

因子
R中用因子代表数据中分类变量, 如性别、省份、职业。
有序因子代表有序量度,如打分结果,疾病严重程度等。
用factor()函数把字符型向量转换成因子,如
x <- c("男", "女", "男", "男", "女")
sex <- factor(x)
sex
## [1] 男 女 男 男 女
## Levels: 男 女
attributes(sex)
## $levels
## [1] "男" "女"
##
## $class
## [1] "factor"因子有class属性,取值为"factor",
还有一个levels(水平值)属性,
此属性可以用levels()函数访问,如
levels(sex)
## [1] "男" "女"因子的levels属性可以看成是一个映射,
把整数值1,2,…映射成这些水平值,
因子在保存时会保存成整数值1,2,…等与水平值对应的编号。
这样可以节省存储空间,
在建模计算的程序中也比较有利于进行数学运算。
事实上,read.csv()函数的默认操作会把输入文件的字符型列自动转换成因子,
这对于性别、职业、地名这样的列是合适的,
但是对于姓名、日期、详细地址这样的列则不合适。
所以,在read.csv()调用中经常加选项stringsAsFactors=FALSE选项禁止这样的自动转换,还可以用colClasses选项逐个指定每列的类型。
建议改用readr包的read_csv()函数,
这个函数读入CSV时不自动转换因子,
生成data.frame的替代类型tibble。
用as.numeric()可以把因子转换为纯粹的整数值,如
as.numeric(sex)
## [1] 1 2 1 1 2因为因子实际保存为整数值,
所以对因子进行一些字符型操作可能导致错误。
用as.character()可以把因子转换成原来的字符型,如
as.character(sex)
## [1] "男" "女" "男" "男" "女"为了对因子执行字符型操作(如取子串),
保险的做法是先用as.character()函数强制转换为字符型。
factor()函数的一般形式为
factor(x, levels = sort(unique(x), na.last = TRUE),
labels, exclude = NA, ordered = FALSE)可以用选项levels自行指定各水平值, 不指定时由x的不同值来求得。
可以用选项labels指定各水平的标签, 不指定时用各水平值的对应字符串。
可以用exclude选项指定要转换为缺失值(NA)的元素值集合。
如果指定了levels,
则当自变量x的某个元素等于第j个水平值时输出的因子对应元素值取整数j, 如果该元素值没有出现在levels中则输出的因子对应元素值取NA。ordered取真值时表示因子水平是有次序的(按编码次序)。
在使用factor()函数定义因子时,
如果知道自变量元素的所有可能取值,
应尽可能使用levels=参数指定这些不同可能取值,
这样,
即使某个取值没有出现,
此变量代表的含义和频数信息也是完整的。
自己指定levels=的另一好处是可以按正确的次序显示因子的分类统计值。
因为一个因子的levels属性是该因子独有的,
所以用c()或者rbind()合并两个因子有可能造成错误,
保险的做法是在定义两个因子时用levels参数指定相同的水平值集合。
较新版本的R软件已经解决了这个问题。
cut()函数
连续取值的变量,可以用cut()函数将其分段,
转换成因子。
使用breaks()参数指定分点,
最小分点要小于数据的最小值,
最大分点要大于等于数据的最大值,
默认使用左开右闭区间分组,
如:
cut(1:10, breaks=c(0, 5, 10))## [1] (0,5] (0,5] (0,5] (0,5] (0,5] (5,10] (5,10] (5,10] (5,10] (5,10]
## Levels: (0,5] (5,10]可以指定breaks为一个正整数,
表示将数据范围略扩大后进行等间距分组,如:
set.seed(1)
x <- sort(round(rnorm(20), 2))
f <- cut(x, breaks=4); f## [1] (-2.21,-1.26] (-1.26,-0.305] (-1.26,-0.305] (-1.26,-0.305] (-1.26,-0.305]
## [6] (-1.26,-0.305] (-0.305,0.647] (-0.305,0.647] (-0.305,0.647] (-0.305,0.647]
## [11] (-0.305,0.647] (-0.305,0.647] (-0.305,0.647] (-0.305,0.647] (0.647,1.6]
## [16] (0.647,1.6] (0.647,1.6] (0.647,1.6] (0.647,1.6] (0.647,1.6]
## Levels: (-2.21,-1.26] (-1.26,-0.305] (-0.305,0.647] (0.647,1.6]可以修改水平标记,
如:
levels(f) <- c("a", "b", "c", "d"); f## [1] a b b b b b c c c c c c c c d d d d d d
## Levels: a b c d为了实现各组个数比较平均的分组,
可以利用quantile()函数计算分位数作为分组,
如:
cu <- quantile(x, c(0, 1/4, 1/2, 3/4, 1))
cu[1] <- cu[1] - 0.01*(cu[5] - cu[1])
f2 <- cut(x, breaks=cu, oredered_result=TRUE)
levels(f2) <- c("a", "b", "c", "d"); f2## [1] a a a a a b b b b b c c c c c d d d d d
## Levels: a b c d参数oredered_result=TRUE表示生成有序因子。
table()函数
用table()函数统计因子各水平的出现次数(称为频数或频率)。
也可以对一般的向量统计每个不同元素的出现次数。
如
table(sex)
## sex
## 男 女
## 3 2对一个变量用table函数计数的结果是一个特殊的有元素名的向量,
元素名是自变量的不同取值,
结果的元素值是对应的频数。
单个因子或单个向量的频数结果可以用向量的下标访问方法取出单个频数或若干个频数的子集。
tapply()函数
可以按照因子分组然后每组计算另一变量的概括统计。
如
h <- c(165, 170, 168, 172, 159)
tapply(h, sex, mean)
## 男 女
## 168.3333 164.5000这里第一自变量h与与第二自变量sex是等长的,
对应元素分别为同一人的身高和性别,tapply()函数分男女两组计算了身高平均值。
forcats包的因子函数
在分类变量类数较多时,往往需要对因子水平另外排序、合并等,
forcats包提供了一些针对因子的方便函数。
fct_relevel
有时在因子水平数较多时仅想将特定的一个或几个水平次序放到因子水平最前面,
可以用forcats::fct_relevel()函数,
如:
set.seed(1)
fac <- sample(c("red", "green", "blue"), 30, replace=TRUE) |>
factor(levels=c("red", "green", "blue"))
levels(fac)
## [1] "red" "green" "blue"
fac3 <- fct_relevel(fac, "blue"); levels(fac3)
## [1] "blue" "red" "green"fct_relevel()第一个参数是要修改次序的因子,
后续可以有多个字符型参数表示要提前的水平。
当然,
也可以提供所有因子水平进行次序重排。
fct_reorder
forcats::fct_reorder()可以根据不同因子水平分成的组中另一数值型变量的统计量值排序。
如:
set.seed(1)
fac <- sample(c("red", "green", "blue"), 30, replace=TRUE)
fac <- factor(fac, levels=c("red", "green", "blue"))
x <- round(100*(10+rt(30,2)))
res1 <- tapply(x, fac, sd); res1
## red green blue
## 370.9222 138.3185 1129.2587
barplot(res1)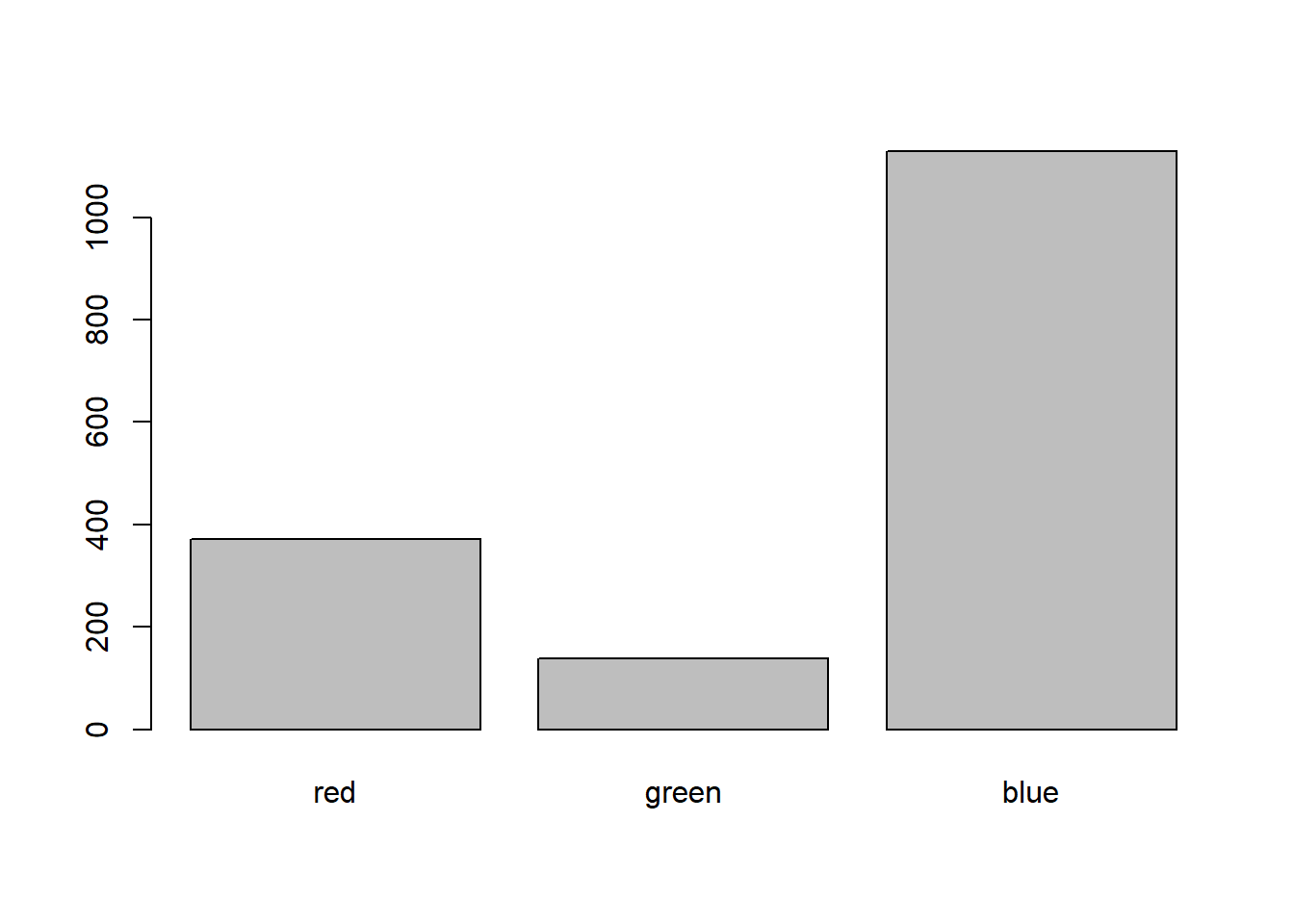

如果希望按照统计量次序对因子排序,
可以用forcats::fct_reorder()函数。
下面的程序将因子按变量x的标准差排序:
fac2 <- fct_reorder(fac, x, sd)
res2 <- tapply(x, fac2, sd)
barplot(res2)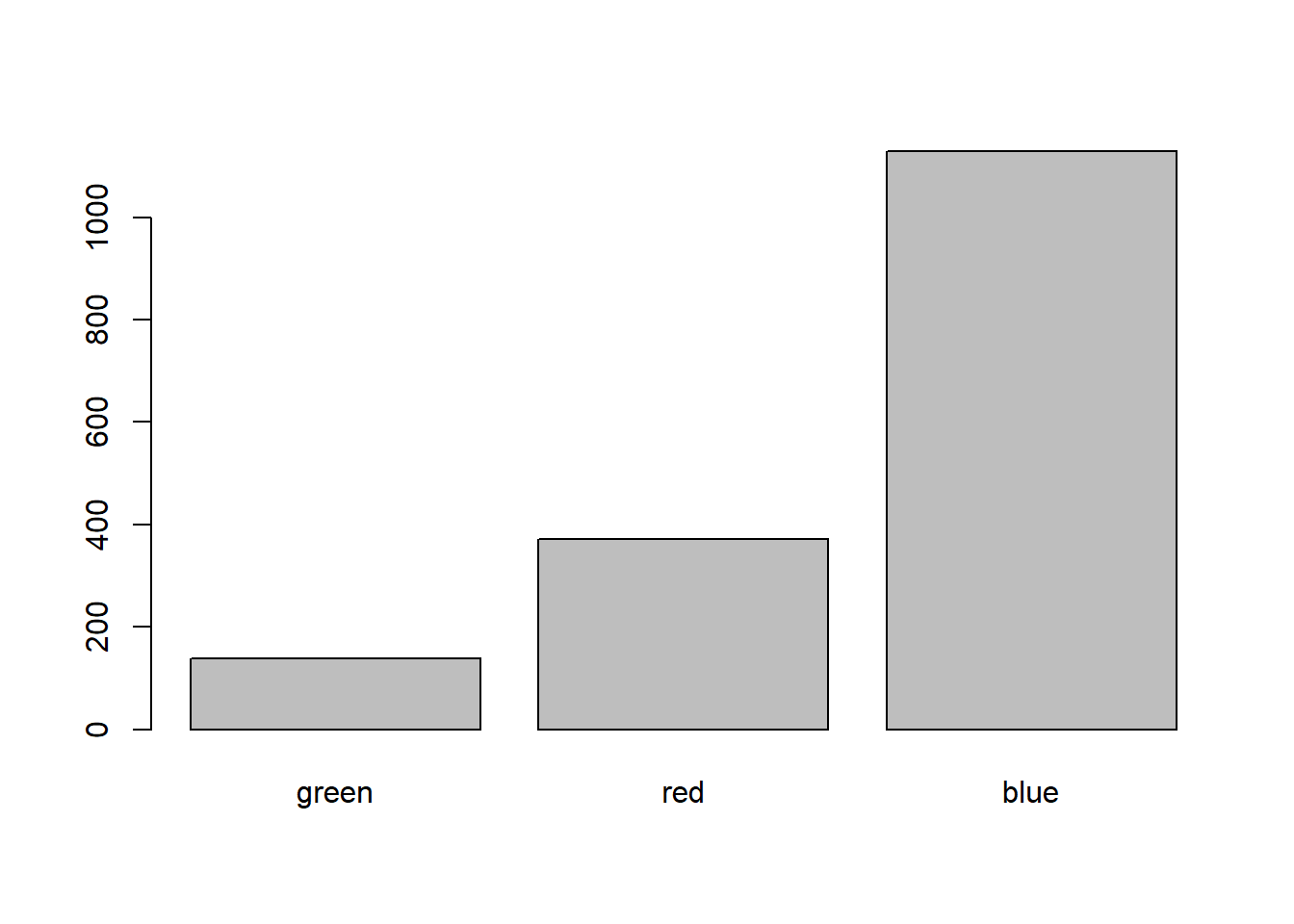
fct_reorder如果不指定按什么统计量排序,
就默认使用中位数。
forcats::fct_reorder2(f, x, y)也调整因子f的水平的次序,
但是根据与每组中最大的x值相对应的y值大小调整次序,
这样在作多个因子水平对应的多条曲线图时,
因子次序按照每条曲线最右端的的纵坐标排列,
而曲线颜色的图例也放在图的右侧,
可以比较容易地将图例颜色与曲线颜色对应起来。
比如,下面的作图用了ggplot2包(见第27章):
## ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.2 ──
## ✔ ggplot2 3.3.6 ✔ purrr 0.3.4
## ✔ tibble 3.1.8 ✔ dplyr 1.0.99.9000
## ✔ tidyr 1.2.1.9001 ✔ stringr 1.5.0.9000
## ✔ readr 2.1.2
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()set.seed(101)
d.rd <- tibble(
x = rep(1:100, 3),
f = factor(rep(1:3, each=100)),
y = c(cumsum(rnorm(100)), cumsum(rnorm(100)), cumsum(rnorm(100)))
)
ggplot(d.rd, aes(
x = x,
y = y,
color = forcats::fct_reorder2(f, x, y))) +
geom_line() +
scale_color_discrete(name="")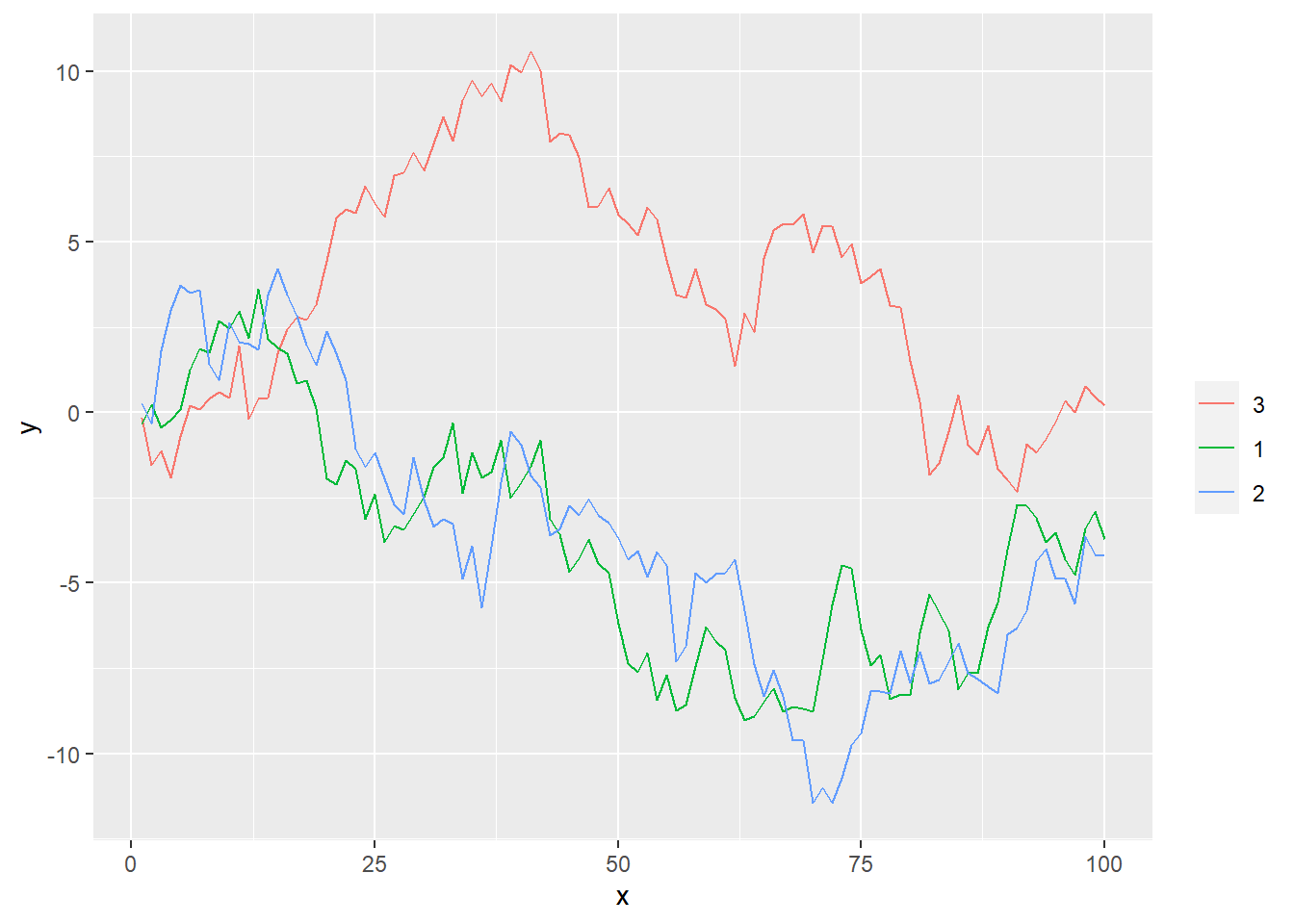
可以看出三条曲线右端的次序与图例的次序一致。
fct_infreq
为了将因子水平按照频数从高到低重新排序,
可以用fct_infreq(f)。
如果需要按频数从低到高排序,
可以用fct_rev(fct_infreq(f))。
fct_recode
forcats::fct_recode()可以修改每个水平的名称,
如:
fac4 <- fct_recode(
fac,
"红"="red",
"绿"="green",
"蓝"="blue")
table(fac4)
## fac4
## 红 绿 蓝
## 13 10 7其中的格式是新水平名 = 老水平名。
fct_recode()在修改水平名时允许多个旧水平对应到一个新水平,
从而合并原来的水平。
如果合并很多,
可以用fct_collapse()函数,
如
compf <- fct_collapse(
comp,
"其它"=c("", "无名", "无应答"),
"联想"=c("联想", "联想集团"),
"百度"=c("百度", "百度集团")
)如果某个因子有很多个类别的观测频数很少,
在统计时有过多水平不易展示主要的类别,
可以用forcats::fct_lump_n(f, n)合并,
用参数n指定要保留多少个类。
类似函数有forcats::fct_lump_min(f, min),
合并频数小于指定界限的类;forcats::fct_lump_prop(f, prop),
合并小于指定比例的类。
函数forcats::fct_lump_lowfreq(f)可以从最少的类合并一直到“其它”类超过未被合并的最小类之前。
练习
设文件class.csv中包含如下内容:
name,sex,age,height,weight
Alice,F,13,56.5,84
Becka,F,13,65.3,98
Gail,F,14,64.3,90
Karen,F,12,56.3,77
Kathy,F,12,59.8,84.5
Mary,F,15,66.5,112
Sandy,F,11,51.3,50.5
Sharon,F,15,62.5,112.5
Tammy,F,14,62.8,102.5
Alfred,M,14,69,112.5
Duke,M,14,63.5,102.5
Guido,M,15,67,133
James,M,12,57.3,83
Jeffrey,M,13,62.5,84
John,M,12,59,99.5
Philip,M,16,72,150
Robert,M,12,64.8,128
Thomas,M,11,57.5,85
William,M,15,66.5,112用如下程序把该文件读入为R数据框d.class,
其中的sex列已经自动转换为因子。
取出其中的sex和age列到变量sex和age中
d.class <- read.csv('class.csv', header=TRUE)
sex <- d.class[,'sex']
age <- d.class[,'age']- 统计并显示列出sex的不同值频数;
- 分男女两组分别求年龄最大值;
- 把sex变量转换为一个新的因子,F显示成“Female”,M显示成“Male”。
韭菜热线原创版权所有,发布者:风生水起,转载请注明出处:https://www.9crx.com/77946.html




