

Julia的语言特点
Julia语言是一种历史很短的计算机语言,
公开发布于2012年。
其设计理念就是希望兼有Python、R、Matlab这样的动态语言的易用性,
以及C、C++、Java这样的静态语言的运行速度。
所以Julia很适合用来做统计和金融计算。
Julia语言的特点有:
- 动态语言;
- 使用基于LLVM的动态编译技术,可以动态生成高效的运行代码;
- 不需要声明类型也一般能够产生高效代码,
需要时声明类型可以提高效率。
程序性能评测
程序计时
用@time宏对一个表达式计时和查看内存分配情况,如:
@time sum(sqrt.(rand(10_000_000)));
## 0.054598 seconds (4 allocations: 152.588 MiB, 15.73% gc time)结果中有程序运行时间的秒数,
进行了多少次内存分配(4次),
总计分配的内存数(约152MB, 中间可能也有释放的内存),
整理内存所用的时间(gc time)。
@time宏执行一个表达式,
显示运行时间、分配内存、垃圾收集时间比例,
然后返回表达式的结果。
@time也可以对一个结构计时,如
s = 0.0
@time for i=1:10_000_000
s += sqrt(rand())
end
## 0.225858 seconds (20.00 M allocations: 305.176 MiB, 1.70% gc time)这个程序慢了很多,分配内存的次数和总量也比较多。
对于多个语句,
可以用begin ... end包裹起来评测,如:
@time begin
A = rand(1000, 1000) .+ 1;
for i=1:100
B = rand(1000, 1000) .+ 1;
A = A * B
end
end;
## 6.227282 seconds (2.26 M allocations: 2.359 GiB,
## 9.77% gc time, 10.61% compilation time)还有一个@timev宏与@time类似,
提供的信息更多。@time和@timev仅是显示表达式执行的时间和内存分配信息,
不影响表达式返回结果,
所以在程序中使用这两个函数计时一般不影响程序的结果。
这样单次运行会受到操作系统中同时运行的其它任务的干扰。
BenchmarkTools包提供了一个@btime代替@time,@btime多次运行相同的程序并取其中时间最短的一个来比较。
程序瓶颈查找(profiler)
为了提高程序效率,
并不是所有的程序代码都需要仔细地考察并改进效率。
大部分的程序可能仅仅执行一两次,
可能仅需要执行几秒钟到几分钟。
这样的程序不需要想办法提高执行效率,
只要程序结果正确就可以了。
有些程序需要执行许多次,
可能会提供给许多用户使用,
这样的程序即使耗时并不多,
也有必要去设法改进其运行效率。
有些程序虽然不需要执行许多次,
但是运行所需的时间可能很长,
比如几小时到几天,
这样的程序需要设法改进效率。
对一段比较长的程序,
如果需要改进效率,
并不需要考虑所有的代码行,
而是只要改进程序执行消耗时间最多的部分就可以了,
这样的部分称为程序的瓶颈。
Julia内置了一个profiler工具,
用定时抽查的方式查看那些代码行被执行得最多。
这样的工具在使用时不需要修改源程序,
对运行速度的影响也很小。
因为Julia使用了即时编译,
所以一个函数在第一次被调用时需要有额外的编译时间,
第二次调用就没有这个问题了。
在用profiler分析一个函数是应该从第二次调用开始分析。
在执行程序之前,调用:
using Profile
Profile.clear()然后执行要分析的程序。
执行完后调用:
将显示程序的执行次数,
包括调用的库函数的执行次数,
执行次数多的程序语句是需要优化的。
ProfileView包可以提供一个交互的图形显示,
直观地显示哪些语句耗时多。
作者个人认为这些工具现在显示的信息还过于繁琐,
不利于一般用户使用。
BenchmarkTools
为了对运行时间较短的程序计时,
通常会人为地重复该程序。
BenchmarkTools提供了更完善的计时统计,
以及系统的性能比较(benchmark)能力。
例如,如下的简短程序:
A = rand(2); B = rand(2); C = zeros(2);
C = A + B;对第二行计时如下:
using BenchmarkTools
@benchmark C = A + B结果中显示了多次重复运行此语句的运行时间的各种统计量和内存使用情况。@btime则仅显示一个重复运行最快时间和内存使用情况:
using BenchmarkTools
@btime C = A + B;
## 32.897 ns (1 allocation: 80 bytes)换用加点写法:
@btime C .= A .+ B;
## 269.497 ns (2 allocations: 64 bytes)这个版本性能更差。
换用显式循环:
@btime for i=1:2
C[i] = A[i] + B[i]
end;
## 115.426 ns (6 allocations: 96 bytes)不如向量化版本,
但优于加点版本。
以上的程序是在全局名字空间(命令行对应的名字空间)中执行的。
如果调用函数,
结果则完全不同:
A = rand(2); B = rand(2); C = zeros(2);
function vecadd1(a,b,c)
c = a + b
return nothing
end
function vecadd2(a,b,c)
c .= a .+ b
return nothing
end
function vecadd3(a,b,c)
for i=1:length(c)
c[i] = a[i] + b[i]
end
return nothing
end
vecadd1(A, B, C);
vecadd2(A, B, C);
vecadd3(A, B, C);
@btime vecadd1(A, B, C)
@btime vecadd2(A, B, C)
@btime vecadd3(A, B, C)
## 35.211 ns (1 allocation: 80 bytes)
## 17.435 ns (0 allocations: 0 bytes)
## 13.928 ns (0 allocations: 0 bytes)向量化版本速度变化不大,
加点和显式循环变成函数后的版本性能比命令行运行时的性能都大大提升,
从原来不如向量化版本变成了比向量化版本快一倍。
这可能与即时编译系统对函数的优化有关。
数据类型与运行效率
类型声明
Julia允许对函数自变量、函数返回值、函数的局部变量声明数据类型,
但是一般不需要声明也能产生运行效率很好的执行代码。
声明方式是在变量名后面用双冒号::后面跟类型名,如
function f_tp01(x::Float64) :: Float64
local y::Float64
y = (1 + x)^2
y = sin(y)
return y
end
f_tp01(1.5)
## -0.03317921654755682说明类型有可能会提高程序效率,
但是也限制了函数调用方法,
尤其是整型与实型会看成两种不同类型,所以:
结果:
MethodError: no method matching f_tp01(::Int64)
Closest candidates are:
f_tp01(!Matched::Float64) at In[12]:2
Stacktrace:
[1] top-level scope at In[13]:1上面的调用错误是因为f_tp01()函数只允许浮点型自变量,
而1不是浮点型,
Julia在调用函数时不会自动将整型转换成浮点型。
因为Julia的四则运算的设计是允许将整型与浮点型混合运算的,
所以四则运算不存在这样的问题。
函数定义时如果不声明自变量类型,
则不存在这个问题,如:
function f_tp01b(x)
y = (1 + x)^2
y = sin(y)
return y
end
f_tp01b(1.5)
## -0.03317921654755682
f_tp01b(1)
## -0.7568024953079282所以自定义函数中如非必要并不是所有自变量、返回值、局部变量都声明类型就更好。
为了使得f01()能够对其它数也适用,
可以写一个更一般的类型作为自变量然后转换成浮点型,如:
function f_tp01(x::Number) :: Float64
local y::Float64
y = (1 + float(x))^2
y = sin(y)
return y
end
f_tp01(1)
## -0.7568024953079282多重派发
Julia的同一个函数可以根据自变量个数和自变量类型的不同而执行不同的操作,
称为“多重派发”(multiple dispatch)。
这有些像是面向对象语言的方法重载(overloading),
但是:
- 方法重载是编译时根据对象的类决定的;
- 方法重载仅能根据其依附的对象而选择对应的方法,即所谓单重派发;
- Julia是动态语言,其函数调用是运行时动态决定的;
- Julia可以根据其多个自变量的类型而选取不同方法。
多重派发可以让多个类似的操作共享同一个函数名。
比如,
可以这样设计绘图函数plot(),
可以仅输入一个数值型向量y,
作序列图;
可以输入两个数值型向量x和y,作散点图;
可以输入一个字符串向量x和数值型向量y,
作条形图。
不同的自变量个数和类型决定了要执行的操作,
这些操作称为plot()函数的“方法”。
类型稳定性
Julia不要求声明函数自变量、返回值和局部变量类型,
但是如果函数返回值不能被其输入数据类型确定,
这样的函数很难得到高效的执行代码。
这种要求称为程序的“类型稳定性”。
例如,下面的程序:
function f_tp02(x)
if x >= 0
return sqrt(x)
else
return "Negative number have no square root!"
end
end
## f_tp02 (generic function with 1 method)这个函数从表面上看很正常,
但是违反了类型稳定性。
因为不论输入x为什么数,
返回值的类型都依赖于x的数值而不能由x的数据类型决定,
这就使得依赖于返回值的代码无法确定返回值类型从而无法优化。
用宏@code_warntype可以检查一个函数调用中的类型稳定性问题,如
@code_warntype f_tp02(1.5)结果中的类型不稳定问题会用红色显示。
另外,如果一个函数反复被调用或者内部有很多次循环,
某些局部变量在多次调用或者多次循环中不能预先确定类型或者类型被改变,
也会造成程序性能急剧下降。
如:
function f_tp03(x)
s = 0
for xi in x
s += sqrt(xi)
end
return s
end
## f_tp03 (generic function with 1 method)变量s开始是整型,但在循环中变成了浮点型。初始化可写成s = 0.0。
函数的效率
由于Julia的多重派发、动态编译特性,
Julia程序最好分解成短小、输入类型明确的多个函数。
函数调用的成本很低,
动态编译可以将函数编译成针对特定输入的高效代码。
全局变量的问题
为了运行效率考虑,
应尽量避免使用全局变量。
全局变量的取值乃至于类型都可能被不同位置的代码改变,
使得编译器很难预估全局变量的类型,
造成编译代码低效。
尽可能使用局部变量与函数自变量保存和传递数据。
Julia的函数是按引用进行参数传递的,
所以数组的传递不会制作副本,
没有内存和时间的额外开销。
Julia的编译器优化主要是针对函数,
所以对效率敏感的代码都应该写成函数而不是直接在全局变量空间执行。
用const声明的全局变量不能改变类型,
这样的全局变量对程序效率的影响较小。
考虑下面的利用了全局变量作为选项的程序:
POWER=2
function f_gl01(x::Vector{Float64})
s = 0.0
for xi in x
s += xi ^ POWER
end
return s
end
f_gl01(rand(10))
using BenchmarkTools
@btime f_gl01(rand(100_000))
## 3.307 ms (300002 allocations: 5.34 MiB)将上面的POWER声明为常数可以提高效率。
Julia用const关键字声明全局变量常数,
但是这种全局变量仅仅是不允许改变数据类型,
变量值还是允许改变的,
改变变量值会有警告信息。
修改后的程序如:
const P_const=2
function f_gl01b(x::Vector{Float64})
s = 0.0
for xi in x
s += xi ^ P_const
end
return s
end
f_gl01b(rand(10))
using BenchmarkTools
@btime f_gl01b(rand(100_000))
## 134.800 μs (2 allocations: 781.30 KiB)比原来效率提高了一个数量级。
在调用全局变量的位置标识其类型也可以提高效率,如
POWER=2
function f_gl01c(x::Vector{Float64})
s = 0.0
for xi in x
s += xi ^ POWER::Int
end
return s
end
f_gl01c(rand(10))
using BenchmarkTools
@btime f_gl01c(rand(100_000))
## 149.200 μs (2 allocations: 781.30 KiB)当然,这个问题实际上完全不需要使用全局变量,
只要作为函数自变量即可:
function f_gl01d(x::Vector{Float64}, p)
s = 0.0
for xi in x
s += xi ^ p
end
return s
end
f_gl01d(rand(10), 2)
using BenchmarkTools
@btime f_gl01d(rand(100_000), 2)
## 143.800 μs (2 allocations: 781.30 KiB)用@code_warntype分析f_gl01()的问题:
@code_warntype f_gl01(rand(10))输出中的红色Any都提示有类型不确定问题。修改然后再用@code_warntype分析:
POWER=2
function f_gl01e(x::Vector{Float64})::Float64
s::Float64 = 0.0
for xi in x
s += xi ^ POWER::Int
end
return s
end
f_gl01e(rand(10))
using BenchmarkTools
@btime f_gl01e(rand(100_000))
## 154.200 μs (2 allocations: 781.30 KiB)@code_warntype f_gl01e(rand(10))结果中没有需要改进的代码了。
行内函数(inline functions)
Julia编译器自动将较小的类型明确的函数调用变成行内函数,
即被调用的函数的实际代码被转移到调用者内部。
行内函数提高了程序效率但是会使得程序变大。
Julia自动确定哪些函数变成行内函数,
然而,
有些反复调用的代码,
尤其是用在循环和内存循环的代码,
比如数组用下标访问元素的函数,
最好人为地规定成行内函数。
用@inline宏说明一个函数定义就可以规定其变成行内函数。
如
@inline function f(x)
...
end用宏提高效率
宏(macro)是类似C语言预处理的语言构件。
宏可以生成程序代码,
可以对程序代码进行操作,
比如前面的@time、@code_warntype等。
宏可以用来对重复性的代码进行简写,
也可以通过将运行时才执行的任务提前到代码编译阶段完成从而提高效率。
以多项式求值的函数为例。
多项式的系数按升序保存在一维数组中。
按照通常的写法,程序为:
function f_ma01(x, a...)
p = zero(x)
for i = 1: length(a)
p += a[i] * x ^(i-1)
end
return p
end
## f_ma01 (generic function with 1 method)这里没有用秦九韶法进行算法优化,直接用了幂函数。
对多项式
,
可以用f_ma01()定义如下的多项式函数:
f_ma01b(x) = f_ma01(x, 1, 2, 3, 4)
## f_ma01b (generic function with 1 method)调用如
f_ma01b(1.0)
## 10.0
f_ma01b(1.5)
## 24.25
f_ma01b(1)
## 10测试程序效率如下:
@btime f_ma01b(1.5)
## 0.800 ns (0 allocations: 0 bytes)将程序改成用秦九韶法,
比如
写成
这样可以减少乘法运算的次数。
算法每一步将前一步的结果乘以x,
加上降序的后一个系数。
将f_ma01()用这种方法改写:
function f_ma02(x, a...)
p = zero(x)
for i = length(a):-1:1
p = a[i] + p*x
end
return p
end
## f_ma02 (generic function with 1 method)多项式
的函数为:
f_ma02b(x) = f_ma02(x, 1, 2, 3, 4)
f_ma02b(1.5)
@btime f_ma02b(1.5)
## 0.800 ns (0 allocations: 0 bytes)两个函数性能相同,
可能是Julia本身进行了优化。
这个算法还是不够优化,
因为每次调用f_ma02()时都需要访问系数数组,
而实际的多项式的系数是常数,
所以,
直接按
计算效率会更高,如:
f_ma03(x) = 1 + x*(2 + x*(3 + 4 * x))
f_ma03(1.5)
@btime f_ma03(1.5)
## 0.001 ns (0 allocations: 0 bytes)第三个版本效率提升了三个数量级。
问题是f_ma03()函数是完全根据多项式阶数与系数手写代码实现的,
我们需要就这个手写代码的过程用Julia程序完成,
这就是宏的作用。
一般的生成一个多项式函数的宏如下:
macro mac_01(x, a...)
ex = esc(a[end])
for i = length(a)-1:-1:1
ex = :(muladd(t, $ex, $(esc(a[i]))))
end
Expr(:block, :(t = $(esc(x))), ex)
end
## @mac_01 (macro with 1 method)生成多项式函数如:
f_ma04(x) = @mac_01(x, 1, 2, 3, 4)
## f_ma04 (generic function with 1 method)测试:
f_ma04(1.5)
@btime f_ma04(1.5)
## 0.001 ns (0 allocations: 0 bytes)程序效率与手写的优化代码相当。
派生函数(generated functions)是与宏类似的函数定义方式,
可以起到类似手写优化代码的效果,
可以将原来一般性的循环写成直接的表达式。
关键字参数问题
Julia的多重派发是仅根据位置参数,
包括没有缺省值的和有缺省值的位置参数的类型来进行的;
关键字参数不影响多重派发,
这样,
用到关键字参数的函数就无法得到类型信息的好处,
效率相对而言比较低。
关键字参数适用于有很多选项的用户直接调用的参数,
如果是反复循环的对性能要求高的函数则应避免使用关键字参数。
例如:
f_kw01(x; y=2, z=2) = x^y + x^z
f_kw01(1.5, y=2, z=3)
@benchmark f_kw01(1.5, y=2, z=3)BenchmarkTools.Trial:
memory estimate: 0 bytes
allocs estimate: 0
--------------
minimum time: 2.299 ns (0.00% GC)
median time: 2.399 ns (0.00% GC)
mean time: 2.368 ns (0.00% GC)
maximum time: 34.901 ns (0.00% GC)
--------------
samples: 10000
evals/sample: 1000f_kw01b(x, y=2, z=2) = x^y + x^z
f_kw01b(1.5, 2, 3)
@benchmark f_kw01b(1.5, 2, 3)BenchmarkTools.Trial:
memory estimate: 0 bytes
allocs estimate: 0
--------------
minimum time: 2.599 ns (0.00% GC)
median time: 2.699 ns (0.00% GC)
mean time: 2.706 ns (0.00% GC)
maximum time: 35.401 ns (0.00% GC)
--------------
samples: 10000
evals/sample: 1000两个版本性能相近,
可能是Julia做了优化。
基本计算
整数的表示与溢出
Julia的数值直接使用硬件的数值表示。
整数值的计算不进行溢出检查,
所以利用整数值计算时需要用户自己注意溢出问题,如:
2^62
## 4611686018427387904
2^63
## -9223372036854775808不进行溢出检查是为了程序效率必须付出的代价。
如果确实有可能发生溢出,
Int128可以保存更多位,
进一步可以改用浮点数Float64,
或者用无限位数的整数类型BigInt,
BigInt效率会很差。
如
BigInt(2)^63
## 9223372036854775808即使用BigInt()说明,
也仅是将输入转换成了无限精度整型,
转换之前的溢出是没有控制的,比如:
BigInt(2^63)
## -9223372036854775808要注意,
直接写的整数根据数字位数,
较短时为Int类型,
超过Int范围首先选用Int64和Int128,
超过Int128后自动认为是BigInt类型。
如:
typeof(123456789012345678)
## Int64typeof(12345678901234567890)
## Int128typeof(1234567890123456789012345678901234567890)
## BigInt用parse(BigInt, "...")从字符串输入长整数,如
parse(BigInt, "12345678901234567890")
## 12345678901234567890数组处理
科学计算,
包括统计建模、数据处理,
广泛使用数组、向量、矩阵运算,
计算中大量的时间都花费在对数组的处理上面。
需要构造高效的数组处理算法。
数组存储
数组通过指定元素类型为抽象类型可以保存不同类型的数组元素,
但是这样的数组就无法利用类型信息进行优化,
所以数组应尽可能保存同一种实在类型(concrete type)的元素。
数组类型为Array{T, N},
其中T为元素类型,
一般是实在类型,
N是维数。
比如Array{Float64, 2}表示浮点数矩阵。
这种数组可以高效地存储与处理。
实在类型的数组一般可以在连续的内存中存储,
使得其遍历或者随机访问都很便捷。
而其它的动态语言如Python一般需要使用指针指向每个数组元素,
除特定的定制数组类型以外。
连续存储的数组比用指针访问的数组效率要高得多。
Julia的多维数组当元素是基础类型时按照列优先原则保存,
比如矩阵的元素也在连续的内存中保存,
先保存第一列,再保存第二列,以此类推。
多维数组类似。Fortran、Matlab也遵循列优先原则,
而C语言在保存二维数组时遵循行优先原则。
在遍历多维数组时按照其存储次序遍历效率更高;
遍历一个矩阵时,
按照列次序遍历效率更高,如:
A = [1 2 3; 4 5 6]
for j=1:size(A,2)
for i=1:size(A,1)
println("(", i, ", ", j, ") -> ", A[i,j])
end
end(1, 1) -> 1
(2, 1) -> 4
(1, 2) -> 2
(2, 2) -> 5
(1, 3) -> 3
(2, 3) -> 6或
for j=1:size(A,2), i=1:size(A,1)
println("(", i, ", ", j, ") -> ", A[i,j])
end(1, 1) -> 1
(2, 1) -> 4
(1, 2) -> 2
(2, 2) -> 5
(1, 3) -> 3
(2, 3) -> 6或
for i in eachindex(A)
println(A[i])
end1
4
2
5
3
6下面的例子演示了按列次序与按行次序遍历矩阵的效率差别。
按列遍历的例子:
function f_ar01(A)
s = zero(eltype(A))
for j=1:size(A,2), i=1:size(A,1)
s += A[i,j]^2
A[i,j] = s
end
return s
end
f_ar01(rand(2,2))
A = rand(1_000,1_000)
@benchmark f_ar01(A)BenchmarkTools.Trial:
memory estimate: 16 bytes
allocs estimate: 1
--------------
minimum time: 1.556 ms (0.00% GC)
median time: 1.630 ms (0.00% GC)
mean time: 1.652 ms (0.00% GC)
maximum time: 9.588 ms (0.00% GC)
--------------
samples: 3017
evals/sample: 1按行遍历的例子:
function f_ar01b(A)
s = zero(eltype(A))
for i=1:size(A,1), j=1:size(A,2)
s += A[i,j]^2
A[i,j] = s
end
return s
end
f_ar01b(rand(2,2))
@benchmark f_ar01b(A)BenchmarkTools.Trial:
memory estimate: 16 bytes
allocs estimate: 1
--------------
minimum time: 2.162 ms (0.00% GC)
median time: 2.351 ms (0.00% GC)
mean time: 2.414 ms (0.00% GC)
maximum time: 8.803 ms (0.00% GC)
--------------
samples: 2063
evals/sample: 1在上面的例子中,按列遍历比按行遍历有明显的性能提升。
减少动态内存分配
对于在循环内反复执行的代码,
应避免重复地分配内存,
而是预先分配内存。
对于以数组为输入和输出的自定义函数,
可以将函数的输出也作为函数自变量。
如:
function f_ar02(x, y, n)
local z
for i in 1:n
z = x + y
end
return z
end
f_ar02(rand(10), rand(10), 100)
@benchmark f_ar02(rand(10), rand(10), 10_000)BenchmarkTools.Trial:
memory estimate: 1.53 MiB
allocs estimate: 10002
--------------
minimum time: 558.399 μs (0.00% GC)
median time: 588.701 μs (0.00% GC)
mean time: 629.451 μs (2.93% GC)
maximum time: 2.763 ms (0.00% GC)
--------------
samples: 7914
evals/sample: 1进行了许多次内存分配。预先分配z的内存:
function f_ar02b(x, y, n)
z = similar(x)
for i in 1:n
z .= x .+ y
end
return z
end
f_ar02b(rand(10), rand(10), 100)
@benchmark f_ar02b(rand(10), rand(10), 10_000)BenchmarkTools.Trial:
memory estimate: 480 bytes
allocs estimate: 3
--------------
minimum time: 104.299 μs (0.00% GC)
median time: 108.800 μs (0.00% GC)
mean time: 110.891 μs (0.00% GC)
maximum time: 253.101 μs (0.00% GC)
--------------
samples: 10000
evals/sample: 1后一个版本基本没有动态分配内存,
效率提升几倍。
用数组视图代替数组切片
设A为矩阵,A[:,j]表示A的第j列组成的一维数组(向量),
这种子集访问称为数组切片(slice)。
对向量x的x[1:end-1]这样的子集也会制作副本(切片)。
切片的问题是,A[:,j]会制作第j列的一个副本,
如果这个副本被反复多次访问,
而且未复制之前的内容在内存中没有连续存储,
复制的做法可以利用复制后连续存储快速访问的优点使得程序效率较高。
但是,
如果副本仅一次性使用,
或者数据子集本来已经是连续存储的,
复制操作会造成严重的性能损失。
例如,如下的程序对矩阵求列和:
function f_ar03(A)
nc = size(A,2)
map(j -> sum(A[:,j]), 1:nc)
end
f_ar03(rand(10,10))
@benchmark f_ar03(rand(1000,1000))BenchmarkTools.Trial:
memory estimate: 15.39 MiB
allocs estimate: 1005
--------------
minimum time: 5.749 ms (0.00% GC)
median time: 7.468 ms (0.00% GC)
mean time: 8.088 ms (15.78% GC)
maximum time: 18.919 ms (34.97% GC)
--------------
samples: 618
evals/sample: 1上面的程序中用了许多次内存分配。
在访问矩阵的一列时最好不制作副本而直接访问矩阵存储的该列。
在用到矩阵切片的代码前面冠以@views宏就可以达到此目的。如
function f_ar03b(A)
nc = size(A,2)
@views map(j -> sum(A[:,j]), 1:nc)
end
f_ar03b(rand(10,10))
@benchmark f_ar03b(rand(1000,1000))BenchmarkTools.Trial:
memory estimate: 7.68 MiB
allocs estimate: 1005
--------------
minimum time: 4.634 ms (0.00% GC)
median time: 5.073 ms (0.00% GC)
mean time: 6.123 ms (14.53% GC)
maximum time: 14.896 ms (49.12% GC)
--------------
samples: 816
evals/sample: 1第二个版本的运行效率明显提升,
内存分配减半。
SIMD并行优化
在执行类似z[i] = x[i] + y[i]这样的向量对应元素运算时,
现代CPU提供了并行执行的SIMD指令,
Julia可以自动分析代码对某些代码执行SIMD优化。
可以用@simd宏要求进行SIMD优化。
这样优化的循环必须是循环各步独立的,
循环体没有分支操作,循环次数固定,
下标是连续变化的。
如:
function f_ar04!(z, x, y)
n = length(x)
for i=1:n
z[i] = x[i] + y[i]
end
return nothing
end
z = zeros(10)
f_ar04!(z, rand(10), rand(10))
z = zeros(1_000_000)
@benchmark f_ar04!(z, rand(1_000_000), rand(1_000_000))BenchmarkTools.Trial:
memory estimate: 15.26 MiB
allocs estimate: 4
--------------
minimum time: 9.780 ms (0.00% GC)
median time: 10.554 ms (0.00% GC)
mean time: 12.369 ms (13.84% GC)
maximum time: 22.918 ms (36.66% GC)
--------------
samples: 404
evals/sample: 1SIMD优化版本:
function f_ar04b!(z, x, y)
n = length(x)
@inbounds @simd for i=1:n
z[i] = x[i] + y[i]
end
return nothing
end
z = zeros(10)
f_ar04b!(z, rand(10), rand(10))
z = zeros(1_000_000)
@benchmark f_ar04b!(z, rand(1_000_000), rand(1_000_000))BenchmarkTools.Trial:
memory estimate: 15.26 MiB
allocs estimate: 4
--------------
minimum time: 9.567 ms (0.00% GC)
median time: 10.158 ms (0.00% GC)
mean time: 12.029 ms (13.94% GC)
maximum time: 25.226 ms (34.29% GC)
--------------
samples: 416
evals/sample: 1性能没有变化,可能是编译器本身已经包含了足够的优化。
并行计算
Julia语言是最近几年才发明的语言,
它吸收了现代最新的计算机科学技术成果,
比如,
语言中直接提供了对并行计算的支持。
因为并行计算与硬件密切相关,
所以这些功能在不同运行环境中有些能发挥作用而有些受限。
统计计算中有大量重复计算可以利用并行计算加速,
尤其是随机模拟问题,比较适合用并行计算。
有一些问题可以不依赖于语言支持而并行执行,
比如,
一个模型的随机模拟研究,
往往需要对模型设置许多组真实参数,
然后对每一组真实参数产生许多批次的样本进行模型估计。
这样,
可以运行多个非交互的Julia程序,
每个程序中使用不同的参数模拟,
最后汇总结果。
这样做的好处是不需要了解并行计算,
缺点是需要人为地开始多组程序,
当某些组任务完成时再人为地开始新的任务。
当每个任务耗时都很长,
比如若干个小时的时候,
这样的方法还是可行的。
最简单的并行运算是单一计算机的多个CPU核心(kernels或threads)同时独立地对一个数组的不同部分计算,
进一步还可以将若干台计算机组成集群(cluster)并行运行。
在统计中随机模拟经常需要对多个独立样本并行地执行一些计算,
这种情况下利用Julia的并行能力是有意义的,
即使单个计算机的4个核心同时运行能够将模拟速度提高一倍也是有意义的。
Julia的Distributed包是标准库的一部分,
提供了这样的功能,
实际上是在不同核心、不同CPU、不同计算机上执行单独的进程,
称这样的每个进程为一个工作进程或者节点。
在Linux或者MAC OS X中的ParallelAccelerator包可以将需要并行执行的代码编译为并行运行的本地二进制代码,
从而获得一两个数量级的加速。
Julia提供了coroutine功能,
也是一种并行机制,
离散系统模拟SimJulia就是利用这种机制。
Julia的Base.Threads包试验性地提供了多线程功能,
功能尚未成熟。
并行for循环和独立随机模拟
随机模拟程序中,
最简单的是独立样本的平均值法或者重要抽样法。
设随机变量
有分布密度
,
为了计算积分
,
注意到
,
可以产生
的独立同分布样本
,
并估计
为
作为示例,
计算积分
,
精确值为
。
取
。
不用并行计算,程序为:
function f_para01(n)
s::Float64 = 0.0
for i = 1:n
s += exp(rand())
end
s /= n
return s
end
@time f_para01(1_000)
@time f_para01(1_000_000_000)结果为
1.718281085841862
21.387429 seconds (7 allocations: 528 bytes)Julia在标准库的Distributed包提供了@distributed for宏,
可以将循环自动划分范围分配到多个核心或者处理器。
同时,
还可以提供一个汇总操作,
将各个并行部分的结果汇总在一起。
修改为并行版本:
using Distributed
function f_para01b(n)
res = @distributed (+) for i = 1:n
exp(rand())
end
res /= n
return res
end
@time f_para01b(1_000)
@time f_para01b(1_000_000_000)结果为
1.7182629178900357
7.630154 seconds (829 allocations: 36.438 KiB)这是用了8个核心的结果,速度提高了大约3倍。
这个结果是在REPL命令行测试,
启动REPL命令行程序时加了选项-p 8表示有8个核心并行运行,
在Windows下可以修改程序的快捷方式在“目标”区域的程序后面加此选项,
如
D:\JuliaPro-1.4.0-1\Julia-1.4.0\bin\julia.exe -p 8另一种办法是运行单核心的julia.exe命令行程序,
然后用如下命令增加可用的核心个数:
using Distributed
addprocs(7)注意上述f_para01b()函数中没有利用统一的累加变量s,
这是因为不同的并行进程中无法同时修改同一个公用的变量。
另外,并行的for循环不能保证各步循环的先后次序。@distributed for的办法是让每步循环都返回一个结果,
在每个并行过程中对其任务的所有循环汇总结果(本例中是求和),
然后将所有并行过程的汇总结果再汇总(本例中是求和)。
并行运行中每个并行的进程都要有随机数,
所有进程需要使用独立的随机数序列。
经过测试,
上面的串行程序与并行程序得到的估计的标准差基本相同。
并行for循环中对公用的变量或数组写访问一般不可行,
读取则没有问题。
例如,
上面的模拟先将需要用的随机数一次性保存为数组,
然后在并行循环中读取随机数。
在10亿次模拟时内存不够出错,
所以将模拟分批进行,
如果在内层循环使用并行计算,
结果消耗内存较大而且速度比串行版本慢20倍;
下面的版本对各批分配到不同进程并行计算,
先不使用成批的随机数,
与不分批的并行计算速度相仿。
程序:
using Distributed
function f_para01c(n)
nb = 1000
n = Int(ceil(n/nb)*nb)
n1 = Int(n / nb)
res = @distributed (+) for j=1:nb
x = rand(n1)
s = 0.0
for i = 1:n1
s += exp(x[i])
end
s
end
res /= n
return res
end
@time f_para01c(1_000)
@time f_para01c(1_000_000_000)结果为
1.7182779449240668
7.121955 seconds (841 allocations: 37.031 KiB)速度与不分批类似,
但是可以在需要占用内存时利用有限的内存完成任务。
所有在有两重循环时应该将外层循环并行化而不是将内层循环并行化。
并行pmap()和互相不影响的计算
@distributed for比较适用于循环次数很多但每一步都很简单的情形。
对于每一步都可能比较复杂,
但是各步没有互相影响的计算,
可以用pmap()函数。
下面用不同的方法计算10个大的随机矩阵的奇异值:
using LinearAlgebra
rmatl = Matrix{Float64}[rand(100,100) for i=1:1000]
@time res = map(svdvals, rmatl);其中调用LinearAlgebra包是Julia v1.0的要求,v0.6并不需要。结果为
3.273278 seconds (227.37 k allocations: 146.472 MiB, 4.24% gc time)改用pmap()并行计算:
@time res = pmap(svdvals, rmatl);结果:
1.444302 seconds (1.25 M allocations: 63.989 MiB, 0.38% gc time)速度提高了1倍;
但是,如果是
的矩阵执行10次重复计算,
速度仅能提高20%左右。
可见pmap()也是在重复次数比较多的时候提高效率明显。
所有节点需要的包和函数
并行计算时,
可以将主要的程序看作是“主控”节点,
用using调入的包、自定义的函数对主控节点是可见的,
但是如果其它工作节点也需要用到这些包或者函数,
就需要在所有节点中使其可用。
对某个包例如SharedArrays,
可以用@everywhere宏在所有节点调入,如
@everywhere using SharedArrays对自定义函数或模块,
可以将源程序文件用@everywhere include("...")在所有节点载入。
比如,设文件f_para03.jl内容为:
f_para03(x) = sin(x) + cos(x)运行如下代码:
@everywhere include("f_para03.jl")
res = @distributed (+) for i=1:100
f_para03(Float64(i))
end结果为
-0.6594596218908123因为用到并行计算的程序往往都是比较耗时的程序,
所以很可能会非交互地运行。
假设所有的并行工作节点都需要fun1.jl和fun2.jl中的程序,
而drv.jl是主控程序,
可以用如下的操作系统命令非交互地并行运行(主控程序中用了@distributed、pmap()等并行控制):
julia -p 8 -L fun1.jl -L fun2.jl drv.jl其中-p 8选项表示有8个核心可以并行使用。-L选项给出每个工作节点需要预先调用的初始化程序。
比例的置信区间模拟研究并行计算示例
问题
统计计算的一部分工作是用随机模拟比较不同的统计方法的性能。
设总体某属性的真实比例为
,n个样本中具有该属性的个数为x,
Julia的HypothesisTests包提供了
的置信区间的若干种计算方法。
如下程序
Using HypothesisTests
testr = BinomialTest(x, n, 0.5)产生一个二项分布检验结果,
然后用
confint(testr, alpha, method=:wald)可以用正态近似方法求置信度为1-alpha的Wald置信区间,
这种方法在真实比例
接近0或者1时效果很差。
如下程序
confint(testr, alpha, method=:wilson)计算基于正态近似的Wilson置信区间,
效果优于Wald方法。
希望对不同的样本量
,不同的真实比例
,
对每一种
组合,
产生
批随机样本,
分别用两种方法计算置信度为0.90、0.95和0.99的置信区间,
比较两种方法得到的区间的覆盖率与置信度。
覆盖率是指置信区间包含真实比例的百分比。
设每个组合的重复样本数
,
样本量
取100, 500, 1000,
真实比例
取0.5, 0.05, 0.01,
共有
种参数组合
(实际问题一般有几十种或几百种参数组合)。
一组参数的模拟程序
对每一组
值,
可以用如下的程序进行一次模拟:
## 比例的置信区间模拟比较。
## 一个样本量和比例组合的多批样本的模拟。
using Random, Distributions, HypothesisTests
function f_paraci(
n::Int, # 样本量
p::Float64, # 真实比例
M::Int) # 重复模拟次数
# 记录覆盖次数,第一行为Wald方法,第二行为Wilson方法
# 三列分别对应于三个水平alpha值
ncov = [0 0 0;
0 0 0]
alphas = [0.10, 0.05, 0.01]
for i = 1:M
x::Int = rand(Binomial(n, p))
if x==0 || x==n
continue
end
testr = BinomialTest(x, n, 0.5)
for j in eachindex(alphas)
low,hi = confint(testr, alphas[j], method=:wald)
if low < p < hi
ncov[1,j] += 1
end
low,hi = confint(testr, alphas[j], method=:wilson)
if low < p < hi
ncov[2,j] += 1
end
end # for j
end # for i
cover = ncov ./ M
println("n=", n, " p=", p)
println(cover)
cover
end为了对某一个参数组合计算,
只要在Julia命令行REPL中运行命令如
@time f_paraci(1000, 0.01, 10_000_000)结果如
n=1000 p=0.01
[0.9074386 0.9269796 0.9706971; 0.9234359 0.9634912 0.9926302]
9.342665 seconds (62 allocations: 4.219 KiB)
2×3 Array{Float64,2}:
0.907439 0.92698 0.970697
0.923436 0.963491 0.99263取
时每组参数模拟需要10秒左右。
人工并行计算
如果有9组参数需要模拟,
假设上面的对一组参数模拟的函数保存在源文件simu-ci.jl中,
可以制作如下的9个源文件,
第一个命名为simu01.jl,内容为
include("simu-ci.jl")
print(f_paraci(100, 0.5, 10_000_000))其它的8个源文件只是
组合值不同。
在MS Windows操作系统中(Linux类似),
假设有4个CPU核心,
可以在源程序所在的文件夹打开4个操作系统命令窗口
(MS Windows是CMD或者PowerShell, Linux是Bash Shell),
分别运行命令如
D:\JuliaPro-1.4.0-1\Julia-1.4.0\bin\julia.exe simu01.jl其中的julia.exe路径应该替换成自己的Julia可执行程序路径。
等待每个窗口的程序执行结束,
就依次调用下一个模拟源程序。
这种做法好处是不需要利用语言本身的并行计算功能,
在参数组合不太多,
而每个参数组合运行时间很长的时候是很实用的做法。
但是组合太多的时候人为调度任务就太麻烦了。
利用Julia分布式计算
设一次模拟的函数f_paraci()定义在simu-ci.jl源文件中。
定义如下的主控文件simu-main.jl:
using Distributed
function simu_all()
M = 10_000_000
pars = [(n, p) for n in [100, 500, 1000], p in [0.5, 0.05, 0.01]]
res = pmap(parone -> f_paraci(parone[1], parone[2], M), pars)
end
@time res = simu_all()打开一个单独的julia命令行,
用如下命令增加可核心(工作节点)个数,
并在工作节点载入所需的包和模拟一次用的函数:
using Distributed
addprocs(7)
@everywhere using Random
@everywhere using Distributions
@everywhere using StatsBase
@everywhere using HypothesisTests
@everywhere include("simu-ci.jl")然后
可以使用8个节点并行计算。
另一种方法是非交互运行,
在操作系统命令行中运行:
D:\JuliaPro-1.4.0-1\Julia-1.4.0\bin\julia.exe -p 8 -L simu-ci.jl simu-main.jl但是在我的JuliaPro1.4.0 Window版系统中,
非交互式运行总提示在工作节点处找不到某些要载入的包如Distributions。
经过试验,
取
时在一台Intel 酷睿i7 8550U 8核心笔记本电脑上运行了41秒。
将程序改为如下非并行版本,运行了79秒,
并行版本速度提高了1倍左右。
当参数组合更多,
每次建模耗时更多,
重复数更多时,
并行计算是很有意义的。
include("simu-ci.jl")
function simu_all_single()
M = 10_000_000
pars = [(n, p) for n in [100, 500, 1000], p in [0.5, 0.05, 0.01]]
res = map(parone -> f_paraci(parone[1], parone[2], M), pars)
end
@time res = simu_all_single()多只股票投资策略实证分析
证券投资策略研究中往往需要对多支证券的历史数据进行投资策略的实证分析,
从而找到在历史数据上较优的策略。
对一支股票,
策略研究需要考虑的参数也有计算区间的长度选择,
策略实施的区间长度选择等变量,
所以组合起来有很大的计算量,
有必要采用并行计算加速,
Julia语言对于显式循环的高效率也使得Julia语言比较适用于金融投资策略研究。
这个示例使用Julia v1.4.0运行。
首先模拟生成100支股票1000天的股价数据:
using Distributions
function price_sim(nstocks=100, ndays=1000)
pdata = Matrix{Float64}(undef, (ndays, nstocks))
for j=1:nstocks
# j: 每只股票
# 每只股票有自己的波动率数值
sig = rand(Uniform(0.01, 0.02))
pdata[:,j] .= round.(
rand(Uniform(10.0, 100.0)) .*
exp.(cumsum(randn(ndays) .* sig)),
digits = 2)
end
return pdata
end
pdata = price_sim(100, 1000);
using Plots
Plots.gr()
Plots.plot(pdata[:,1:5])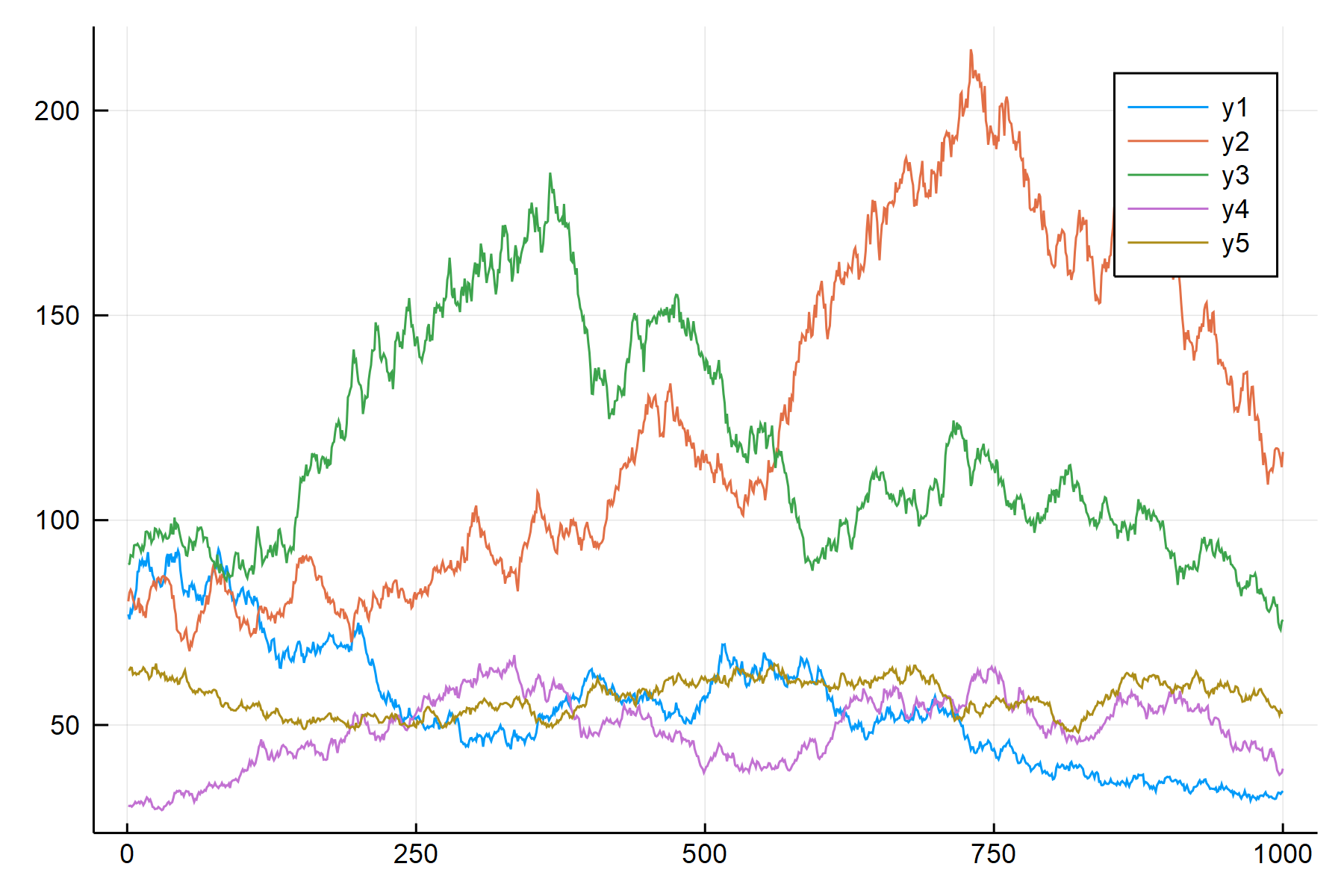

svg
上面的结果显示了模拟的100支股票中前5支的价格序列。
假设对每支股票采用如下的投资策略回测研究:
依次截取
天的价格统计其20%分位数
和80%分位数
(也可以是更一般的分位数),
然后在后续的
天中(经常是一个月)当价格首次低于
时就开仓买入一个单位,
然后在这
天中当价格首次高于
时就卖出,到
天的最后一天时不管价位如何都卖出。
如果在
天中卖出了,卖出的第二天开始后续的
天的统计,
如果没有开仓,则在
天结束后开始第二轮的
天的统计。
如果需要试验不同的
的取法组合,
计算量会比较大。
对一支股票的策略回测函数为:
function testone(x::Vector{Float64}, n1=30, n2=30)
ndays = length(x)
t = 1
earn = 0.0
while t < ndays - (n1 + n2)
# 首先进行n1天的统计
lo, hi = quantile(x[t:(t+n1-1)], [0.2, 0.8])
# 然后在后续的n2天寻找开仓时机
t += n1
t1 = t
p_buy = NaN
p_sell = NaN
for t1 in t:(t+n2-2)
if x[t1] < lo
p_buy = x[t1]
break
end
end
if !isnan(p_buy) # 有买入,查找从t1+1到t+n2-1天的卖出时机
for t2=(t1+1):(t+n2-1)
if x[t2] > hi
p_sell = x[t2]
earn += p_sell - p_buy
t = t2 + 1 # 开始下一轮
break
end
end
# 如果没有卖出就在n2天的最后一天平仓
if isnan(p_sell)
p_sell = x[t+n2-1]
earn += p_sell - p_buy
t += n2
end
end
end # while t
return earn
end
function testn(x, n1vec, n2vec)
[testone(x, n1, n2) for n1 in n1vec, n2 in n2vec]
end设以上函数存入了sim-stock-fun.jl中。
比较串行和并行程序:
using Distributed
addprocs(7)
@everywhere include("sim-stock-fun.jl")
pdata = price_sim(1000, 3000);串行版本1:
@time for j = 1:size(pdata,2)
x = testn(pdata[:,j], 20:40, 30:50)
end
## 43.397073 seconds (172.90 M allocations: 23.689 GiB, 3.79% gc time)串行版本2:
@time map(j -> testn(pdata[:,j], 20:40, 30:50),
1:size(pdata,2));
## 49.662468 seconds (173.10 M allocations: 23.699 GiB, 3.44% gc time)并行版本:
using Distributed
@time pmap(j -> testn(pdata[:,j], 20:40, 30:50),
1:size(pdata,2));
## 19.880122 seconds (1.02 M allocations: 53.250 MiB, 0.03% gc time)结果发现小规模计算时并行版本更慢,
串行版本的map()函数分配内存次数和总量都很大,pmap()则相对来说很少。
较大计算量时串行计算CPU占用率仅30%左右,并行计算时CPU占用有80%左右,
3000支股票1000天的数据,建模窗宽与执行窗口共441种组合,
都能在几十秒内完成,
并行算法快一倍多。
更复杂的建模可能会速度慢得多,
这时并行的速度提升就很有意义;
即使仅使用串行算法,
使用Julia会比同样方法的R、Python等程序快10倍以上。
亚式期权计算例子
下面的例子是用亚式Julia随机模拟方法对亚式期权定价的例子,
来自Mastering Julia。
用了不同的编程方法比较效率,
Julia用了8.7秒,
未向量化的R程序用了93秒,
向量化的R程序用了12.6秒,
用Rcpp连接C++程序的版本用了7.8秒。
Julia与C++程序效率相近。
mean(x) = sum(x)/length(x)
function run_asian(N = 100000, PutCall='C';)
# 来自Mastering Juia P.16
# 股票期权分为看涨期权(call option)和看跌期权(put option)。
# 交易双方称为granter(期权卖家)和beneficiary(期权买家)。
# 以看涨期权为例,期权买家付出一定的期权价格从期权买家手里购买一个权力,
# 在指定的时间以后可以用预先指定价格从期权卖家手里购买股票,
# 当然对买家不利时买家可以不行使此权利。
# 亚式期权的收益依赖于整个价格路径的算数平均,所以需要模拟许多条路径
println("Setting option parameters")
S0 = 100 # spot price,当前价格
K = 100 # strike price,执行价格
r = 0.05 # risk free rate,无风险利率
q = 0.0 # dividend yield,红利
v = 0.2 # Volatility,波动率
tma = 0.25 # time to maturity,期权的交割时间
Averaging = 'A' # 'A' 用算数平均,'G'用几何平均
OptType = (PutCall == 'C' ? "CALL" : "PUT") # 看涨期权还是看跌期权
println("Option type is $OptType")
# 模拟设置
println("Setting simulation parameters")
T = 100 # number of time steps,模拟路径时的时间片段个数
dt = tma / T # time increment per step,模拟路径时每隔多长时间更新状态
# Initialize the terminal stock price matrices
# for the Euler and Milstein discretization schemes.
# 初始化终端市场股票价格矩阵,采用Euler和Milstein离散化方案。
# 矩阵S的每行为一条轨道,每列为一个时间点
S = zeros(Float64, N, T)
for n=1:N
S[n,1] = S0
end
# Simulate the stock price under the Euler and Milstein schemes.
# Take average of terminal stock price.
# 下面对每条轨道(变量n),沿时间t向前模拟。最后计算终端股价的算数平均值。
println("Looping $N times")
A = zeros(Float64, N); # A用来存储每条轨道沿时间的平均值。
for n = 1:N
for t = 2:T
dW = (randn(1)[1])*sqrt(dt) # N(0, \sqrt{dt})随机变量
z0 = (r - q - 0.5*v*v)*S[n,t-1]*dt
z1 = v*S[n, t-1]*dW
z2 = 0.5*v*v*S[n,t-1]*dW*dW
S[n,t] = S[n, t-1] + z0 + z1 + z2
end
if cmp(Averaging, 'A') == 0
A[n] = mean(S[n, :])
elseif cmp(Averaging, 'G') == 0
A[n] = exp(mean(log(S[n,:])))
end
end
# define the payoff(计算每条轨道的收益)
P = zeros(Float64, N)
if cmp(PutCall, 'C') == 0
for n = 1:N
P[n] = max(A[n] - K, 0);
end
elseif cmp(PutCall, 'P') == 0
for n = 1:N
P[n] = max(K - A[n], 0);
end
end
# Calculate the price of the Asian option(计算亚式期权的价格)
AsianPrice = exp(-r*tma)*mean(P)
println("Price: ", AsianPrice)
end
@time run_asian(1000000, 'C')
## Setting simulation parameters
## Looping 1000000 times
## Price: 2.5879421759595704
## 8.717699 seconds (100.18 M allocations: 10.455 GiB, 19.93% gc time)Julia版本用了8.7秒。速度很好。
将Julia版本改成R版本,没有过多的向量化处理,用了93秒,
与Julia版本运行速度相差10倍以上:
run_asian <- function(N = 100000, PutCall='C'){
# 来自Mastering Juia P.16,改变自Julia版本
# 股票期权分为看涨期权(call option)和看跌期权(put option)。
# 交易双方称为granter(期权卖家)和beneficiary(期权买家)。
# 以看涨期权为例,期权买家付出一定的期权价格从期权买家手里购买一个权力,
# 在指定的时间以后可以用预先指定价格从期权卖家手里购买股票,
# 当然对买家不利时买家可以不行使此权利。
# 亚式期权的收益依赖于整个价格路径的算数平均,所以需要模拟许多条路径
cat("Setting option parameters\n")
S0 = 100 # spot price,当前价格
K = 100 # strike price,执行价格
r = 0.05 # risk free rate,无风险利率
q = 0.0 # dividend yield,红利
v = 0.2 # Volatility,波动率
tma = 0.25 # time to maturity,期权的交割时间
Averaging = 'A' # 'A' 用算数平均,'G'用几何平均
OptType = ifelse(PutCall == 'C', "CALL", "PUT") # 看涨期权还是看跌期权
cat("Option type is", OptType, "\n")
# 模拟设置
cat("Setting simulation parameters\n")
T = 100 # number of time steps,模拟路径时的时间片段个数
dt = tma / T # time increment per step,模拟路径时每隔多长时间更新状态
# Initialize the terminal stock price matrices
# for the Euler and Milstein discretization schemes.
# 初始化终端市场股票价格矩阵,采用Euler和Milstein离散化方案。
# 矩阵S的每行为一条轨道,每列为一个时间点
S = matrix(0.0, nrow=N, ncol=T)
S[,1] = S0 # 第一列是初始时刻的价格
# Simulate the stock price under the Euler and Milstein schemes.
# Take average of terminal stock price.
# 下面对每条轨道(变量n),沿时间t向前模拟。最后计算终端股价的算数平均值。
cat("Looping", N, "times\n")
A = numeric(N) # A用来存储每条轨道沿时间的平均值。
for(n in 1:N){
dW_arr <- rnorm(T-1, 0, sd=sqrt(dt))
for(t in 2:T){
dW = dW_arr[t-1] # N(0, \sqrt{dt})随机变量
z0 = (r - q - 0.5*v*v)*S[n,t-1]*dt
z1 = v*S[n, t-1]*dW
z2 = 0.5*v*v*S[n,t-1]*dW*dW
S[n,t] = S[n, t-1] + z0 + z1 + z2
} # for t
if(Averaging == 'A'){
A[n] = mean(S[n,])
} else if(Averaging == 'G'){
A[n] = exp(mean(log(S[n,])))
} else {
stop("Averaging selection known!")
} # if
} # for n
# define the payoff(计算每条轨道的收益)
P = numeric(N)
if(PutCall == 'C'){
P = pmax(A - K, 0)
} else if(PutCall == 'C'){
P = pmax(K - A, 0)
}
# Calculate the price of the Asian option(计算亚式期权的价格)
AsianPrice = exp(-r*tma)*mean(P);
return(AsianPrice);
}
print(system.time(run_asian(1E6, 'C'))[3])将一百万次重复模拟向量化,
关于时间t作循环,结果运行时间为12.6秒,
仅比Julia版本慢了不到一倍。程序如下:
run_asian_vec <- function(N = 100000, PutCall='C'){
cat("Setting option parameters\n")
S0 = 100 # spot price,当前价格
K = 100 # strike price,执行价格
r = 0.05 # risk free rate,无风险利率
q = 0.0 # dividend yield,红利
v = 0.2 # Volatility,波动率
tma = 0.25 # time to maturity,期权的交割时间
Averaging = 'A' # 'A' 用算数平均,'G'用几何平均
OptType = ifelse(PutCall == 'C', "CALL", "PUT") # 看涨期权还是看跌期权
cat("Option type is", OptType, "\n")
# 模拟设置
cat("Setting simulation parameters\n")
T = 100 # number of time steps,模拟路径时的时间片段个数
dt = tma / T # time increment per step,模拟路径时每隔多长时间更新状态
# Initialize the terminal stock price matrices
# for the Euler and Milstein discretization schemes.
# 初始化终端市场股票价格矩阵,采用Euler和Milstein离散化方案。
# 矩阵S的每行为一条轨道,每列为一个时间点
S = matrix(0.0, nrow=N, ncol=T)
S[,1] = S0 # 第一列是初始时刻的价格
# Simulate the stock price under the Euler and Milstein schemes.
# Take average of terminal stock price.
# 下面对每条轨道(变量n),沿时间t向前模拟。最后计算终端股价的算数平均值。
cat("Looping", N, "times\n")
dW_arr <- rnorm(T-1, 0, sd=sqrt(dt))
for(t in 2:T){
dW = rnorm(N, 0, sd=sqrt(dt))
z0 = (r - q - 0.5*v*v)*S[,t-1]*dt
z1 = v*S[, t-1]*dW
z2 = 0.5*v*v*S[,t-1]*dW*dW
S[,t] = S[, t-1] + z0 + z1 + z2
} # for t
if(Averaging == 'A'){
A = rowMeans(S)
} else if(Averaging == 'G'){
A = exp(rowMeans(log(S)))
} else {
stop("Averaging selection known!")
} # if
# define the payoff(计算每条轨道的收益)
if(PutCall == 'C'){
P = pmax(A - K, 0)
} else if(PutCall == 'C'){
P = pmax(K - A, 0)
}
# Calculate the price of the Asian option(计算亚式期权的价格)
AsianPrice = exp(-r*tma)*mean(P)
return(AsianPrice)
}
system.time(print(run_asian_vec(1E6, 'C')))[3]在R中用Rcpp将改写为C++的程序连接到R中计算,用了7.8秒,与Julia版本运行速度持平。
设C++源文件名为asian_option.cpp:
#include <Rcpp.h>
using namespace Rcpp;
// [[Rcpp::export]]
double run_asian_Cpp(int N = 100000) {
double S0 = 100; // spot price,当前价格
double K = 100; // strike price,执行价格
double r = 0.05; // risk free rate,无风险利率
double q = 0.0; // dividend yield,红利
double v = 0.2; // Volatility,波动率
double tma = 0.25; // time to maturity,期权的交割时间
char PutCall = 'C';
RNGScope scope; // 设置随机数种子
char Averaging = 'A'; // 'A' 用算数平均,'G'用几何平均
// 模拟设置
int T = 100; // number of time steps,模拟路径时的时间片段个数
double dt = tma / T; // time increment per step,模拟路径时每隔多长时间更新状态
// Initialize the terminal stock price matrices
// for the Euler and Milstein discretization schemes.
// 初始化终端市场股票价格矩阵,采用Euler和Milstein离散化方案。
// 矩阵S的每行为一条轨道,每列为一个时间点
NumericMatrix S(N, T);
for(int i=0; i<N; i++)
S(i,0) = S0; // 第一列是初始时刻的价格
// Simulate the stock price under the Euler and Milstein schemes.
// Take average of terminal stock price.
// 下面对每条轨道(变量n),沿时间t向前模拟。最后计算终端股价的算数平均值。
NumericVector A(N); // A用来存储每条轨道沿时间的平均值。
NumericVector dW_arr(T-1);
double dW, z0, z1, z2;
double An;
for(int n=0; n<N; n++){
dW_arr = rnorm(T-1, 0.0, sqrt(dt));
for(int t=1; t < T; t++){
dW = dW_arr[t-1]; // N(0, \sqrt{dt})随机变量
z0 = (r - q - 0.5*v*v)*S(n,t-1)*dt;
z1 = v*S(n,t-1)*dW;
z2 = 0.5*v*v*S(n,t-1)*dW*dW;
S(n,t) = S(n,t-1) + z0 + z1 + z2;
} // for t
if(Averaging == 'A'){
An = 0.0;
for(int i=0; i<T; i++){
An += S(n,i);
}
A[n] = An / T;
} else if(Averaging == 'G'){
An = 0.0;
for(int i=0; i<T; i++){
An += log(S(n,i));
}
An /= T;
A[n] = exp(An);
} else {
Rf_error("Error Averaging!");
} // if
} // for n
// define the payoff(计算每条轨道的收益)
NumericVector P(N);
if(PutCall == 'C'){
for(int i=0; i<N; i++){
double Pi = A[i] - K;
if(Pi < 0.0) Pi = 0.0;
P[i] = Pi;
}
} else if(PutCall == 'C'){
for(int i=0; i<N; i++){
double Pi = K - A[i];
if(Pi < 0.0) Pi = 0.0;
P[i] = Pi;
}
}
// Calculate the price of the Asian option(计算亚式期权的价格)
An = 0.0;
for(int n=0; n<N; n++){
An += P[n];
}
An /= N;
double AsianPrice = exp(-r*tma)*An;
return(AsianPrice);
}R接口:
sourceCpp(file="asian_option.cpp")
system.time(print(run_asian_Cpp(1E4)))[3]
## [1] 2.587442
## elapsed
## 7.8 韭菜热线原创版权所有,发布者:风生水起,转载请注明出处:https://www.9crx.com/75721.html




