

36.1 单因素方差分析
单因素方差分析可以看成基础统计中两样本t检验的一个推广, 要比较试验观测值的某个因变量(称为“指标”)按照一个分组变量(称为“因素”)分组后, 各组的因变量均值有无显著差异。
设因素A将所有观测分为m个组, 每组对因变量进行r次观测, 且各次观测相互独立, 模型为
yij=eijμi+eij,i=1,2,…,m, j=1,2,…,r. iid N(0,σ2).
希望研究如下问题:
H0: μ1=μ2=⋯=μm.
如果拒绝H0, 希望找出哪些组的均值两两之间是有显著差异的。
这样的问题称为单因素方差分析问题, “单因素”是指按照一种分组方式分组。 主要模型中假定各个观测独立, 误差eij服从正态分布, 且误差的方差相等。
方差分析在最初是采用平方和分解的方式进行检验, 但是随着模型变得更复杂, 现在处理方差分析问题一般都采用线性模型的一般理论进行处理。
单因素方差分析问题可以推广到不同组的重复观测次数不同的情形。
36.1.1 单因素方差分析示例
例子:考虑如下的方差分析问题。 某工厂要比较三种不同组装工艺(A, B, C)的工作效率, 将15名工人随机分为3个组, 每个组采用一种工艺, 一周后各组的成品数如下:
| A | B | C |
|---|---|---|
| 58 | 58 | 48 |
| 64 | 69 | 57 |
| 55 | 71 | 59 |
| 66 | 64 | 47 |
| 67 | 68 | 49 |
我们需要长表格式,进行转换:
d.manu <- d.manu.w |>
pivot_longer(A:C,
names_to = "grp",
values_to = "y") |>
mutate(grp = factor(grp, levels=c("A", "B", "C"))) |>
arrange(grp)
knitr::kable(d.manu)| grp | y |
|---|---|
| A | 58 |
| A | 64 |
| A | 55 |
| A | 66 |
| A | 67 |
| B | 58 |
| B | 69 |
| B | 71 |
| B | 64 |
| B | 68 |
| C | 48 |
| C | 57 |
| C | 59 |
| C | 47 |
| C | 49 |
用aov()进行方差分析:
aov.manu <- aov(y ~ grp, data=d.manu)
summary(aov.manu)## Df Sum Sq Mean Sq F value Pr(>F)
## grp 2 520 260.00 9.176 0.00382 **
## Residuals 12 340 28.33
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1主效应grp(分组)的F检验的p值为0.004, 若检验水平为0.05则分组效应显著, 各组之间有显著差异。
可以用并列盒形图比较各组的取值, 并检查分布对称性和方差齐性:
ggplot(data = d.manu, mapping = aes(
x = grp, y = y)) +
geom_boxplot()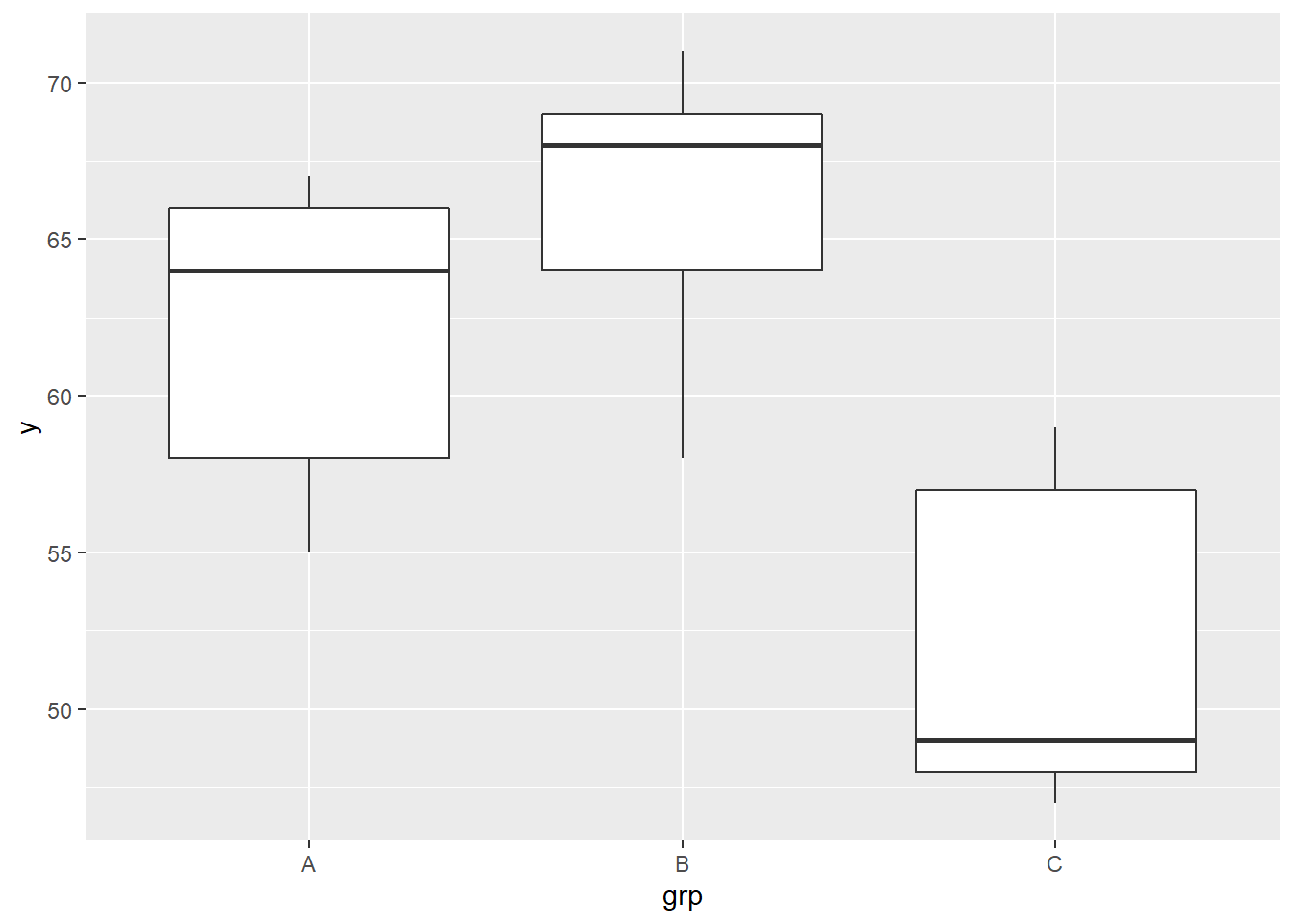

从图形看,C组的工作效率显著低于A组和B组, A、B两组之间差异不明显。
为了检查各组方差是否相等,可以进行Bartlett检验:
bartlett.test(y ~ grp, data = d.manu)##
## Bartlett test of homogeneity of variances
##
## data: y by grp
## Bartlett's K-squared = 0.024476, df = 2, p-value = 0.9878结果表明可以认为各组的方差相等。
除了各组并列盒形图, 也可以做点图并将各组的均值、均值置信区间作图,如:
d2.manu <- d.manu |>
group_by(grp) |>
summarise(ym = mean(y),
ystd = sd(y),
yrad = 1.96 * ystd / sqrt(n()))
ggplot(data=d2.manu) +
geom_errorbar(data = d2.manu,
mapping = aes(
x = grp, ymin = ym - yrad, ymax = ym + yrad )) +
geom_point(mapping = aes(
x = grp, y = ym ), size=3, color="turquoise4") +
geom_jitter(data=d.manu, mapping=aes(
x = grp, y = y ), width=0.1) 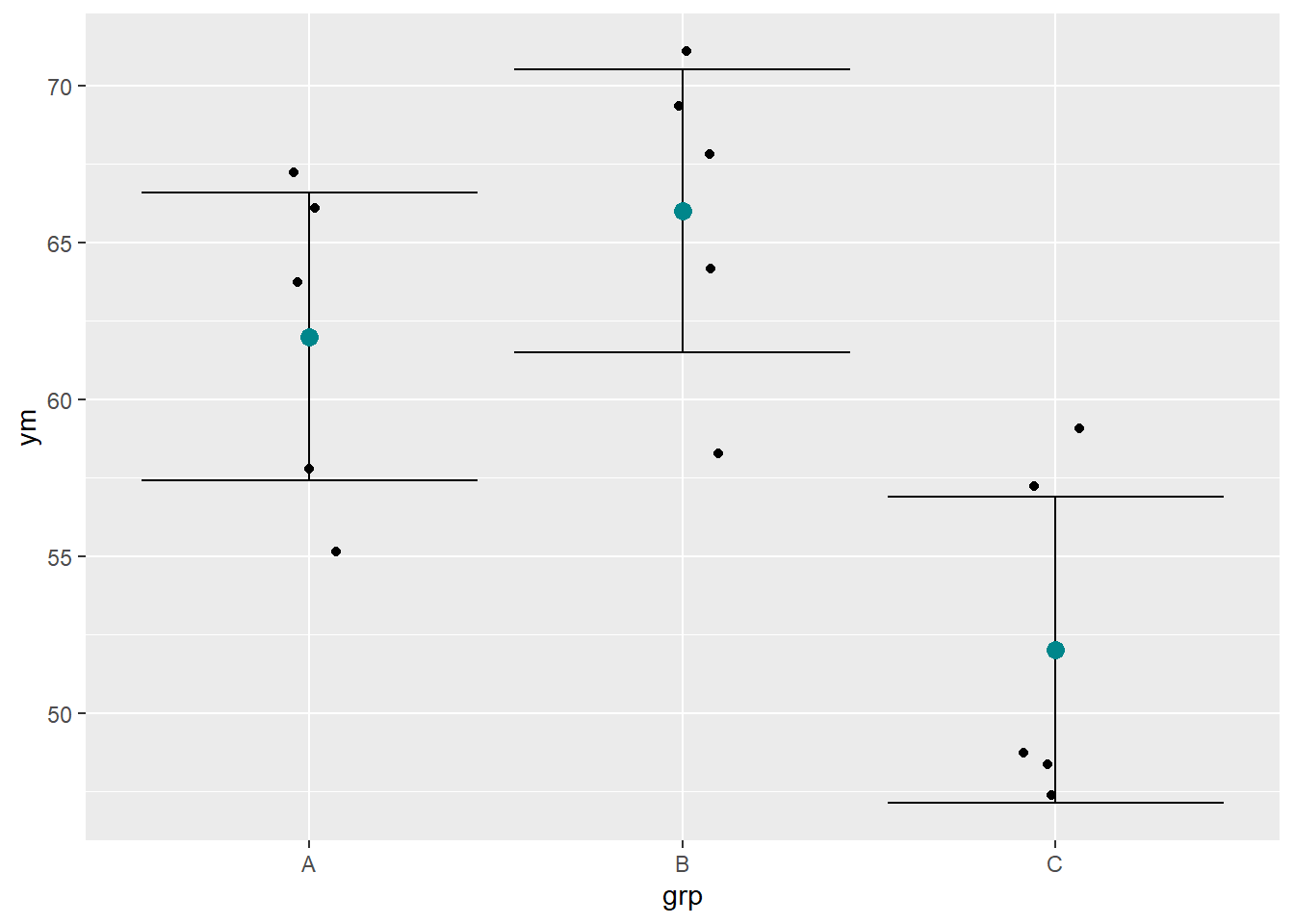
可以看出C的误差条(均值置信区间)低于A和B的误差条, 而A和B的误差条有交集。
36.1.2 功效与样本量计算
对均衡设计的单因素方差分析, 可以用pwr包的pwr.anova.test()函数计算功效和样本量。 设k个组的因变量(指标)值共同的标准差为σwithin, 而各个组的均值的样本标准差为σbetween(但是使用k作为分母而不是k−1作为分母), 定义要检验的效应大小为
f=σbetweenσwithin.
典型的效应大小值为:
- 小:0.1;
- 中: 0.25;
- 大: 0.4。
考虑前面比较三种工艺的例子, 取检验水平0.05, 每组样本量n=5, 要检验中等的效应大小, 功效为:
library(pwr)## Warning: package 'pwr' was built under R version 4.2.2cohen.ES(test = "anov", size = "medium")##
## Conventional effect size from Cohen (1982)
##
## test = anov
## size = medium
## effect.size = 0.25pwr.anova.test(
k = 3, # 分组数
f = 0.25, # 效应大小
sig.level = 0.05,
n = 5 )##
## Balanced one-way analysis of variance power calculation
##
## k = 3
## n = 5
## f = 0.25
## sig.level = 0.05
## power = 0.1095297
##
## NOTE: n is number in each group功效只有11%。 计算达到80%功效所需样本量:
library(pwr)
cohen.ES(test = "anov", size = "medium")##
## Conventional effect size from Cohen (1982)
##
## test = anov
## size = medium
## effect.size = 0.25pwr.anova.test(
k = 3, # 分组数
f = 0.25, # 效应大小
sig.level = 0.05,
power = 0.80 )##
## Balanced one-way analysis of variance power calculation
##
## k = 3
## n = 52.3966
## f = 0.25
## sig.level = 0.05
## power = 0.8
##
## NOTE: n is number in each group需要每组53个试验值。
我们计算一下比较工艺例子中实际数据反映出来的效应大小。
sigs <- d.manu |>
group_by(grp) |>
summarise(
ng = n(),
gmean = mean(y),
gstd = sd(y),
.groups = "drop") |>
summarise(
sig_within = sqrt(sum(gstd^2) / 3),
sig_between = sd(gmean) * sqrt(2/3) )
fv <- sigs |>
mutate(f = sig_between / sig_within) |>
pull()
fv## [1] 1.106133按这个效应计算检验的功效:
pwr.anova.test(
k = 3, # 分组数
f = fv, # 效应大小
sig.level = 0.05,
n = 5 )##
## Balanced one-way analysis of variance power calculation
##
## k = 3
## n = 5
## f = 1.106133
## sig.level = 0.05
## power = 0.9292112
##
## NOTE: n is number in each group功效有93%。 计算80%功效需要的样本量:
pwr.anova.test(
k = 3, # 分组数
f = fv, # 效应大小
sig.level = 0.05,
power = 0.80 )##
## Balanced one-way analysis of variance power calculation
##
## k = 3
## n = 3.82216
## f = 1.106133
## sig.level = 0.05
## power = 0.8
##
## NOTE: n is number in each group每组4各试验即可。
基本R的power.anova.test()也能计算功效, 需要输入组内方差、组间方差, 而且计算组间方差时用的是各组均值方差使用k−1(组数)作为分母的公式。 如:
power.anova.test(
groups = 3,
within.var = sigs$sig_within^2,
between.var = sigs$sig_between^2 * 3 / 2,
sig.level = 0.05,
n = 5 )##
## Balanced one-way analysis of variance power calculation
##
## groups = 3
## n = 5
## between.var = 52
## within.var = 28.33333
## sig.level = 0.05
## power = 0.9292112
##
## NOTE: n is number in each group和pwr.anova.test()输出的结果相同。
36.1.3 多重比较
为了找到各组两两之间是否有显著差异, 可以进行两两的独立两样本t检验, 但这样不能利用共同的模型参数, 进行多次重复检验也会使得总第一类错误概率变得比较高, 发生过度拟合。
进行多个假设检验(如均值比较)的操作称为“多重比较”(multiple comparison, 或multiple testing), 多次检验会使得总第一类错误概率增大。 以两两比较为例, 当比较次数很多时, 即使所有的组之间都没有真实的差异, 很多个两两比较也会找到差异最大的一对, 使得发现的的显著差异有很大可能性不是真实存在的。
为此,可以进行一些调整, 使得报告的检验p值能够控制总第一类错误概率。 multcomp包的glht()函数可以对方差分析结果进行多重比较并控制总错误率, 一种方法是利用Tukey的HSD(Honest Significant Difference)方法, 程序如下:
library(multcomp, quietly=TRUE)
aov.manu <- aov(y ~ grp, data=d.manu)
glht(aov.manu, linfct = mcp(grp = "Tukey")) |>
summary()##
## Simultaneous Tests for General Linear Hypotheses
##
## Multiple Comparisons of Means: Tukey Contrasts
##
##
## Fit: aov(formula = y ~ grp, data = d.manu)
##
## Linear Hypotheses:
## Estimate Std. Error t value Pr(>|t|)
## B - A == 0 4.000 3.367 1.188 0.4820
## C - A == 0 -10.000 3.367 -2.970 0.0292 *
## C - B == 0 -14.000 3.367 -4.159 0.0034 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## (Adjusted p values reported -- single-step method)Tukey HSD检验的结果是, 在0.05水平下, A和B没有显著差异, C与A、B均有显著差异。
36.1.4 方差不相等情形
方差分析模型要求误差项独立同正态分布N(0, σ2), 这意味着各组的因变量方差相等。 实际中不同组的因变量可能有不同的方差。 R提供了oneway.test()函数作为独立两样本t检验的Welch方法的推广, 可以不要求方差相等。 如
oneway.test(y ~ grp, data=d.manu)##
## One-way analysis of means (not assuming equal variances)
##
## data: y and grp
## F = 8.1976, num df = 2.0000, denom df = 7.9914, p-value = 0.01159p值为0.011,在0.05水平下显著, 说明三种生产工艺的时间有显著差异。
为了进行多重比较, 可以进行两两t检验并不使用合并的标准差估计, 使用Holm方法进行p值调整以控制总错误率:
with(d.manu,
pairwise.t.test(y, grp, pool.sd=FALSE,
p.adjust.method="holm"))##
## Pairwise comparisons using t tests with non-pooled SD
##
## data: y and grp
##
## A B
## B 0.258 -
## C 0.039 0.010
##
## P value adjustment method: holm在0.05水平下, A和B没有显著差异,C与A和B都有显著差异。
36.1.5 非参数方差分析
如果各组的因变量(指标)分布严重偏离正态, 则单因素方差分析所依据的F检验会有很大的误差。 这时, 可以使用非参数方法, Kruskal-Wallis检验是独立两样本比较的Wilcoxon秩和检验的推广。 如:
kruskal.test(y ~ grp, data=d.manu)##
## Kruskal-Wallis rank sum test
##
## data: y by grp
## Kruskal-Wallis chi-squared = 7.7677, df = 2, p-value = 0.02057检验p值为0.02,在0.05水平下拒绝零假设, 认为各组之间有显著差异。
36.2 协方差分析
在单因素方差分析问题中, 有可能存在一个连续型的解释变量, 对因变量(指标)有影响, 希望在排除此连续型解释变量影响后对各组进行比较。 这相当于如下的模型:
yij=μi+βxij+eij,
其中xij为已知值的解释变量。
例子 考虑multcomp包的litter数据。 为研究某种药物对出生小数体重的影响, 将若干怀孕小鼠随机分配到4个不同的处理组, 变量dose表示这4个组, 其取值是母鼠服药的剂量。 研究的因变量(指标)是母鼠所生产的幼鼠的平均体重(weight), 要排除协变量gesttime(怀孕时间)的影响。 这个数据的各组试验数不相同,频数统计为:
data(litter, package="multcomp")
litter |>
count(dose) |>
knitr::kable()| dose | n |
|---|---|
| 0 | 20 |
| 5 | 19 |
| 50 | 18 |
| 500 | 17 |
进行协方差分析:
aov.lit1 <- aov(weight ~ gesttime + dose,
data = litter)
summary(aov.lit1)## Df Sum Sq Mean Sq F value Pr(>F)
## gesttime 1 134.3 134.30 8.049 0.00597 **
## dose 3 137.1 45.71 2.739 0.04988 *
## Residuals 69 1151.3 16.69
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1从结果中dose的检验结果看, 排除协变量gesttime影响后, 在0.05水平下, 四个处理组之间有显著差异。
将服药的三个组的均值与不服药(dose=0)的组比较的检验如下:
contr <- rbind("服药与不服药比较" = c(3, -1, -1, -1))
glht(aov.lit1, linfct = mcp(dose = contr)) |>
summary()##
## Simultaneous Tests for General Linear Hypotheses
##
## Multiple Comparisons of Means: User-defined Contrasts
##
##
## Fit: aov(formula = weight ~ gesttime + dose, data = litter)
##
## Linear Hypotheses:
## Estimate Std. Error t value Pr(>|t|)
## 服药与不服药比较 == 0 8.284 3.209 2.581 0.012 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## (Adjusted p values reported -- single-step method)检验的零假设为H0:α1=(α2+α3+α4)/3, 其中αj表示第j个组的均值,α1对应于dose=0的组, 即不服药的组。 检验结果表明在0.05水平下, 服药的和不服药的指标均值有显著差异。
36.3 两因素方差分析
两因素方差分析, 最简单的情形是有两个分组变量(称为因素)A和B, A有s个分类, B有t个分类, 对A和B的每一种搭配(i,j), 重复试验r次得到观测值yijk, 设各次观测值相互独立。 模型为
yijk=μij+eijk, i=1,…,s, j=1,…,t, k=1,…,r,
误差项eijk独立同正态分布N(0,σ2)。
一般将上述模型用另外的参数表示成:
yijk=μ+αi+βj+γij+eijk,
其中αi表示因素A的“主效应”, βj表示因素B的主效应, γij表示因素A和因素B的交互作用效应。 这样模型中的参数是冗余的, 一般会加限制, 比如设α1=0, β1=0, γi1=γ1j=0。
二元方差分析的问题是分别检验两个因素的主效应是否显著(不等于零), 交互作用效应是否存在(不等于零)。
36.3.1 两因素方差分析计算示例
以R的datasets包的ToothGrowth数据为例。 考虑维生素C对豚鼠的成牙质细胞生长的影响, 因变量(指标)len是某牙齿长度测量值, 考虑两种不同的维生素C类型(变量supp,取值为OJ或VC), 以及三种剂量(变量dose, 取值为0.5, 1.0, 2.0)。 需要将这两个因素都转换成R的因子:
data(ToothGrowth, package="datasets")
d.tooth <- ToothGrowth |>
mutate(supp = factor(supp, levels=c("OJ", "VC")),
dose = factor(dose, levels=c(0.5, 1.0, 2.0)))
d.tooth |>
count(supp, dose)## supp dose n
## 1 OJ 0.5 10
## 2 OJ 1 10
## 3 OJ 2 10
## 4 VC 0.5 10
## 5 VC 1 10
## 6 VC 2 10可见这个试验是均衡有重复完全试验设计。
进行二元方差分析:
aov.to1 <- aov(len ~ dose + supp + dose:supp,
data = d.tooth)
summary(aov.to1)## Df Sum Sq Mean Sq F value Pr(>F)
## dose 2 2426.4 1213.2 92.000 < 2e-16 ***
## supp 1 205.4 205.4 15.572 0.000231 ***
## dose:supp 2 108.3 54.2 4.107 0.021860 *
## Residuals 54 712.1 13.2
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1在0.05水平下, 两个主效应和交互作用效应都显著。
36.3.2 交互作用图
R函数interaction.plot()可以绘制表示交互作用的图形。 此图形以因变量为y坐标, 以第一个因素的水平为横坐标作折线图, 但根据第二个因素的不同水平分组作图。 如果不同组的折线图基本平行则没有交互作用效应, 否则提示有交互作用效应。 程序如:
with(d.tooth,
interaction.plot(dose, supp, len) )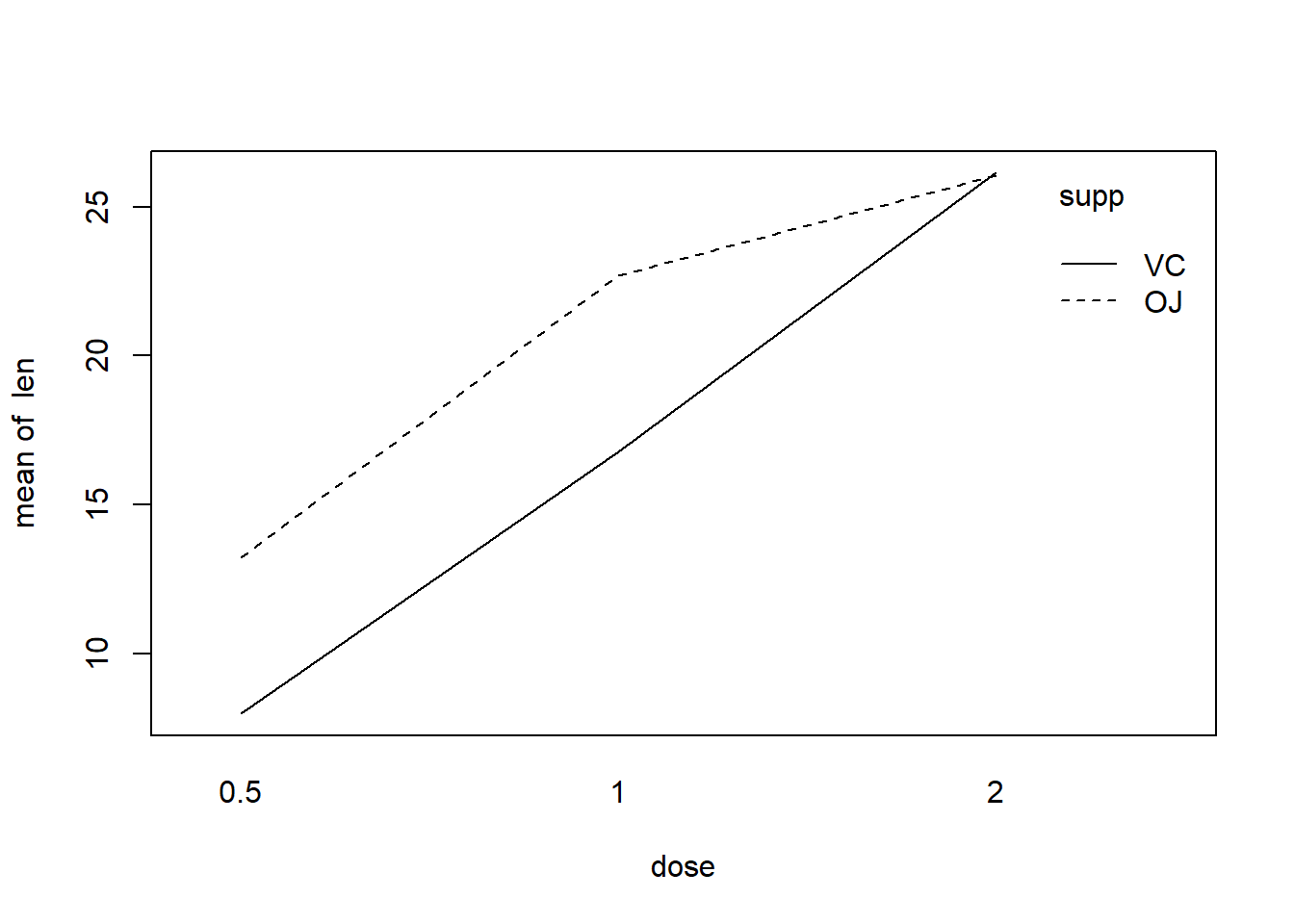
图形结果提示有交互作用效应。
韭菜热线原创版权所有,发布者:风生水起,转载请注明出处:https://www.9crx.com/79761.html




