

50.1 正则表达式应用例子
50.1.1 数据预处理
在原始数据中, 经常需要审核数据是否合法, 已经把一些常见错误输入自动更正。 这都可以用正则表达式实现。
50.1.1.1 除去字符串开头和结尾的空格
函数stringr::str_trim()和base::trimws()可以除去字符串开头与结尾的空格, 也可以仅除去开头或仅除去结尾的空格。
这个任务如果用正则表达式字符串替换函数来编写,可以写成:
### 把字符串向量x的元素去除首尾的空白。
strip <- function(x){
x <- str_replace_all(x, "^[[:space:]]+", "")
x <- str_replace_all(x, "[[:space:]]+$", "")
x
}或者
### 把字符串向量x的元素去除首尾的空白。
strip <- function(x){
x <- gsub("^[[:space:]]+", "", x, perl=TRUE)
x <- gsub("[[:space:]]+$", "", x, perl=TRUE)
x
}这个版本可以除去包括空格在内的所有首尾空白字符。
50.1.1.2 除去字符串向量每个元素中所有空格
compress <- function(x){
str_replace_all(x, " ", "")
}或者
compress <- function(x){
gsub(" ", "", x, fixed=TRUE)
}这可以解决"李明"与"李 明"不相等这样的问题。 类似的程序也可以用来把中文的标点替换成英文的标点。
50.1.1.3 判断日期是否合法
设日期必须为yyyy-mm-dd格式, 年的数字可以是两位、三位、四位, 程序为:
is_yyyymmdd <- function(x){
pyear <- "([0-9]{2}|[1-9][0-9]{2}|[1-2][0-9]{3})"
pmon <- "([1-9]|0[1-9]|1[0-2])"
pday <- "([1-9]|0[1-9]|1[0-9]|2[0-9]|3[01])"
pat <- paste0("\\A", pyear, "-", pmon, "-", pday, "\\Z")
str_detect(x, pat)
}或
is.yyyymmdd <- function(x){
pyear <- "([0-9]{2}|[1-9][0-9]{2}|[1-2][0-9]{3})"
pmon <- "([1-9]|0[1-9]|1[0-2])"
pday <- "([1-9]|0[1-9]|1[0-9]|2[0-9]|3[01])"
pat <- paste("\\A", pyear, "-", pmon, "-", pday, "\\Z", sep="")
grepl(pat, x, perl=TRUE)
}这样的规则还没有排除诸如9月31号、2月30号这样的错误。
例:
x <- c("49-10-1", "1949-10-01", "532-3-15", "2015-6-1",
"2017-02-30", "2017-13-11", "2017-1-32")
is_yyyymmdd(x)## [1] TRUE TRUE TRUE TRUE TRUE FALSE FALSE注意错误的2月30号没有识别出来。
50.1.1.4 把字符型日期变成yyyy-mm-dd格式。
make_date <- function(x){
x |>
str_trim() |>
str_replace_all("[[:space:]]+", "-") |>
str_replace_all("/", "-") |>
str_replace_all("[.]", "-") |>
str_replace_all(
"^([0-9]{2})(-[0-9]{1,2}-[0-9]{1,2})$",
"20\\1\\2") |>
str_replace_all(
"^([0-9]{4})-([0-9])-([0-9]{1,2})$",
"\\1-0\\2-\\3") |>
str_replace_all(
"^([0-9]{4}-[0-9]{2})-([0-9])$",
"\\1-0\\2")
}或者
make.date <- function(x){
x <- trimws(x)
x <- gsub("[[:space:]]+", "-", x)
x <- gsub("/", "-", x)
x <- gsub("[.]", "-", x)
x <- gsub("^([0-9]{2})(-[0-9]{1,2}-[0-9]{1,2})$",
"20\\1\\2", x)
x <- gsub("^([0-9]{4})-([0-9])-([0-9]{1,2})$",
"\\1-0\\2-\\3", x)
x <- gsub("^([0-9]{4}-[0-9]{2})-([0-9])$",
"\\1-0\\2", x)
x
}另一办法是用strsplit()拆分出三个部分, 转换为整数, 再转换回字符型。
测试:
x <- c("49/10/1", "1949.10.01", "532 3 15", "2015/6.1",
"20170230", "2017.13/11", "2017 1 32")
make_date(x)## [1] "2049-10-01" "1949-10-01" "532-3-15" "2015-06-01" "20170230"
## [6] "2017-13-11" "2017-01-32"目前的函数还不能处理没有分隔符的情况, 也不能验证日期的合法性。
50.1.1.5 合并段落为一行
在某些纯文本格式中, 各段之间用空行分隔, 没有用空行分隔的各行看成同一段。 如下的函数把其中的不表示分段的换行删去从而合并这些段落。 函数以一个文件名作为输入, 合并段落后存回原文件。 注意, 这样修改文件的函数在调试时, 应该注意先备份文件, 等程序没有任何错误以后才可以忽略备份。
combine_paragraph <- function(fname, encoding="UTF-8"){
lines <- readr::read_lines(
fname, locale=locale(encoding=encoding))
s <- str_flatten(lines, collapse="\n")
s <- s |>
# 含有空格的空行去掉空格
str_replace_all("^[[:space:]]+\n", "\n") |>
# 有内容行的换行替换成空格
str_replace_all("([^\n]+)\n", "\\1 ") |>
# 段落换行增加一个空行
str_replace_all("([^\n]+)\n", "\\1\n\n") |>
# 多个空行换成一个空行
str_replace_all("\n{3,}", "\n\n")
write_lines(str_split(s, "\n")[[1]],
file=fname)
}下面的版本不使用stringr和readr包:
combine.paragraph <- function(
fname, encoding="UTF-8"){
lines <- readLines(fname, encoding = encoding)
s <- paste(lines, collapse="\n") |>
gsub("^[[:space:]]+\n", "\n", x = _, perl=TRUE) |>
gsub("([^\n]+)\n", "\\1 ", x = _, perl=TRUE) |>
gsub("([^\n]+)\n", "\\1\n\n", x = _, perl=TRUE) |>
gsub("\n{3,}", "\n\n", x = _, perl=TRUE)
lines <- strsplit(s, "\n", fixed=TRUE)[[1]]
writeLines(lines, con=fname)
}50.1.2 不规则Excel文件处理
- 作为字符型数据处理示例, 考察如下的一个Excel表格数据。
假设一个中学把所有课外小组的信息汇总到了Excel表的一个工作簿中。 每个课外小组占一块区域,各小组上下排列, 但不能作为一个数据框读取。 下图为这样的文件的一个简化样例:
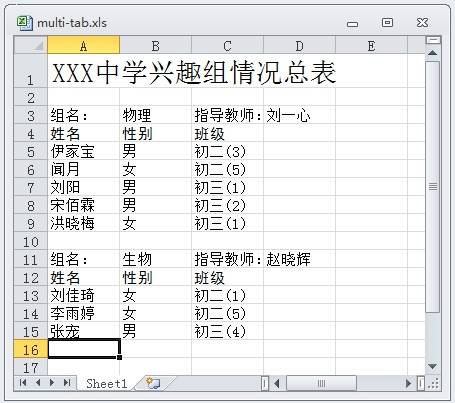

不规则Excel文件样例图形
实际数据可能有很多个小组, 而且数据是随时更新的, 所以复制粘贴另存的方法不太可行, 需要用一个通用的程序处理。 Excel文件(.xls后缀或.xlsx后缀)不是文本型数据。 在Excel中,用“另存为”把文件保存为CSV格式, 内容如下:
XXX中学兴趣组情况总表,,,
,,,
组名:,物理,指导教师:,刘一心
姓名,性别,班级,
伊家宝,男,初二(3),
闻月,女,初二(5),
刘阳,男,初三(1),
宋佰霖,男,初三(2),
洪晓梅,女,初三(1),
,,,
组名:,生物,指导教师:,赵晓辉
姓名,性别,班级,
刘佳琦,女,初二(1),
李雨婷,女,初二(5),
张宠,男,初三(4),生成测试用的数据文件:
demo.multitab.data <- function(){
s <- "
XXX中学兴趣组情况总表,,,
,,,
组名:,物理,指导教师:,刘一心
姓名,性别,班级,
伊家宝,男,初二(3),
闻月,女,初二(5),
刘阳,男,初三(1),
宋佰霖,男,初三(2),
洪晓梅,女,初三(1),
,,,
组名:,生物,指导教师:,赵晓辉
姓名,性别,班级,
刘佳琦,女,初二(1),
李雨婷,女,初二(5),
张宠,男,初三(4),
"
writeLines(s, "data/multitab.csv")
}
demo.multitab.data()读入测试用的数据,转换为一整个数据框:
demo_multitab <- function(){
## 读入所有行
lines <- readr::read_lines("data/multitab.csv")
## 去掉首尾空格
lines <- str_trim(lines)
## 删去所有空行和只有逗号的行
empty <- str_detect(lines, "^[[:space:],]*$")
if(length(empty)>0){
lines <- lines[!empty]
}
## 找到所有包含 “组名:”的行对应的行号
heads <- str_which(lines, "组名:")
## 定位每个表的开始行和结束行(不包括组名和表头所在的行)
start <- heads + 2
end <- c(heads[-1]-1, length(lines))
ngroups <- length(heads)
for(ii in seq(ngroups)){
## 组名和指导教师所在行:
line <- lines[heads[ii]]
v <- str_split(line, ",")[[1]]
## 组名:v[2] 指导教师: v[4]
## 将表格内容各行合并成一个用换行符分隔的长字符串,
## 然后变成可读取的文件
s <- str_flatten(lines[start[ii]:end[ii]], collapse="\n")
da1 <- readr::read_csv(
s, col_names = c("姓名", "性别", "班级", "xxx"),
col_types = cols(
.default=col_character(),
xxx = col_skip()) )
da1 <- bind_cols(tibble("组名"=v[2], "指导教师"=v[4]), da1)
if(ii==1) {
da <- da1
} else {
da <- bind_rows(da, da1)
}
}
da
}
da <- demo_multitab()
knitr::kable(da)| 组名 | 指导教师 | 姓名 | 性别 | 班级 |
|---|---|---|---|---|
| 物理 | 刘一心 | 伊家宝 | 男 | 初二(3) |
| 物理 | 刘一心 | 闻月 | 女 | 初二(5) |
| 物理 | 刘一心 | 刘阳 | 男 | 初三(1) |
| 物理 | 刘一心 | 宋佰霖 | 男 | 初三(2) |
| 物理 | 刘一心 | 洪晓梅 | 女 | 初三(1) |
| 生物 | 赵晓辉 | 刘佳琦 | 女 | 初二(1) |
| 生物 | 赵晓辉 | 李雨婷 | 女 | 初二(5) |
| 生物 | 赵晓辉 | 张宠 | 男 | 初三(4) |
不使用stringr和readr的版本:
demo.multitab <- function(){
## 读入所有行
lines <- readLines("data/multitab.csv")
## 去掉首尾空格
lines <- trimws(lines)
## 删去所有空行和只有逗号的行
## (1) 不用正则表达式做法
#empty <- which(lines == "" | substring(lines, 1, 3)==",,,")
## (2) 用正则表达式做法:
empty <- grep("^[[:space:],]*$", lines)
if(length(empty)>0){
lines <- lines[-empty]
}
## 找到所有包含 “组名:”的行对应的行号
heads <- grep("组名:", lines, fixed=TRUE)
## 定位每个表的开始行和结束行(不包括组名和表头所在的行)
start <- heads + 2
end <- c(heads[-1]-1, length(lines))
ngroups <- length(heads)
for(ii in seq(ngroups)){
## 组名和指导教师所在行:
line <- lines[heads[ii]]
v <- strsplit(line, ",")[[1]]
## 组名:v[2] 指导教师: v[4]
## 将表格内容各行合并成一个用换行符分隔的长字符串,
## 然后变成可读取的文件
s <- paste(lines[start[ii]:end[ii]], collapse="\n")
con <- textConnection(s, "rt")
da1 <- read.csv(
con, header=FALSE,
colClasses=c("character", "character", "character", "NULL"))
close(con)
names(da1) <- c("姓名", "性别", "班级")
da1 <- cbind("组名"=v[2], "指导教师"=v[4], da1)
if(ii==1) {
da <- da1
} else {
da <- rbind(da, da1)
}
}
da
}
da <- demo.multitab()
da在程序中, 用readLines函数读取文本文件各行到一个字符型向量。 用grep可以找到每个小组开头的行(有“组名:”的行)。 然后可以找出每个小组学生名单的开始行号和结束行号。 各小组循环处理,读入后每个小组并入结果数据框中。 用strsplit函数拆分用逗号分开的数据项。 用textConnection函数可以把一个字符串当作文件读取, 这样read.csv函数可以从一个字符串读入数据。
50.1.3 字频统计
正则表达式中的字符类[:alpha:]指的是当前系统中的字母, 所以在中文环境中的中文字也是字母, 但中文标点不算。 下面是《红楼梦》中“秋窗风雨夕”的文本:
秋花惨淡秋草黄,耿耿秋灯秋夜长。
已觉秋窗秋不尽,那堪风雨助凄凉!
助秋风雨来何速!惊破秋窗秋梦绿。
抱得秋情不忍眠,自向秋屏移泪烛。
泪烛摇摇爇短檠,牵愁照恨动离情。
谁家秋院无风入?何处秋窗无雨声?
罗衾不奈秋风力,残漏声催秋雨急。
连宵脉脉复飕飕,灯前似伴离人泣。
寒烟小院转萧条,疏竹虚窗时滴沥。
不知风雨几时休,已教泪洒窗纱湿。希望统计每个字的出现次数, 并显示频数前十的字。 设变量poem_autumnwindow中包含了上述诗词的文本。
首先用str_extract_all()提取每个中文字,组成一个字符型向量:
words_vec <- str_extract_all(poem_autumnwindow, "[[:alpha:]]")[[1]]
head(words_vec)## [1] "秋" "花" "惨" "淡" "秋" "草"用tidyverse方法:
用table()函数计算频数,并按频数排序,输出前10结果:
tibble(words = words_vec) |>
count(words) |>
arrange(desc(n)) |>
slice_head(n=10)## # A tibble: 10 × 2
## words n
## <chr> <int>
## 1 秋 15
## 2 窗 5
## 3 雨 5
## 4 风 5
## 5 不 4
## 6 泪 3
## 7 何 2
## 8 助 2
## 9 声 2
## 10 已 2或者,用table()函数计算频数:
words_freq <- sort(table(words_vec), decreasing=TRUE)
knitr::kable(head(words_freq, 10))| words_vec | Freq |
|---|---|
| 秋 | 15 |
| 窗 | 5 |
| 风 | 5 |
| 雨 | 5 |
| 不 | 4 |
| 泪 | 3 |
| 灯 | 2 |
| 耿 | 2 |
| 何 | 2 |
| 离 | 2 |
50.1.4 数字验证
50.1.4.1 整数
字符串完全为十进制正整数的模式,写成R字符型常量:
"\\A[0-9]+\\Z"这个模式也允许正整数以0开始,如果不允许以零开始,可以写成
"\\A[1-9][0-9]*\\Z"对于一般的整数,字符串完全为十进制整数,但是允许前后有空格, 正负号与数字之间允许有空格,模式可以写成:
"\\A[ ]*[+-]?[ ]*[1-9][0-9]*\\Z"50.1.4.2 十六进制数字
字符串仅有十六进制数字,模式写成R字符型常量为
"\\A[0-9A-Fa-f]+\\Z"在文中匹配带有0x前缀的十六进制数字,模式为
"\\b0x[0-9A-Fa-f]+\\b"50.1.4.3 二进制数字
为了在文中匹配一个以B或b结尾的二进制非负整数,可以用
"\\b[01]+[Bb]\\b"50.1.4.4 有范围的整数
1-12:
"\\b1[012]|[1-9]\\b"1-24:
"\\b2[0-4]|1[0-9]|[1-9]\\b"1-31:
"\\b3[01]|[12][0-9]|[1-9]\\b"1900-2099:
"\\b(?:19|20)[0-9]{2}\\b"这里的分组仅用于在19和20之间选择, 不需要捕获,所以用了(?:的非捕获分组格式。
50.1.4.5 判断字符型向量每个元素是否数值
如下的R函数用了多种数字的正则表达式来判断字符型向量每个元素是否合法数值。
all_numbers <- function(x){
x <- x |>
str_replace_all("\\A[ ]+", "") |>
str_replace_all("[ ]+\\Z", "")
pint <- "\\A[+-]?[0-9]+\\Z" # 整数, 允许有前导零
## 浮点数1, 整数部分必须,小数部分可选,指数部分可选
pf1 <- "\\A[+-]?[0-9]+([.][0-9]*)?([Ee][+-]?[0-9]+)?\\Z"
## 浮点数2, 整数部分省略,小数部分必须,指数部分可选
pf2 <- "\\A[+-]?[.][0-9]+([Ee][+-]?[0-9]+)?\\Z"
pat <- str_c(pint, pf1, pf2, sep="|")
str_detect(x, pat)
}不使用stringr的版本:
all.numbers <- function(x){
x <- gsub("\\A[ ]+", "", x, perl=TRUE)
x <- gsub("[ ]+\\Z", "", x, perl=TRUE)
pint <- "\\A[+-]?[0-9]+\\Z" # 整数, 允许有前导零
## 浮点数1, 整数部分必须,小数部分可选,指数部分可选
pf1 <- "\\A[+-]?[0-9]+([.][0-9]*)?([Ee][+-]?[0-9]+)?\\Z"
## 浮点数2, 整数部分省略,小数部分必须,指数部分可选
pf2 <- "\\A[+-]?[.][0-9]+([Ee][+-]?[0-9]+)?\\Z"
pat <- paste(pint, pf1, pf2, sep="|")
grepl(pat, x, perl=TRUE)
}测试:
all_numbers(c("1", "12", "-12", "12.", "-12.",
"123.45", "-123.45", ".45", "-.45",
"1E3", "-12E-10", "1.1E3", "-1.1E-3",
"1.0.0", "1.0-0.5"))## [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
## [13] TRUE FALSE FALSE50.1.5 文件名中的数字提取
设有如下的一些文件名:
s <- c("10-0.16-1700.0-42.csv", "12-0.22-1799.1.csv")希望提取出每个文件名中用减号分隔开的数字, 如第一个文件名中的10, 0.16, 1700.0, 42, 第二个文件名中的12, 0.22, 1799.1, 数字的个数不需要相同。
先定义数字的模式, 注意长备择模式中长的模式要写在前面, 否则会被短的模式优先匹配:
pat <- "[0-9]+[.][0-9]+|[0-9]+"用stringr::str_match_all()提取其中的匹配数字:
s1 <- str_match_all(s, pat); s1## [[1]]
## [,1]
## [1,] "10"
## [2,] "0.16"
## [3,] "1700.0"
## [4,] "42"
##
## [[2]]
## [,1]
## [1,] "12"
## [2,] "0.22"
## [3,] "1799.1"每个列表元素是一个矩阵, 其中第一列的各行是对模式的多次匹配, 取出这些匹配为一个字符型向量:
s2 <- s |>
str_match_all(pat) |>
map(function(x) x[,1])
s2## [[1]]
## [1] "10" "0.16" "1700.0" "42"
##
## [[2]]
## [1] "12" "0.22" "1799.1"如果需要,也可以将拆分出的字符型的数字结果转换成数值型:
s3 <- s |>
str_match_all(pat) |>
map(function(x) x[,1]) |>
map(parse_double)
s3## [[1]]
## [1] 10.00 0.16 1700.00 42.00
##
## [[2]]
## [1] 12.00 0.22 1799.10这个问题也可以用strsplit()或者stringr::str_split()解决。如:
s <- c("10-0.16-1700.0-42.csv", "12-0.22-1799.1.csv")
s1 <- substring(s, 1, nchar(s)-4) # 去掉".csv"
s2 <- strsplit(s1, "[-]") # 按减号分成几个部分,结果为列表
s3 <- lapply(s2, as.numeric) # 转换为数值型
print(s3)## [[1]]
## [1] 10.00 0.16 1700.00 42.00
##
## [[2]]
## [1] 12.00 0.22 1799.1050.2 网站数据获取
很多网站定期频繁发布数据, 所以传统的手工复制粘贴整理是不现实的。 有些网站提供了下载功能, 有些则仅能显示。
如果网页不是依赖JavaScript来展示的话, 可以读取网页然后通过字符型数据处理方法获得数据。 一般地, 可以用download.file()下载网页文件, 这是特殊的文本文件, 其中有许多标记(tags), 如<html>, </html>, <head>, </head>, <body>, </body>, <p>, </p>, <table>, </table>, <tr>, </tr>, <th>, </th>, <td>, </td>, 等等。 用str_replace_all()或者gsub()去掉不需要的成分, 用str_which()或者grep查找关键行。
许多数据网页有固定模式并且含有数据, R扩展包rvest可以对网页按照其中的网页构成节点路径(xpath)提取数据, 转换为R数据框。
以上海证券交易所的上证综指成份股列表为例。 使用Google Chrome浏览器打开如下的页面:
http://www.sse.com.cn/market/sseindex/indexlist/s/i000001/const_list.shtml
将显示上证综指成份股的名称与编码的列表页面。 利用Chrome浏览器的功能先获取表格所在页面部分的xpath, 办法是鼠标右键单击表格开头部分, 选择“检查”(inspect), 这时会在浏览器右边打开一个html源代码窗口, 当前加亮显示部分是表格开头内容的源代码, 将鼠标单击到上层的<table class="tablestyle">处, 右键单击选择“Copy-Copy XPath”, 得到如下的xpath地址:'//*[@id="content_ab"]/div[1]/table'。
然后, 用rvest的read_html()将HTML页面内容下载为R变量, 用html_nodes()函数提取页面中用xpath指定的成分, 用html_table()函数将HTML表格转换为数据框, 结果是一个数据框列表, 因为仅有一个, 所以取列表第一项即可。 程序如下:
library(rvest)
## 网页地址
urlb <- paste0("http://www.sse.com.cn/",
"market/sseindex/indexlist/s/i000001/const_list.shtml")
## 网页中数据表的xpath
xpath <- '//*[@id="content_ab"]/div[1]/table'
## 读入网页
html_var <- read_html(urlb)
## 提取读入的页面内容中的表格节点
nodes <- html_nodes(html_var, xpath=xpath)
## 从表格节点转换为表格列表
tables <- html_table(nodes)
restab <- tables[[1]]
head(restab)
## X1 X2
## 1 浦发银行\r\n (600000) 白云机场\r\n (600004)
## 2 中国国贸\r\n (600007) 首创股份\r\n (600008)
## X3
## 1 东风汽车\r\n (600006)
## 2 上海机场\r\n (600009)可见每一行有三个股票, 我们将数据中的\r\n和空格去掉, 然后转换成名称与代码分开的格式:
library(tidyverse)
pat1 <- "^(.*?)\\((.*?)\\)"
tab1 <- restab |>
## 将三列纵向合并为一列,结果为字符型向量
reduce(c) %>%
## 去掉空格和换行符,结果为字符型向量
str_replace_all("[[:space:]]", "") %>%
## 提取公司简称和代码到一个矩阵行,结果为字符型矩阵
str_match(pat1)
tab <- tibble(
name = tab1[,2],
code = tab1[,3])
head(tab)
## # A tibble: 6 x 2
## name code
## <chr> <chr>
## 1 浦发银行 600000
## 2 中国国贸 600007
## 3 包钢股份 600010
## 4 华夏银行 600015
## 5 上港集团 600018
## 6 上海电力 600021str(tab)
## Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 1551 obs. of 2 variables:
## $ name: chr "浦发银行" "中国国贸" "包钢股份" "华夏银行" ...
## $ code: chr "600000" "600007" "600010" "600015" ...有些网页是依靠JavaScript来显示数据的, 比如新浪财经的环球股指汇总网页:
http://finance.sina.com.cn/money/globalindex/
在查看其页面源代码时, 仅能看到一堆JavaScrip代码而看不到实际数据, 这样的网页很难用程序提取数据。
关于rvest从html中提取数据的许多函数, 可参见https://r4ds.hadley.nz/webscraping.html。
50.3 中文分词与词云
为了对中文文章进行分析, 需要将文章内容拆分为一个个单词。 R扩展包jiebaR可以进行中文分词。 用w <- worker()创建一个分词器, 用segment(txt, w)对字符串txt中的中文内容进行分词, 得到字符型向量,每个元素是一个词。
也可以调用segment(fname, w), 其中fname是输入文本文件名, 可以自动侦测其中的中文编码, 分词结果会自动保存为文件开头和文件扩展名与fname相同的一个文件, 词之间以空格分隔。
分词后, R可以很容易地进行词频统计, 如table()函数。
例如, 对金庸的《侠客行》分词:
library(jiebaR)## Loading required package: jiebaRDwk <- worker()
txt <- readr::read_file("xkx.txt", locale=locale(encoding="GB18030"))
words <- segment(txt, wk)
tab <- table(words)
tab <- sort(tab, decreasing = TRUE)
## 去掉单个字的词语
tab2 <- tab[stringr::str_length(names(tab)) > 1]
knitr::kable(as.data.frame(head(tab2, 20)))| words | Freq |
|---|---|
| 石破天 | 1800 |
| 什么 | 697 |
| 说道 | 602 |
| 自己 | 570 |
| 雪山 | 451 |
| 白万剑 | 443 |
| 丁当 | 443 |
| 一个 | 421 |
| 帮主 | 387 |
| 武功 | 381 |
| 石清 | 372 |
| 丁不四 | 345 |
| 谢烟客 | 340 |
| 一声 | 321 |
| 不是 | 319 |
| 二人 | 319 |
| 不知 | 308 |
| 咱们 | 304 |
| 史婆婆 | 291 |
| 夫妇 | 284 |
词频可以用“词云”数据可视化方式表现。 在词云图形中, 词频大的词显示为较大的字体。 R扩展包wordcloud2可以输入词频统计表, 输出图形格式的词云显示, 以HTML5格式显示。 函数wordcloud2()可以输入table()的结果, 或者有词和词频构成的两列的数据框。
library(wordcloud2)
wordcloud2(data = head(tab2, 20))
注意,这个库支持图形在HTML结果中显示, 且具有一定交互性, 但不直接支持LaTeX转换的PDF输出, 所以需要进行设置。 可以在Rmd源文件开头运行命令:
is_html <- knitr::opts_knit$get("rmarkdown.pandoc.to") == "html"这可以定义一个变量is_html, 仅在输出格式为HTML时才为TRUE, 然后在包含特殊HTML显示的代码段选项中, 加选项eval = is_html。
ggwordcloud包也提供了词云作图功能, 没有提供交互功能。
韭菜热线原创版权所有,发布者:风生水起,转载请注明出处:https://www.9crx.com/80372.html




