

语言模型的演变无异于一场超速工业革命。谷歌在 2017 年通过开发转换器模型点燃了火花,它使语言模型能够专注于或关注一段文本中的关键元素。下一个突破——语言模型预训练或自我监督学习——出现在 2020 年,之后 LLM 可以显着扩展以驱动 Generative Pretrained Transformer 3 (GPT-3)。
虽然像 ChatGPT 这样的大型语言模型 (LLM) 远非完美,但它们的发展只会在未来几个月和几年内加速。ChatGPT 插件商店的快速扩张暗示了加速的速度。为了预测它们将如何塑造投资行业,我们需要了解它们的起源和迄今为止的路径。
那么 LLM 早期发展的六个关键阶段是什么?
GPT-4 的业务:我们如何走到这里 ChatGPT 和 GPT-4 只是 OpenAI、谷歌、Meta 和其他组织开发的众多 LLM 中的两个。它们既不是最大的也不是最好的。例如,我们更喜欢将LaMDA用于 LLM 对话,将 Google 的Pathways Language Model 2 (PaLM 2)用于推理,将Bloom作为开源、多语言的 LLM。(LLM 排行榜是流动的,但 GitHub上的这个站点 对模型、论文和排名进行了有用的概述。)
那么,为什么 ChatGPT 成为 LLM 的代言人?部分原因是它首先推出时大张旗鼓。谷歌和 Meta 都对启动他们的 LLM 犹豫不决,担心如果他们制作冒犯性或危险的内容可能会损害声誉。谷歌还担心其 LLM 可能会蚕食其搜索业务。但是,一旦 ChatGPT 推出,据报道谷歌的首席执行官桑达尔皮查伊就宣布了“红色代码”,并且谷歌很快推出了自己的法学硕士。
GPT:大人物还是聪明人?
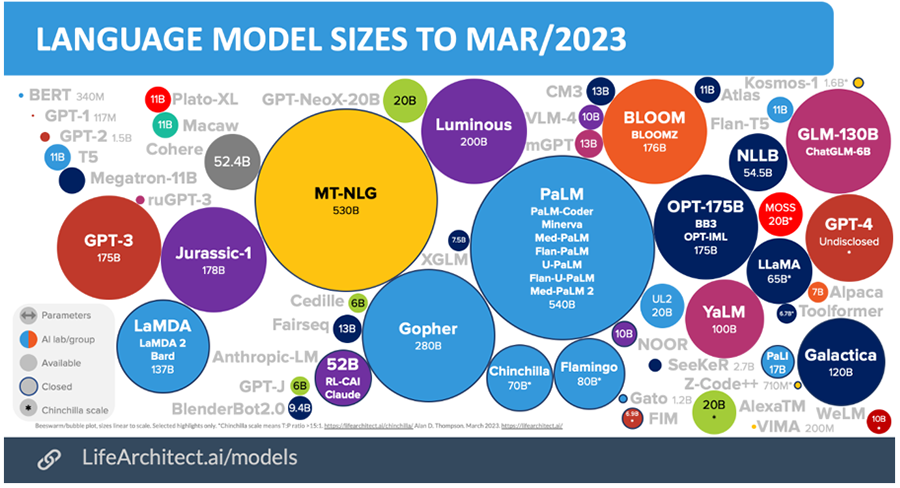
ChatGPT 和 ChatGPT Plus 聊天机器人分别位于 GPT-3 和 GPT-4 神经网络之上。在模型大小方面,Google 的 PaLM 2、NVIDIA 的Megatron-Turing 自然语言生成 (MT-NLG)以及现在的 GPT-4 已经让 GPT-3 及其变体 GPT-3.5 黯然失色,后者是 ChatGPT 的基础。与其前身相比,GPT-4 生成的文本更流畅,语言质量更好,解释更准确,并且与 GPT-3.5 相比有细微但显着的进步,可以处理更大的输入提示。这些改进是训练和优化进步的结果——额外的“智能”——可能是更多参数的纯粹蛮力,但 OpenAI 不共享有关 GPT-4 的技术细节。

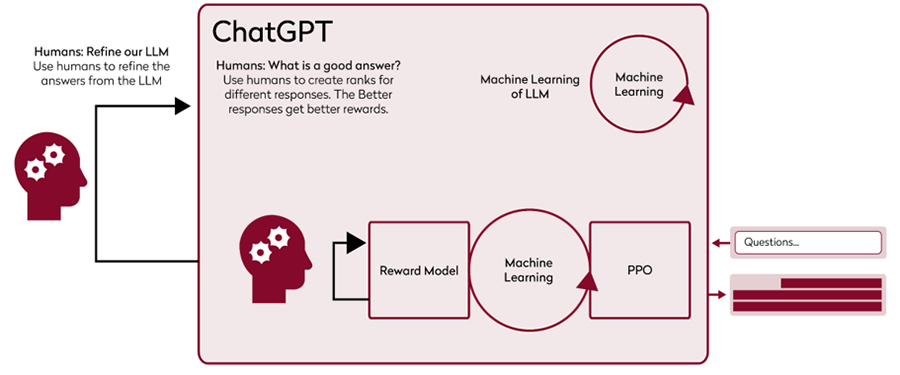
ChatGPT 培训:半机器,半人
ChatGPT 是一个 LLM,它通过强化学习进行微调,特别是 从人类反馈中强化学习 (RLHF)。这个过程原则上很简单:首先,人类通过大规模分类 LLM 生成的文本的准确性来改进聊天机器人所基于的 LLM。然后,这些人工评分会训练一个自动对答案质量进行排名的奖励模型。当聊天机器人收到相同的问题时,奖励模型会对聊天机器人的答案进行评分。这些分数会返回微调聊天机器人,以通过近端策略优化(PPO) 算法产生越来越好的答案。
ChatGPT 和 LLM 背后的机器学习
LLM 是自然语言处理 (NLP) 领域的最新创新。NLP 的核心概念是将概率分配给单词或文本序列的语言模型——S = ( w 1 , w 2 , … , w m )——就像我们的手机在我们“猜测”我们的下一个词时一样根据模型的最高概率输入短信。
LLM 发展的步骤
LLM 发展的六个进化步骤,如下图所示,展示了 LLM 如何适应 NLP 研究。

1、Unigram 模型
unigram 为给定文本中的每个单词分配一个概率。为了识别描述与感兴趣的公司有关的欺诈的新闻文章,我们可能会搜索“欺诈”、“骗局”、“假冒”和“欺骗”。如果这些词在文章中出现的次数多于常规语言,则该文章很可能在讨论欺诈。更具体地说,我们可以指定一段文本的概率。更具体地说,我们可以通过乘以单个单词的概率来指定一段文本是关于欺诈的概率:
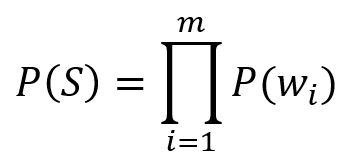
在这个等式中,P(S)表示句子S的概率,P(w i )反映了单词w i在关于欺诈的文本中出现的概率,乘积接过了序列中的所有m个单词,决定了这些句子与欺诈相关的概率。
这些单词概率基于单词在我们的欺诈相关文档语料库中出现的相对频率,表示为 D,在被检查的文本中。我们将其表示为 P(w) = count(w) / count(D),其中 count(w) 是词 w 在 D 中出现的频率,count(D) 是 D 的总词数。
具有更频繁单词的文本更可能或更典型。虽然这在搜索“identify theft”这样的短语时可能效果很好,但它对“theft identify”的搜索效果不佳,尽管两者具有相同的概率。因此,unigram 模型有一个关键的限制:它忽略了词序。
2、N-Gram 模型
“你应该知道它所拥有的公司的一个词!” —约翰·鲁珀特·弗斯
n-gram 模型通过检查几个单词的子序列比 unigram 更进一步。因此,为了识别与欺诈相关的文章,我们将使用“金融欺诈”、“洗钱”和“非法交易”等二元语法。对于八卦,我们可能包括“欺诈性投资计划”和“保险索赔欺诈”。我们的 fourgram 可能会写成“财务不当行为的指控”。
通过这种方式,我们将一个词的概率置于其前面的上下文中,n-gram 通过计算训练模型的语料库中的词序列来估计它。
这个公式是:
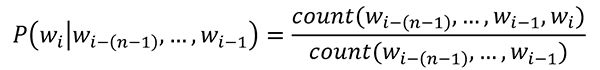
该模型更真实,例如,“识别盗窃”而不是“盗窃识别”的概率更高。然而,计数方法有一些缺陷。如果一个词序列没有出现在语料库中,那么它的概率将为零,从而使整个产品为零。
随着 n-gram 中“n”值的增加,模型在文本搜索中变得更加精确。这增强了它识别相关主题的能力,但可能会导致搜索范围过于狭窄。
下图显示了一个简单的 n-gram 文本分析。在实践中,我们可能会删除不提供任何有意义信息的“停用词”,例如“and”、“in”、“the”等,尽管 LLM 会保留它们。

3、神经语言模型 (NLM)
在 NLM 中,机器学习和神经网络解决了 unigram 和 n-gram 的一些缺点。我们可以直接以上下文 ( w i–(n–1) , … , w i–1 ) 作为输入,将w i作为目标来训练神经网络模型N。有许多改进语言模型的巧妙技巧,但从根本上讲,LLM 所做的只是查看一系列单词并猜测下一个单词。因此,模型通过根据预测的概率对下一个单词进行采样来表征单词并生成文本。随着深度学习在过去 10 年中的发展,这种方法已经开始主导 NLP。
4、突破:自监督学习
多亏了互联网,越来越大的文本数据集变得可用于训练日益复杂的神经模型架构。然后发生了两件值得注意的事情:
首先,神经网络中的单词由向量表示。随着训练数据集的增长,这些向量会根据单词的句法和语义自行排列。
其次,语言模型的简单 自监督 训练结果出乎意料地强大。人类不再需要手动标记每个句子或文档。相反,该模型学会了预测序列中的下一个单词,并且在此过程中还获得了其他能力。研究人员意识到,预训练语言模型为文本分类、情感分析、问答和其他 NLP 任务提供了良好的基础,并且随着模型规模和训练数据的增长,该过程变得更加有效。
这为序列到序列模型铺平了道路。这些包括将输入转换为向量表示的编码器和从该向量生成输出的解码器。这些神经序列到序列模型优于以前的方法,并于 2016 年被纳入谷歌翻译。
5、最先进的 NLP:变形金刚
直到 2017 年,循环网络是最常见的语言建模神经网络架构,尤其是长短期记忆 (LSTM)。LSTM 上下文的大小在理论上是无限的。这些模型也是双向的,因此所有未来的词和过去的词都被考虑在内。然而,在实践中,好处是有限的,循环结构使训练成本更高且更耗时:很难在 GPU 上并行化训练。主要出于这个原因,Transformer 取代了 LSTM。
Transformers 建立在注意力机制之上:该模型根据上下文学习赋予单词多少权重。在循环模型中,最近的词对预测下一个词有最直接的影响。有了注意力,当前上下文中的所有单词都可用,并且模型会学习要关注哪些单词。
在他们题为“Attention is All You Need”的论文中,谷歌研究人员介绍了 Transformer 序列到序列架构,它没有循环连接,只是在生成文本时使用自己的输出作为上下文。这使得训练很容易并行化,因此模型和训练数据可以扩展到以前闻所未闻的规模。对于分类,Transformers 的双向编码器表示 (BERT)成为新的首选模型。对于文本生成,竞赛现在已经开始扩大规模。
6、多模式学习
虽然标准 LLM 专门针对文本数据进行训练,但其他模型(例如 GPT-4)包括图像或音频和视频。在金融环境中,这些模型可以检查图表、图像和视频,从 CEO 采访到卫星照片,以寻找潜在的可投资信息,所有这些都与新闻流和其他数据源进行交叉引用。
对法学硕士的批评
Transformer LLM 可以预测单词并在 NLP 任务的大多数基准测试中表现出色,包括回答问题和总结。但它们仍然有明显的局限性。他们靠记忆而不是推理,并且没有超出单词概率的世界因果模型。诺姆·乔姆斯基 (Noam Chomsky)将它们描述为“高科技剽窃”,艾米丽·本德 (Emily Bender) 等人。作为“随机鹦鹉”。扩大模型或在更多文本上训练它们不会解决它们的缺陷。Christopher D. Manning、 Jacob Browning 和 Yann LeCun 以及其他研究人员认为,重点应该放在将模型的技术扩展到多模态,包括更结构化的知识。
法学硕士还有其他科学和哲学问题。例如,神经网络在多大程度上可以仅从语言中真正了解世界的本质?答案可能会影响模型的可靠性。法学硕士的经济和环境成本也可能很高。扩大规模使得它们的开发和运行成本很高,这引发了对其生态和经济可持续性的质疑。
使用 LLM 的通用人工智能 (AGI)?
无论目前的局限性如何,法学硕士都将继续发展。最终他们将解决比简单的即时响应复杂得多的任务。仅举一个例子,法学硕士可以成为其他系统的“控制者”,原则上可以指导投资研究的要素和目前仅由人类参与的其他活动。有些人将其描述为“Baby AGI”,对我们来说,这无疑是这项技术最令人兴奋的领域。
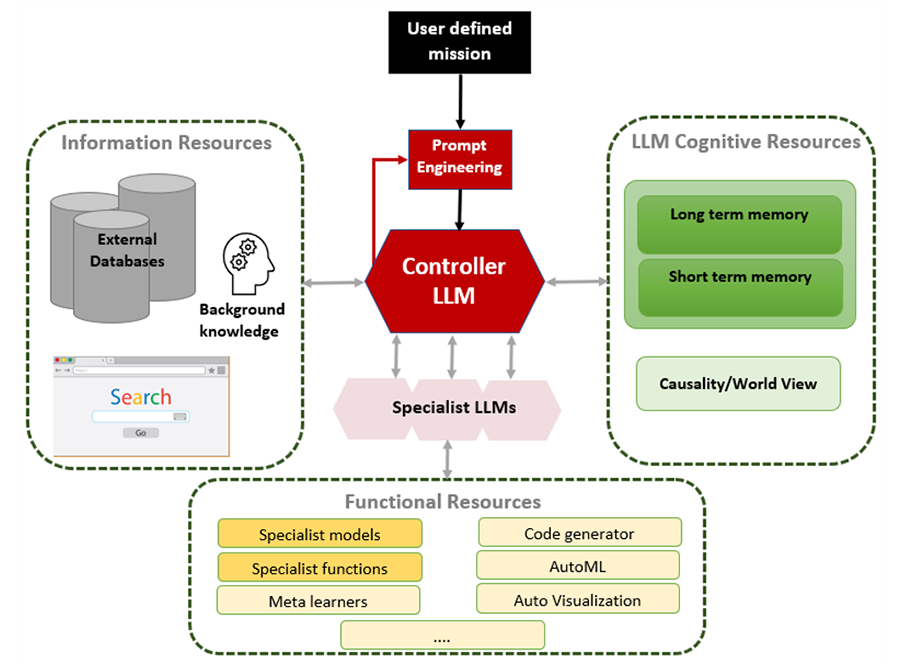
人工智能进化的下一步
ChatGPT 和 LLM 更普遍地说是强大的系统。但他们只是触及表面。法学硕士革命的下一步将既令人兴奋又令人恐惧:对于有技术头脑的人来说是令人兴奋的,而对于勒德分子来说则是可怕的。
LLM 将提供更多最新信息、更高的准确性以及破译因果关系的能力。他们将更好地复制人类的推理和决策。
对于高科技经理来说,这将是削减成本和提高绩效的绝佳机会。但整个投资行业是否已准备好迎接这种颠覆性变化?可能不会。
Luddite 或技术专家,如果我们看不到如何应用 LLM 和 ChatGPT 来更好地完成我们的工作,那么可以肯定的是,其他人会。欢迎来到投资的新技术军备竞赛!
By Dan Philps, PhD, CFA and Tillman Weyde, PhD Posted In: Drivers of Value, Economics, Future States
韭菜热线原创版权所有,发布者:弗里曼,转载请注明出处:https://www.9crx.com/71842.html




