

10.1 方法示例
在统计学的数据分析中,
线性回归分析是最常用的分析工具之一。
线性回归以一元线性回归为例,模型如下
Yt=β0+β1Xt+et, t=1,2,…,T(10.1)
其中自变量{Xt}为常数列,
β0,β1为未知的系数,
{et}为零均值独立同分布随机误差序列,
方差为σ2e,
因变量{Yt}为随机变量列。
参数β0,β1,σ2e可以用最小二乘法估计,
估计量无偏、相合,
系数的估计渐近正态分布。
为了对估计结果做假设检验或者用模型结果做预测,
一般还假设{et}为零均值独立同正态分布序列。
在金融研究中,
{Xt}和{Yt}一般都是时间序列,
而且{et}也是时间序列,有序列相关性。
这时,
最小二乘估计不是最有效的估计甚至于可能不相合,
基于{et}独立同正态分布所做的标准误差估计、假设检验和预测都不再成立。
(Cochrane and Orcutt 1949)的文章指出,
当{et}彼此正相关时,
回归系数的标准误差估计偏低,
使得相应的t和F检验统计量的绝对值偏大。
(James Durbin and Watson 1950)和(James Durbin and Watson 1951)给出了一阶自相关的检验。
Durbin-Watson序列自相关检验使用检验统计量
DW=∑Tt=2(ê t−ê t−1)2∑Tt=1ê 2t≈2(1−ρ̂ 1)
其中ê t是回归残差,
当无序列相关时DW统计量接近于2。
此统计量只用到一阶自相关。
当{et}是平稳可逆ARMA序列时,
可以将线性回归模型与平稳可逆ARMA序列同时估计,
可以得到需要标准误差估计、假设检验和预测。
R的arima()函数提供了一个xreg=用来引入回归自变量。
如果不关心{et}的具体模型,
而只关心对回归系数的SE的正确估计以及假设检验的正确性,
可以仅假设{et}的协方差结构而不考虑{et}的建模。
这样的方法在混合线性模型中使用。
下面举例说明。
考虑美国国债一年期与三年期利率,
数据为周数据,从1962-01-05到2009-10-04,共2467个观测。
记一年期利率序列为{x1t},
三年期利率序列为{x3t}。
先读入数据:
da <- read_table(
"w-gs1yr.txt",
col_types=cols(.default=col_double()))
x1 <- da[["rate"]]
y1 <- xts(x1, make_date(da[["year"]], da[["mon"]], da[["day"]]))
da <- read_table2(
"w-gs3yr.txt",
col_types=cols(.default=col_double()))## Warning: `read_table2()` was deprecated in readr 2.0.0.
## Please use `read_table()` instead.x3 <- da[["rate"]]
y3 <- xts(x3, make_date(da[["year"]], da[["mon"]], da[["day"]]))
rm(da)
xts.gs <- cbind(gs1yr=y1, gs3yr=y3)
rm(y1, y3)两个利率序列的时间序列图:
plot(xts.gs, type="l",
main="US Federal Bonds 1 Year and 3 Years",
major.ticks="years", minor.ticks=NULL,
grid.ticks.on="auto",
col=c("blue", "red"))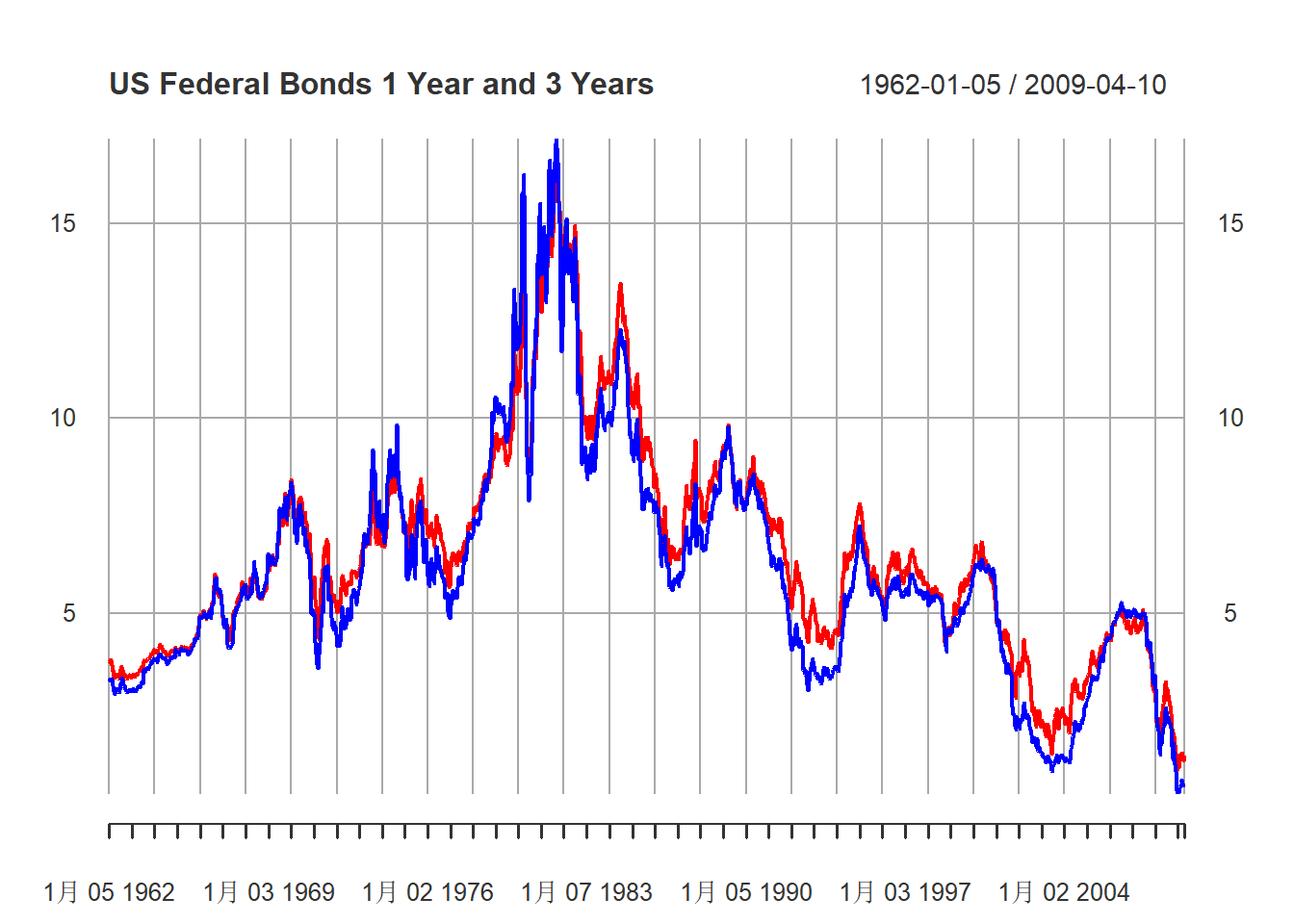

图10.1: 美国一年期与三年期国债利率周数据
蓝色为一年期,红色为三年期。
最后三年的图形:
plot(last(xts.gs, "3 years"), type="l",
main="US Federal Bonds 1 Year and 3 Years",
major.ticks="years", minor.ticks=NULL,
grid.ticks.on="auto",
col=c("blue", "red"))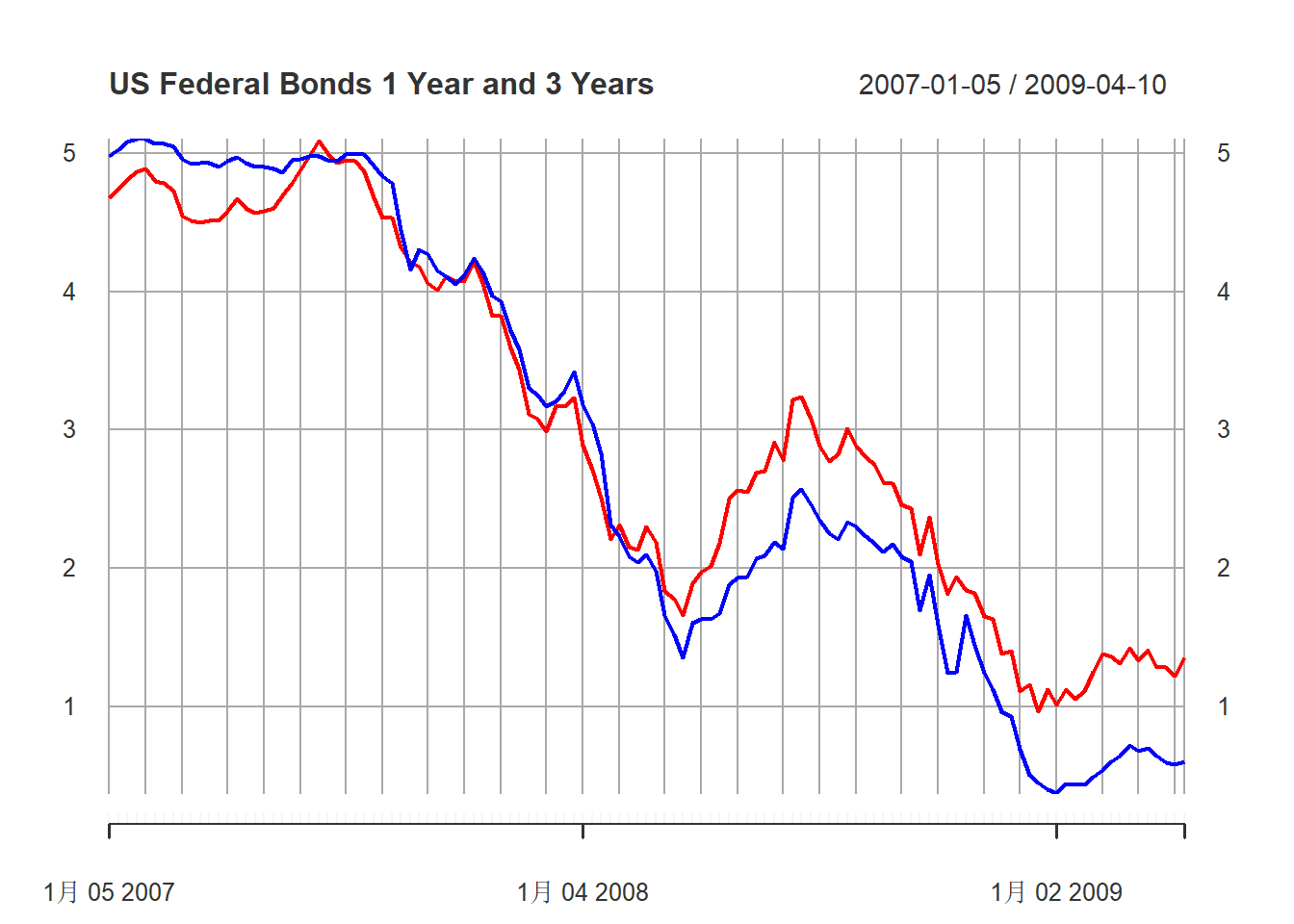
图10.2: 美国一年期与三年期国债利率周数据
这些数据作为时间序列呈现出不平稳的表现。
对一年期利率作ACF估计:
forecast::Acf(x1, main="")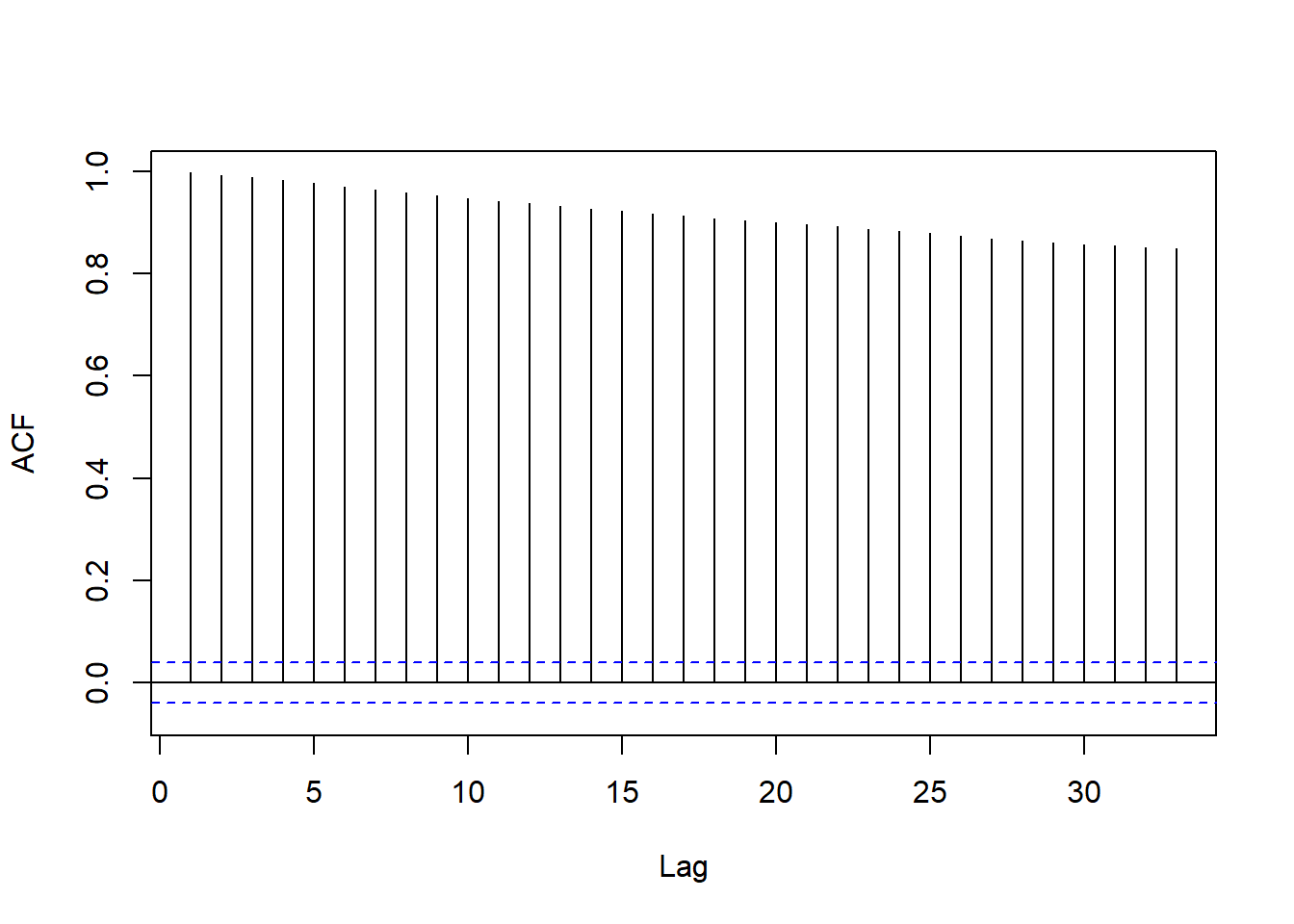
图10.3: 一年期利率ACF
这样的ACF是有缓慢变化趋势的典型表现。
对一年期利率序列作单位根检验:
ar(diff(x1), method="mle")##
## Call:
## ar(x = diff(x1), method = "mle")
##
## Coefficients:
## 1 2 3 4 5 6 7 8
## 0.3213 0.0372 0.0333 0.0577 -0.0093 -0.0008 -0.0813 0.0312
## 9
## -0.0469
##
## Order selected 9 sigma^2 estimated as 0.03103fUnitRoots::adfTest(x1, lags=9, type="ct")##
## Title:
## Augmented Dickey-Fuller Test
##
## Test Results:
## PARAMETER:
## Lag Order: 9
## STATISTIC:
## Dickey-Fuller: -2.3813
## P VALUE:
## 0.4169
##
## Description:
## Wed Mar 23 07:33:20 2022 by user: Lenovo单位根检验结果不显著,
说明一年期利率序列是单位根过程。
如果以x3t为因变量,
以x1t为自变量作线性回归:
x3t=β0+β1x1t+et
就会遇到{et}序列相关的问题,
甚至于{et}可能有单位根造成方差线性增长,
有异方差问题。
先用散点图考察两个序列的关系:
plot(x1, x3, type="p", pch=16, cex=0.5,
xlab="1 Year", ylab="3 Years",
main="US Federal Bonds 3 Years Rate Vs. 1 Year Rate")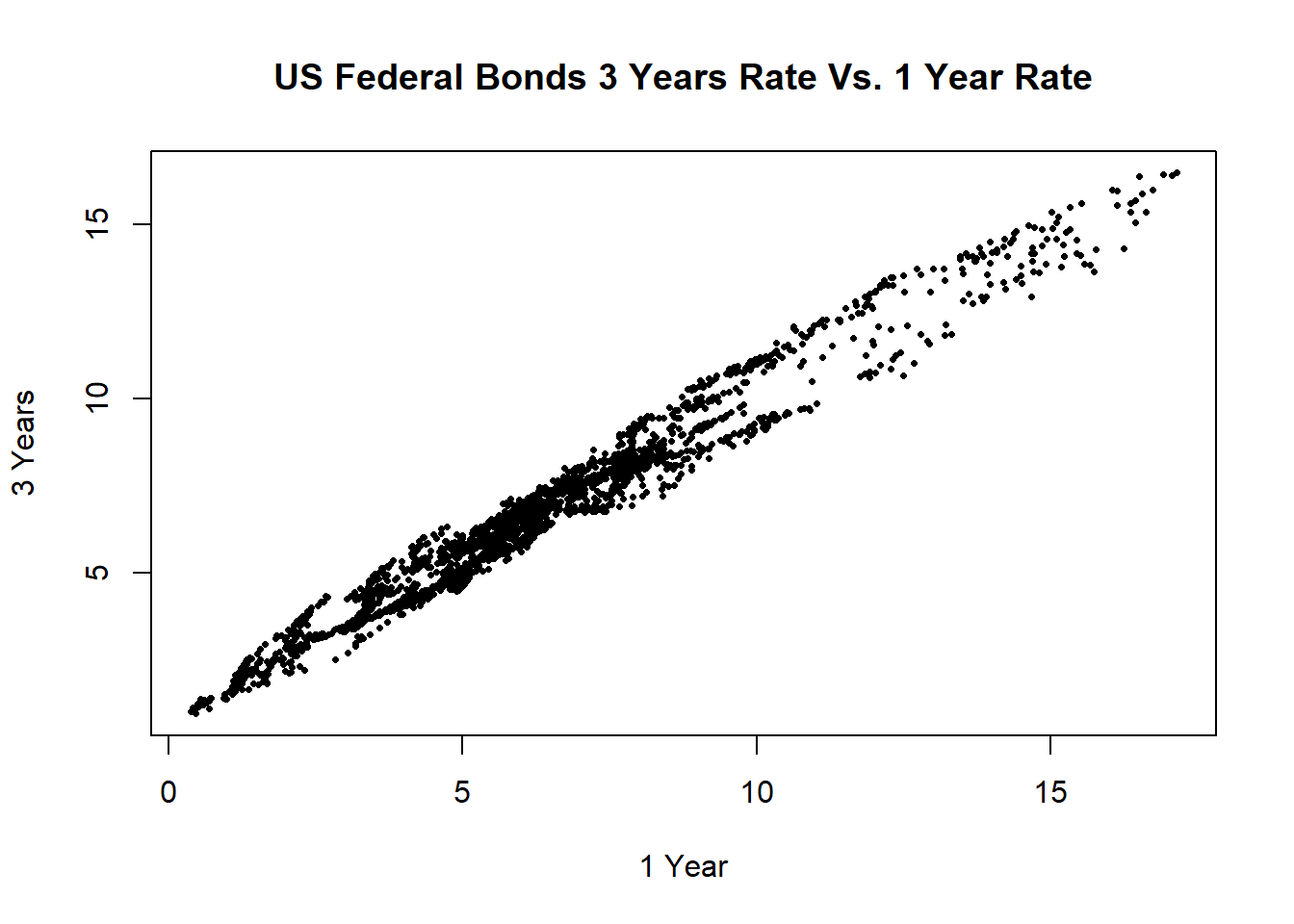
图10.4: 美国一年期与三年期国债利率周数据散点图
散点图显示同期的一年期利率和三年期利率高度相关。
试拟合线性回归模型:
lm1 <- lm(x3 ~ x1); summary(lm1)##
## Call:
## lm(formula = x3 ~ x1)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.82319 -0.37691 -0.01462 0.38661 1.35679
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.83214 0.02417 34.43 <2e-16 ***
## x1 0.92955 0.00357 260.40 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.5228 on 2465 degrees of freedom
## Multiple R-squared: 0.9649, Adjusted R-squared: 0.9649
## F-statistic: 6.781e+04 on 1 and 2465 DF, p-value: < 2.2e-16注意:不懂统计的人会盲目相信统计软件给出的如此专业的输出结果。
R2=0.9649是一个十分令人欣喜的回归结果。
但是,
只有学习了相应的统计模型的有关知识并且知道模型的局限,
才能正确地运用统计模型。
上面的系数估计、σ2e估计、SE估计、t检验等等都是基于随机误差项独立同分布假定的。
如果假定不成立,σ2e的估计会严重低估,SE估计不相合,检验不准确。
在经济和金融数据分析中一定要对回归模型结果进行诊断分析,
最常用的是残差分析,
其中一项是残差序列相关性的检验。
传统的残差序列相关性检验有Durbin-Watson检验,
在时间序列分析软件的支持下,
我们可以做ACF图,
进行Ljung-Box白噪声检验。
forecast::Acf(lm1$residuals, main="")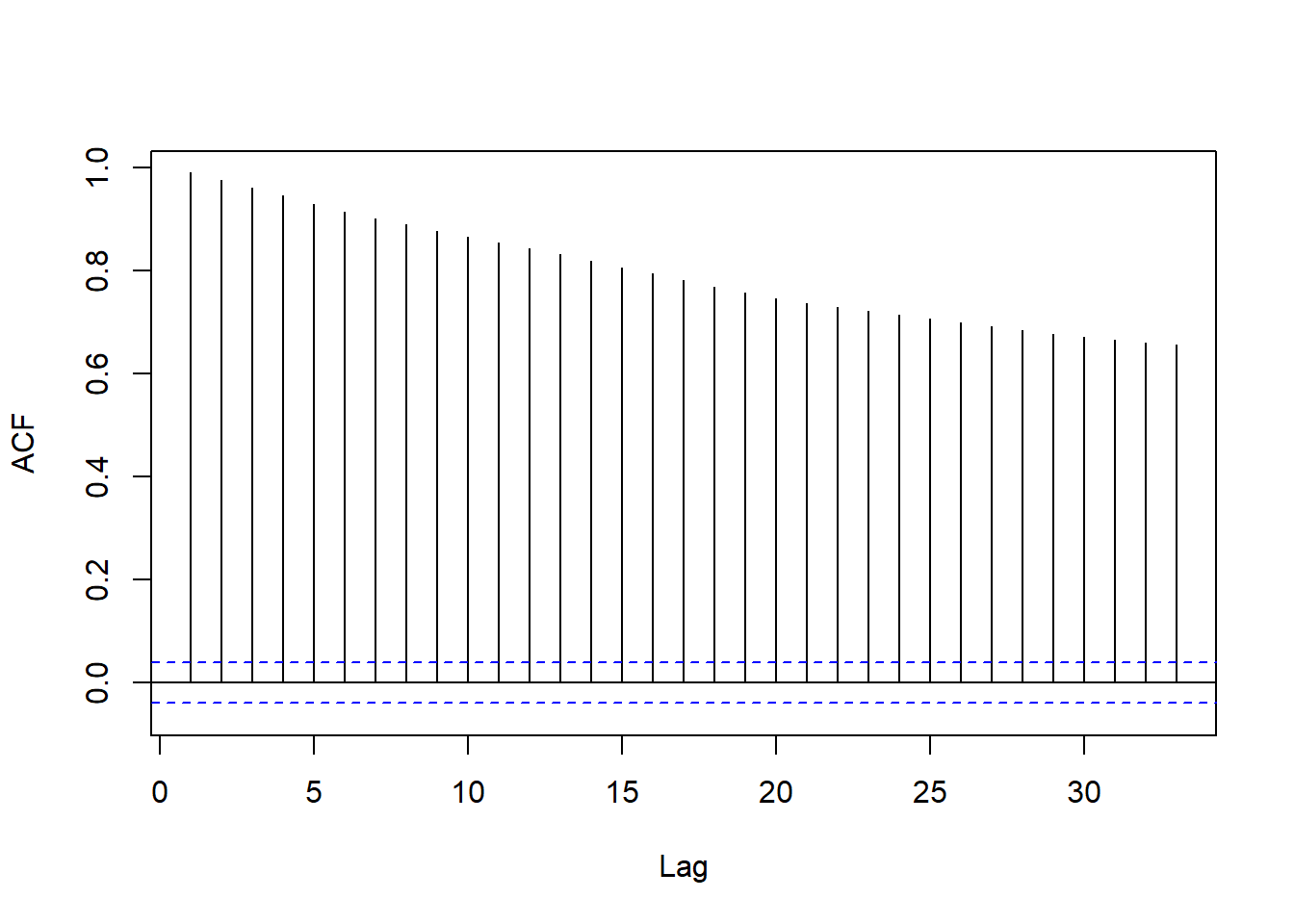
图10.5: 三年期对一年期利率回归残差的ACF
残差的ACF表明结果仍有很强的自相关,甚至于可能有单位根。
白噪声检验:
Box.test(lm1$residuals, lag=9)##
## Box-Pierce test
##
## data: lm1$residuals
## X-squared = 19303, df = 9, p-value < 2.2e-16结果显著,拒绝残差序列为白噪声的零假设。
对残差序列作单位根检验:
ar(diff(lm1$residuals), method="mle")##
## Call:
## ar(x = diff(lm1$residuals), method = "mle")
##
## Coefficients:
## 1 2 3 4 5 6 7 8
## 0.2072 -0.0030 -0.0100 0.0911 -0.0641 -0.0642 -0.0475 0.0193
## 9 10 11 12
## 0.0163 -0.0509 -0.0174 0.0706
##
## Order selected 12 sigma^2 estimated as 0.005036fUnitRoots::adfTest(lm1$residuals, lags=12, type="nc")## Warning in fUnitRoots::adfTest(lm1$residuals, lags = 12, type = "nc"): p-value
## smaller than printed p-value##
## Title:
## Augmented Dickey-Fuller Test
##
## Test Results:
## PARAMETER:
## Lag Order: 12
## STATISTIC:
## Dickey-Fuller: -4.1201
## P VALUE:
## 0.01
##
## Description:
## Wed Mar 23 07:33:21 2022 by user: Lenovo结果显著,拒绝残差有单位根的零假设。
尽管如此,鉴于残差的高度自相关,
还是不能轻易使用线性回归。
如果回归模型yt=β0+β1xt+et
中yt和xt都是单位根过程而et是线性时间序列,
则称{yt}与{xt}序列存在协整关系(cointegrated)。
在目前的数据中,
因为利率序列有单位根,
残差虽然没有单位根但是ACF衰减很慢,
不符合协整的要求。
为此,
对利率序列作一阶差分,考虑利率差分之间的关系。
分别记差分后的两个序列为{c1t}和{c3t}。
c1 <- diff(x1)
c3 <- diff(x3)一年期利率的差分序列的ACF:
forecast::Acf(c1, main="")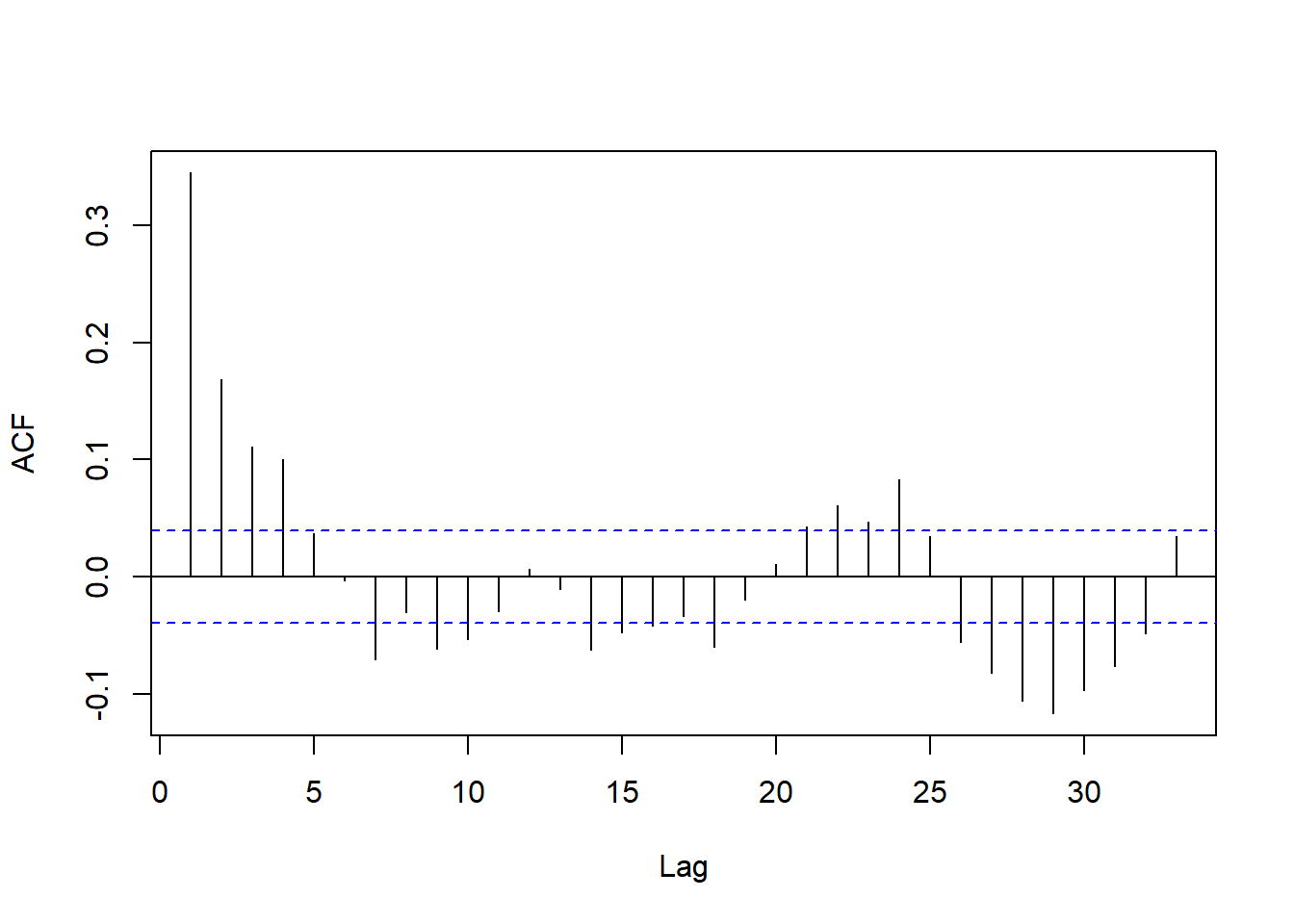
图10.6: 一年期利率差分序列的ACF
这个ACF的表现已经不是单位根过程,
符合线性时间序列的ACF的表现。
一年期与三年期的两个差分序列的散点图:
plot(c1, c3, type="p", pch=16, cex=0.5,
xlab="1 Year", ylab="3 Years",
main="US Federal Bonds 3 Years Rate Diff1 Vs. 1 Year Rate Diff1")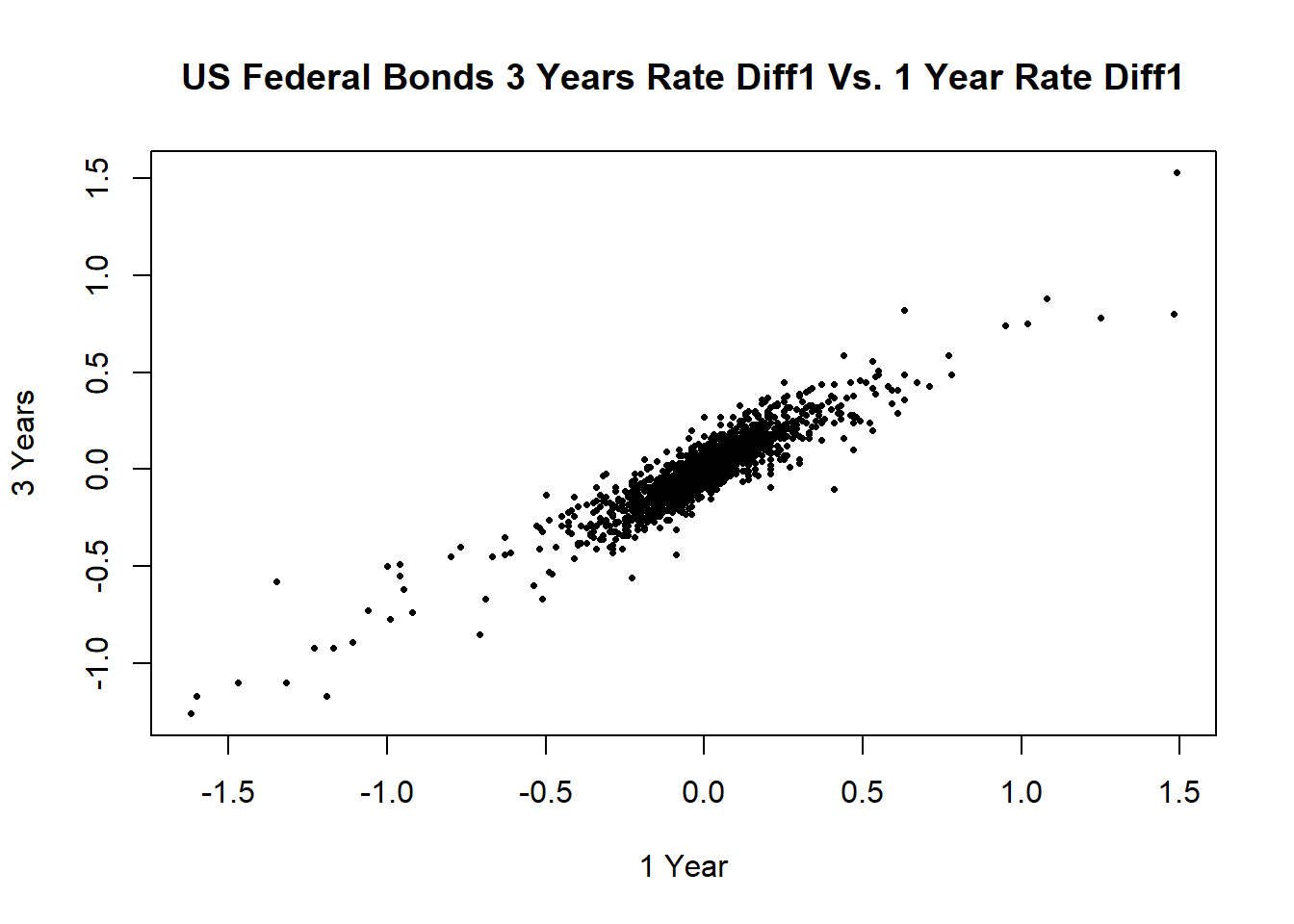
图10.7: 一年期利率差分序列的ACF
两者仍有强烈的线性相关。作线性回归:
lm2 <- lm(c3 ~ c1); summary(lm2)##
## Call:
## lm(formula = c3 ~ c1)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.42459 -0.03578 -0.00117 0.03467 0.48921
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.0001051 0.0013890 -0.076 0.94
## c1 0.7919323 0.0073391 107.906 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.06897 on 2464 degrees of freedom
## Multiple R-squared: 0.8253, Adjusted R-squared: 0.8253
## F-statistic: 1.164e+04 on 1 and 2464 DF, p-value: < 2.2e-16结果表面上也很好,
但仍需作序列相关性诊断分析。
残差的ACF:
forecast::Acf(lm2$residuals, main="")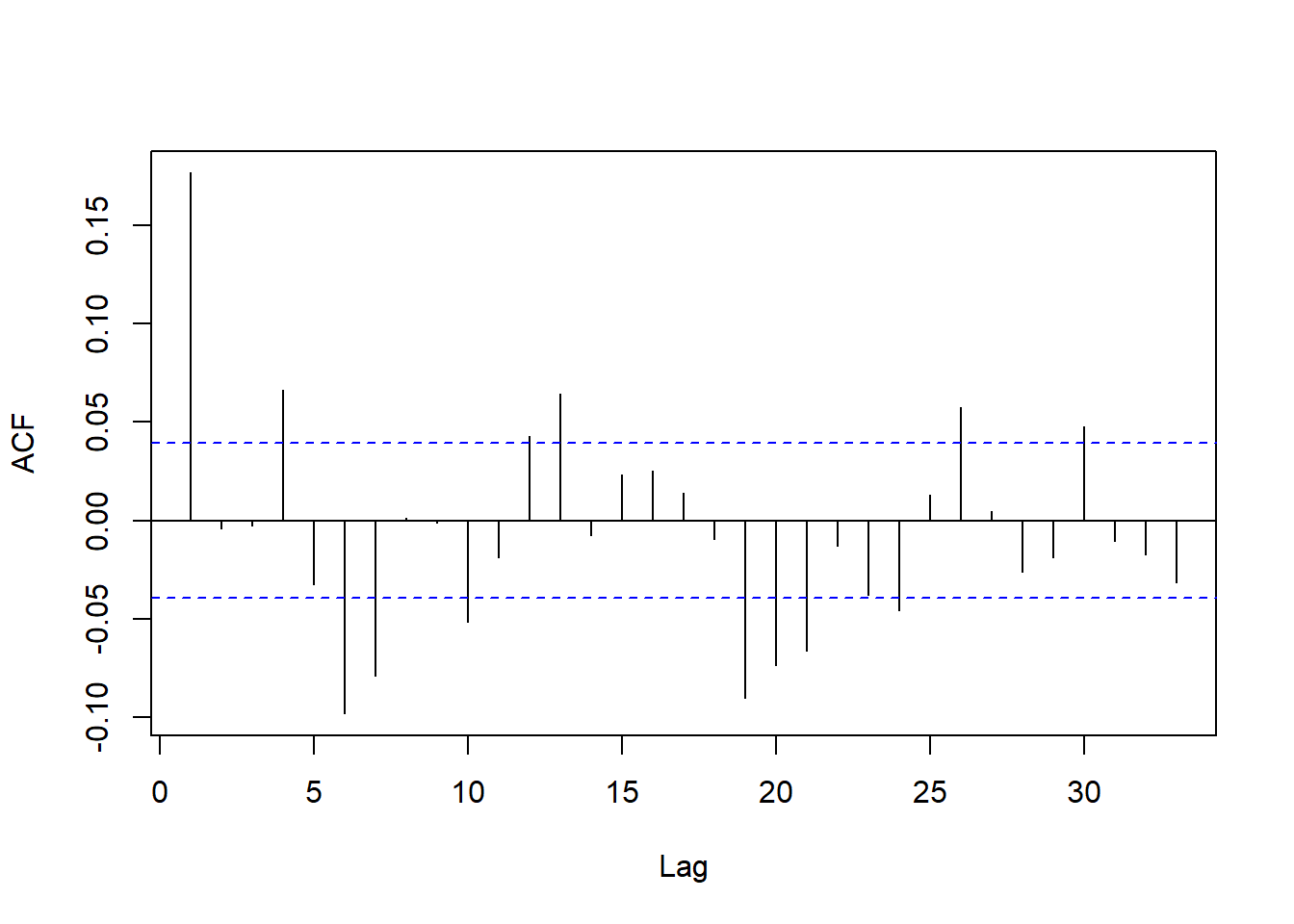
图10.8: 差分之间回归残差的ACF
这个ACF表现得与线性时间序列ACF相像,
但是滞后1处仍显著不等于零。
作Ljung-Box白噪声检验:
Box.test(lm2$residuals, lag=9)##
## Box-Pierce test
##
## data: lm2$residuals
## X-squared = 129.57, df = 9, p-value < 2.2e-16结果显著,
说明回归模型中的误差项存在序列自相关,
这样,
上面的两个差分序列的回归结果中仅两个回归系数估计是可信的,
误差方差估计、SE估计、假设检验结果均不可用。
因为上面的回归残差的ACF主要在滞后1显著,其它位置虽然也有显著但值不大,
所以考虑et用MA(1),
回归变成
c3t=β1c1t+et,et=εt+θεt−1
其中{εt}为零均值独立同分布白噪声列。
这里没有常数项是因为两个序列都是差分过的,
如果原来的关系有常数项会在差分过程中被消去。
R的arima()函数提供了将外生回归自变量与AMRA模型一同估计的功能。
用xreg=指定外生回归自变量。
mres <- arima(c3, xreg=c1, order=c(0,0,1), include.mean=FALSE)
mres##
## Call:
## arima(x = c3, order = c(0, 0, 1), xreg = c1, include.mean = FALSE)
##
## Coefficients:
## ma1 c1
## 0.1823 0.7936
## s.e. 0.0196 0.0075
##
## sigma^2 estimated as 0.0046: log likelihood = 3136.62, aic = -6267.23这拟合了如下的带有MA(1)误差的无截距项的一元线性回归模型:
c3t=0.7936c1t+et,et=εt+0.1823εt−1, σ̂ 2ε=0.0046
从β̂ 1和θ̂ 的SE估计来看,
两个系数都是显著不为零的。
小结:带时间序列误差的线性回归模型建模步骤
- 拟合一个线性回归模型,并检验残差的序列相关性
- 如果残差序列是单位根非平稳的,则对因变量和自变量都做一阶差分。
然后对差分后的序列再进行第一步。
如果残差序列是平稳的,
则对残差序列识别一个ARMA模型,
并相应地修改线性回归模型。 - 用最大似然估计法对回归模型与ARMA模型进行联合估计,
并对模型进行检验,
看是否需要改进。
主要可以使用Ljung-Box对残差进行白噪声检验。
10.2 arima函数说明
R中的arima()函数支持ARIMA建模,
支持差分和季节模型,
支持以平稳ARMA序列为误差项的回归建模。
参数include.mean=TRUE仅支持没有差分和季节差分的模型,
这时的ARIMA(p,0,q)(P,0,Q)s模型为:
=(1−ϕ1B−ϕ2B2−⋯−ϕpBp)(1−Φ1Bs−Φ2B2s−⋯−ΦPBPs)(Yt−μ)(1+θ1B+θ2B2+⋯+θqBq)(1+Θ1Bs+Θ2B2s+⋯+ΘPBQs)εt,(10.2)
其中s是周期,μ是{Yt}的期望值。
对于ARIMA(p,d,q)(P,D,Q)s模型{Zt},
则令Yt=(1−B)d(1−Bs)D,
Yt服从(10.2)中μ=0时的模型。
如果ARIMA(p,0,q)(P,0,Q)s模型{Zt}有xreg选项,
设输入的自变量或自变量矩阵(每列是一个自变量)的各个观测xt(标量或行向量),
则模型为
Zt=β0+βxt+Yt,(10.3)
其中{Yt}服从(10.2)中μ=0时的模型。
我们用模拟数据来进行这种情形的验证计算。
sima <- function(){
# 样本量
n <- 500
# 自变量
x <- runif(n, 10, 20)
# 作为误差项的ARMA
y <- arima.sim(model=list(ar=0.3, ma=0.7), n=n)
# 回归参数
a <- 100; b <- 2
# 输出的因变量
z <- a + b*x + y
cat("Z的样本均值 =", mean(z), "\n")
# 估计:
res <- arima(z, order=c(1,0,1), xreg=x)
print(res)
}
set.seed(101)
sima()## Z的样本均值 = 129.9459
##
## Call:
## arima(x = z, order = c(1, 0, 1), xreg = x)
##
## Coefficients:
## ar1 ma1 intercept x
## 0.2927 0.7127 99.8338 1.9994
## s.e. 0.0511 0.0375 0.1643 0.0086
##
## sigma^2 estimated as 0.8742: log likelihood = -676.45, aic = 1362.89上述结果中intercept是(10.3)中回归截距项β0的估计而不再是Zt的均值μ的估计。
如果包含回归自变量{Xt}时因变量{Zt}有单位根,
这时最好先将两者都预先差分后再建模,
ARIMA不会自动建立关于差分之后的自变量和因变量的回归模型,
应使用模型
ΔZt=a+bΔXt+Yt,(10.4)
其中{Yt}服从平稳的ARMA模型,
ΔZt和ΔXt预先计算。
如果真实模型是(10.4)但在arima()函数中直接输入Zt和Xt且指定差分阶1,
则模型估计结果将受到单位根影响给出错误结果。
模拟验证如下:
simb <- function(){
# 样本量
n <- 500
# 自变量
dx <- runif(n, 10, 20)
x <- cumsum(dx)
# 作为误差项的ARMA
dy <- arima.sim(model=list(
ar=0.3, ma=0.7), n=n)
# 回归参数
a <- 100; b <- 2
# 输出的因变量
dz <- a + b*dx + dy
z <- cumsum(dz)
# 估计,不预先差分:
res <- arima(z, order=c(1,1,1), xreg=x)
cat("不预先差分的错误结果:\n")
print(res)
#估计,预先差分:
res2 <- arima(dz, order=c(1,0,1), xreg=dx)
cat("\n\n预先差分的正确结果:\n")
print(res2)
}
set.seed(101)
simb()## 不预先差分的错误结果:
##
## Call:
## arima(x = z, order = c(1, 1, 1), xreg = x)
##
## Coefficients:
## ar1 ma1 x
## 0.9999 0.4827 1.9977
## s.e. 0.0002 0.0605 0.0094
##
## sigma^2 estimated as 1.29: log likelihood = -776.24, aic = 1560.49
##
##
## 预先差分的正确结果:
##
## Call:
## arima(x = dz, order = c(1, 0, 1), xreg = dx)
##
## Coefficients:
## ar1 ma1 intercept dx
## 0.2927 0.7127 99.8338 1.9994
## s.e. 0.0511 0.0375 0.1643 0.0086
##
## sigma^2 estimated as 0.8742: log likelihood = -676.45, aic = 1362.89预先差分的缺点是predict()函数给出的预测也是关于ΔZt的,
需要人为使用Zt+1=Zt+ΔZt进行转换。
如果Zt和Xt包含单位根,
而误差项Yt为平稳的ARMA,
这时
Zt=β0+βXt+Yt,
称Zt和Xt有协整关系,
arima函数能正确给出估计,
模拟验证如下:
simc <- function(){
# 样本量
n <- 500
# 自变量
dx <- runif(n, 10, 20)
x <- cumsum(dx)
# 作为误差项的ARMA
dy <- arima.sim(model=list(
ar=0.3, ma=0.7), n=n)
# 回归参数
a <- 100; b <- 2
# 输出的因变量
z <- a + b*x + dy
# 估计,不预先差分:
res <- arima(z, order=c(1,0,1), xreg=x)
cat("协整情况下的估计:\n")
print(res)
}
set.seed(101)
simc()## 协整情况下的估计:
##
## Call:
## arima(x = z, order = c(1, 0, 1), xreg = x)
##
## Coefficients:
## ar1 ma1 intercept x
## 0.2926 0.7128 99.7804 2e+00
## s.e. 0.0511 0.0374 0.2026 1e-04
##
## sigma^2 estimated as 0.8741: log likelihood = -676.42, aic = 1362.83如果Xt与Zt都有单位根且误差项也有单位根,
这样的模型没有合理的定义,
应使用预先差分的做法。
总之,
在arima()函数中用xreg=引入回归自变量(外生变量)时,
不要指定差分或者季节差分。
韭菜热线原创版权所有,发布者:风生水起,转载请注明出处:https://www.9crx.com/74121.html




