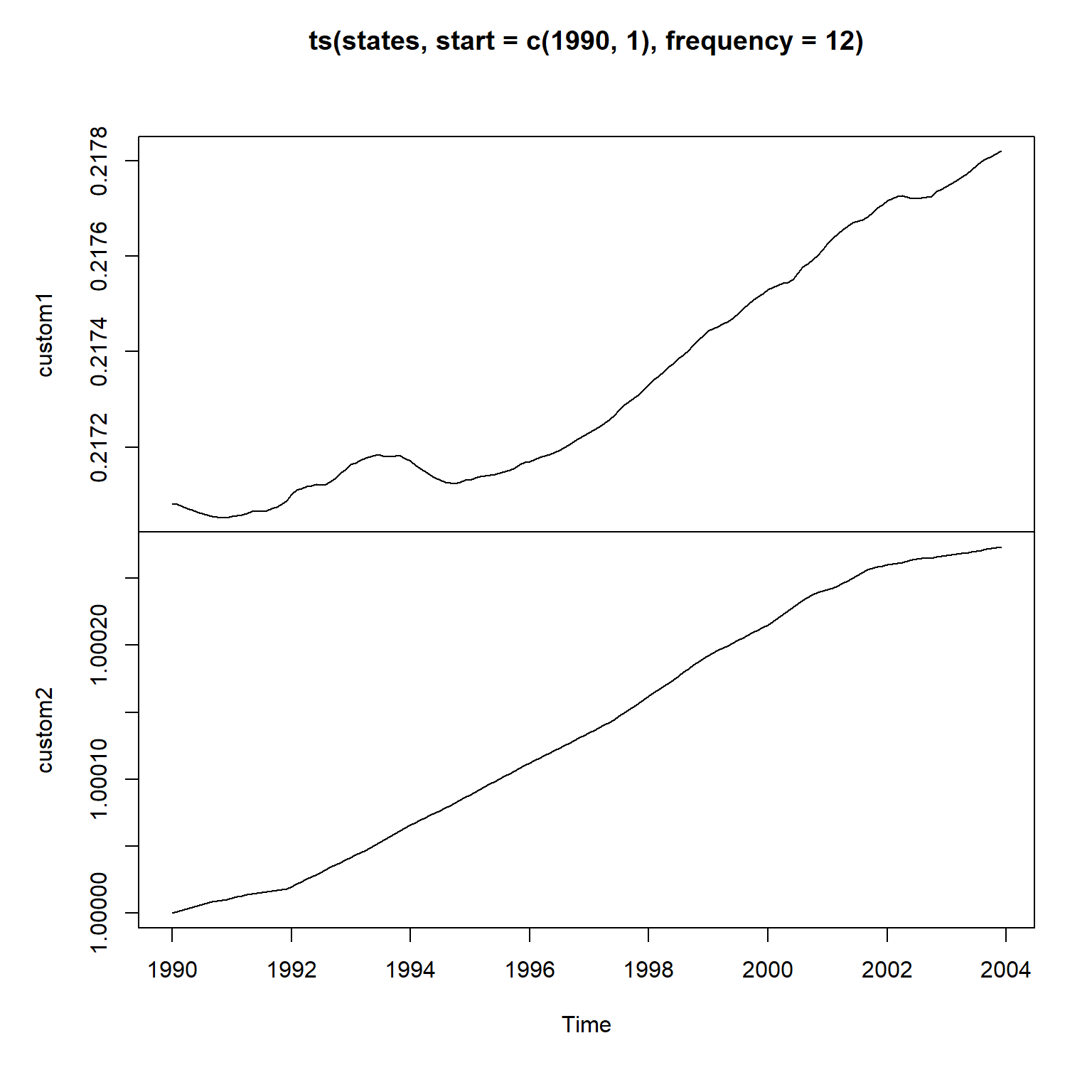
可以看出,
时变的截距项β0t和时变斜率项β1t的变化范围很小。
与滚动回归得到的结果不一致,
基本上没有起到时变的效果。
使用KFAS的SSMregression(),
仅使用随机斜率项:
mod_gm <- SSModel(
da_gm$GM ~ SSMregression(
~ da_gm$SP5,
# Q是状态方程扰动项方差阵
Q = NA),
# H是观测方程误差方差阵
H = NA)
fit_gm <- fitSSM(
mod_gm,
inits = c(0, 0),
method="BFGS")
res_gm <- KFS(fit_gm$model)拟合结果:
plot(ts.gm[,"GM"], main="GM and fitted with time-varying beta")
lines(as.vector(time(ts.gm)),
c(fitted(res_gm, filtered=FALSE)),
col="red")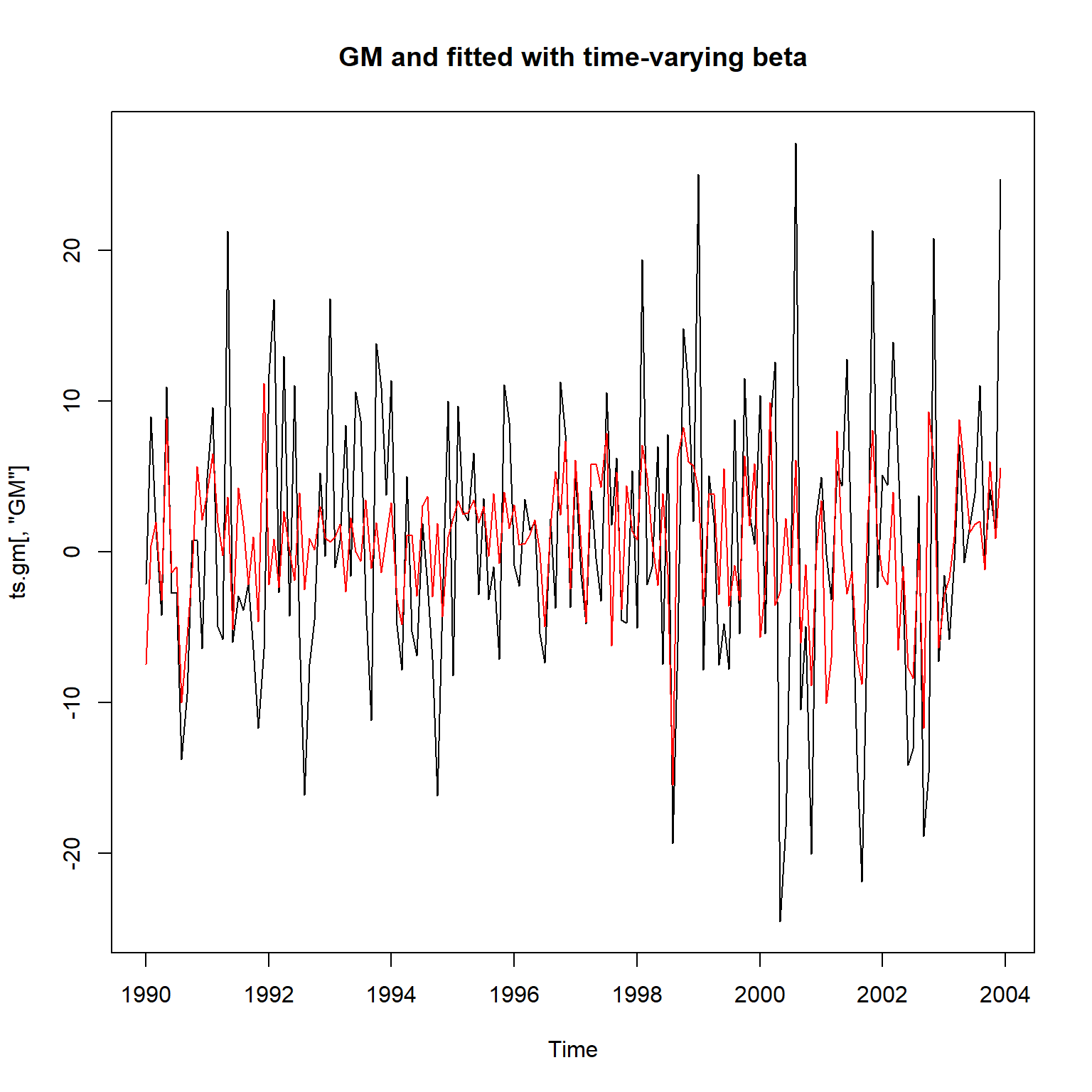
这个拟合结果比较合理。
随机斜率项估计:
states <- as.matrix(coef(res_gm))
plot(ts(states[,2], start=c(1990, 1), frequency=12),
main="Time-varying Regression Slope")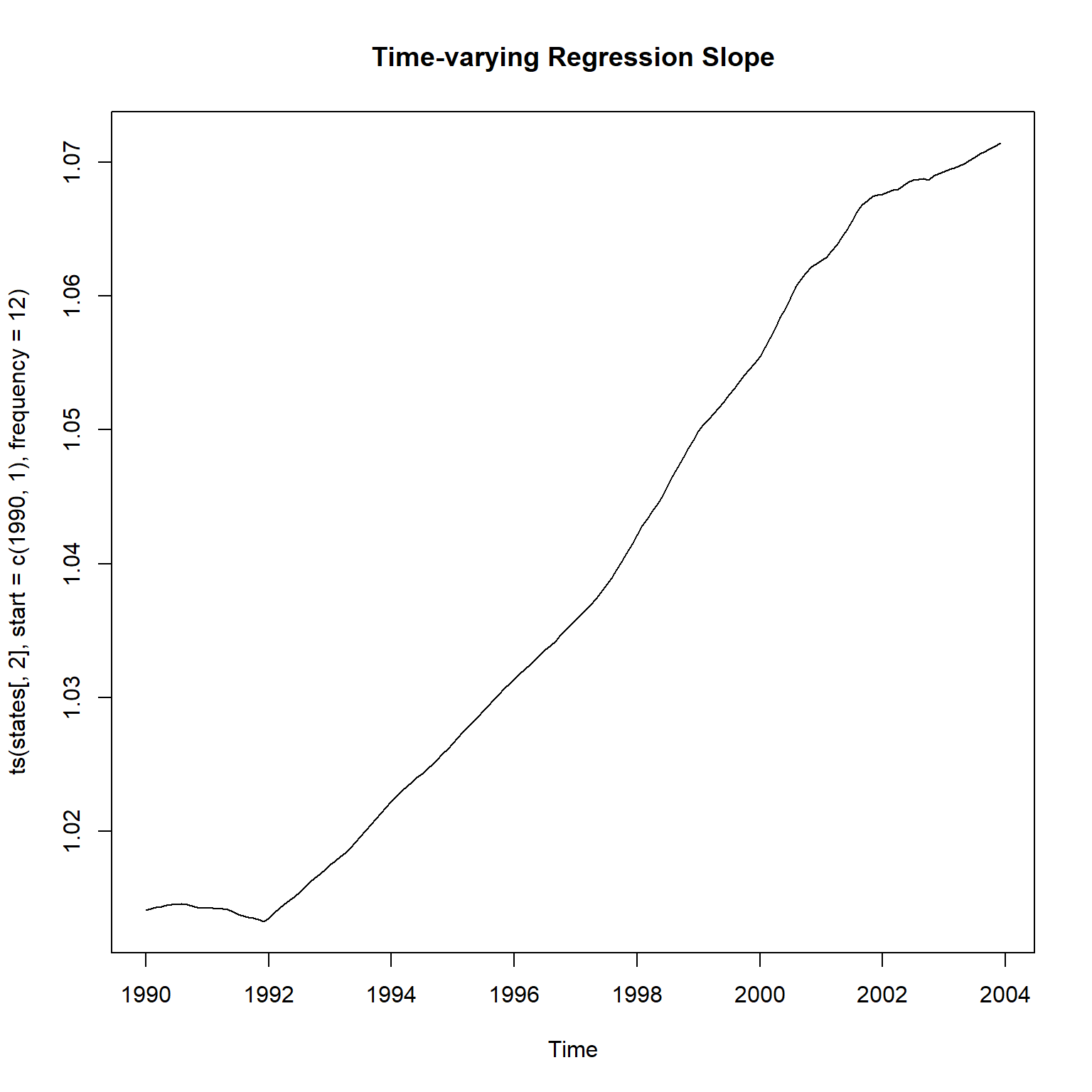
这个结果与滚动窗口回归计算的斜率项还是不一致,
但是变化范围比较小,
有一定合理性。
28.4.6.5 使用dlm包拟合时变系数回归模型
dlm包也支持时变系数回归,
可以用dlm尝试估计时变截距和斜率。
输入超参数的建模函数:
library(dlm)
buildFun <- function(para){
dlmModReg(
cbind(da_gm[["SP5"]]), # 自变量值
dV = exp(para[1]), # 回归误差方差
dW= exp(para[2:3])) # 状态方差误差方差
}超参数最大似然估计:
fit_dlm <- dlmMLE(
da_gm[["GM"]],
parm = c(0,-2,-2),
build = buildFun)
fit_dlm$conv## [1] 0估计的数值算法收敛。
提取最优参数的模型:
dlm_gm <- buildFun(fit_dlm$par)回归误差项标准差:
## [,1]
## [1,] 8.130086随机截距项和斜率项的标准差:
W(dlm_gm) |> diag() |> sqrt()## [1] 9.177050e-04 1.271935e-06估计得到的状态方程扰动项标准差很小,
比KFAS模型得到的结果小得多,
使得截距和斜率基本等于常数。
利用最大似然估计得到的超参数进行滤波和平滑:
filt_gm <- dlmFilter(da_gm[["GM"]], dlm_gm)
smth_gm <- dlmSmooth(filt_gm)平滑得到的时变截距项和时变斜率项:
plot(ts(
smth_gm$s[-1,1:2],
start=c(1990, 1),
frequency=12),
main="Time-varying intercept and slope")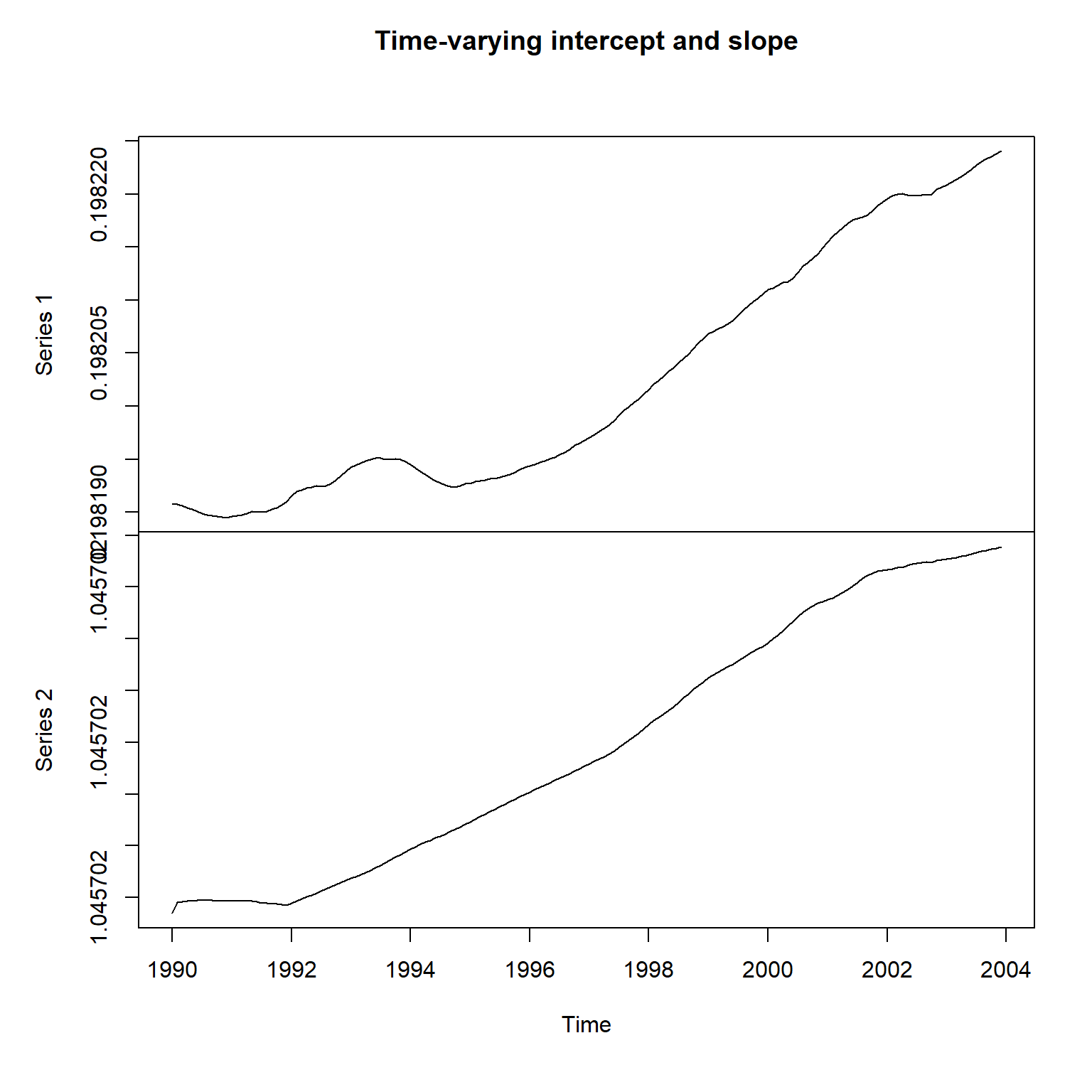
与KFAS的结果不一致。
另外,实际上截距和斜率的变化范围很小,
基本上是常数。
韭菜热线原创版权所有,发布者:风生水起,转载请注明出处:https://www.9crx.com/74934.html




