

概率论例子
取帽子问题
问题介绍与推导
设
n个人都戴了帽子参加聚会,
聚会时摘下帽子弄乱了,
散会时随机抽取一顶。
问:所有人都没有取到自己的帽子的概率是多少?
令
Ai表示第
i个人取对自己的帽子,
要求概率的事件为
B=⋂i=1nAic.
由概率论的Jordan公式,
P(B)=1−P(Bc)=1−P(⋃i=1nAi)=1−[∑iP(Ai)−∑i<jP(AiAj)+∑i<j<kP(AiAjAk)+⋯+(−1)n−1P(A1A2⋯An)].
根据对称性,
P(Ai)=P(A1)=1n,
P(AiAj)=P(A1A2)=1n1n−1,
P(AiAjAk)=P(A1A2A3)=1n1n−11n−2,
有
m个
Ai的交集的概率为
(n−m)!n!,
这样的交集共有
(nm)=n!m!(n−m)!个,
所以
P(B)=1−∑m=1n(−1)m−1n!m!(n−m)!(n−m)!n!=1−∑m=1n(−1)m−11m!=∑m=0n(−1)m1m!.
用计算机程序验证此公式。
理论公式的程序
function hat_prob_th(n)
local s, a
s = 1//1
a = 1//1
sn = 1
for k=1:n
a *= -1 // k
s += a
end
return s
end
hat_prob_th.(1:10) |> show
## Rational{Int64}[0//1, 1//2, 1//3, 3//8, 11//30,
## 53//144, 103//280, 2119//5760, 16687//45360, 16481//44800]用穷举法计算理论值
function hat_exaust(n::Int)
local Ai_vec, Ω, Ai
# 生成样本空间为1:n的所有排列
Ω = collect(permutations(1:n))
# 生成各个事件为所包含的基本事件的集合
Ai_vec = []
for i=1:n
# 对$A_i$
Ai = []
for ω ∈ Ω
if ω[i] == i
push!(Ai, ω)
end
end
push!(Ai_vec, Ai)
end # for i
noMatch = setdiff(Ω, union(Ai_vec...))
length(noMatch) // length(Ω)
end
hat_exaust.(1:10) |> show
## Rational{Int64}[0//1, 1//2, 1//3, 3//8, 11//30,
## 53//144, 103//280, 2119//5760, 16687//45360, 16481//44800]上面的程序中,
用
1:n的所有
n!个排列组成了样本空间
Ω,
对每个事件
Ai,
都对每一个
ω∈Ω查看是否
ω∈Ω,
如果
ω∈Ω就把
ω存入集合
Ai中。
这样,
把所有
Ai保存为一个集合的序列Ai_vec,
然后用union(Ai_vec...)计算所有这些
Ai的并集,
用setdiff(Ω, union(Ai_vec...))计算所有
Aic的交集,
用古典概型估计
P(B)。
随机模拟方法
# 某种取法是否有人取对的函数
function any_match(perm, n)
return any(perm .== collect(1:n))
end
# 对n个人的问题模拟计算概率的函数
function hat_sim(n, N=1_000_000)
1 - sum(any_match(randperm(n), n) for _ in 1:N) / N
end
# 测试,取n=1:10
nn = 10
p_th = round.(float.(hat_prob_th.(1:nn)), digits=4)
p_sim = round.(hat_sim.(1:nn), digits=4)
[1:nn p_th p_sim]结果:
10×3 Matrix{Float64}:
1.0 0.0 0.0
2.0 0.5 0.4992
3.0 0.3333 0.333
4.0 0.375 0.3745
5.0 0.3667 0.3665
6.0 0.3681 0.3681
7.0 0.3679 0.3681
8.0 0.3679 0.3688
9.0 0.3679 0.3671
10.0 0.3679 0.3675注意到理论公式的值当
n较大时
接近于
e−1的泰勒展开级数,
所以
n较大时所有人都没有取对的概率近似等于
e−1=0.3678794。
可重复分组问题
问题和推导
设有
n个编号的球,
有放回随机抽取
m次,
记录第
i个球出现的次数为
Xi,
考虑随机向量
X=(X1,X2,…,Xn)的分布。
这个模型也可以表述为有
m个不可区分的球,
有
n个编号的箱子,
将
m个球依次随机地放入箱子,
问每个箱子中球的个数组合的分布。
这是多项分布,
所以
P(X1=k1,X2=k2,…,Xn=kn)=(mk1,k2…,kn)(1n)k1(1n)k2…(1n)kn=m!k1!k2!…kn!n−m.
验证这个概率公式。
穷举所有取值
用穷举所有
(k1,k2,…,kn)组合计算所有对应概率,
然后检查和是否等于1来检查这个公式有没有错误。
如何穷举
(k1,k2,…,kn)组合?
其中
k1+k2+⋯+kn=m。
先看有多少个这样的组合。
我们想象有
n个箱子排成一排并编号
1:n,
每次抽取的球放入对应号码的箱子中(因为是有放回,所以可以认为是放了同号码球的复制品)。
用
n−1个1代表两个箱子之间的边界,
用
m个0代表箱子中的球,
用
n+m−1个0-1序列代表某种结果。
比如
010010表示
n=3,
m=4,
X1=1,
X2=2,
X3=1。
显然,总的可能个数是从
n+m−1个二进制位中选出
n−1个1的位置的组合数
(n+m−1n−1)。
计算所有结果数的函数,
和某一个结果的概率的函数如下:
using Combinatorics: multinomial, combinations
function n_xvalues(n, m)
binomial(n+m-1, n-1)
end
function prob(x::Vector, n, m)
@assert sum(x)==m
multinomial(x...) / n^m
end下面的函数将0-1序列表示的结果转换为多项分布向量结果,
并罗列多项分布所有可能结果:
# 从0-1数列表示转换成(x1, ..., xn)的表示
function bin2mult(bits::Vector)
n = sum(bits) + 1
x = zeros(Int, n)
kx = 1
for bit in bits
if bit == 0
x[kx] += 1
else
kx += 1
end
end
return x
end
# 罗列所有可能组合:
function make_xvalues(n,m)
# 找出0-1序列中n-1个1的位置,穷举所有可能
npos = Combinatorics.combinations(1:(n+m-1), n-1)
xs = Vector{Int}[]
bits = zeros(Int, n+m-1)
for pos in npos
bits[:] .= 0
bits[pos] .= 1
push!(xs, bin2mult(bits))
end
return xs
end下面的函数对某对
n,m值计算分布概率和:
function prob_sum(n, m)
xs = make_xvalues(n, m)
probs = map(x -> prob(x, n, m), xs)
sum(probs)
end下面的程序对多个
n,m组合检查概率和是否等于1:
for n=2:10, m=1:20
if !(prob_sum(n,m) ≈ 1.0)
@show n, m, prob_sum(n,m);
end
end结果发现当
n≥9,
m≥20时发生错误。
这应该是累积误差造成的,
对
n=10,m=20,
共有10015005种不同结果。
模拟验证
对某个
n,m组合,
模拟
N次,
然后比较所有可能结果的理论概率与模拟样本估计的频率。
using DataFrames
function sim(n, m, N=1_000_000)
# 随机向量所有可能取值组合的列表
xvalues = make_xvalues(n,m)
# 用字典来保存从随机向量取值组合到概率或频数的
prob_th = Dict(Tuple(x) => prob(x, n, m) for x in xvalues)
xfreqs = Dict(Tuple(x) => 0 for x in xvalues)
for i=1:N
# xvs用来保存某一次模拟的随机向量取值
xvs = zeros(Int, n)
# 随机有放回地从1:n中抽取m次
draws = [rand(1:n) for _ in 1:m]
for k=1:n
xvs[k] += count(d -> d==k, draws)
end
xfreqs[Tuple(xvs)] += 1
end
# 下面将随机向量每个取值组合、理论概率、模拟估计频率列表
xv_mat = reduce(vcat, x' for x in xvalues)
pr0 = zeros(size(xv_mat, 1))
pr1 = zeros(size(xv_mat, 1))
for i=1:size(xv_mat,1)
xvt = Tuple(xv_mat[i,:])
pr0[i] = prob_th[xvt]
pr1[i] = xfreqs[xvt] / N
end
xv_df = DataFrame(reduce(vcat, x' for x in xvalues),
:auto)
xv_df[!,:prob_th] = pr0
xv_df[!,:prob_sim] = pr1
xv_df
end
# 测试
Random.seed!(101)
sim(3,4)结果:
15×5 DataFrame
Row │ x1 x2 x3 prob_th prob_sim
│ Int64 Int64 Int64 Float64 Float64
─────┼──────────────────────────────────────────
1 │ 0 0 4 0.0123457 0.012519
2 │ 0 1 3 0.0493827 0.049381
3 │ 0 2 2 0.0740741 0.074013
4 │ 0 3 1 0.0493827 0.049132
5 │ 0 4 0 0.0123457 0.012562
6 │ 1 0 3 0.0493827 0.049522
7 │ 1 1 2 0.148148 0.148013
8 │ 1 2 1 0.148148 0.148371
9 │ 1 3 0 0.0493827 0.049498
10 │ 2 0 2 0.0740741 0.074574
11 │ 2 1 1 0.148148 0.148458
12 │ 2 2 0 0.0740741 0.07349
13 │ 3 0 1 0.0493827 0.049227
14 │ 3 1 0 0.0493827 0.049107
15 │ 4 0 0 0.0123457 0.012133 多人博弈连续胜出问题
例子来自Ross Introduction to Probablity Models 12th Ed P.439 例7.7。
设有
n个人比赛,
每一轮有且仅有一个人获胜,
每个人在一轮中获胜的概率为
p1,…,pn,
每当同一个人
k次连续获胜时就结束一局比赛,
开始新的一局,
k≥2。
问每个人赢得一局的概率是多少,
平均多长时间完成一局比赛。
用全期望公式和更新过程理论可以推导出每个人赢得一局的概率为
wi∝pik(1−pi)1−pik.
平均每局的时间为
E(T)=(∑i=1npik(1−pi)1−pik)−1.
用随机模拟方法进行验证。
程序和结果如下:
# 多人连胜游戏。每次某人连胜k轮时结束一局比赛。
# 输入:
# pw: 每人的获胜概率
# k: 连胜多少轮算一局结束
# N: 模拟重复的轮数
using Random, Distributions
using Statistics, StatsBase
function simone(pw::Vector; k=2, N=1000_000)
n = length(pw)
rates = pw .^ k .* (1 .- pw) ./ (1 .- pw .^ k)
# 每人理论获胜概率
probs = rates ./ sum(rates)
# 平均每局时间的理论值
mean_time = 1 / sum(rates)
# 一次性生成N轮的输赢
xv = StatsBase.sample(1:n, StatsBase.Weights(pw),
N; replace=true)
winners = Int[]
times = Int[]
# 下面循环找到每一局,条件是最后的k个为相同胜者
istart = 1
i = k
while i <= N
if all(xv[i-k+1:i-1] .== xv[i])
## 找到k个连续,结束一局,开始新的一局
push!(winners, xv[i])
push!(times, i - istart + 1)
istart = i+1
i += k
else
i += 1
end
end # while i
# 获胜者频率估计
freqs = counts(winners, 1:n)
probs_est = freqs ./ sum(freqs)
# 平均每局时间估计
mean_time_est = mean(times)
println("理论概率与模拟估计概率:")
display(round.([probs probs_est], digits=6))
println("理论平均时间与模拟估计值:")
show(round.([mean_time, mean_time_est], digits=4))
return
end
function test(k=2, N=1000)
pw = [1/2, 1/3, 1/6]
simone(pw, k=k, N=N)
end
Random.seed!(101)
test(2, 1000_000)
## 理论概率与模拟估计概率:
## 3×2 Matrix{Float64}:
## 0.608696 0.608658
## 0.304348 0.303514
## 0.086957 0.087829
## 理论平均时间与模拟估计值:
## [3.6522, 3.6565]
test(3, 1000_000)
## 理论概率与模拟估计概率:
## 3×2 Matrix{Float64}:
## 0.707595 0.706294
## 0.254008 0.254546
## 0.038397 0.03916
## 理论平均时间与模拟估计值:
## [9.9063, 9.9466]统计学例子
威布尔参数估计
考虑威布尔分布的矩估计问题。
威布尔分布密度函数为
f(x;m,η)=mη(xη)m−1exp[−(xη)m], x>0.
期望和方差为
EX=Γ(1+1m),Var(X)=η2[Γ(1+2m)−(Γ(1+1m))2].
矩估计法
设样本均值、方差分别为
X¯,
S2,
求解关于
(m,η)的非线性方程组
Γ(1+1m)=X¯,η2[Γ(1+2m)−(Γ(1+1m))2]=S2.
可以求得参数的矩估计
(m^,η^)。
这有一个危险,
就是这个非线性方程组可能解不唯一,
求解的迭代算法可能不收敛到方程组的零点。
举例说明:
using Random, Distributions, SpecialFunctions, Statistics
Random.seed!(101)
dist = Weibull(2.0, 4.0)
samp = rand(dist, 100)
xbar = mean(samp)
S2 = var(samp)
xbar, S2
## (3.8028830034916767, 3.567696384660564)用NLsolve包求解:
using NLsolve
function eqnf!(F, x)
m, η = x
F[1] = gamma(1 + 1.0/m) - xbar
F[2] = η^2 * (gamma(1 + 2/m) - gamma(1 + 1/m)^2) - S2
return
end
x0 = [1.0, 1.0]
res = nlsolve(eqnf!, x0, autodiff=:forward)其中eqnf!函数将计算得到的两个方程返回到输入的自变量F中。x0为初值。
结果:
Results of Nonlinear Solver Algorithm
* Algorithm: Trust-region with dogleg and autoscaling
* Starting Point: [1.0, 1.0]
* Zero: [0.3816718560241766, 0.14606373284767674]
* Inf-norm of residuals: 0.000000
* Iterations: 15
* Convergence: true
* |x - x'| < 0.0e+00: false
* |f(x)| < 1.0e-08: true
* Function Calls (f): 12
* Jacobian Calls (df/dx): 8结果收敛了,
方程组的结果的函数值都等于0。
但是,
估计的参数值为
m=0.38,
η=0.15,
与真实值
(2,4)差距很大,
说明方程组解不唯一。
换一组初值,
使用模拟时的参数真实值作为初值:
x0 = [2.0, 4.0]
res = nlsolve(eqnf!, x0, autodiff=:forward)Results of Nonlinear Solver Algorithm
* Algorithm: Trust-region with dogleg and autoscaling
* Starting Point: [2.0, 4.0]
* Zero: [0.5756992788212827, 0.7052533506778957]
* Inf-norm of residuals: 2.211473
* Iterations: 8
* Convergence: false
* |x - x'| < 0.0e+00: false
* |f(x)| < 1.0e-08: false
* Function Calls (f): 9
* Jacobian Calls (df/dx): 4结果没有收敛。
这说明威布尔分布不适合使用矩估计法。
最大似然估计法
设样本为
x1,x2,…,xn。
对数似然函数为
logL(m,η)=nlog(m)−nmlog(η)+(m−1)∑ilogxi−η−m∑xim.
为避免
m>0,
η>0的约束,
令
a=logm,
b=logη,
取目标函数为关于
a,b的负对数似然函数:
h(a,b)=−na+nmb−(m−1)∑ilogxi+η−m∑ixim.
用Optim包求解上述目标函数的最小值点。
using Optim, ForwardDiff
function mle_wei(x, x0=log.([1.0, 1.0]))
n = length(x)
sumlogx = sum(log.(x))
# 负对数似然函数
function objf(xv)
a, b = xv
m = exp(a)
eta = exp(b)
-n*a + n*m*b - (m-1) * sumlogx + sum(x .^ m) / eta^m
end
ores = Optim.optimize(objf, [0.0, 0.0], Newton(); autodiff = :forward)
#ores = Optim.optimize(objf, [0.0, 0.0])
display(ores)
a, b = Optim.minimizer(ores)
[exp(a), exp(b)]
end
mle_wei(samp) |> show * Status: success
* Candidate solution
Final objective value: 1.996358e+02
* Found with
Algorithm: Newton's Method
* Convergence measures
|x - x'| = 3.69e-10 ≰ 0.0e+00
|x - x'|/|x'| = 2.53e-10 ≰ 0.0e+00
|f(x) - f(x')| = 2.84e-14 ≰ 0.0e+00
|f(x) - f(x')|/|f(x')| = 1.42e-16 ≰ 0.0e+00
|g(x)| = 1.42e-13 ≤ 1.0e-08
* Work counters
Seconds run: 0 (vs limit Inf)
Iterations: 6
f(x) calls: 20
∇f(x) calls: 20
∇²f(x) calls: 6
[2.138207889557369, 4.299549737307604]估计的参数值为
(2.14,4.30)。
最小二乘法
威布尔分布函数为
F(x)=1−exp[−(xη)m], x>0,
生存函数为
S(x)=exp[−(xη)m], x>0.
设样本的次序统计量为
t1≤t2≤⋯≤tn,
估计
S(ti)为
S^(ti)=n−i+58n+14, n=1,2,…,n,
注意到
log[−logS(x)]=mlogx−mlogη,
记
yi=log(−log(S^(ti))),
xi=logti,
考虑回归问题
yi=a+bxi,
其中
a=−mlogη,
b=m。
求解出
a,b可得
m=b,
η=e−a/b。
using GLM
using DataFrames
n = length(samp)
y = log.(-log.((n .- (1:n) .+ 5/8)/(n+1/4)))
x = log.(sort(samp))
df = DataFrame(x=x, y=y)
lmr = lm(@formula(y ~ x), df)
show(lmr)
a, b = coef(lmr)
m, eta = b, exp(-a/b)StatsModels.TableRegressionModel{LinearModel{GLM.LmResp{Vector{Float64}},
GLM.DensePredChol{Float64, LinearAlgebra.CholeskyPivoted{
Float64, Matrix{Float64}}}}, Matrix{Float64}}
y ~ 1 + x
Coefficients:
─────────────────────────────────────────────────────────────────────────
Coef. Std. Error t Pr(>|t|) Lower 95% Upper 95%
─────────────────────────────────────────────────────────────────────────
(Intercept) -3.16163 0.0430582 -73.43 <1e-86 -3.24708 -3.07618
x 2.16524 0.032482 66.66 <1e-82 2.10078 2.2297
─────────────────────────────────────────────────────────────────────────
(2.165238989151171, 4.30671460249195)估计
m=2.17,
η=4.31,
与最大似然估计结果相近。
最小二乘方法计算仅需要求解线性方程组,
计算量较小。
这个计算中的最小二乘回归是一个一元回归问题,
如果我们仅需要回归系数估计值,
可以不需要调用GLM包,
而是自己写一个小的一元回归系数计算函数:
function simple_reg(x, y)
n = length(x)
mx = mean(x)
my = mean(y)
b = sum((x .- mx) .* (y .- my)) / sum((x .- mx) .^2)
a = my - b * mx
a, b
end测试:
a, b = simple_reg(x, y)
m, eta = b, exp(-a/b)
## (2.1652389891511716, 4.30671460249195)三角形分布参数矩估计
考虑如下的一般三角形分布:
f(x;a,b,c)={2x−a(b−a)(c−a), x∈[a,c),2b−x(b−a)(b−c), x∈[c,b].
可以计算得到前三阶中心矩为:
m1=13(a+b+c),m2=16(a2+b2+c2+ab+bc+ac),m3=110(a3+b3+c3+a2b+a2c+b2a+b2c+c2a+c2b+abc).
用矩估计法估计
a,b,c:
using Random, Distributions, Statistics
using NLsolve, ForwardDiff
Random.seed!(101)
# 生成模拟样本
a, b, c = 3, 5, 4
dist = TriangularDist(a,b,c)
n = 100
samp = rand(dist, n)
# k阶中心矩估计函数:
m_k(k,data) = 1/n*sum(data.^k)
mHats = [m_k(k,samp) for k in 1:3]
# 要求解的方程,函数值返回到F中
function eqnf!(F, x)
a, b, c = x
F[1] = 1/3*( a + b + c) - mHats[1]
F[2] = 1/6*( a^2 + b^2 + c^2 + a*b + b*c + c*a ) - mHats[2]
F[3] = 1/10*( a^3 + b^3 + c^3
+ a^2*(b+c) + b^2*(a+c) + c^2*(a+b) + a*b*c) - mHats[3]
return
end
nlOutput = nlsolve(eqnf!, [ minimum(samp), maximum(samp), mean(samp) ],
autodiff=:forward)
display(nlOutput)
sol = sort(nlOutput.zero)
aHat, cHat, bHat = sol
show((aHat, bHat, cHat))Results of Nonlinear Solver Algorithm
* Algorithm: Trust-region with dogleg and autoscaling
* Starting Point: [3.1321401602888455, 4.847665660768514, 4.041969871032595]
* Zero: [3.0109895917758136, 5.051519606315913, 4.063400415006064]
* Inf-norm of residuals: 0.000000
* Iterations: 4
* Convergence: true
* |x - x'| < 0.0e+00: false
* |f(x)| < 1.0e-08: true
* Function Calls (f): 5
* Jacobian Calls (df/dx): 5
(3.0109895917758136, 5.051519606315913, 4.063400415006064)模拟的真实参数为
(a,b,c)=(3,5,4)。
估计结果
(a,b,c)=(3.01,5.05,4.06)。
注意一到三阶矩的公式关于
a,b,c是对称的,
所以求得解后按
a<c<b重排后输出估计结果。
伽马分布参数估计
设总体
X服从
Γ(α,λ)分布,密度为
p(x;α,λ)={λαxα−1Γ(α)e−λx,x>0,α>0,λ>0,0,其它
设有
X的简单随机样本
X1,X2,…,Xn,则对数似然函数为
l(α,λ)=nαlogλ−nlogΓ(α)+α∑logXi−λ∑Xi−∑logXi,
给定
α>0,先关于
λ求最大值。易见
∂l∂λ=nαλ−∑Xi,
解得稳定点
λ^=λ^(α)=α/X¯,
其中
X¯=1n∑Xi。
又
∂2l∂λ2=−nαλ2<0,
∀λ>0,
所以
λ^(α)是给定
α情形下
l(α,λ)关于自变量
λ的最大值点。
令
l~(α)=l(α,λ^(α)),
则
l~(α)=nαlogα−nlogΓ(α)+α[∑logXiX¯−n]−∑logXi,l~′(α)=nlogα−nψ(α)+∑logXiX¯,
其中
ψ(α)=ddαlogΓ(α)称为digamma函数。
可以证明
l~′(α)严格单调减,
方程
l~′(α)=0存在唯一解
α^,
且
α^=argmaxα>0l~(α),
从而
(α^,λ^(α^))为总体参数的最大似然估计。
原来二维的优化问题简化为一个一元函数
l~(α)的优化问题,
可以用二分法或牛顿法求解方程
l~′(α)=0。
Julia模拟例子:
using Random, Distributions, SpecialFunctions, Statistics
Random.seed!(101)
α,λ=(2.0, 3.0)
n = 100
dist = Gamma(α, 1/λ)
samp = rand(dist, n)
xbar = mean(samp)
using Roots
c1 = sum(log.(samp ./ xbar))
function g(alpha)
n * log(alpha) - n*digamma(alpha) + c1
end
alphahat = Roots.find_zero(g, 1.0)
lambdahat = alphahat / xbar
alphahat, lambdahat
## (1.9778484307569368, 2.9858680740265013)二项分布参数三次方无偏估计
设总体服从二项分布
B(m,θ),
m≥3已知,
0<θ<1未知。
对样本
X1,…,Xn(
n≥2),
求
θ3的无偏估计。
先得到二项分布的矩母函数
g(t)=(θet+1−θ)m,
利用矩母函数求出一、二、三阶矩,
有
mθ=E(X),m(m−1)θ2=E(X2)−E(X),θ3=1m(m−1)(m−2)[E(X3)−3E(X2)+2E(X)].
用程序验证:
using Random, Distributions
using Statistics, StatsBase
function pcest(x, m)
n = length(x)
V3 = sum(x .^ 3) / n
V1 = sum(x) / n
V2 = sum(x .^ 2) / n
#1/(m*(m-1)*(m-2))*(v3 - (3*m-2)*xbar + 3*(m-1)*S2)
1/(m*(m-1)*(m-2))*(V3 - 3V2 + 2V1)
end
function mean_pce(theta; m = 10, n=15, N=100_000)
dist = Binomial(m, theta)
mean([pcest(rand(dist, n), m) for i=1:N])
end
Random.seed!(101)
[[theta^3, mean_pce(theta)] for theta=0.1:0.1:0.9]9-element Vector{Vector{Float64}}:
[0.0010000000000000002, 0.0009987555555555552]
[0.008000000000000002, 0.00795673888888889]
[0.027, 0.027034577777777777]
[0.06400000000000002, 0.06390299444444444]
[0.125, 0.12496742222222224]
[0.216, 0.215703]
[0.3429999999999999, 0.34297825]
[0.5120000000000001, 0.5120347444444445]
[0.7290000000000001, 0.7291053055555556]Satterthwaite两样本t检验统计量分布研究
统计学中一个常见问题是独立的两个正态总体的均值是否相等的检验。
常用的方法是假设方差相等,
然后使用独立两样本t检验法。
但实际中两个总体方差不一定相等。
Satterthwaite检验法使用如下的近似t检验统计量,
不要求方差相等:
T=x¯−y¯Sx2n1+Sy2n2.
在
μx=μy的零假设成立时,
T近似服从
t(v)分布,
其中
v=(Sx2n1+Sy2n2)2Sx2/n1n1−1+Sy2/n2n2−1.
v不一定是整数值。
t分布可以推广到允许自由度非整数值。
这个近似分布的精确程度如何?
我们针对不同的样本量,
不同的方差比值做一些模拟研究。
我们对给定的
n1,n2,
σx2,
σy平方,
模拟产生
N组样本,
每组样本产生相应的T统计量
ti和相应的自由度
vi,
i=1,2,…,N。
用模拟方法研究
T统计量是否服从
t(v)分布。
这里的困难是,
每个不同的
ti服从不同的t分布,
所以无法直接做QQ图,
或者作直方图然后叠加理论分布密度图。
为此,
我们计算
ti的正态分数:
因为理论上
ti服从
t(vi)分布,
所以
Ft(ti,vi)应服从U(0,1)均匀分布,
其中
Ft(⋅,n)是自由度为
n的t分布的分布函数。
于是,
Φ−1(Ft(ti,vi))应该服从标准正态分布,
其中
Φ(⋅)是标准正态分布函数,
Φ−1是标准正态分布分位数函数。
这样,
令
zi=Φ−1(Ft(ti,vi)),
{zi,i=1,2,…,N}应表现为来自标准正态分布的随机样本。
我们用正态QQ图验证。
using Statistics
# 计算Satterthwaite两样本t统计量和近似自由度
function tstat_satt(x, y)
n1 = length(x)
n2 = length(y)
sx2 = var(x)
sy2 = var(y)
v = (sx2/n1 + sy2/n2)^2 /
((sx2/n1)^2/(n1-1) + (sy2/n2)^2/(n2-1))
t = (mean(x) - mean(y)) / sqrt(sx2/n1 + sy2/n2)
return (t, v)
end
# 将t统计量按理论分布转换为正态分布
using Distributions
z_satt(t, v) = quantile(Normal(), cdf(TDist(v), t))
# 模拟
function sim_satt(n1=10, n2=10, sx2=1.0, sy2=1.0; N=10_000)
t_vec = zeros(N)
v_vec = zeros(N)
q_vec = zeros(N)
for i=1:N
x = randn(n1) .* sqrt(sx2)
y = randn(n2) .* sqrt(sy2)
t, v = tstat_satt(x, y)
t_vec[i] = t
v_vec[i] = v
end
z_vec = [z_satt(t_vec[i], v_vec[i]) for i=1:N]
# 作Z分数的正态QQ图
fig, ax, plt = qqnorm(z_vec, qqline=:identity)
display(fig)
fig
end相等样本量,
相等方差的情形:
using Random
Random.seed!(101)
using CairoMakie
CairoMakie.activate!()
sim_satt(10, 10, 1.0, 1.0);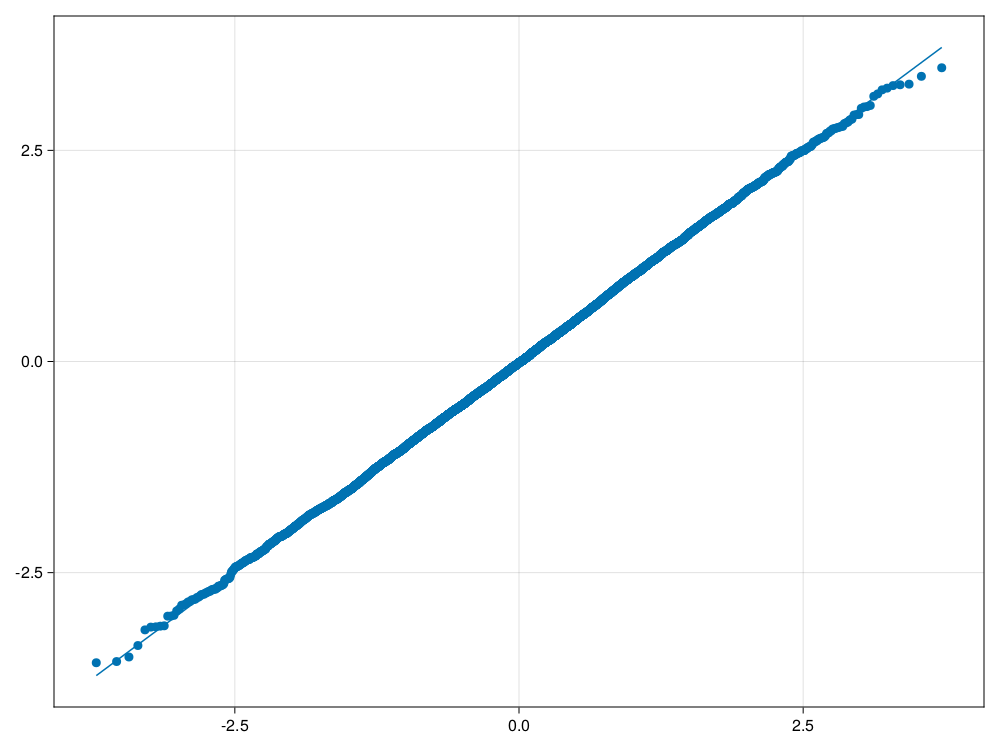

相等样本量,2倍方差的情形:
sim_satt(10, 10, 2.0, 1.0);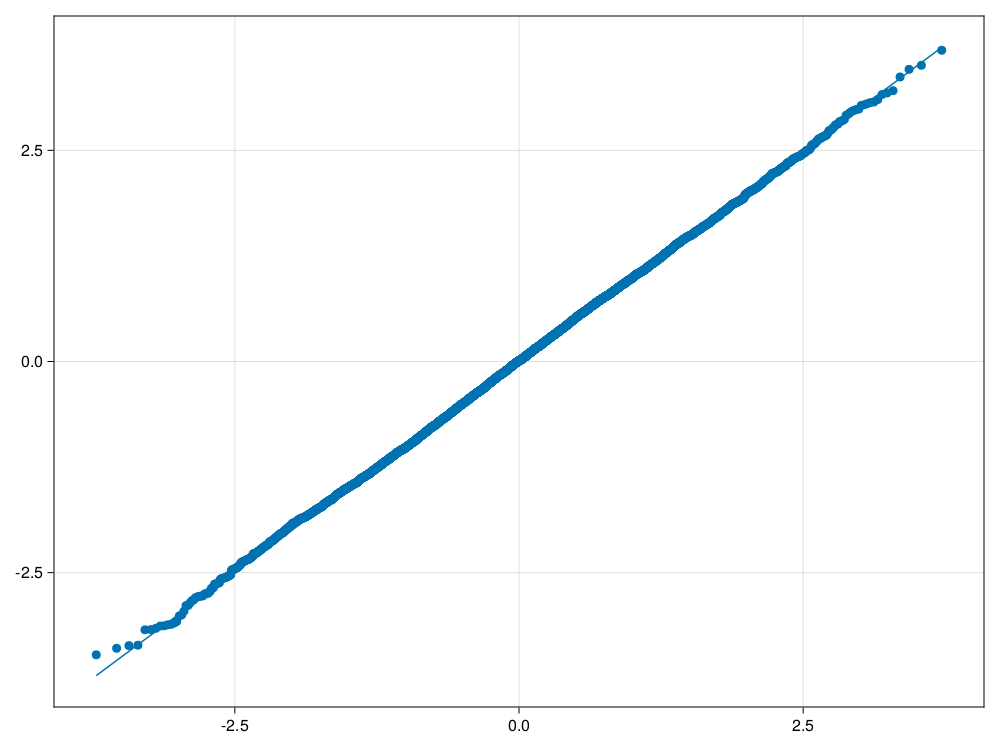
不等样本量,2倍方差的情形:
sim_satt(20, 10, 2.0, 1.0);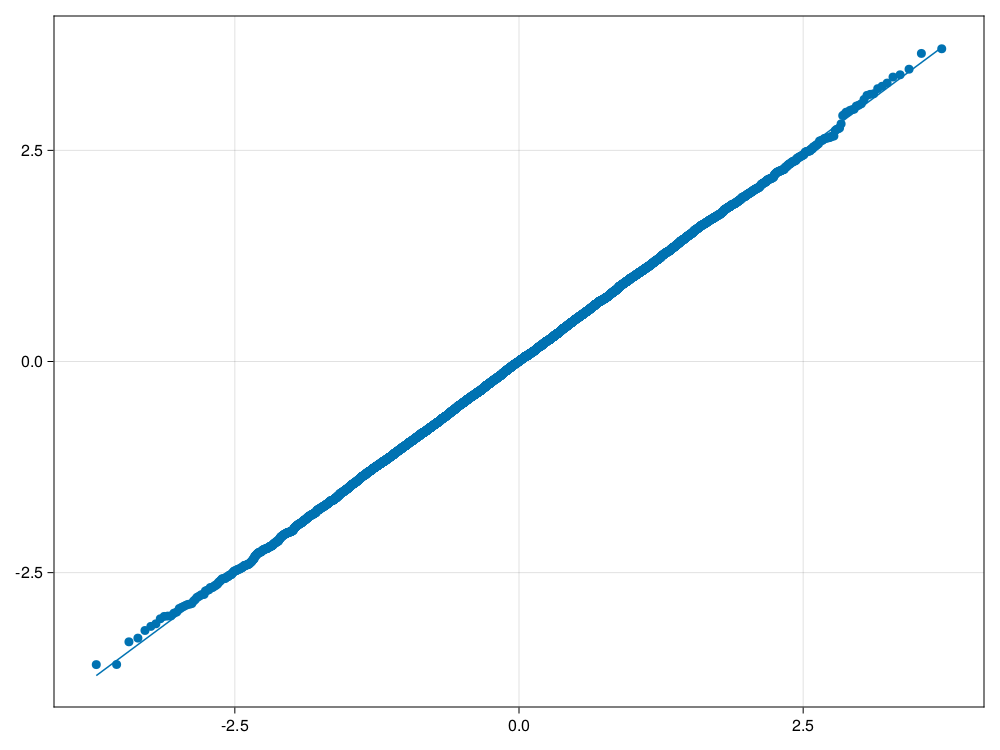
韭菜热线原创版权所有,发布者:风生水起,转载请注明出处:https://www.9crx.com/76000.html




