

本章内容来自自(Tsay 2013)§4.13和§4.14内容。
前面的波动率方程中σ2t=Var(at|Ft−1)都是被σt−1,…和
at−1,…完全决定。
另一种方法是假定σ2t的模型本身有新息,
这样的模型称为随机波动率(Stochastic Volatility, SV)模型。
模型写成
at=σtεt,(1−α1B−⋯−αmBm)lnσ2t=α0+vt.
其中σ2t取对数是为了取消系数必须为非负的限制。
{εt}独立同标准正态分布,
{vt}独立同N(0,σ2v)分布,
{εt}和{vt}相互独立。
αi为常数,
特征多项式1−α1z−⋯−αmzm根都在单位圆外。
记ξt=lnσ2t,
则{ξt}是一个严平稳AR(m)序列。
加入vt新息后,
收益率rt的一个新息at就包含了εt和vt两个新息,
这增加了模型的自由度,
但是使得从rt数据估计模型参数变得更加困难,
需要使用Kalman滤波或者随机模拟方法计算拟似然估计。
当m=1时,有
lnσ2t∼Ea2t=Ea4t=ρ(a2t,a2t−i)=N(α01−α1,σ2v1−α21)=N(μh,σ2h),exp(μh+12σ2h),3exp(2μ2h+2σ2h),eσ2hαi1−13eσ2h−1.
SV模型经常在拟合上有所改善,
但是波动率的样本外预测时好时坏。
20.2 长记忆随机波动率模型
对资产收益率的实证分析发现,
收益率本身没有长记忆性,
但是其平方序列或者绝对值序列的ACF往往衰减很慢。
前面GARCH类模型的建模中σ2t−1的系数很接近于1,
也提示有长记忆。
下面对1962年到2003年标普500指数和IBM股票的日对数收益率序列的绝对值作ACF,
可以看到长记忆现象存在。
da <- read_table(
"d-ibmvwewsp5-6203.txt",
col_types=cols(.default=col_double(),
date=col_date(format="%Y%m%d")))
xts.ibm <- xts(log(1 + da[,-1]), da[["date"]])
ibm <- coredata(xts.ibm)[,"ibm"]
sp5 <- coredata(xts.ibm)[,"sp5"]标普500指数日对数收益率绝对值的ACF:
np <- 200; nt <- length(sp5)
tmpa <- acf(abs(sp5), lag.max=np, main="", plot=FALSE)
plot(seq(np), tmpa$acf[2:(np+1)], type="h", xlab="Lag", ylab="acf", ylim=c(-0.05, 0.3))
abline(h=c(2,-2)/sqrt(nt), lty=2, col="blue")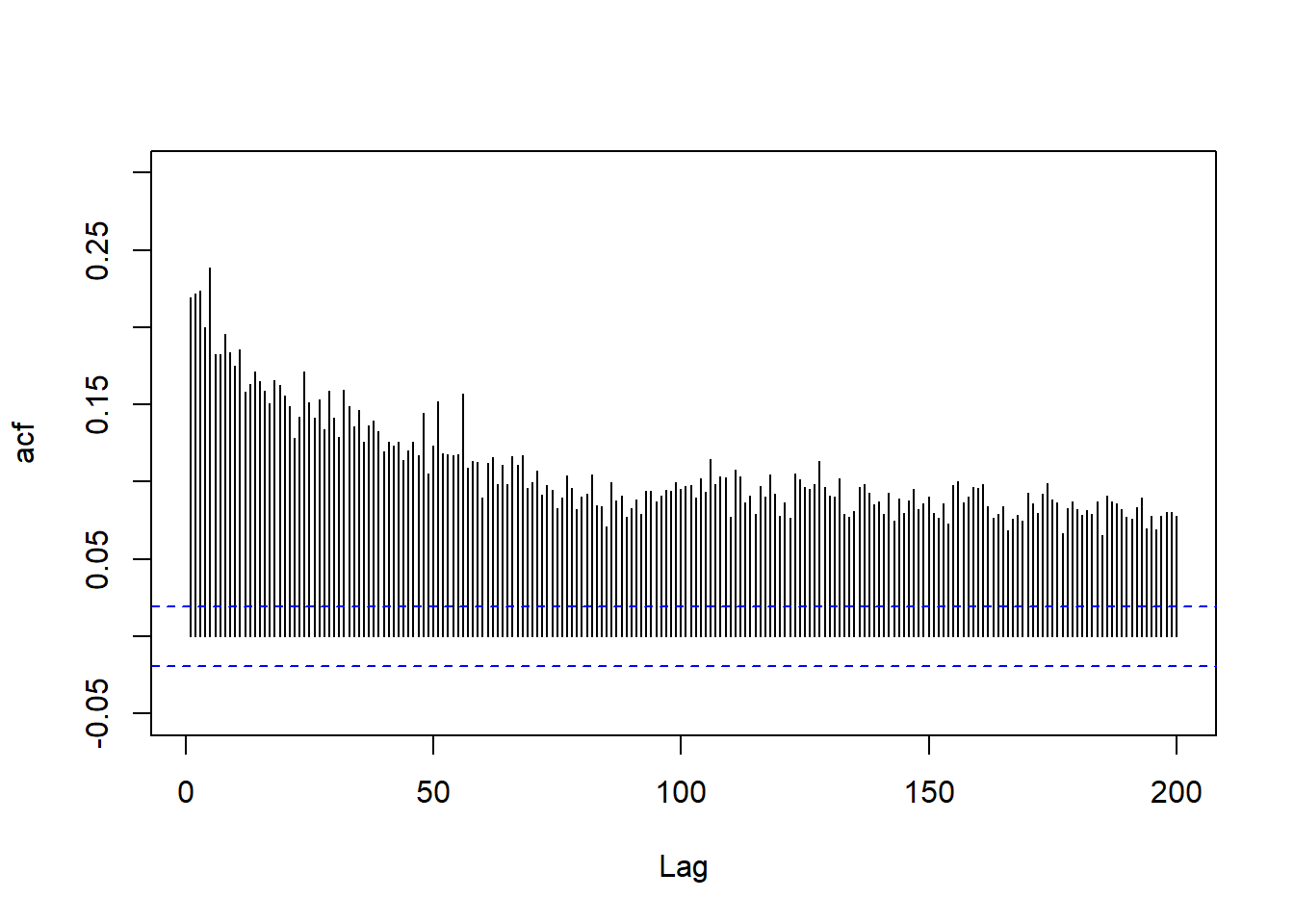

图20.1: 标普500指数日对数收益率绝对值的ACF
IBM股票日对数收益率绝对值的ACF:
np <- 200; nt <- length(sp5)
tmpa <- acf(abs(ibm), lag.max=np, main="", plot=FALSE)
plot(seq(np), tmpa$acf[2:(np+1)], type="h", xlab="Lag", ylab="acf", ylim=c(-0.05, 0.3))
abline(h=c(2,-2)/sqrt(nt), lty=2, col="blue")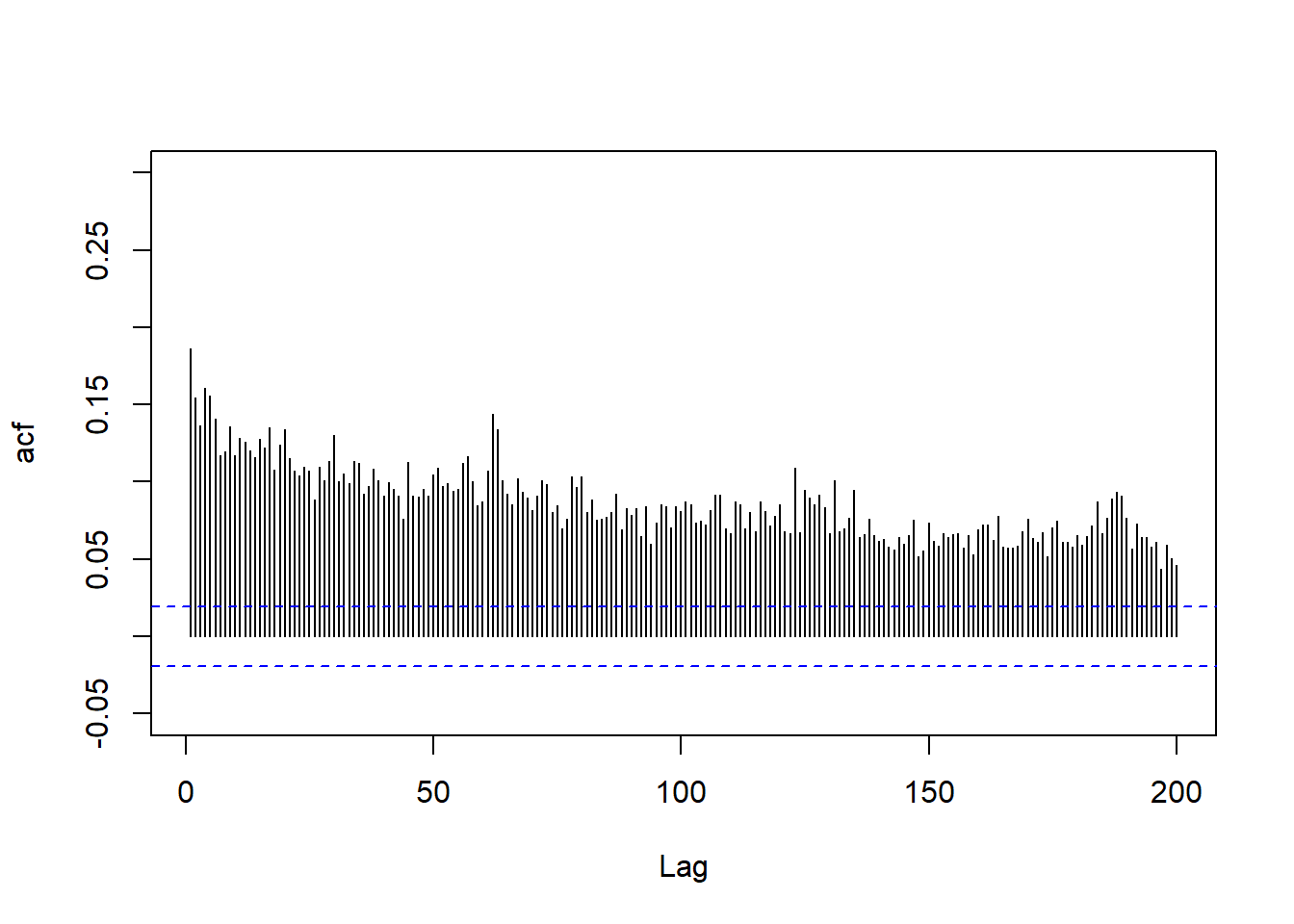
图20.2: IBM股票日对数收益率绝对值的ACF
简单的长记忆随机波动率(LMSV)模型可以写成
at=σtεt,σt=σe12ut,(1−B)dut=ηt.
其中σ>0,
{εt}和{ηt}是两个相互独立的独立同分布高斯白噪声列,
εt∼N(0,1),
ηt∼N(0,σ2η),
0<d<0.5。
长记忆来源于分数差分(1−B)d,
这使得ut的ACF以负幂速度衰减而非负指数速度衰减。
对LMSV有
lna2t===ln(σ2tε2t)=lnσ2+ut+lnε2t(lnσ2+Elnε2t)+ut+(lnε2t−Elnε2t)μ+ut+et.
其中ut是一个长记忆的平稳高斯时间序列,
et是一个非高斯的独立同分布白噪声列。
LMSV估计比较复杂,
分数参数d可以用拟最大似然估计法或者回归方法估计。
标普500指数成份股日收益率平方的对数序列的d估计的中位数是0.38。
同一行业的股票的长记忆成分往往相同。
韭菜热线原创版权所有,发布者:风生水起,转载请注明出处:https://www.9crx.com/74609.html




