

38.1 模型
38.1.1 介绍
线性回归模型
Y=a+bx+ε, ε∼N(0,σ2)
可以写成
Y|x∼g(x)=N(g(x),σ2),a+bx.
这样,因变量Y与自变量x1,x2,…,xp的更一般的模型, 可以写成如下形式的广义线性模型:
Y∼g(μ)=F(y;μ)β0+β1×1+⋯+βpxp.
其中F(⋅,μ)是参数为μ的某种分布, 通常取μ=EY, g(⋅)为某个线性或非线性函数, 称为联系函数(link function)。 模型也可以写成
Y|(x1,…,xp)∼F(y;g−1(β0+β1×1+⋯+βpxp)).
一个广义线性模型有如下三个部分:
- 随机部分,给出因变量Y及其条件概率分布Y∼F(⋅;μ);
- 系统部分,给出模型自变量的线性函数β0+β1×1+⋯+βpxp;
- 联系函数g(⋅), 将因变量分布参数(一般是均值)μ与自变量线性组合β0+β1×1+⋯+βpxp联系在一起。
在广义线性模型中, 因变量的分布不一定是正态分布, 因变量的期望值EY不一定是自变量的线性函数, 因变量的方差不一定是恒定值。
典型的因变量分布有二项分布、泊松分布等。
本章内容参考了Paul Roback和Julie Legler的教材《超越多元线性回归–用R语言进行广义线性模型和多水平模型应用》 (Roback and Legler 2021):
38.1.2 指数族分布
设随机变量Y的概率密度函数或概率质量函数f(y)可以表达为
f(y;θ)=exp{a(y)b(θ)+c(θ)+d(y)},
且f(⋅;θ)的支撑集不依赖于θ, 则称Y服从单参数指数族分布。
单参数指数族分布与广义线性模型有密切联系, 其中b(⋅)称为经典联系函数, 作为广义线性模型中g(⋅)的一种重要选择。
对单参数指数族分布随机变量Y, 计算可得
EY=−c′(θ)b′(θ),Var(Y)=b″(θ)c′(θ)−c″(θ)b′(θ)[b′(θ)]3.
单参数指数族分布包含了许多常见分布, 如方差已知的正态分布、泊松分布、二项分布等。
例如, 考虑一元线性回归模型
Y=a+bx+ε, ε∼N(0,σ2),
正态N(μ,σ2)(其中σ2已知)的密度函数写成单参数指数族为
f(y;μ)===12πσ2‾‾‾‾‾√exp{−12σ2(y−μ)2}exp{[yσ2μ]+[−μ22σ2]+[−12ln2π−12lnσ2−12σ2y2]}exp{a(y)b(θ)+c(θ)+d(y)}.这里参数为θ=μ。 一元线性回归模型可以写成
Y∼g(θ)=N(θ,σ2),θ=a+bx,其中g(θ)=θ是恒等函数, 这是经典联系函数b(θ)=θ。
泊松分布的概率质量函数为
f(y;λ)=λyy!e−λ=exp{ylnλ−λ−ln(y!)}, y=0,1,…,
是单参数指数族分布。 参数为λ=EY。 经典联系函数为g(θ)=lnθ, 一元泊松回归模型可以写成
Y∼g(θ)=Poisson(θ),ln(θ)=a+bx.
二项分布B(n,p)当n已知, 以p为参数时,是单参数指数族分布, 其概率质量函数为
f(y;p)====(ny)py(1−p)n−y, y=0,1,…,n(ny)(1−p)n(p1−p)yexp{ylnp1−p+nln(1−p)+ln(ny)}exp{a(y)b(θ)+c(θ)+d(y)},
这里θ=p=1nEY, 其中n已知。 b(p)=lnp1−p, 称lnp1−p为logit(p), 是二项分布的经典联系函数。
logit(p)=logit−1(u)=lnp1−p, p∈(0,1),eu1+eu=11+e−u∈(0,1), u∈(−∞,∞).一元逻辑斯谛回归模型可以写成
Y∼g(θ)=B(n,θ),logit(θ)=a+bx.
对于以上的三个分布, 使用经典联系函数将因变量分布参数与自变量线性组合联系起来可以给出一些粗浅的解释。
- 对于正态分布因变量, 因为正态分布可以在(−∞,∞)取值, 其期望值也可以在(−∞,∞)取值, 所以其期望值μ可以不进行变换地用自变量线性组合a+bx表示。
- 对于泊松分布因变量, 泊松分布仅取非负整数值, 其期望λ仅取正值, 所以不能直接用自变量线性组合a+bx表示, 因为a+bx可能取到负值; 而期望λ用exp{a+bx}表示则不会出现λ取负值的问题。
- 对于二项分布因变量, 其分布参数p仅在(0,1)区间内取值, 所以不能直接用自变量线性组合a+bx表示, 因为a+bx可能取到负值或者大于1的值, 而logit−1(a+bx)则可以将(−∞,∞)映射到(0,1)内, 保证了p的取值在允许范围内。
38.2 泊松回归
38.2.1 模型
泊松分布是一种常见的取非负整数值的随机变量分布, 经常用于计数变量的模型。 如果某种事件在短时间内发生的概率很低, 发生与否独立, 则该时间在某一时间区间内发生的次数服从泊松分布。 参数为λ的泊松分布的概率质量函数为
f(y;λ)=λyy!e−λ, y=0,1,….
设随机变量Y的分布受到自变量x1,…,xp的影响, 在给定x1,…,xp的条件下Y服从泊松分布, 则可以用泊松回归描述Y与x1,…,xp的关系:
Y∼g(λ)=Poisson(λ),β0+β1×1+⋯+βpxp.
其中g(λ)经常取为经典联系函数lnλ。
实际上, 即使给定x1,…,xp后Y服从泊松分布, 参数λ与x1,…,xp的关系也不一定恰好被g(λ)=β0+β1×1+⋯+βpxp确定, 泊松回归模型是Y|(x1,…,xp)分布的一种简化模型。
泊松回归的假定:
- Y|(x1,…,xp)服从泊松分布;
- 不同的观测相互独立;
- Y|(x1,…,xp)的分布均值与分布方差相等, 这一点与线性回归不同;
- g(λ)与x1,…,xp服从线性关系, 这是对模型的简化假设。
38.2.2 最大似然估计
考虑单个自变量的泊松回归, 设Yi∼Poisson(λi), lnλi=β0+β1xi, 于是单个观测(xi,yi)对于似然函数的贡献为
λyiiyi!e−λi,
对于对数似然函数的贡献为
yilnλi−lnyi!−λi=yi(β0+β1xi)−lnyi!−eβ0+β1xi,其中−lnyi!在对数似然函数中是常数项, 所以对数似然函数为
ℓ(β0,β1)=常数+∑i=1n{yi(β0+β1xi)−eβ0+β1xi}.
可以用Newton-Raphson迭代方法进行最大似然估计的数值求解, 并且可以使用Fisher得分方法改造Newton-Raphson方法, 具体方法是在迭代中用负信息阵的当前估计值代替对数似然函数的海色阵。 这样还可以从最大值点处的信息阵的逆矩阵给出参数估计的协方差阵估计。 这种利用Fisher得分的Newton-Raphson迭代方法, 等价于迭代再加权最小二乘方法, 每步迭代是一个加权最小二乘计算, 加权按照当前的方差倒数来计算。
38.2.3 偏差与偏差分析
线性回归模型使用残差平方和以及方差分析评估模型的拟合优劣。 因为广义线性模型是对因变量分布参数的拟合而非直接对因变量值的拟合, 所以没有原来的残差以及残差平方和的概念, 而是用偏差(deviance)代替。
设要评估的模型的对数似然函数在最大似然估计处的值为ℓM, 为了比较, 考虑一个参数最复杂的“饱和模型”, 使得因变量得到最大程度的解释。 例如, 在方差分析中对因素的每种组合都单独使用一个参数。 理论上, 在饱和模型中, 应该每一组不同的自变量组合都单独设置一个因变量独立参数值, 但是在R统计软件glm()计算时实际是对每个观测单独使用参数。 计算饱和模型的对数似然函数的最大值ℓS。 这样, 饱和模型的自由参数(独立参数)个数是最多的。
要评估的模型的偏差(deviance)定义为
Dev=−2[ℓM−ℓS],
偏差一定是非负的, 对于某些广义线性模型, 如果模型M很好地解释了数据, 则模型M与饱和模型S应该效果相近, 在一定条件下偏差近似服从卡方分布, 自由度等于两个模型独立参数的个数差, 当偏差不超过卡方的1−α分位数时可以认为模型M是充分的。
类似于线性模型中的平方和分解, 偏差也可以进行分解。 比如, 有两个模型M0和M1, M0是M1的特例, 即M0是M1的参数取特定值或满足特定约束后的模型, 称M1为完全模型, 称M0为简化模型, 称这两个模型有嵌套关系。 这时, 为了在M1的假设下检验M0是否成立, 计算似然比统计量
−2[ℓ0−ℓ1]=−2[ℓ0−ℓS]+2[ℓ1−ℓS]=Dev0−Dev1,
当M0与M1效果相同的零假设成立时统计量服从卡方分布, 自由度等于两个模型的独立参数个数差, 这个统计量可以用两个模型的偏差之差计算。
38.2.4 残差分析
对于泊松回归, 也可以定义残差, 但是不像线性回归那样只有观测值减去预测值这一种, 因为广义线性模型中自变量预测的是因变量的期望值而非因变量本身。
以一元泊松回归为例。 响应残差(response residual)定义为ei=yi−μ̂ i, 而μ̂ i估计为g−1(β̂ 0+β̂ 1xi), 其中g(⋅)是联系函数, 对泊松回归一般取为ln, 所以μ̂ i=exp(β̂ 0+β̂ 1xi)。
定义标准化残差或Pearson残差为
e(P)i=yi−μ̂ iμ̂ i‾‾√.
定义偏差残差(deviance residual)为
e(D)i=sgn(yi−μ̂ i){2[yi(lnyi−lnμ̂ i)−(yi−μ̂ i)]}1/2.
其平方和恰好等于模型的残差偏差(residual deviance)。 偏差残差一般与Pearson残差近似相等。
对glm()结果, 可以用residuals()函数提取各种残差, 指定type="response"或"pearson"、"deviance", 缺省为type="deviance"。
38.2.5 菲律宾家庭人数研究案例
38.2.5.1 数据与探索性分析
本例子来自(Roback and Legler 2021)§4.4。 数据是菲律宾统计局的2015年调查数据, 从4万户家庭数据中随机抽取了1500个家庭的子集。 因变量是家庭中除了户主以外的人数, 自变量包括户主年龄、家庭贫困与否、所在地区。 家庭贫困与否, 用住房屋顶是否主要使用廉价材料来表征。 因为因变量是计数的, 所以考虑使用泊松回归作为初始的模型。 泊松分布参数λ是除了户主以外的家庭人数的期望值。
读入数据并展示前几行:
dfp <- read_csv(
"data/fHH1.csv",
col_types = cols(
.default = col_double(),
location = col_factor(
levels = c("CentralLuzon", "DavaoRegion",
"IlocosRegion", "MetroManila", "Visayas")),
roof = col_factor(
levels = c("Predominantly Light/Salvaged Material",
"Predominantly Strong Material")) ),
col_select = c(-1))## New names:
## • `` -> `...1`knitr::kable(head(dfp, 5))| location | age | total | numLT5 | roof |
|---|---|---|---|---|
| CentralLuzon | 65 | 0 | 0 | Predominantly Strong Material |
| MetroManila | 75 | 3 | 0 | Predominantly Strong Material |
| DavaoRegion | 54 | 4 | 0 | Predominantly Strong Material |
| Visayas | 49 | 3 | 0 | Predominantly Strong Material |
| MetroManila | 74 | 3 | 0 | Predominantly Strong Material |
数据包含了1500个家庭的数据, 每行为一个家庭,每行中各变量分别为:
location:所在区域,有5个不同取值;age:户主年龄;total:除了户主以外的人数;numLT5:家庭中低于5岁的儿童个数;roof:房顶类型,"Predominantly Light/Salvaged Material"代表家庭比较贫困,"Predominantly Strong Material"则代表非贫困。
因变量total是一个取非负整数值的数值型变量, 这里之所以扣除了户主, 是因为泊松分布理论上可以取0, 而包括户主后人数至少等于1。 对total变量进行简单数值概括:
summary(dfp[["total"]])## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.000 2.000 3.000 3.685 5.000 16.000平均值为3.685,中位数为3,最大值为16。 因为total是离散取值的, 不适合作一般的直方图, 用条形图表现其分布:
ggplot(data = dfp, mapping = aes(
x = total )) +
geom_bar()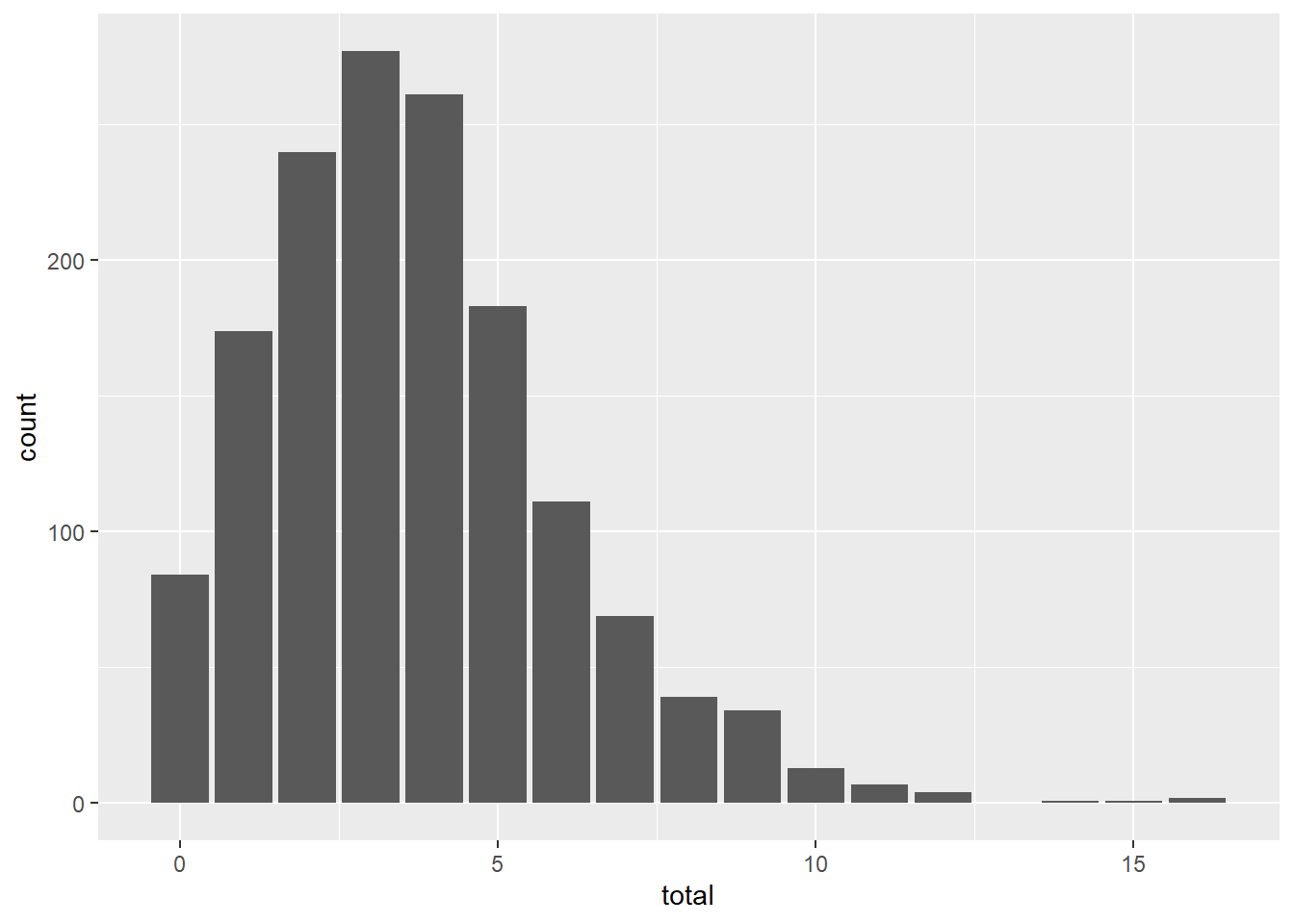

为考察户主年龄与家庭人数的关系, 作两者的散点图:
ggplot(data = dfp, mapping = aes(
x = age, y = total )) +
geom_jitter(alpha = 0.5) +
geom_smooth()## `geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")'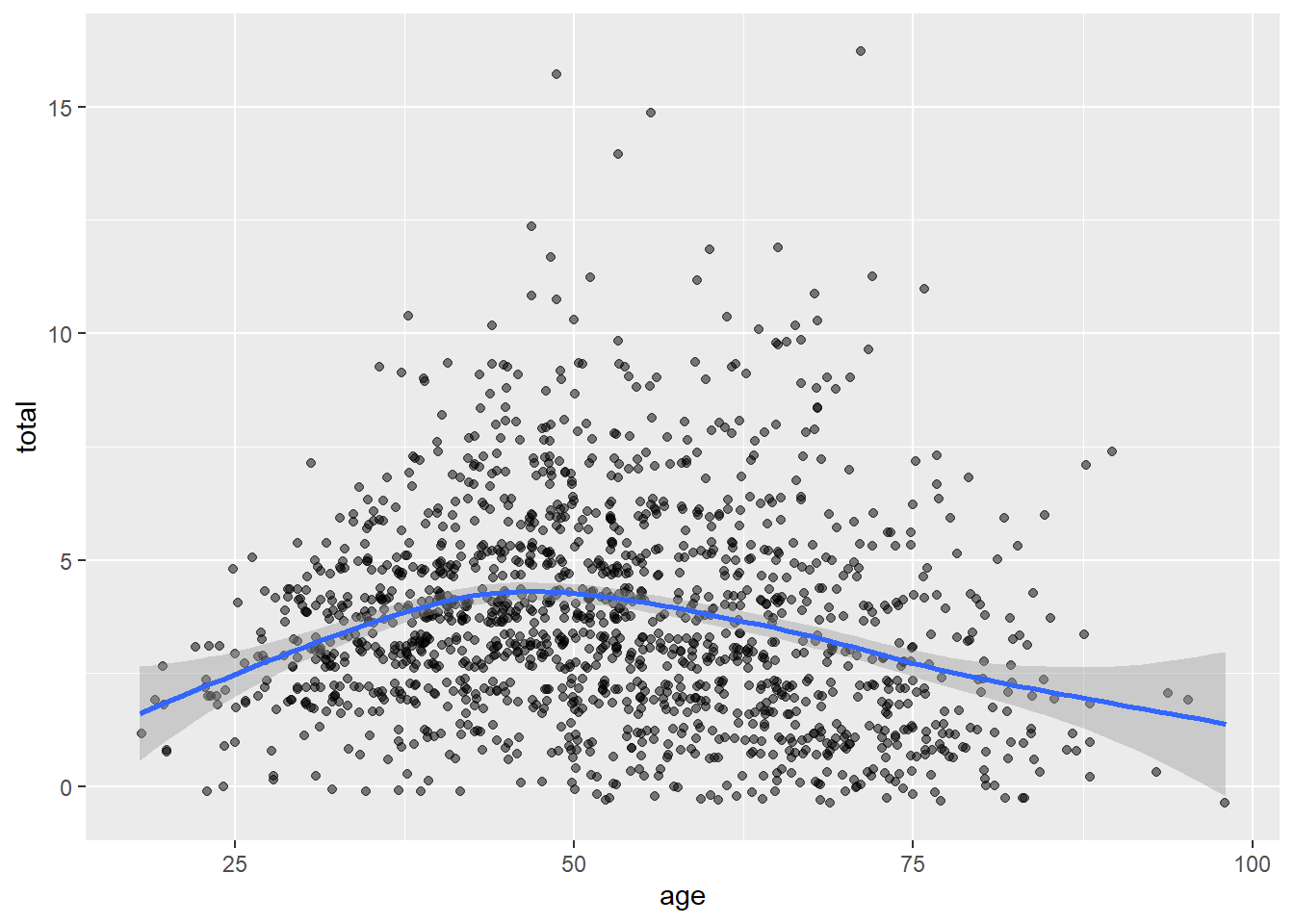
其中的拟合曲线并不符合exp{a+b⋅age}的形状。 所以有可能需要增加age的二次项以改善模型。
从数据无法确定各个观测之间是否独立, 这里先假定独立, 如果抽样方案不能保证各个家庭独立, 可以采用观测之间带有相关性的模型。
38.2.5.2 单个自变量的泊松回归建模
基本R软件的配套(默认安装)扩展包stats提供了glm()函数, 用来进行广义线性模型建模。 对家庭人口数问题, 以total为因变量, 以户主年龄age为自变量, 先建立仅有一个自变量的模型:
glmp1 <- glm(total ~ age,
family = poisson, data = dfp)
summary(glmp1)##
## Call:
## glm(formula = total ~ age, family = poisson, data = dfp)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.9079 -0.9637 -0.2155 0.6092 4.9561
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 1.5499422 0.0502754 30.829 < 2e-16 ***
## age -0.0047059 0.0009363 -5.026 5.01e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 2362.5 on 1499 degrees of freedom
## Residual deviance: 2337.1 on 1498 degrees of freedom
## AIC: 6714
##
## Number of Fisher Scoring iterations: 5结果模型可以写成
total∼lnλ=Poisson(λ),1.55−0.0047age.
模型指出随着户主年龄增加, 平均人口数会减少。 从summary()函数给出的age变量的系数的z检验p值看, 年龄对平均人口数是有显著影响的。
为了获得β1参数的置信区间, 可以利用confint()函数:
confint(glmp1)## Waiting for profiling to be done...## 2.5 % 97.5 %
## (Intercept) 1.451170100 1.648249185
## age -0.006543163 -0.002872717可以用level参数指定置信度,默认值为0.95。 因为logλ=β0+β1x, 所以λ=exp{β0+β1x}, 当x增加一个单位时, λ变化为原来的eβ1倍; 所以,当年龄增加一岁时, 按模型解释, 平均人口数会降低到原来的e−0.0047=99.5%倍, 即平均减少0.5%, 变化的倍数的95%置信区间为:
exp(confint(glmp1))## Waiting for profiling to be done...## 2.5 % 97.5 %
## (Intercept) 4.2681057 5.1978713
## age 0.9934782 0.9971314即减少0.7%到0.3%。
38.2.5.3 与空模型的比较
可以建立一个没有自变量的模型作为基准模型, 称这个模型为空模型(null model):
glmp2 <- glm(total ~ 1,
family = poisson, data = dfp)
summary(glmp2)##
## Call:
## glm(formula = total ~ 1, family = poisson, data = dfp)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.7147 -0.9619 -0.3687 0.6495 4.7285
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 1.30418 0.01345 96.96 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 2362.5 on 1499 degrees of freedom
## Residual deviance: 2362.5 on 1499 degrees of freedom
## AIC: 6737.4
##
## Number of Fisher Scoring iterations: 5可以看出, 结果中Residual deviance和Null deviance相同, 也和前面包含自变量age的模型结果中的Null deviance相同。
在线性回归中我们用残差平方和(SSE)表示模型的拟合优度, 更一般的广义线性模型中不一定能使用残差平方和, 而是改用偏差(deviance)。 偏差等于定义要评估的模型与饱和模型的对数似然函数最大值之差的负二倍。 通过比较两个嵌套模型的残差偏差, 可以判断复杂的模型是否与简单的模型有显著差异。 饱和模型是自由参数最多的模型, 对每个自变量组合都设置一个自由参数; 空模型是仅包含截距项的模型, 是自由参数最少的模型。
空模型结果可以写成公式
total∼Poisson(e1.30=3.68).
以有age自变量的模型为完全模型, 以没有自变量的模型为简化模型, 用anova()函数进行偏差检验:
anova(glmp2, glmp1, test = "Chisq")## Analysis of Deviance Table
##
## Model 1: total ~ 1
## Model 2: total ~ age
## Resid. Df Resid. Dev Df Deviance Pr(>Chi)
## 1 1499 2362.5
## 2 1498 2337.1 1 25.399 4.661e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1结果给出了残差偏差的差值(Deviance), 在简化模型与完全模型相同的零假设下, 偏差近似服从卡方分布, 自由度为两个模型的自由参数个数之差, 这里自由度为1, 结果显著, 说明加入age变量是有意义的。
38.2.5.4 增加年龄的二次项
从探索性数据分析结果发现年龄对平均人口数的影响并不是单调的, 而是在中间达到最大值。 所以有可能需要增加年龄的二次项。 平均年龄约为53, 为了避免共线问题,增加(age−53)2项:
glmp3 <- glm(total ~ age + I((age - 53)^2),
family = poisson, data = dfp)
summary(glmp3)##
## Call:
## glm(formula = total ~ age + I((age - 53)^2), family = poisson,
## data = dfp)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.9068 -0.9261 -0.1048 0.5773 5.1731
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 1.657e+00 5.596e-02 29.611 < 2e-16 ***
## age -4.196e-03 1.033e-03 -4.062 4.87e-05 ***
## I((age - 53)^2) -7.083e-04 6.406e-05 -11.058 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 2362.5 on 1499 degrees of freedom
## Residual deviance: 2200.9 on 1497 degrees of freedom
## AIC: 6579.8
##
## Number of Fisher Scoring iterations: 5这里二次项的z检验的p值也是显著的, 说明增加二次项是有意义的。 与仅有一次项的模型进行偏差比较:
anova(glmp1, glmp3, test = "Chisq")## Analysis of Deviance Table
##
## Model 1: total ~ age
## Model 2: total ~ age + I((age - 53)^2)
## Resid. Df Resid. Dev Df Deviance Pr(>Chi)
## 1 1498 2337.1
## 2 1497 2200.9 1 136.15 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1结果也是显著的。 模型写成数学公式为
logλ=1.66−0.0042age−0.00071(age−53)2.
38.2.5.5 增加更多自变量
其它自变量对家庭人口数也可以有影响。 先增加location变量, 这是一个有5个水平的因子, 建模时会被转化为4个二值哑变量:
glmp41 <- glm(total ~ age + I((age - 53)^2) + location,
family = poisson, data = dfp)
summary(glmp41)##
## Call:
## glm(formula = total ~ age + I((age - 53)^2) + location, family = poisson,
## data = dfp)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.9781 -0.9278 -0.1149 0.5924 5.0424
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 1.5892291 0.0666770 23.835 < 2e-16 ***
## age -0.0041112 0.0010348 -3.973 7.09e-05 ***
## I((age - 53)^2) -0.0007026 0.0000642 -10.944 < 2e-16 ***
## locationDavaoRegion -0.0193872 0.0537827 -0.360 0.71849
## locationIlocosRegion 0.0609820 0.0526598 1.158 0.24685
## locationMetroManila 0.0544801 0.0472012 1.154 0.24841
## locationVisayas 0.1121092 0.0417496 2.685 0.00725 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 2362.5 on 1499 degrees of freedom
## Residual deviance: 2187.8 on 1493 degrees of freedom
## AIC: 6574.7
##
## Number of Fisher Scoring iterations: 5summary()给出的关于因子location的检验结果是基于各个哑变量的, 如果要检验整个因子, 可以使用偏差来比较:
anova(glmp3, glmp41, test = "Chisq")## Analysis of Deviance Table
##
## Model 1: total ~ age + I((age - 53)^2)
## Model 2: total ~ age + I((age - 53)^2) + location
## Resid. Df Resid. Dev Df Deviance Pr(>Chi)
## 1 1497 2200.9
## 2 1493 2187.8 4 13.144 0.01059 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1p值为0.01,在0.05水平下显著。
继续增加表征贫困与否的变量roof, 这是一个二值变量:
glmp42 <- glm(total ~ age + I((age - 53)^2) + location + roof,
family = poisson, data = dfp)
summary(glmp42)##
## Call:
## glm(formula = total ~ age + I((age - 53)^2) + location + roof,
## family = poisson, data = dfp)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.9900 -0.9281 -0.1070 0.5912 5.0255
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 1.547e+00 7.698e-02 20.102 < 2e-16 ***
## age -4.160e-03 1.036e-03 -4.017 5.9e-05 ***
## I((age - 53)^2) -7.034e-04 6.419e-05 -10.958 < 2e-16 ***
## locationDavaoRegion -1.655e-02 5.384e-02 -0.307 0.75855
## locationIlocosRegion 6.299e-02 5.269e-02 1.195 0.23194
## locationMetroManila 5.322e-02 4.721e-02 1.127 0.25967
## locationVisayas 1.168e-01 4.196e-02 2.784 0.00537 **
## roofPredominantly Strong Material 4.752e-02 4.359e-02 1.090 0.27564
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 2362.5 on 1499 degrees of freedom
## Residual deviance: 2186.6 on 1492 degrees of freedom
## AIC: 6575.5
##
## Number of Fisher Scoring iterations: 5summary()给出的结果表明在已有年龄和区域自变量的前提下, 增加roof自变量对模型没有显著意义。
尝试增加低于五岁的儿童人数的自变量:
glmp43 <- glm(total ~ age + I((age - 53)^2) + location + numLT5,
family = poisson, data = dfp)
summary(glmp43)##
## Call:
## glm(formula = total ~ age + I((age - 53)^2) + location + numLT5,
## family = poisson, data = dfp)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.6909 -0.8391 -0.1610 0.5856 3.5535
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 1.248e+00 6.919e-02 18.035 <2e-16 ***
## age 2.839e-04 1.056e-03 0.269 0.788
## I((age - 53)^2) -7.809e-04 6.475e-05 -12.059 <2e-16 ***
## locationDavaoRegion -6.309e-02 5.386e-02 -1.171 0.241
## locationIlocosRegion 8.834e-03 5.277e-02 0.167 0.867
## locationMetroManila 1.800e-02 4.726e-02 0.381 0.703
## locationVisayas 2.371e-02 4.204e-02 0.564 0.573
## numLT5 3.729e-01 1.632e-02 22.853 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 2362.5 on 1499 degrees of freedom
## Residual deviance: 1736.8 on 1492 degrees of freedom
## AIC: 6125.6
##
## Number of Fisher Scoring iterations: 5增加低龄儿童数自变量后, location变量变得不再显著, 用偏差进行检验:
glmp43b <- glm(total ~ age + I((age - 53)^2) + numLT5,
family = poisson, data = dfp)
summary(glmp43b)##
## Call:
## glm(formula = total ~ age + I((age - 53)^2) + numLT5, family = poisson,
## data = dfp)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.6678 -0.8414 -0.1672 0.5970 3.5762
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 1.256e+00 5.965e-02 21.057 <2e-16 ***
## age 2.483e-04 1.053e-03 0.236 0.814
## I((age - 53)^2) -7.817e-04 6.465e-05 -12.092 <2e-16 ***
## numLT5 3.742e-01 1.617e-02 23.139 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 2362.5 on 1499 degrees of freedom
## Residual deviance: 1740.8 on 1496 degrees of freedom
## AIC: 6121.6
##
## Number of Fisher Scoring iterations: 5anova(glmp43b, glmp43, test = "Chisq")## Analysis of Deviance Table
##
## Model 1: total ~ age + I((age - 53)^2) + numLT5
## Model 2: total ~ age + I((age - 53)^2) + location + numLT5
## Resid. Df Resid. Dev Df Deviance Pr(>Chi)
## 1 1496 1740.8
## 2 1492 1736.8 4 4.0023 0.4057检验结果表明加入numLT5后location可以取消。 但是,numLT5本身就是一个人口数变量, 用作解释家庭人口数的自变量并不太合适。
最终应该选择的模型是包含了年龄、年龄二次项、location变量的模型。
38.2.6 发病率模型
流行病学研究中, 经常要研究某种病的发病率如何受到自变量的影响。 虽然这属于二项分布, 但是因为发病率都比较低, 可以用泊松分布作为近似模型。 设T为总人数和累计时间(如人年单位), λ为T对应的平均发病人数, 则针对参数
ρ=λ/T
建模, 这样才可以对人口数不同的地区使用统一的模型。 利用泊松回归, 需要写成
log(λ)=β0+β1x+log(T),glm()公式中可以用offset()表示系数固定等于1的自变量。
例38.1 ISwR包的eba1977包含类丹麦的4个城市肺癌发病率数据, 以年龄和城市为自变量建模。
data(eba1977, package = "ISwR")
str(eba1977)## 'data.frame': 24 obs. of 4 variables:
## $ city : Factor w/ 4 levels "Fredericia","Horsens",..: 1 2 3 4 1 2 3 4 1 2 ...
## $ age : Factor w/ 6 levels "40-54","55-59",..: 1 1 1 1 2 2 2 2 3 3 ...
## $ pop : int 3059 2879 3142 2520 800 1083 1050 878 710 923 ...
## $ cases: int 11 13 4 5 11 6 8 7 11 15 ...用泊松回归建模:
glm.eba <- glm(
cases ~ city + age + offset(log(pop)),
family = poisson,
data = eba1977)
summary(glm.eba)##
## Call:
## glm(formula = cases ~ city + age + offset(log(pop)), family = poisson,
## data = eba1977)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.63573 -0.67296 -0.03436 0.37258 1.85267
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -5.6321 0.2003 -28.125 < 2e-16 ***
## cityHorsens -0.3301 0.1815 -1.818 0.0690 .
## cityKolding -0.3715 0.1878 -1.978 0.0479 *
## cityVejle -0.2723 0.1879 -1.450 0.1472
## age55-59 1.1010 0.2483 4.434 9.23e-06 ***
## age60-64 1.5186 0.2316 6.556 5.53e-11 ***
## age65-69 1.7677 0.2294 7.704 1.31e-14 ***
## age70-74 1.8569 0.2353 7.891 3.00e-15 ***
## age75+ 1.4197 0.2503 5.672 1.41e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 129.908 on 23 degrees of freedom
## Residual deviance: 23.447 on 15 degrees of freedom
## AIC: 137.84
##
## Number of Fisher Scoring iterations: 5注意数据1968-1971共4年的数据, 所以模型的发病率ρ应理解为4年发病率。 从残差偏差看模型拟合基本充分, 实际上p值为:
1 - pchisq(23.447, 15)## [1] 0.07509937因为两个自变量都是类别变量, 所以系数估计中的检验仅是针对与基线的比较, 不能作为某个自变量是否显著的检验。 可以用anova()进行检验, 但anova()执行第一类检验, 仅最后一个变量的结果才是排除单个变量的模型与完整模型的比较。 用drop1()可以逐个检验变量是否显著, 作第三类检验:
drop1(glm.eba, test="Chisq")## Single term deletions
##
## Model:
## cases ~ city + age + offset(log(pop))
## Df Deviance AIC LRT Pr(>Chi)
## <none> 23.447 137.84
## city 3 28.307 136.69 4.859 0.1824
## age 5 126.515 230.90 103.068 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1其中age最为显著, city也可以保留。
为了在各年龄组比较, 我们建立一个所有年龄组有各自截距的模型:
glm.eba2 <- glm(
cases ~ -1 + age + city + offset(log(pop)),
family = poisson,
data = eba1977)
summary(glm.eba2)##
## Call:
## glm(formula = cases ~ -1 + age + city + offset(log(pop)), family = poisson,
## data = eba1977)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.63573 -0.67296 -0.03436 0.37258 1.85267
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## age40-54 -5.6321 0.2003 -28.125 <2e-16 ***
## age55-59 -4.5311 0.2073 -21.861 <2e-16 ***
## age60-64 -4.1135 0.1869 -22.005 <2e-16 ***
## age65-69 -3.8644 0.1841 -20.993 <2e-16 ***
## age70-74 -3.7752 0.1897 -19.897 <2e-16 ***
## age75+ -4.2124 0.2082 -20.233 <2e-16 ***
## cityHorsens -0.3301 0.1815 -1.818 0.0690 .
## cityKolding -0.3715 0.1878 -1.978 0.0479 *
## cityVejle -0.2723 0.1879 -1.450 0.1472
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 50361.048 on 24 degrees of freedom
## Residual deviance: 23.447 on 15 degrees of freedom
## AIC: 137.84
##
## Number of Fisher Scoring iterations: 5从age的系数看, 肺癌发病率随年龄而上升, 但75岁以上组又恢复到了60岁时的发病率。
对于发病率的泊松回归模型, 自变量的系数β代表自变量每增加1, 对数发病率会增加β, 从而发病率会增加到原来的eβ倍。 显示自变量的系数所代表的发病率变化倍数:
cbind(Multple=coef(glm.eba), confint(glm.eba)) |>
exp() |> round(4)## Waiting for profiling to be done...## Multple 2.5 % 97.5 %
## (Intercept) 0.0036 0.0024 0.0052
## cityHorsens 0.7189 0.5027 1.0259
## cityKolding 0.6897 0.4756 0.9950
## cityVejle 0.7616 0.5251 1.0990
## age55-59 3.0072 1.8430 4.9010
## age60-64 4.5659 2.9072 7.2363
## age65-69 5.8574 3.7483 9.2489
## age70-74 6.4036 4.0430 10.2119
## age75+ 4.1357 2.5229 6.7624两个自变量都是因子, 都是和基线水平的比较, 比如,age55-59的倍数3.0072, 是与基线水平age40-54的发病率比值。 从相邻年龄组之间的倍数变化看,年龄每提高5岁, 肺癌发病率平均提高60%到300%, 尤其以从44-54年龄组到55-60年龄组的危险率增加最多。
38.2.7 其它问题
在泊松回归这样的因变量为计数变量问题中, 可能会出现如下的问题:
- 零过多数据(zero inflated data)。 数据中存在比泊松分布应有的个数更多的零。 这一般是来自于两个总体的混合, 其中一个总体服从泊松分布, 而另一个总体总是等于零。
- 过度离势(over dispersion)问题。 数据中因变量的方差显著地高于泊松分布应有的方差。 这可能来自于缺少了重要的解释变量导致不同组被混在一起变成了混合泊松分布, 或者观测的独立性不成立, 等等。 如果存在过度离势, 参数估计的标准误差会过于低估, 导致显著性检验结果过于乐观, 使得本来不显著的自变量变得显著。
38.3 逻辑斯谛回归
38.3.1 模型
当因变量Y是零壹变量(二值变量)时, 即Y表示分两类的类别, 用取值1和0表示, 将取值1称为成功, 我们关心的是成功概率p=P(Y=1)。 这是一个[0,1]区间内的值。 如果把Y当作一般因变量做线性回归, 会给出不合理的结果,比如负值, 另外线性回归假定误差项为正态分布在这里也不适用。
如果Y是m次试验中成功的次数, 这时可以设Y服从二项分布B(m,p), 关心的是成功概率p, 也可以归入相同的模型。
为此考虑对应于二项分布的广义线性回归模型:
Y∼g(p)=B(m,p)β0+β1×1+⋯+βkxk.
其中m为试验次数,Y为m次试验中成功次数, p为给定x1,…,xk条件下的成功概率。 一般取联系函数g(p)为logit函数
logit(p)=ln(p1−p).此模型称为逻辑斯谛回归模型。 p1−p是成功概率与失败概率的比值, 称为发生比(odds,或优势)。 lnp1−p称为对数发生比。
逻辑斯谛回归模型有如下的模型假定:
- 因变量表示成败型结果,为零壹变量或者已知试验次数中成功次数;
- 各个观测独立;
- 如果某个观测的试验次数为m,成功概率为p, 则因变量方差为mp(1−p), 方差不等于常数值,与期望值mp有关系;
- 对数发生比lnp1−p与自变量之间为线性关系。
比如, 仅有一个自变量x时, 数据可以是(xi,yi),i=1,2,…,n, 其中yi仅取0或取1, 模型为
yi∼logit(pi)=b(1,pi),a+bxi, i=1,2,…,n.
数据也可以是 (xi,yi,zi),i=1,2,…,n, 其中yi代表第i个观测的成功数, zi代表失败数, 模型为
yi∼logit(pi)=B(mi,pi),a+bxi, i=1,2,…,n.
其中mi=yi+zi是第i个观测的试验次数, 是非随机的正整数值。
38.3.2 最大似然估计
先考虑观测的因变量是二值因变量情形。 数据为(xi,yi), i=1,…,n, 一个观测对似然函数的贡献为
pyii(1−pi)1−yi,
其中
pi=logit−1(a+bxi)=ea+bxi1+ea+bxi,对数似然函数为
ℓ(a,b)===∑i=1n{yilnpi+(1−yi)ln(1−pi)}∑i=1n{yilnpi1−pi+ln(1−pi)}∑i=1n{yi(a+bxi)−ln(1+ea+bxi)}.
若观测是二项数据(xi,mi,yi), 其中yi∼B(mi,pi),
pi=logit−1(a+bxi),
则第i个观测对似然函数的贡献为
(miyi)pyii(1−pi)mi−yi,对于对数似然函数的贡献为
==ln(miyi)+yilnpi+(mi−yi)ln(1−pi)ln(miyi)+yilnpi1−pi+miln(1−pi)ln(miyi)+yiln(a+bxi)−miln(1+ea+bxi),忽略与待估参数a,b无关的常数项后, 对数似然函数为 因变量的对数似然函数为
ℓ(a,b)==∑i=1n[yilnpi+(mi−yi)ln(1−pi)]∑i=1n[yiln(a+bxi)−miln(1+ea+bxi)].(38.1)
需要用数值迭代算法求最大似然估计。 若样本为满足模型的随机样本, 最大似然估计是相合估计, 渐近有效估计, 具有渐近正态分布。
得到最大似然估计(â ,b̂ )后, 一般用信息阵的逆矩阵估计其协方差阵, 信息阵为:
I(a,b)=−E[∂2ℓ(a,b)∂(a,b)∂(a,b)T],
在用数值迭代算法计算最大似然估计时, 一般会得到最大值点处的对数似然函数的海色阵, 加上负号并求逆矩阵, 就可以作为参数协方差阵估计。
有了参数估计的协方差阵估计, 就得到了参数估计的标准误差。 设参数估计为θ̂ , 估计的方差开平方根作为其抽样分布标准差估计, 称为标准误差,记为SE(θ̂ )。 令
Z=θ̂ SE(θ̂ ),
可以用Z统计量检验H0:θ=0, 在H0成立、大样本且满足适当正则性条件时Z近似服从标准正态分布。 也可以用Z2近似服从χ2(1)分布进行检验。 这样对回归系数进行的检验称为Wald类型的检验。 此检验对中小样本有一定缺陷, 当参数的实际数值绝对值较大时, 容易错判成不显著。 另一种可用的方法是下面所述的利用偏差统计量的方法。
38.3.3 偏差分析
当因变量是多次试验的二项分布结果时, 虽然可以计算比例与模型预测概率的差, 但残差平方和与线性正态情形的回归模型的残差平方和不同, 所以用偏差(deviance)代替了残差平方和。
对yi∼B(mi,pi), 设p̂ i=logit−1(â +b̂ xi), ŷ i=mip̂ i, 定义逻辑斯谛回归的偏差为
G2=2∑i=1n[yilog(yiŷ i)+(mi−yi)log(mi−yimi−ŷ i)].
当因变量观测值yi与预测值ŷ i都很接近时, 偏差G2的值比较小; 当模型不准确时,偏差的值比较大。 记此模型为M, 设模型M有p个回归系数, 模型M拟合充分时一定条件下偏差服从自由度为n−p的卡方分布。 下面解释上述偏差公式。
在R软件的glm()函数计算时, “饱和模型”(称为模型S)就是对每个观测估计一个不同的ŷ i, 即p̂ i=yi/mi, ŷ i=yi。这样有n个参数。 但是要注意, 饱和模型使用n个参数, 默认假定了各个观测的自变量组合都是互不相同的, 因为某一个特定的自变量组合如果在多个观测中重复出现应该给出相同的预测值, R中并没有自动进行各个观测的自变量组合互不相同的验证。
在模型S下, 最大化的对数似然函数值为(38.1)式中pi=yi/mi; 在模型M下, 最大化的对数似然函数值为(38.1)式中pi=p̂ i; 于是两个模型的对数似然函数差的−2倍为
G2===−2[maxln(LM)−maxln(LS)]−2∑i=1n[yilogp̂ i+(mi−yi)log(1−p̂ i)]+2∑i=1n[yilogyimi+(mi−yi)log(1−yimi)]2∑i=1n[yiyiŷ i+(mi−yi)log(mi−yimi−ŷ i)]
其中ŷ i=mip̂ i是模型M的预测值。 可见偏差是模型M与饱和模型S比较的对数似然比统计量, 相应的检验是似然比检验。 在“模型M与模型S相同”的零假设成立时, G2在大样本情况下近似服从χ2(n−p)分布, p为回归参数β的维数, 在上述推导中有两个回归参数a,b,所以p=2。 在R软件输出中偏差显示为“残差偏差”(residual deviance)。 可以将残差偏差按照n−p自由度的卡方分布计算右侧p值, 因为是将模型与饱和模型比较, 所以p值小于检验水平α时认为模型拟合不足。
如果有两个模型M和C, C是M的特例(比如令M中某个参数等于0), 称这两个模型有嵌套关系, 模型C嵌套于M中。 所有模型都是饱和模型S的嵌套模型。 这时, 计算M和C的残差偏差G2M和G2C, 则其差值G2M−G2C在两个模型相同的零假设下近似服从卡方分布, 自由度等于两个模型的参数个数之差。 可以用这样的方法检验两个嵌套模型是否有显著差异。 在R中用anova()函数加test="Chisq"选项进行这样的检验。
R的输出结果有null deviance, 这是空模型(仅有截距项、没有自变量的模型)的残差偏差, 即空模型与完全模型的比较。 null deviance是所有模型的residual deviance中最大的。 将模型偏差(残差偏差)与空模型的偏差进行比较, 就可以检验所有自变量的系数(除截距项以外的回归系数)同时为0的零假设。 显然, 空模型嵌套在所有其它模型中。
因为偏差统计量的近似卡方分布是大样本性质, 有文献认为, 偏差统计量在自变量都是类别变量, 数据为列联表数据, 且每个单元格观测数都达到5或10以上时比较准确; 如果自变量中有连续测量的自变量, 使得每个单元格重复试验次数很少, 偏差统计量的分布不一定准确。
38.3.4 足球罚球得分概率案例
考虑足球比赛罚球得分的概率, 研究得分概率是否与罚球球队当前是否比分领先有关系。 若干次罚球的汇总表格数据如下:
| 得分 | 未得分 | 总数 | |
|---|---|---|---|
| 领先 | 22 | 2 | 24 |
| 不领先 | 141 | 39 | 180 |
| 总数 | 163 | 41 | 204 |
不同于概率统计中用概率表示可能性, 在比赛、赌博中经常使用发生比(odds,或称优势、几率、赔率)的概念。 在本例中, 罚球时比分领先的情况下, 罚球成功了22例,失败了2例, 则罚球成功的发生比是22:2=11:1=1:0.09, 其含义是每罚球失败一次, 平均有11次成功; 每罚球成功一次, 平均有0.0909次失败。 从概率论的角度, 以p为罚球成功概率, 则发生比是p1−p。
当罚球的球队比分不领先时, 罚球成功的发生比为141:39=3.62:1=1:0.28, 这个发生比远低于领先的情况。 计算领先时的发生比和不领先时的发生比的比值:
22/2141/39=3.04,
称这个比例为优势比(odds ratio), 可以看出比分领先情况下的罚球成功概率相对较高。
发生比是一个取值于(0,∞)的正数, 优势比也是取值于(0,∞)的正数, 都是以1作为比较的基准值。 发生比为1,表明成功和失败概率相等, 发生比越大,成功概率越大。 优势比等于1, 表明两个组的成功概率相等; 优势比越大, 表明第一个组的成功概率越大。 但是, 两个组的发生比等于3.04, 不能说第一个组的成功概率是第二个组成功概率的3.04倍, 因为设两个组的成功概率分别为p1,p2, 则两个组的优势比等于
p1/(1−p1)p2/(1−p2)=p1p21−p21−p1,
比两个组的概率之比p1p2还多了1−p21−p1这一项。
定义自变量
X={1,0,罚球球队比分领先,比分不领先,
则问题用逻辑回归表示, 可以写成
Y∼lnp1−p=B(m,p),β0+β1X.问题的数据比较简单, 可以看成只有X=0和X=1两个观测, 于是当X=0(罚球球队比分不领先时), 记这时罚球成功概率为p0, 则
lnp01−p0=β0;当X=1,即罚球球队比分领先时, 记这时罚球成功概率为p1,则
lnp11−p1=β0+β1;由此可以解释β1的含义为:
β1==(β0+β1)−β0=lnp11−p1−lnp01−p0lnp11−p1p01−p0,其中p11−p1p01−p0是比分领先相对于比分不领先时的优势比(odds ratio), 所以eβ1等于优势比。
用二项分布的分布概率可以写出模型的似然函数为
L(β0,β1)=∝(2422)p221(1−p1)2 (180141)p1410(1−p1)39(eβ0+β11+eβ0+β1)22(1−eβ0+β11+eβ0+β1)2(eβ01+eβ0)141(1−eβ01+eβ0)39.
可以用数值优化方法求得最大似然估计 β̂ 0=1.2852, β̂ 1=1.1127。 从而优势比的估计为e1.1127=3.04, 与直接计算优势比完全相同。
使用R的glm()函数来计算这个例子。 将因变量输入为由成功数与失败数两列组成的矩阵。
dga <- tibble(
lead = factor(c("Lead", "Not Lead"),
levels = c("Not Lead", "Lead")),
score = c(22, 141),
fail = c(2, 39) )
glmga1 <- glm(cbind(score, fail) ~ lead,
family = binomial,
data = dga)
summary(glmga1)##
## Call:
## glm(formula = cbind(score, fail) ~ lead, family = binomial, data = dga)
##
## Deviance Residuals:
## [1] 0 0
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 1.2852 0.1809 7.104 1.22e-12 ***
## leadLead 1.1127 0.7604 1.463 0.143
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 2.7930e+00 on 1 degrees of freedom
## Residual deviance: 4.2188e-15 on 0 degrees of freedom
## AIC: 11.789
##
## Number of Fisher Scoring iterations: 4在这个例子中, 饱和模型只需要给领先和不领先分别指定得分概率, 有两个自由参数; 要拟合的模型也是恰好有β0和β1两个参数, 所以两个模型是等价的, 残差偏差(Residual deviance)等于负二倍的最大对数似然函数值的差, 等于零。 空模型的偏差(Null deviance)有一个自由度, 所谓空模型是只有截距项β0的模型, 有一个自由参数, 所以和饱和模型相比相差一个自由度。
领先与不领先时的罚球得分概率是否有显著差异? H0:β1=0代表优势比等于1, 这时两种情况的得分概率相同。 虽然优势比达到3.04, 但是程序结果中系数β1的显著性p值只有0.143, 在0.05水平下不显著。 这里的标准误差是利用最大似然估计得到的信息矩阵估计给出的估计, z统计量和相应p值利用了参数估计的渐近正态分布。
用如下方法产生优势比与优势比的置信区间:
exp(cbind(OR = coef(glmga1), confint(glmga1)))## Waiting for profiling to be done...## OR 2.5 % 97.5 %
## (Intercept) 3.615385 2.5637929 5.221335
## leadLead 3.042553 0.8453435 19.505910可见领先相对于非领先的优势比为3.04, 95%置信区间为(0.85,19.51), 置信区间包含1说明两组的罚球成功概率没有显著差异。
因为这是一个四格表数据, 我们还可以用Fisher精确检验比较领先与非领先的罚球成功概率, 或将优势比与1比较:
fisher.test(as.matrix(dga[,2:3]))##
## Fisher's Exact Test for Count Data
##
## data: as.matrix(dga[, 2:3])
## p-value = 0.1758
## alternative hypothesis: true odds ratio is not equal to 1
## 95 percent confidence interval:
## 0.693731 27.710569
## sample estimates:
## odds ratio
## 3.029845Fisher精确检验是基于多项分布, 得到的p值与逻辑斯谛回归结果相近但不相等。
38.3.5 餐馆评分问题
数据框Michelin中包含了Zagat Survey 2006考察的164家法餐馆的顾客评分和是否被米其林推荐收录。 数据中每一行是一个评分值对应的数据, 变量Food是Zagat评分,取值从15到28, InMichelin是某一评分被米其林收录家数, NotInMichelin是未被米其林收录家数, mi是该评分的总家数, proportion是收录比例。
以是否收录作为因变量, 以Zagat评分作为自变量,建立逻辑斯谛回归:
glm.mic1 <- glm(
cbind(InMichelin,NotInMichelin) ~ Food,
family=binomial,
data=MichelinFood)
summary(glm.mic1)##
## Call:
## glm(formula = cbind(InMichelin, NotInMichelin) ~ Food, family = binomial,
## data = MichelinFood)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.4850 -0.7987 -0.1679 0.5913 1.5889
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -10.84154 1.86236 -5.821 5.84e-09 ***
## Food 0.50124 0.08768 5.717 1.08e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 61.427 on 13 degrees of freedom
## Residual deviance: 11.368 on 12 degrees of freedom
## AIC: 41.491
##
## Number of Fisher Scoring iterations: 4自变量Food的系数为0.5012, 检验结果显著。
结果中残差偏差11.4,自由度12, 残差偏差与自由度相比不大, 说明模型拟合较好。
优势比和优势比置信区间:
cbind(OR = coef(glm.mic1), confint(glm.mic1)) |>
exp() |> round(4)## Waiting for profiling to be done...## OR 2.5 % 97.5 %
## (Intercept) 0.0000 0.0000 0.0006
## Food 1.6508 1.4065 1.9871自变量Food的优势比为1.65, 表示Zaga评分每提高1分, 被米其林收录的发生比将提高到原来的e0.5012=1.65倍, 即发生比提高65%; 优势比的置信区间为(1.41,1.99)不包含1, 所以优势比与1有显著差异。
因为数据是二项数据, 有重复, 所以我们可以将数据中的收录比例与模型预测的收录概率进行对照, 作图表示:
dmicpr <- tibble(
Food = seq(15, 28, length.out=100))
dmicpr <- dmicpr |>
mutate(p = predict(glm.mic1, newdata = dmicpr,
type = "response"))
ggplot(data = MichelinFood, mapping = aes(
x = Food, y = proportion)) +
geom_point() +
geom_line(data = dmicpr, mapping = aes(
x = Food, y = p ))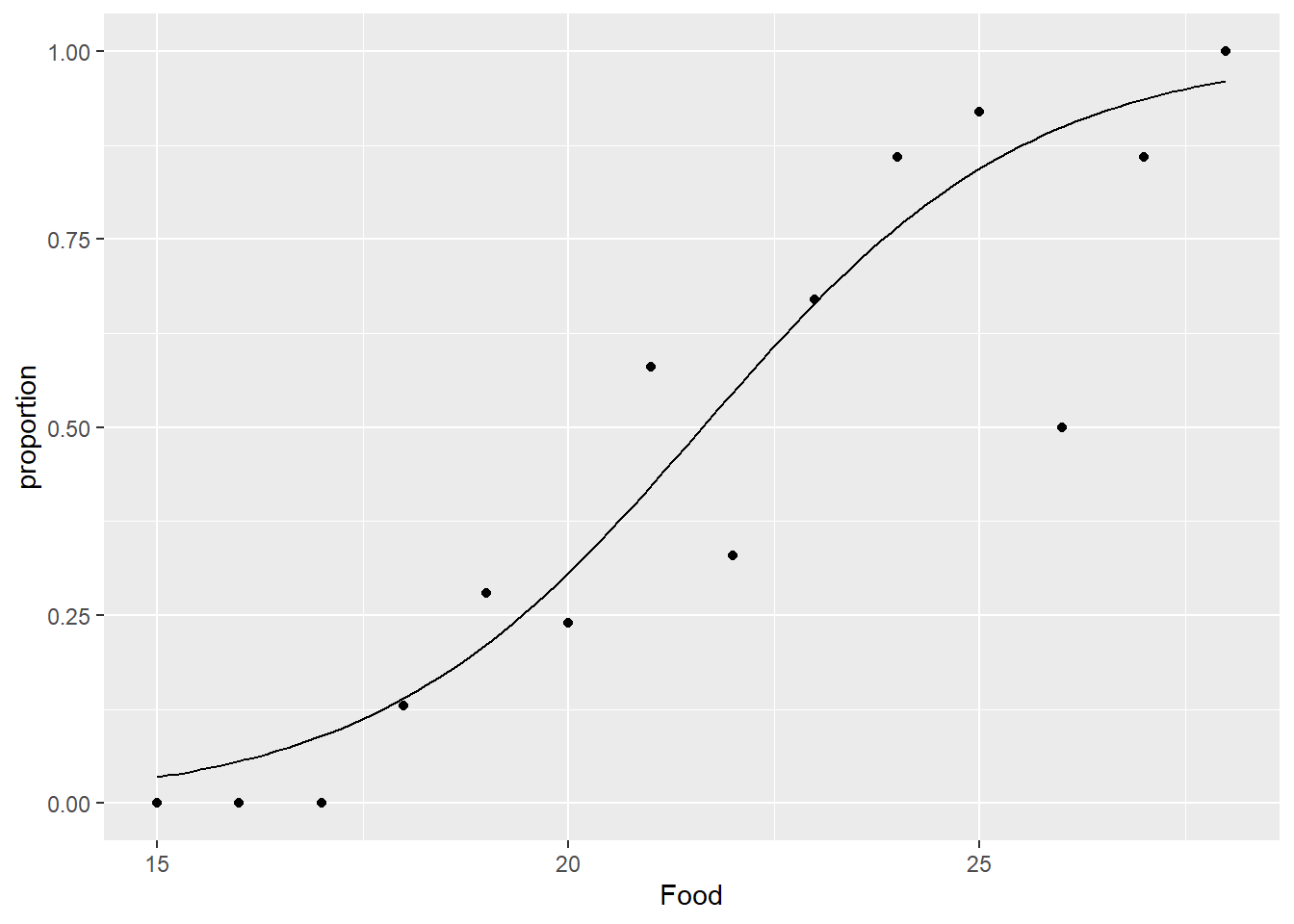
38.3.6 修建铁路意见投票情况案例
考虑在某地的4个不同区域进行关于是否修建铁路的意见征询投票的数据分析, 赞同修建铁路的比例可能受到所在区域到要修建的铁路的距离(单位:英里)的影响, 距离越远越容易反对修建, 可能受到投票人中黑人比例的影响。 数据如下:
| 黑人百分比 | 距离 | 赞成票数 | 总票数 |
|---|---|---|---|
| 58.40 | 17 | 61 | 110 |
| 92.40 | 7 | 0 | 15 |
| 18.28 | 15 | 4 | 42 |
| 59.38 | 0 | 1790 | 1804 |
| 55.51 | 7 | 0 | 15 |
| 58.40 | 12 | 16 | 68 |
| 83.39 | 2 | 31 | 42 |
| 94.54 | 9 | 87 | 154 |
| 88.54 | 0 | 107 | 118 |
| 77.19 | 4 | 90 | 102 |
| 38.75 | 7 | 6 | 23 |
仅使用距离作为自变量进行逻辑斯谛回归:
glmrr1 <- glm(
cbind(YesVotes, NumVotes - YesVotes) ~ distance,
family = binomial, data = drr)
summary(glmrr1)##
## Call:
## glm(formula = cbind(YesVotes, NumVotes - YesVotes) ~ distance,
## family = binomial, data = drr)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -6.793 -4.753 -2.852 -1.625 9.097
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 3.30927 0.11313 29.25 <2e-16 ***
## distance -0.28758 0.01302 -22.09 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 988.45 on 10 degrees of freedom
## Residual deviance: 318.44 on 9 degrees of freedom
## AIC: 360.73
##
## Number of Fisher Scoring iterations: 5模型说明距离对支持比例起到负面作用, 距离每增加一英里, 支持修建铁路的发生比降低到原来的e−0.28758=75%。 此自变量是显著的。
因为数据总共11个观测, 所以R程序将完全模型的参数个数定为11, 空模型是仅有截距项的模型,参数个数为1, 空模型的偏差(null deviance)的自由度为11−1=10。 上面的模型有两个回归系数β0,β1, 参数个数为2, 所以模型的偏差(Residual deviance)自由度为11−2=9。 与自由度相比,偏差统计量的值很大,说明模型拟合不足。
仅使用黑人比例建立逻辑斯谛回归模型:
glmrr2 <- glm(
cbind(YesVotes, NumVotes - YesVotes) ~ pctBlack,
family = binomial, data = drr)
summary(glmrr2)##
## Call:
## glm(formula = cbind(YesVotes, NumVotes - YesVotes) ~ pctBlack,
## family = binomial, data = drr)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -12.7774 -8.4961 -7.5295 -0.7781 18.4292
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 2.565957 0.307642 8.341 <2e-16 ***
## pctBlack -0.009091 0.004679 -1.943 0.052 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 988.45 on 10 degrees of freedom
## Residual deviance: 984.74 on 9 degrees of freedom
## AIC: 1027
##
## Number of Fisher Scoring iterations: 6系数为−0.009091, 模型说明黑人比例对支持比例有负面影响, 黑人比例每增加一个百分点, 支持修建铁路的发生比降低到原来的e−0.009091=99%。 从Z检验(Wald类型检验)结果看显著性p值0.052显著性不明显。
使用两个自变量进行逻辑斯谛回归建模:
glmrr3 <- glm(
cbind(YesVotes, NumVotes - YesVotes)
~ pctBlack + distance,
family = binomial, data = drr)
summary(glmrr3)##
## Call:
## glm(formula = cbind(YesVotes, NumVotes - YesVotes) ~ pctBlack +
## distance, family = binomial, data = drr)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -7.0509 -5.3271 -3.7259 -0.2912 8.7718
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 4.222021 0.296963 14.217 < 2e-16 ***
## pctBlack -0.013227 0.003897 -3.394 0.000688 ***
## distance -0.291735 0.013100 -22.270 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 988.45 on 10 degrees of freedom
## Residual deviance: 307.22 on 8 degrees of freedom
## AIC: 351.51
##
## Number of Fisher Scoring iterations: 5注意这时回归系数的解释受到自变量之间的相关性的影响。 pctBlack的系数−0.013227, 对应于优势比e−0.013227=0.987, 需要解释成控制距离自变量后, 黑人比例每增加一个单位, 发生比降低1.3%, 与仅有黑人比例的模型相比, 对支持发生比的影响与原来方向相同但影响更大了一些。 在控制了黑人比例后, 距离自变量对支持发生比的影响与原来接近。
从模型的残差偏差来看, 如果模型很好地拟合观测数据, 残差偏差应该近似服从卡方分布, 自由度也在输出结果中给出, 上述结果中过大的残差偏差(residual deviance)说明模型拟合不足。 改进的方向是考虑两个自变量的交互作用, 考虑方差膨胀模型(over dispresion),等等。
可以用残差偏差的卡方检验方法比较有或者没有黑人比例自变量的模型:
anova(glmrr1, glmrr3, test = "Chisq")## Analysis of Deviance Table
##
## Model 1: cbind(YesVotes, NumVotes - YesVotes) ~ distance
## Model 2: cbind(YesVotes, NumVotes - YesVotes) ~ pctBlack + distance
## Resid. Df Resid. Dev Df Deviance Pr(>Chi)
## 1 9 318.44
## 2 8 307.22 1 11.222 0.0008083 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1结果显著,说明增加黑人比例是有作用的。
逻辑斯谛回归采用了二项分布, 估计和统计推断依据二项分布及其大样本近似进行。 实际建模中, 有时数据会有过度离势(over dispersion)问题, 即因变量成功个数的实际方差大于二项分布理论方差。 设第i个观测有mi次试验, 成功次数为yi, 估计的成功概率为p̂ i, 则yi的拟合值为mip̂ i, 方差应该约为mip̂ i(1−p̂ i), 如果实际数据中yi与拟合值的差距表现得远大于上述方差, 则称数据有过度离势。
R提供了一种简单的拟合过度离势的方法, 是利用偏差统计量与自由度比值估计过度离势参数。 这时, 实际的似然函数已经偏离了理论上的二项分布。 在R的glm()程序中用family=quasibinomial指定这种方法。 例如:
glmrr11 <- glm(
cbind(YesVotes, NumVotes - YesVotes) ~ distance + pctBlack,
family = quasibinomial, data = drr)
summary(glmrr11)##
## Call:
## glm(formula = cbind(YesVotes, NumVotes - YesVotes) ~ distance +
## pctBlack, family = quasibinomial, data = drr)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -7.0509 -5.3271 -3.7259 -0.2912 8.7718
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.22202 1.99031 2.121 0.0667 .
## distance -0.29173 0.08780 -3.323 0.0105 *
## pctBlack -0.01323 0.02612 -0.506 0.6262
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for quasibinomial family taken to be 44.9194)
##
## Null deviance: 988.45 on 10 degrees of freedom
## Residual deviance: 307.22 on 8 degrees of freedom
## AIC: NA
##
## Number of Fisher Scoring iterations: 5结果中的Dispersion parameter就是过度离势参数, 估计为44.9194, 远大于1。 采用过度离势调整后, 自变量“黑人比例”不再是显著的。
38.3.7 癌症病人康复概率自变量选择
文件“data/remiss.csv”中保存了癌症病人康复的数据, 变量remiss为康复与否(1为康复,0为未康复), 另外的6个变量为可能影响康复概率的自变量。 研究这些自变量对康复概率的影响, 并筛选最有解释能力的自变量。
读入数据:
d.remiss <- read_csv("data/remiss.csv")## Rows: 27 Columns: 7
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## dbl (7): remiss, cell, smear, infil, li, blast, temp
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.knitr::kable(d.remiss)| remiss | cell | smear | infil | li | blast | temp |
|---|---|---|---|---|---|---|
| 1 | 0.80 | 0.83 | 0.66 | 1.9 | 1.100 | 0.996 |
| 1 | 0.90 | 0.36 | 0.32 | 1.4 | 0.740 | 0.992 |
| 0 | 0.80 | 0.88 | 0.70 | 0.8 | 0.176 | 0.982 |
| 0 | 1.00 | 0.87 | 0.87 | 0.7 | 1.053 | 0.986 |
| 1 | 0.90 | 0.75 | 0.68 | 1.3 | 0.519 | 0.980 |
| 0 | 1.00 | 0.65 | 0.65 | 0.6 | 0.519 | 0.982 |
| 1 | 0.95 | 0.97 | 0.92 | 1.0 | 1.230 | 0.992 |
| 0 | 0.95 | 0.87 | 0.83 | 1.9 | 1.354 | 1.020 |
| 0 | 1.00 | 0.45 | 0.45 | 0.8 | 0.322 | 0.999 |
| 0 | 0.95 | 0.36 | 0.34 | 0.5 | 0.000 | 1.038 |
| 0 | 0.85 | 0.39 | 0.33 | 0.7 | 0.279 | 0.988 |
| 0 | 0.70 | 0.76 | 0.53 | 1.2 | 0.146 | 0.982 |
| 0 | 0.80 | 0.46 | 0.37 | 0.4 | 0.380 | 1.006 |
| 0 | 0.20 | 0.39 | 0.08 | 0.8 | 0.114 | 0.990 |
| 0 | 1.00 | 0.90 | 0.90 | 1.1 | 1.037 | 0.990 |
| 1 | 1.00 | 0.84 | 0.84 | 1.9 | 2.064 | 1.020 |
| 0 | 0.65 | 0.42 | 0.27 | 0.5 | 0.114 | 1.014 |
| 0 | 1.00 | 0.75 | 0.75 | 1.0 | 1.322 | 1.004 |
| 0 | 0.50 | 0.44 | 0.22 | 0.6 | 0.114 | 0.990 |
| 1 | 1.00 | 0.63 | 0.63 | 1.1 | 1.072 | 0.986 |
| 0 | 1.00 | 0.33 | 0.33 | 0.4 | 0.176 | 1.010 |
| 0 | 0.90 | 0.93 | 0.84 | 0.6 | 1.591 | 1.020 |
| 1 | 1.00 | 0.58 | 0.58 | 1.0 | 0.531 | 1.002 |
| 0 | 0.95 | 0.32 | 0.30 | 1.6 | 0.886 | 0.988 |
| 1 | 1.00 | 0.60 | 0.60 | 1.7 | 0.964 | 0.990 |
| 1 | 1.00 | 0.69 | 0.69 | 0.9 | 0.398 | 0.986 |
| 0 | 1.00 | 0.73 | 0.73 | 0.7 | 0.398 | 0.986 |
建立包含所有6个自变量的模型:
glmr1 <- glm(
remiss ~ cell+smear+infil+li+blast+temp,
family=binomial, data=d.remiss)
summary(glmr1)##
## Call:
## glm(formula = remiss ~ cell + smear + infil + li + blast + temp,
## family = binomial, data = d.remiss)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.95165 -0.66491 -0.04372 0.74304 1.67069
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 58.0385 71.2364 0.815 0.4152
## cell 24.6615 47.8377 0.516 0.6062
## smear 19.2936 57.9500 0.333 0.7392
## infil -19.6013 61.6815 -0.318 0.7507
## li 3.8960 2.3371 1.667 0.0955 .
## blast 0.1511 2.2786 0.066 0.9471
## temp -87.4339 67.5735 -1.294 0.1957
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 34.372 on 26 degrees of freedom
## Residual deviance: 21.751 on 20 degrees of freedom
## AIC: 35.751
##
## Number of Fisher Scoring iterations: 8可以用drop1()函数选择要删去的变量:
drop1(glmr1, test="Chisq")## Single term deletions
##
## Model:
## remiss ~ cell + smear + infil + li + blast + temp
## Df Deviance AIC LRT Pr(>Chi)
## <none> 21.751 35.751
## cell 1 22.071 34.071 0.3202 0.57147
## smear 1 21.869 33.869 0.1180 0.73121
## infil 1 21.857 33.857 0.1065 0.74417
## li 1 26.095 38.095 4.3446 0.03713 *
## blast 1 21.755 33.755 0.0044 0.94716
## temp 1 23.877 35.877 2.1264 0.14478
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1先删除blast:
glmr2 <- update(glmr1, . ~ . - blast)
summary(glmr2)##
## Call:
## glm(formula = remiss ~ cell + smear + infil + li + temp, family = binomial,
## data = d.remiss)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.93753 -0.65855 -0.04328 0.75287 1.65475
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 57.128 69.977 0.816 0.414
## cell 24.180 47.257 0.512 0.609
## smear 18.370 56.218 0.327 0.744
## infil -18.477 59.260 -0.312 0.755
## li 3.987 1.902 2.097 0.036 *
## temp -86.137 64.785 -1.330 0.184
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 34.372 on 26 degrees of freedom
## Residual deviance: 21.755 on 21 degrees of freedom
## AIC: 33.755
##
## Number of Fisher Scoring iterations: 8drop1(glmr2, test="Chisq")## Single term deletions
##
## Model:
## remiss ~ cell + smear + infil + li + temp
## Df Deviance AIC LRT Pr(>Chi)
## <none> 21.755 33.755
## cell 1 22.073 32.073 0.3175 0.573134
## smear 1 21.869 31.869 0.1141 0.735530
## infil 1 21.858 31.858 0.1029 0.748323
## li 1 30.216 40.216 8.4606 0.003629 **
## temp 1 24.198 34.199 2.4435 0.118016
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1删去infil:
glmr3 <- update(glmr2, . ~ . - infil)
summary(glmr3)##
## Call:
## glm(formula = remiss ~ cell + smear + li + temp, family = binomial,
## data = d.remiss)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.87933 -0.66813 -0.07052 0.78408 1.72472
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 70.0994 58.7634 1.193 0.2329
## cell 9.8507 7.8263 1.259 0.2082
## smear 0.9124 2.9600 0.308 0.7579
## li 3.9052 1.8167 2.150 0.0316 *
## temp -85.4447 64.2143 -1.331 0.1833
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 34.372 on 26 degrees of freedom
## Residual deviance: 21.858 on 22 degrees of freedom
## AIC: 31.858
##
## Number of Fisher Scoring iterations: 7drop1(glmr3, test="Chisq")## Single term deletions
##
## Model:
## remiss ~ cell + smear + li + temp
## Df Deviance AIC LRT Pr(>Chi)
## <none> 21.858 31.858
## cell 1 24.477 32.477 2.6185 0.105622
## smear 1 21.953 29.953 0.0954 0.757449
## li 1 30.434 38.434 8.5757 0.003407 **
## temp 1 24.292 32.292 2.4345 0.118695
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1删去smear:
glmr4 <- update(glmr3, . ~ . - smear)
summary(glmr4)##
## Call:
## glm(formula = remiss ~ cell + li + temp, family = binomial, data = d.remiss)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.02043 -0.66313 -0.08323 0.81282 1.65887
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 67.634 56.888 1.189 0.2345
## cell 9.652 7.751 1.245 0.2130
## li 3.867 1.778 2.175 0.0297 *
## temp -82.074 61.712 -1.330 0.1835
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 34.372 on 26 degrees of freedom
## Residual deviance: 21.953 on 23 degrees of freedom
## AIC: 29.953
##
## Number of Fisher Scoring iterations: 7drop1(glmr4, test="Chisq")## Single term deletions
##
## Model:
## remiss ~ cell + li + temp
## Df Deviance AIC LRT Pr(>Chi)
## <none> 21.953 29.953
## cell 1 24.648 30.648 2.6945 0.100698
## li 1 30.829 36.829 8.8752 0.002891 **
## temp 1 24.341 30.341 2.3874 0.122321
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1剩下的cell, li, temp这三个变量可以保留。
可用直接使用逐步回归进行自变量筛选:
glmr5 <- step(glm(
remiss ~ cell + smear + infil + li + blast + temp,
family=binomial, data=d.remiss))## Start: AIC=35.75
## remiss ~ cell + smear + infil + li + blast + temp
##
## Df Deviance AIC
## - blast 1 21.755 33.755
## - infil 1 21.857 33.857
## - smear 1 21.869 33.869
## - cell 1 22.071 34.071
## <none> 21.751 35.751
## - temp 1 23.877 35.877
## - li 1 26.095 38.095
##
## Step: AIC=33.76
## remiss ~ cell + smear + infil + li + temp
##
## Df Deviance AIC
## - infil 1 21.858 31.858
## - smear 1 21.869 31.869
## - cell 1 22.073 32.073
## <none> 21.755 33.755
## - temp 1 24.198 34.199
## - li 1 30.216 40.216
##
## Step: AIC=31.86
## remiss ~ cell + smear + li + temp
##
## Df Deviance AIC
## - smear 1 21.953 29.953
## <none> 21.858 31.858
## - temp 1 24.292 32.292
## - cell 1 24.477 32.477
## - li 1 30.434 38.434
##
## Step: AIC=29.95
## remiss ~ cell + li + temp
##
## Df Deviance AIC
## <none> 21.953 29.953
## - temp 1 24.341 30.341
## - cell 1 24.648 30.648
## - li 1 30.829 36.829summary(glmr5)##
## Call:
## glm(formula = remiss ~ cell + li + temp, family = binomial, data = d.remiss)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.02043 -0.66313 -0.08323 0.81282 1.65887
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 67.634 56.888 1.189 0.2345
## cell 9.652 7.751 1.245 0.2130
## li 3.867 1.778 2.175 0.0297 *
## temp -82.074 61.712 -1.330 0.1835
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 34.372 on 26 degrees of freedom
## Residual deviance: 21.953 on 23 degrees of freedom
## AIC: 29.953
##
## Number of Fisher Scoring iterations: 738.4 多水平有序因变量的逻辑斯谛回归
逻辑斯谛回归是因变量为二值变量时的广义线性模型。 在有些应用问题中, 因变量是有序变量, 比如满意程度取“低”、“中”、“高”, 这时不应该分别对“中对低”、“高对低”用二值的逻辑斯谛回归建模, 因为“高”和“中”之间也是可比的, 分别建模的结果不一定能保证这个次序。
采用如下的理论模型。 设某个潜在的连续取值的因变量为Z, 服从如下的逻辑斯谛分布:
F(x;η)=logit−1(x−η),
易见EZ=η。 设观测到的取有序因子值的因变量Y是将Z的值按照如下的分点
ζ0=−∞<ζ1<⋯<ζK−1<ζK=+∞将实数轴分为K段,各段分别编码为1,2,…,K, 则
P(Y≤k)=logit[P(Y≤k)]=P(Z≤ζk)=logit−1(ζk−η),ζk−η.
设潜在变量Z的均值η依赖于自变量的线性组合, 则有如下的有序因子值的因变量的“比例发生比逻辑斯谛回归”(POLR)模型:
logit[P(Y≤k|x)]=ζk−βx,k=2,3,…,K.(38.2)
这里k=1作为一个基线值。 因为ζk未知,所以回归的截距项也归入到{ζk}中。 模型左边是因变量类别为k以及低于k的概率的对数发生比, 如果自变量的值不变, 对于不同的k这些对数发生比只差一个常数, 发生比只差一个倍数, 所以称为“比例发生比逻辑斯谛回归”模型; 因为是对P(Y≤k)从k=1,2,…,K依次建模, 所以也称为累积逻辑斯谛回归模型。
注意(38.2)式左侧是小于等于的概率的一个单调增函数, 右侧用了自变量线性组合的相反数, 所以正系数代表了当自变量值增大时因变量取较高类别的概率变大。
MASS包的polr()函数可以建立这种模型。 以MASS包的housing数据为例, 这是一个有四个分类变量的交叉频数表, 调查房主满意度有关情况, 四个分类变量是:
Sat:房主满意度,取值为Low, Medium, High,是有序因子;Infl:房主对物业服务影响的评价,取值为Low, Medium, High;Type:房屋类型,包括Tower, Atrium, Apartment, Terrace;Cont:住户之间的交往情况,取值为Low, High。
housing是长表格式, 每个分类变量占一列, 另外Freq列保存单元格频数。
library(MASS)##
## Attaching package: 'MASS'## The following object is masked from 'package:dplyr':
##
## selectdata(housing, package="MASS")
options(contrasts = c("contr.treatment", "contr.poly"))
house.fm1 <- Sat ~ Infl + Type + Cont
house.plr <- polr(
house.fm1,
weights = Freq, data = housing)
summary(house.plr)##
## Re-fitting to get Hessian## Call:
## polr(formula = house.fm1, data = housing, weights = Freq)
##
## Coefficients:
## Value Std. Error t value
## InflMedium 0.5664 0.10465 5.412
## InflHigh 1.2888 0.12716 10.136
## TypeApartment -0.5724 0.11924 -4.800
## TypeAtrium -0.3662 0.15517 -2.360
## TypeTerrace -1.0910 0.15149 -7.202
## ContHigh 0.3603 0.09554 3.771
##
## Intercepts:
## Value Std. Error t value
## Low|Medium -0.4961 0.1248 -3.9739
## Medium|High 0.6907 0.1255 5.5049
##
## Residual Deviance: 3479.149
## AIC: 3495.149在结果中, Intercepts是潜在因变量Z的分点ζ1,…,ζK−1, 即Y的各组之间的Z分界点, 这里Y有三个组, 所以给出了两个分界点。
Infl(物业服务影响)分低、中、高三档, 以“低”为基线,两个系数为正值, 可以看出物业服务影响越大, 高满意度概率越大。
住房类型分Tower, Atrium, Apartment, Terrace等类型, 以Tower为基线, 从系数看, Apartment, Atrium 和Terrace都相对于Tower满意度较低, 满意度次高的是Atrium,最低的是Terrace。
住户交往情况分为低、高两类, 从系数看, 高的交往对应较高的满意度。
使用anova进行每个自变量的显著性检验:
house.plr2 <- update(house.plr, . ~ . - Infl)
anova(house.plr2, house.plr)## Likelihood ratio tests of ordinal regression models
##
## Response: Sat
## Model Resid. df Resid. Dev Test Df LR stat. Pr(Chi)
## 1 Type + Cont 1675 3587.389
## 2 Infl + Type + Cont 1673 3479.149 1 vs 2 2 108.2392 0物业服务影响Infl显著。
house.plr3 <- update(house.plr, . ~ . - Type)
anova(house.plr3, house.plr)## Likelihood ratio tests of ordinal regression models
##
## Response: Sat
## Model Resid. df Resid. Dev Test Df LR stat. Pr(Chi)
## 1 Infl + Cont 1676 3535.059
## 2 Infl + Type + Cont 1673 3479.149 1 vs 2 3 55.91008 4.39071e-12住房类型Type显著。
house.plr4 <- update(house.plr, . ~ . - Cont)
anova(house.plr4, house.plr)## Likelihood ratio tests of ordinal regression models
##
## Response: Sat
## Model Resid. df Resid. Dev Test Df LR stat. Pr(Chi)
## 1 Infl + Type 1674 3493.456
## 2 Infl + Type + Cont 1673 3479.149 1 vs 2 1 14.30621 0.0001553518住户之间交往情况Cont显著。
还可以考虑加入交互作用效应的模型。
References
Roback, Paul, and Julie Legler. 2021. Beyond Multiple Linear Regression – Applied Generalized Linear Models and Multilevel Models in r. Chapman; Hall/CRC. https://bookdown.org/roback/bookdown-BeyondMLR/.
韭菜热线原创版权所有,发布者:风生水起,转载请注明出处:https://www.9crx.com/79796.html




