

这一部分讲授如何用R进行统计分析, 包括基本概括统计和探索性数据分析, 置信区间和假设检验, 回归分析与各种回归方法, 广义线性模型, 非线性回归与平滑, 判别树和回归树, 等等。
主要参考书:
- (Venables and Ripley 2002)
- (Kabacoff 2012)
30.1 概率分布
R中与xxx分布有关的函数包括:
dxxx(x), 即xxx分布的分布密度函数(PDF)或概率函数(PMF)p(x)。pxxx(q), 即xxx分布的分布函数(CDF)F(q)=P(X≤q)。qxxx(p), 即xxx分布的分位数函数q(p), p∈(0,1), 对连续型分布,q(p)=F−1(p), 即F(x)=p的解x。rxxx(n), 即xxx的随机数函数,可以生成n个xxx的随机数。
dxxx(x)函数可以加选项log=TRUE, 用来计算\ln p(x), 这在计算对数似然函数时有用, 比log(dxxx(x))更精确。
pxxx(q)可以加选项lower.tail=FALSE, 变成计算P(X>q)=1−F(q)。
qxxx(p)可以加选项lower.tail=TRUE, 表示求P(X>x)=p的解x; 可以加选项log.p=TRUE, 表示输入的p实际是lnp。
这些函数都可以带有自己的分布参数, 有些分布参数有缺省值, 比如正态分布的缺省参数值为零均值单位标准差。
具体的分布类型可以在R命令行用?Distributions查看列表。 常用的分布密度有:
- 离散分布有
dbinom二项分布,dpois泊松分布,dgeom几何分布,dnbinom负二项分布,dmultinom多项分布,dhyper超几何分布。 - 连续分布有
dunif均匀分布,dnorm正态分布,dchisq卡方分布,dtt分布(包括非中心t),dfF分布,dexp指数分布,dweibull威布尔分布,dgamma伽马分布,dbeta贝塔分布,dlnorm对数正态分布,dcauchy柯西分布,dlogis逻辑斯谛分布。
R的扩展包提供了更多的分布, 参见R网站的如下链接:
- https://cran.r-project.org/web/views/Distributions.html
30.2 最大似然估计
R函数optim()、nlm()、optimize()可以用来求函数极值, 因此可以用来计算最大似然估计。 optimize()只能求一元函数极值。
30.2.1 一元正态分布参数最大似然估计
正态分布最大似然估计有解析表达式。 作为示例, 用R函数进行数值优化求解。
对数似然函数为:
lnL(μ,σ2)=−n2ln(2π)−n2lnσ2−12σ2∑(Xi−μ)2
定义R的优化目标函数为上述对数似然函数去掉常数项以后乘以−2, 求其最小值点。 目标函数为:
objf.norm1 <- function(theta, x){
mu <- theta[1]
s2 <- exp(theta[2])
n <- length(x)
res <- n*log(s2) + 1/s2*sum((x - mu)^2)
res
}其中θ1为均值参数μ, θ2为方差参数σ2的对数值。 x是样本数值组成的R向量。
可以用optim函数来求极小值点。下面是一个模拟演示:
norm1d.mledemo1 <- function(n=30){
mu0 <- 20
sigma0 <- 2
set.seed(1)
x <- rnorm(n, mu0, sigma0)
theta0 <- c(0,0)
ores <- optim(theta0, objf.norm1, x=x)
print(ores)
theta <- ores$par
mu <- theta[1]
sigma <- exp(0.5*theta[2])
cat('真实mu=', mu0, ' 公式估计mu=', mean(x),
' 数值优化估计mu=', mu, '\n')
cat('真实sigma=', sigma0,
'公式估计sigma=', sqrt(var(x)*(n-1)/n),
' 数值优化估计sigma=', sigma, '\n')
}
norm1d.mledemo1()## $par
## [1] 20.166892 1.193593
##
## $value
## [1] 65.83709
##
## $counts
## function gradient
## 115 NA
##
## $convergence
## [1] 0
##
## $message
## NULL
##
## 真实mu= 20 公式估计mu= 20.16492 数值优化估计mu= 20.16689
## 真实sigma= 2 公式估计sigma= 1.817177 数值优化估计sigma= 1.816291也可以用nlm()函数求最小值点, 下面是正态分布最大似然估计的另一个演示:
norm1d.mledemo2 <- function(){
set.seed(1)
n <- 30
mu <- 20
sig <- 2
z <- rnorm(n, mean=mu, sd=sig)
neglogL <- function(parm) {
-sum( dnorm(z, mean=parm[1],
sd=exp(parm[2]), log=TRUE) )
}
res <- nlm(neglogL, c(10, log(10)))
print(res)
sig2 <- exp(res$estimate[2])
cat('真实mu=', mu, ' 公式估计mu=', mean(z),
' 数值优化估计mu=', res$estimate[1], '\n')
cat('真实sigma=', sig,
'公式估计sigma=', sqrt(var(z)*(n-1)/n),
' 数值优化估计sigma=', sig2, '\n')
invisible()
}
norm1d.mledemo2()## $minimum
## [1] 60.48667
##
## $estimate
## [1] 20.1649179 0.5972841
##
## $gradient
## [1] 1.444576e-05 9.094805e-06
##
## $code
## [1] 2
##
## $iterations
## [1] 28
##
## 真实mu= 20 公式估计mu= 20.16492 数值优化估计mu= 20.16492
## 真实sigma= 2 公式估计sigma= 1.817177 数值优化估计sigma= 1.817177函数optim()缺省使用Nelder-Mead单纯型搜索算法, 此算法不要求计算梯度和海色阵, 算法稳定性好, 但是收敛速度比较慢。 可以用选项method="BFGS"指定BFGS拟牛顿法。 这时可以用gr=选项输入梯度函数, 缺省使用数值微分计算梯度。 如:
norm1d.mledemo1b <- function(n=30){
mu0 <- 20
sigma0 <- 2
set.seed(1)
x <- rnorm(n, mu0, sigma0)
theta0 <- c(1,1)
ores <- optim(theta0, objf.norm1, x=x, method="BFGS")
print(ores)
theta <- ores$par
mu <- theta[1]
sigma <- exp(0.5*theta[2])
cat('真实mu=', mu0, ' 公式估计mu=', mean(x),
' 数值优化估计mu=', mu, '\n')
cat('真实sigma=', sigma0,
'公式估计sigma=', sqrt(var(x)*(n-1)/n),
' 数值优化估计sigma=', sigma, '\n')
}
norm1d.mledemo1b()## $par
## [1] 20.164916 1.194568
##
## $value
## [1] 65.83704
##
## $counts
## function gradient
## 41 17
##
## $convergence
## [1] 0
##
## $message
## NULL
##
## 真实mu= 20 公式估计mu= 20.16492 数值优化估计mu= 20.16492
## 真实sigma= 2 公式估计sigma= 1.817177 数值优化估计sigma= 1.817177注意使用数值微分时, 参数的初值的数量级应该与最终结果相差不大, 否则可能不收敛, 比如上面程序取初值(0,0)就会不收敛。
optim()函数支持的方法还有"CG"是一种共轭梯度法, 此方法不如BFGS稳健, 但是可以减少存储量使用, 对大规模问题可能更适用。 "L-BFGS-B"是一种区间约束的BFGS优化方法。 "SANN"是模拟退火算法, 有利于求得全局最小值点, 速度比其它方法慢得多。
函数optimize()进行一元函数数值优化计算。 例如,在一元正态分布最大似然估计中, 在对数似然函数中代入μ=x¯,目标函数(负2倍对数似然函数)为
h(σ2)=ln(σ2)+1σ2∑(Xi−X¯)2
下面的例子模拟计算σ2的最大似然估计:
norm1d.mledemo3 <- function(n=30){
mu0 <- 20
sigma0 <- 2
set.seed(1)
x <- rnorm(n, mu0, sigma0)
mu <- mean(x)
ss <- sum((x - mu)^2)/length(x)
objf <- function(delta, ss) log(delta) + 1/delta*ss
ores <- optimize(objf, lower=0.0001,
upper=1000, ss=ss)
delta <- ores$minimum
sigma <- sqrt(delta)
print(ores)
cat('真实sigma=', sigma0,
'公式估计sigma=', sqrt(var(x)*(n-1)/n),
' 数值优化估计sigma=', sigma, '\n')
}
norm1d.mledemo3()## $minimum
## [1] 3.30214
##
## $objective
## [1] 2.194568
##
## 真实sigma= 2 公式估计sigma= 1.817177 数值优化估计sigma= 1.81717930.3 单样本均值的检验和置信区间
R的ggstatsplot扩展包提供了将假设检验结果图示化的功能。
30.3.1 大样本情形
设总体X期望为μ,方差为σ2。 X1,X2,…,Xn是一组样本。
在大样本时,令
Z=x¯−μS/n‾√∼∙N(0,1)
其中∼∙表示近似服从某分布。 x¯为样本均值,S为样本标准差。 σ未知且大样本时, μ近似1−α置信区间为
x¯±qnorm(1−α/2)S/n‾√
用BSDA::z.test(x, sigma.x=sd(x), conf.level=1-alpha)可以计算如上的近似置信区间。
对于假设检验问题
H0:μ=μ0⟷Ha:μ≠μ0H0:μ≤μ0⟷Ha:μ>μ0H0:μ≥μ0⟷Ha:μ<μ0
定义检验统计量
Z=x¯−μ0S/n‾√当μ=μ0时Z近似服从N(0,1)分布。 可以用BSDA::z.test(x, mu=mu0, sigma.x=sd(x))进行双侧Z检验。 加选项alternative="greater"作右侧检验, 加选项alternative="less"作左侧检验。
如果上述问题中标准差σ为已知, 应该在Z的公式用σ替换S,即
Z=x¯−μ0σ/n‾√
计算μ的置信区间程序为BSDA::z.test(x, sigma.x=sigma0), 计算Z检验的程序为BSDA::z.test(x, mu=mu0, sigma.x=sigma0), 仍可用选项alternative=指定双侧、右侧、左侧。
30.3.2 小样本正态情形
如果样本量较小(小于30), 则需要假定总体服从正态分布N(μ,σ2)。
当σ已知时, 有
Z=x¯−μ0σ/n‾√∼N(0,1)
计算μ的置信区间程序为BSDA::z.test(x, sigma.x=sigma0), 计算Z检验的程序为BSDA::z.test(x, mu=mu0, sigma.x=sigma0)。
可以自己写一个计算Z检验的较通用的R函数:
z.test.1s <- function(
x, n=length(x), mu=0, sigma=sd(x), alternative="two.sided"){
z <- (mean(x) - mu) / (sigma / sqrt(n))
if(alternative=="two.sided"){ # 双侧检验
pvalue <- 2*(1 - pnorm(abs(z)))
} else if(alternative=="less"){ # 左侧检验
pvalue <- pnorm(z)
} else if(alternative=="greater"){ # 右侧检验
pvalue <- 1 - pnorm(z)
} else {
stop("alternative unknown!")
}
c(stat=z, pvalue=pvalue)
}这个函数输入样本x和σ=σ0, 或者输入x¯为x和σ=σ0, 输出检验统计量值和p值。
如果σ未知,应使用t统计量检验
T=x¯−μS/n‾√
当μ=μ0时T∼t(n−1)。 如果x保存了样本, 用t.test(x, conf.level=1-alpha)计算μ的置信区间; 用t.test(x, mu=mu0, alternative="two.side")计算H0:μ=μ0的双侧检验, 称为单样本t检验。
如果已知的x¯和S而非具体样本数据, 可以自己写一个R函数计算t检验:
t.test.1s <- function(
x, n=length(x), sigma=sd(x), mu=0,
alternative="two.sided"){
tstat <- (mean(x) - mu) / (sigma / sqrt(n))
if(alternative=="two.sided"){ # 双侧检验
pvalue <- 2*(1 - pt(abs(tstat), n-1))
} else if(alternative=="less"){ # 左侧检验
pvalue <- pt(tstat, n-1)
} else if(alternative=="greater"){ # 右侧检验
pvalue <- 1 - pt(tstat, n-1)
} else {
stop("Alternative unknown!")
}
c(stat=tstat, pvalue=pvalue)
}这个函数允许输入x¯到x中,输入n,输入S到sigma中, 然后计算t检验。
30.3.3 统计假设检验显著性的解释
统计假设检验如果拒绝了H0, 也称“结果显著”、“有显著差异”等。 这只代表样本与零假设的差距足够大, 可以以比较小的代价(第一类错误概率) 排除这样的差距是由于随机样本的随机性引起的, 但是并不表明这样的差距是有科学意义或者有现实意义的。
尤其是超大样本时, 完全没有实际意义的差距也会检验出来是统计显著的。
这时,可以设定一个“有实际意义的差距”δ, 当差距超过δ时才认为有实际差距,如:
H0:|μ−μ0|≤δ⟷|μ−μ0|>δ
统计假设检验如果不拒绝H0, 也称为“结果不显著”、“没有显著差异”, 通常不认为H0就是对的, 看法是没有充分理由推翻H0。
进一步收集更多的数据, 有可能就会发现显著差异。
例如,H0是嫌疑人无罪, 最后不拒绝H0, 只能是没有充分证据证明有罪, 如果后来收集到了关键的罪证, 就还可以再判决嫌疑人有罪。
30.3.4 置信区间与双侧检验的关系
设总体为正态分布N(μ,σ2), σ已知。 随机抽取了n个样品,计算得x¯。 μ的1−α置信区间为
x¯±zα/2σ/n‾√
置信区间理论依据:
P(|x¯−μ|σ/n‾√≤zα/2)=1−α(*)
对双侧检验
H0:μ=μ0⟷Ha:μ≠μ0
当
|x¯−μ0|σ/n‾√≤zα/2时接受H0。
接受H0的条件,就是μ0满足(*)式的大括号中的条件, 即当且仅当μ0落入μ的1−α置信区间时接受H0。
其它检验也与置信区间有类似关系, 但是单侧检验对应于单侧置信区间。
30.3.5 单样本均值比较例子
载入假设检验部分示例程序所用数据:
load("data/hyptest-data.RData")30.3.5.1 咖啡标重的单侧检验
美国联邦贸易委员会定期检查商品标签是否与实际相符。 Hiltop Coffee大罐咖啡标签注明含量为3磅。 每罐具体多一些或少一些并不要紧, 只要总体平均值不少于3磅, 消费者利益就未受侵害。
只有在有充分证据时才应该做出分量不够的判决进而对厂家进行处罚。 所以零假设是H0:μ≥3, 对立假设是Ha:μ<3。
收集数据进行统计判决后, 如果不拒绝H0, 就不需要采取行动; 如果拒绝了H0, 就说明有足够证据认为厂商灌装分量不足, 应进行处罚。
随机抽取了36件样品, 计算平均净重x¯作为总体均值μ的估计。
如果x¯<3, 则H0有理由被怀疑。
x¯比μ0=3少多少, 才让我们愿意拒绝H0? 做出拒绝H0的决定可能会犯第一类错误, 如果差距很小, 这样的差距很可能是随机抽样的随机性引起的, 拒绝H0有很大的机会犯错。
必须先确定一个能够容忍的第一类错误概率。 调查员认为,可以容忍1%的错误拒绝H0的机会 (不该处罚时给出了处罚) 以换得能够在厂商分量不足时正确地做出处罚决定的机会。 即选检验水平α=0.01。
当H0实际成立时, 边界μ=μ0=3处犯第一类错误的概率最大 (这里最不容易区分), 所以计算第一类错误概率只要在边界处计算。
统计假设检验第一步是确定零假设与对立假设, 第二步是确定检验水平α。 第三步是抽取随机样本,计算检验统计量。
以往经验证明净重的标准差是σ=0.18, 且净重的分布为正态分布。
则x¯的抽样分布为N(μ,σ2/n), x¯的标准误差为SE(x¯)=0.18/36‾‾‾√=0.03。
令
z=x¯−μ0SE(x¯)
则H0成立且μ取边界处的μ0时z∼N(0,1)。
当x¯比μ0=3小很多时应拒绝H0。 即检验统计量z很小时拒绝H0。
如果z=−1, 标准正态分布取-1或比-1更小的值的概率是0.1586 (用R程序pnorm(-1)计算), 这个概率不小, 不小于α=0.01, 这时不应该拒绝H0。
如果z=−2, 标准正态分布取-2或比-2更小的值的概率是0.0228, (用R程序pnorm(-2)计算), 这个概率已经比较小了, 但还不小于预先确定的第一类错误概率α=0.01, 这时不应该拒绝H0。
如果z=−3, 标准正态分布取-3或比-3更小的值的概率是0.0013, (用R程序pnorm(-3)计算), 这个概率已经很小了, 也小于预先确定的第一类错误概率α=0.01, 这时应该拒绝H0。
对左侧检验问题H0:μ≥μ0⟷Ha:μ<μ0, 若Z表示标准正态分布随机变量, z是检验统计量的值,在μ=μ0时z的抽样分布是标准正态分布, 可以计算抽样分布中取到等于z以及比z更小的值的概率P(Z≤z), 称为检验的p值。
p值越小,说明x¯比μ0小得越多, 拒绝H0也越有充分证据。 当且仅当p值小于检验水平α时拒绝H0。
p值小于α,说明如果H0真的成立, 出现x¯那么小的检验统计量值的概率也很小, 小于α,所以第一类错误概率小于等于α。
一般地, p值是从样本计算的一个在假定零假设成立情况下, 检验统计量取值更倾向于对立假设成立的概率。 p值越小,拒绝H0越有依据。
设咖啡标称重量问题中抽取了36件样品,测得x¯=2.92磅, 计算得
z=x¯−μ0σ/n‾√=2.92−30.18/36‾‾‾√=−2.67
p值为P(Z≤−2.67)(Z是标准正态分布随机变量), 用R计算得pnorm(-2.67)=0.0038≤α=0.01, 拒绝H0, 应对该厂商进行处罚。
已经预先确定了检验水平α=0.01就不能在看到检验结果后更改检验水平。 但是, 报告出p值后, 其他的人可以利用这样的信息, 不同的人或利益方可能有不同的检验水平的选择, 这通过同一个p值都可以给出需要的结果。
p值也称为“观测显著性水平”, 因为它是能够拒绝H0的最小的可选检验水平, 选取比p值更小的检验水平就不能拒绝H0了。
用自定义的z.test.1s()计算:
z.test.1s(x=2.92, mu=3, n=36, sigma=0.18, alternative="less")## stat pvalue
## -2.666666667 0.003830381p值为0.004,在0.01水平下拒绝原假设, 认为咖啡平均重量显著地低于标称的3磅。
设Coffee数据框的Weight是这36个样本值, 也可以将程序写成:
z.test.1s(Coffee[["Weight"]], mu=3, sigma=0.18, alternative="less")## stat pvalue
## -2.666666667 0.003830381或
BSDA::z.test(Coffee[["Weight"]], mu=3, sigma.x=0.18, alternative="less")##
## One-sample z-Test
##
## data: Coffee[["Weight"]]
## z = -2.6667, p-value = 0.00383
## alternative hypothesis: true mean is less than 3
## 95 percent confidence interval:
## NA 2.969346
## sample estimates:
## mean of x
## 2.9230.3.5.2 高尔夫球性能的双侧检验
美国高尔夫协会对高尔夫运动器械有一系列的规定。 MaxFlight生产高品质的高尔夫球, 平均的飞行距离是295码。
生产线有时会有波动, 当生产的球平均飞行距离不足295码时, 用户会感觉不好用; 当生产的球平均飞行距离超过295码时, 美国高尔夫协会禁止使用这样的球。
该厂商定期抽检生产线上下来的产品, 每次抽取50只。
当平均飞行距离与295码没有显著差距时, 不需要采取措施; 如果有显著差距,就需要调整生产线。
所以取H0:μ=295, Ha:μ≠295。 选检验水平α=0.05。
随机抽取n个样品, 在可控条件下测试出每个的飞行距离, 计算出平均值x¯。
当x¯比μ0(这里是295)小很多或者 x¯比μ0大很多时拒绝H0, 否则不拒绝H0。
设已知总体标准差σ=12, 且飞行距离服从正态分布。
取统计量
z=x¯−μ0σ/n‾√
在H0成立时, z的抽样分布为标准正态分布。
- 设测得x¯=297.6,超过了μ0=295。
z==x¯−μ0σ/n‾√=297.6−29512/50‾‾‾√=1.53
H0成立时z抽样分布为标准正态分布, 设Z是标准正态分布随机变量, Z取到1.53或者比1.53更倾向于反对H0的值概率? 这包括P(Z≥1.53), 还应包括P(Z≤−1.53)。
所以p值是P(|Z|≥|z|), R中计算为2*(1 - pnorm(abs(z)))。 p值等于0.1260, 超过检验水平, 不拒绝H0, 不需要调整生产线。
用自定义的z.test.1s()检验:
z.test.1s(GolfTest[['Yards']], mu=295, sigma=12, alternative="two.sided")## stat pvalue
## 1.5320647 0.1255065或用BSDA::z.test():
BSDA::z.test(GolfTest[['Yards']], mu=295, sigma.x=12, alternative="two.sided")##
## One-sample z-Test
##
## data: GolfTest[["Yards"]]
## z = 1.5321, p-value = 0.1255
## alternative hypothesis: true mean is not equal to 295
## 95 percent confidence interval:
## 294.2738 300.9262
## sample estimates:
## mean of x
## 297.6p值为0.13,在0.05水平下不拒绝H0, 生产的球的平均飞行距离与标准的295码之间没有显著差异。
30.3.5.3 Heathrow机场打分的检验
某旅行杂志希望根据乘机进行商务旅行的意见给跨大西洋门户机场评分。 乘客评分取0到10分,超过7分算作是服务一流的机场。 在每个机场随机选取60位商务旅行乘客打分评价。 英国Heathrow机场的打分样本x¯=7.25, S=1.052。 英国Heathrow机场可以算是服务一流吗?
由于随机样本的随机性, 要判断的是μ>7是否成立, 这里x¯=7.25并不能很确定第说μ>7成立。
因为将机场评为一流需要有充分证据, 所以将对立假设Ha设为μ>7, 然后取H0:μ≤7。
取检验水平α=0.05。
计算检验统计量
t=x¯−μ0S/n‾√=7.25−71.052/60‾‾‾√=1.84
设T是服从t(n−1)分布的随机变量, p值为P(T≥1.84)。 用R软件计算为1 - pt(1.84, 60-1)=0.0354。 p值小于α,拒绝H0, 认为平均评分显著高于7, 可以认为Heathrow机场是服务一流。
从原始样本数据用t.test()检验:
t.test(AirRating[["Rating"]], mu=7, alternative="greater")##
## One Sample t-test
##
## data: AirRating[["Rating"]]
## t = 1.8414, df = 59, p-value = 0.03529
## alternative hypothesis: true mean is greater than 7
## 95 percent confidence interval:
## 7.023124 Inf
## sample estimates:
## mean of x
## 7.25用自定义的t.test.1s()和样本统计量计算:
t.test.1s(x=7.25, sigma=1.052, n=60, mu=7, alternative="greater")## stat pvalue
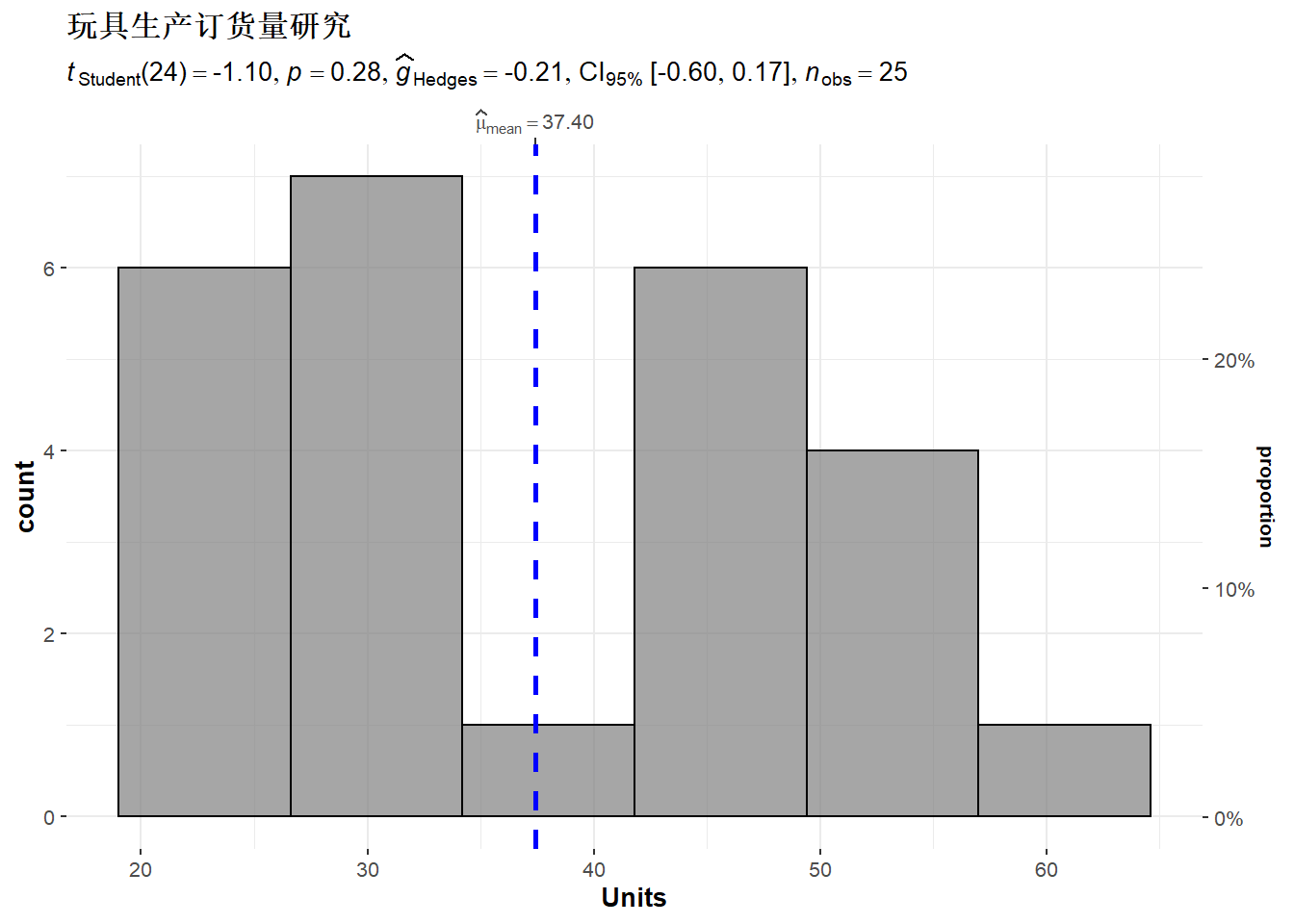
## 1.84077155 0.0353425530.3.5.4 玩具厂商订货量的假设检验
玩具厂商Holiday Toys通过超过1000家玩具商店售货。 为了准备即将到来的冬季销售季节, 销售主管需要确定今年某新款玩具的生产量。 凭经验判断平均每家商店需要40件。
为了确定,随机抽取了25家商店, 提供了新款玩具的特点、进货价和建议销售价, 让他们给出订货量估计。 目的是判断按每家40件来生产是否合适。
因为多生产或少生产都不合适, 所以取零假设为H0:μ=40。 对立假设为Ha:μ≠40。 只有拒绝H0时才需要更改生产计划。
取检验水平α=0.05。 样本计算得n=25,x¯=37.4, S=11.79。
检验统计量
t=x¯−μ0S/n‾√=37.4−4011.79/25‾‾‾√=−1.10
设T为服从t(n−1)分布的随机变量, p值为2P(|T|>|−1.10|), 用R计算为2*(1 - pt(abs(-1.10), 25-1))=0.2822。
不拒绝H0,所以不需要更改生产计划。
从原始样本数据用t.test()检验:
t.test(Orders[["Units"]], mu=40, alternative="two.sided")##
## One Sample t-test
##
## data: Orders[["Units"]]
## t = -1.1026, df = 24, p-value = 0.2811
## alternative hypothesis: true mean is not equal to 40
## 95 percent confidence interval:
## 32.5334 42.2666
## sample estimates:
## mean of x
## 37.4用自定义的t.test.1s()和样本统计量计算:
t.test.1s(x=37.4, sigma=11.79, n=25, mu=40, alternative="two.sided")## stat pvalue
## -1.1026293 0.2811226利用ggstatsplot图示:
library(ggstatsplot)
gghistostats(
data = Orders,
x = Units,
title = "玩具生产订货量研究",
test.value = 40
)

30.3.6 单样本均值比较样本量和功效计算
检验的功效, 是指对立假设成立时检验拒绝H0的概率1−β, 其中β是第二类错误, 即当对立假设成立时错误地接受H0的概率。 需要足够大的样本量才能使得检验能够发现实际存在的显著差异。 因为要计算功效需要一个确定的对立假设下的分布, 而不是一族分布, 所以需要指定要检验的具体零假设和对立假设分布, 或者指定一个效应大小值。
设H0:μ=μ0, 对立假设是双侧或者单侧, 为了能够在μ=μ1≠μ0时拒绝H0的概率达到指定的功效1−β=0.80, 设检验水平为α, |μ1−μ0|=δ, 需要的样本量为可以用R的power.t.test()计算,如:
power.t.test(delta = 2.5, sd = 1.5,
type = "one.sample",
alternative = "two.sided",
sig.level=0.05,
power=0.80)##
## One-sample t test power calculation
##
## n = 5.04919
## delta = 2.5
## sd = 1.5
## sig.level = 0.05
## power = 0.8
## alternative = two.sided其中delta是要发现的均值差距下限, sd是样本标准差, 如果未知需要先用一个小样本进行估计, sig.level是检验水平, power是要求达到的功效。 可以用alternative参数选择双侧(two.sided)或单侧(one.sided)。 结果表明所求样本量为6。
样本量和功效是互相决定的。 前面的例子是给定要达到的功效, 求样本量。 也可以输入样本量, 求可达到的功效,如:
power.t.test(delta = 2.5, sd = 1.5,
type = "one.sample",
alternative = "two.sided",
sig.level=0.05,
n=10)##
## One-sample t test power calculation
##
## n = 10
## delta = 2.5
## sd = 1.5
## sig.level = 0.05
## power = 0.9964471
## alternative = two.sided所以在单样本t检验中, 若标准差为σ=1.5, 零假设和对立假设下的均值差为|μ1−μ0|=2.5, 检验水平α=0.05, 作双侧t检验, 则样本量n=10时功效可达到99.64%。
实际上, 要发现的均值之间的差别依赖于标准差, 而比值|μ1−μ0|σ则完全决定了要发现的均值差别, 样本量与功效的关系在比值|μ1−μ0|σ给定时也完全确定。 所以, 称比值
d=|μ1−μ0|σ
为要检验的“效应大小”(effect size)。 上面例子中d=2.5/1.5=1.67, 属于较大的效应, 所以很容易检出, 只需要较小的样本量就可以达到足够的功效。
(Cohen 1988)给出了单样本t检验时常用的效应大小:
- 小(small): 0.2;
- 中(medium): 0.5;
- 大(large): 0.8。
要发现的效应越小, 就需要越大的样本量。 要发现的效应很大时, 较小的样本量就可以获得较高的功效。
R扩展包pwr提供了功效与样本量计算问题。 比如, 单样本t检验, 要检验中等效应大小, 取检验水平0.05, 为了达到0.80的功效, 可计算如:
library(pwr)
cohen.ES(test = "t", size = "medium")##
## Conventional effect size from Cohen (1982)
##
## test = t
## size = medium
## effect.size = 0.5pwr.t.test(
type = "one.sample",
alternative="two.sided",
d = 0.5,
sig.level = 0.05,
power = 0.80 )##
## One-sample t test power calculation
##
## n = 33.36713
## d = 0.5
## sig.level = 0.05
## power = 0.8
## alternative = two.sided结果表明, 样本量要达到n=34。
也可以输入样本量, 计算可达到的功效:
pwr.t.test(
type = "one.sample",
alternative="two.sided",
d = 0.5,
sig.level = 0.05,
n = 30 )##
## One-sample t test power calculation
##
## n = 30
## d = 0.5
## sig.level = 0.05
## power = 0.7539647
## alternative = two.sided单样本双侧t检验, 为了检验中等效应大小, 样本量n=30对应的功效是75%。
例30.1 以希思罗机场打分数据为例。
H0下μ=7.0, 实际数据的x¯=7.25, 标准差用样本标准差S=1.052代替, 样本量n=60, 计算x¯−μ0=7.25−0.25这样的均值差, 其效应大小为
d=x¯−μ0S=7.25−7.01.052=0.2376
这个效应比较小, 对应于较大的样本量或者较小的功效。
计算这样的效应大小的功效, 取检验水平0.05:
pwr.t.test(
type = "one.sample",
alternative="greater",
d = (7.25 - 7.0)/1.052,
sig.level = 0.05,
n = 60 )##
## One-sample t test power calculation
##
## n = 60
## d = 0.2376426
## sig.level = 0.05
## power = 0.5693621
## alternative = greater功效只有57%。 计算需要多大样本量可达到80%功效:
pwr.t.test(
type = "one.sample",
alternative="greater",
d = (7.25 - 7.0)/1.052,
sig.level = 0.05,
power = 0.80 )##
## One-sample t test power calculation
##
## n = 110.8416
## d = 0.2376426
## sig.level = 0.05
## power = 0.8
## alternative = greater样本量要达到n=111。
功效随样本量变化曲线图示:
pwr.t.test(
type = "one.sample",
alternative="greater",
d = (7.25 - 7.0)/1.052,
sig.level = 0.05,
power = 0.80 ) |>
plot()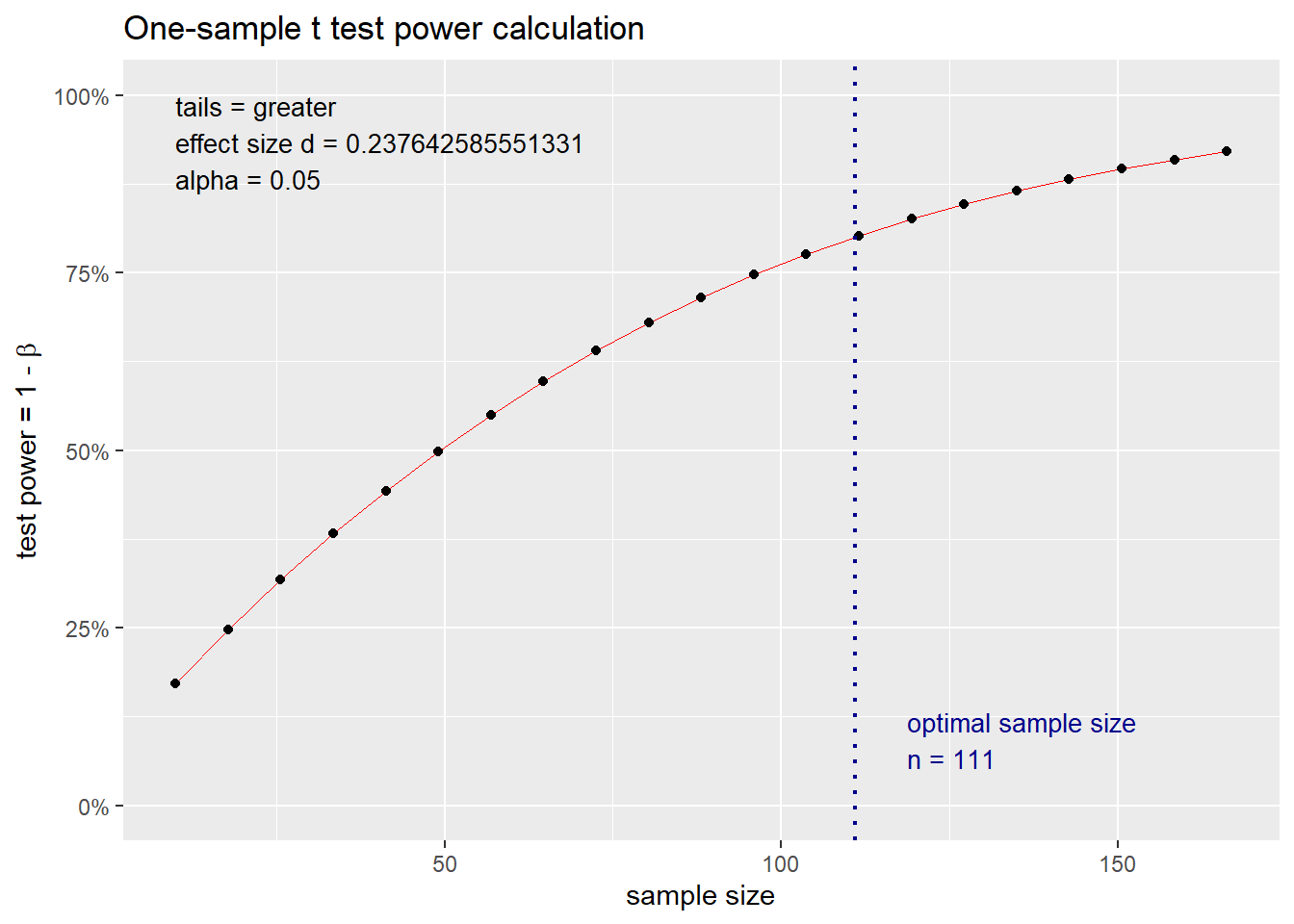
30.4 均值比较
30.4.1 独立两样本Z检验
假设有两个独立的总体X,Y,例如,男性与女性的寿命。 要比较两个总体的期望μ1=EX和μ2=EY。 设两个总体的方差分别为σ21和σ22。 可以对均值作双侧、左侧、右侧检验。 比如,双侧检验为
H0:μ1=μ2⟷Ha:μ1≠μ2
如果两个总体都服从正态分布, 而且分别的方差σ21和σ22已知, 设X的样本量为n1的样本得到样本均值x¯, 设Y的样本量为n2的样本得到样本均值y¯, 取统计量
Z=x¯−y¯σ21n1+σ22n2‾‾‾‾‾‾‾‾√
其中分母是分子的标准误差。 当μ1=μ2时Z∼N(0,1)。
如果分布不一定是正态分布但是样本量足够大, 可以令
Z=x¯−y¯S2xn1+S2yn2‾‾‾‾‾‾‾‾√
当μ1=μ2时Z近似服从N(0,1)。
检验问题还可以变成μ1−μ2与某个δ的比较,如
H0:μ1≤μ2−δ⟷Ha:μ1>μ2−δ
这个对立假设是“不次于”的结论。
可以写一个大样本方差未知或已知, 小样本独立两正态总体方差已知情况做Z检验的R函数:
z.test.2s <- function(
x, y, n1=length(x), n2=length(y), delta=0,
sigma1=sd(x), sigma2=sd(y), alternative="two.sided"){
z <- (mean(x) - mean(y) - delta) / sqrt(sigma1^2 / n1 + sigma2^2 / n2)
if(alternative=="two.sided"){ # 双侧检验
pvalue <- 2*(1 - pnorm(abs(z)))
} else if(alternative=="less"){ # 左侧检验
pvalue <- pnorm(z)
} else if(alternative=="greater"){ # 右侧检验
pvalue <- 1 - pnorm(z)
} else {
stop("alternative unknown!")
}
c(stat=z, pvalue=pvalue)
}函数允许输入两组样本到x和y中, 输入σ1和σ2到sigma1和sigma2中, 这时不输入sigma1和sigma2则从样本中计算样本统计量代替。 也允许输入x¯和y¯到x和y中, 输入σ1和σ2到sigma1和sigma2中, 或者输入Sx和Sy到sigma1和sigma2中, 输入n1到n1中, 输入n2到n2中, 计算独立两样本均值比较的Z检验。
30.4.2 独立两样本t检验
如果样本是小样本,但两个总体分别服从正态分布, 两个总体的方差未知, 但已知σ21=σ22。 这时σ21=σ22可以统一估计为
S2p=1n1+n2−2((n1−1)S2x+(n2−1)S2y)
取检验统计量
T=x¯−y¯Sp1n1+1n2‾‾‾‾‾‾‾‾√当μ1=μ2时T∼t(n1+n2−2)。
当x和y存放了两组独立样本时, 可以用t.test(x, y, var.equal=TRUE)计算两样本t检验, 用alternative=选项指定双侧、右侧、左侧检验。
可以自己写一个这样的R函数作两样本t检验, 允许只输入统计量而非具体样本值:
t.test.2s <- function(
x, y, n1=length(x), n2=length(y),
sigma1=sd(x), sigma2=sd(y), delta=0,
alternative="two.sided"){
sp <- sqrt(1/(n1+n2-2) * ((n1-1)*sigma1^2 + (n2-1)*sigma2^2))
t <- (mean(x) - mean(y) - delta) / (sp * sqrt(1 / n1 + 1 / n2))
if(alternative=="two.sided"){ # 双侧检验
pvalue <- 2*(1 - pt(abs(t), n1+n2-2))
} else if(alternative=="less"){ # 左侧检验
pvalue <- pt(t, n1+n2-2)
} else if(alternative=="greater"){ # 右侧检验
pvalue <- 1 - pt(t, n1+n2-2)
} else {
stop("alternative unknown!")
}
c(stat=t, pvalue=pvalue)
}如果两个独立正态总体的方差不相等,样本量不够大, 可以用如下的在H0下近似服从t分布的检验统计量:
T=x¯−y¯S2xn1+S2yn2‾‾‾‾‾‾‾‾√
自由度为
m=(S2x/n1+S2y/n2)2(S2x/n1)2n1−1+(S2y/n2)2n2−1这个检验称为Welch两样本t检验,或Satterthwaite 两样本t检验 当x和y存放了两组独立样本时, 可以用t.test(x, y, var.equal=FALSE)计算Welch两样本t检验。
如果方差是否相等不易判断, 可以直接选用Welch检验。
因为大样本时t分布与标准正态分布基本相同, 所以非正态总体大样本Z检验也可以用t.test()计算。
30.4.3 成对均值比较问题
设总体包含两个X,Y分量, 比如, 一组病人的服药前血压与服药后血压。 这两个变量是相关的, 不能用独立两总体的均值比较方法比较μ1=EX与μ2=EY。
若ξ=X−Y服从正态分布, 则可以对ξ进行均值为零的单样本t检验。 这样的检验称为成对均值的t检验。
若x和y分别为X和Y的样本值, 可以用t.test(x, y, paired=TRUE)计算计算成对均值t检验。
30.4.4 均值比较的例子
30.4.4.1 顾客平均年龄差别比较
HomeStyle是一个连锁家具店, 两家分店一个在城区,一个在郊区。 经理发现同一种家具有可能在一个分店卖的很好, 另一个分店则不好。 怀疑是顾客人群的人口学差异(年龄、性别、种族等)。
独立地抽取两个分店的顾客样本,比较平均年龄。 设城内的分店顾客年龄σ1=9已知, 郊区的分店顾客年龄σ2=10已知。
城内调查了n1=36位顾客,年龄的样本平均值x¯=40; 郊区调查了n2=49位顾客,年龄的样本平均值y¯=35。 x¯−y¯=5。
作双侧检验,水平α=0.05。
计算Z统计量:
Z=40−359236+10249‾‾‾‾‾‾‾‾√=2.4138
p值为P(|V|≥|2.4138|),其中V为标准正态分布随机变量。 用R计算为2*(1 - pnorm(abs(2.4138)))=0.016, 两个分店的顾客年龄有显著差异, 城里的顾客平均年龄显著地高。
基于样本统计量用自定义的z.test.2s()计算:
z.test.2s(n1=36, x=40, sigma1=9,
n2=49, y=35, sigma2=10,
alternative="two.sided")## stat pvalue
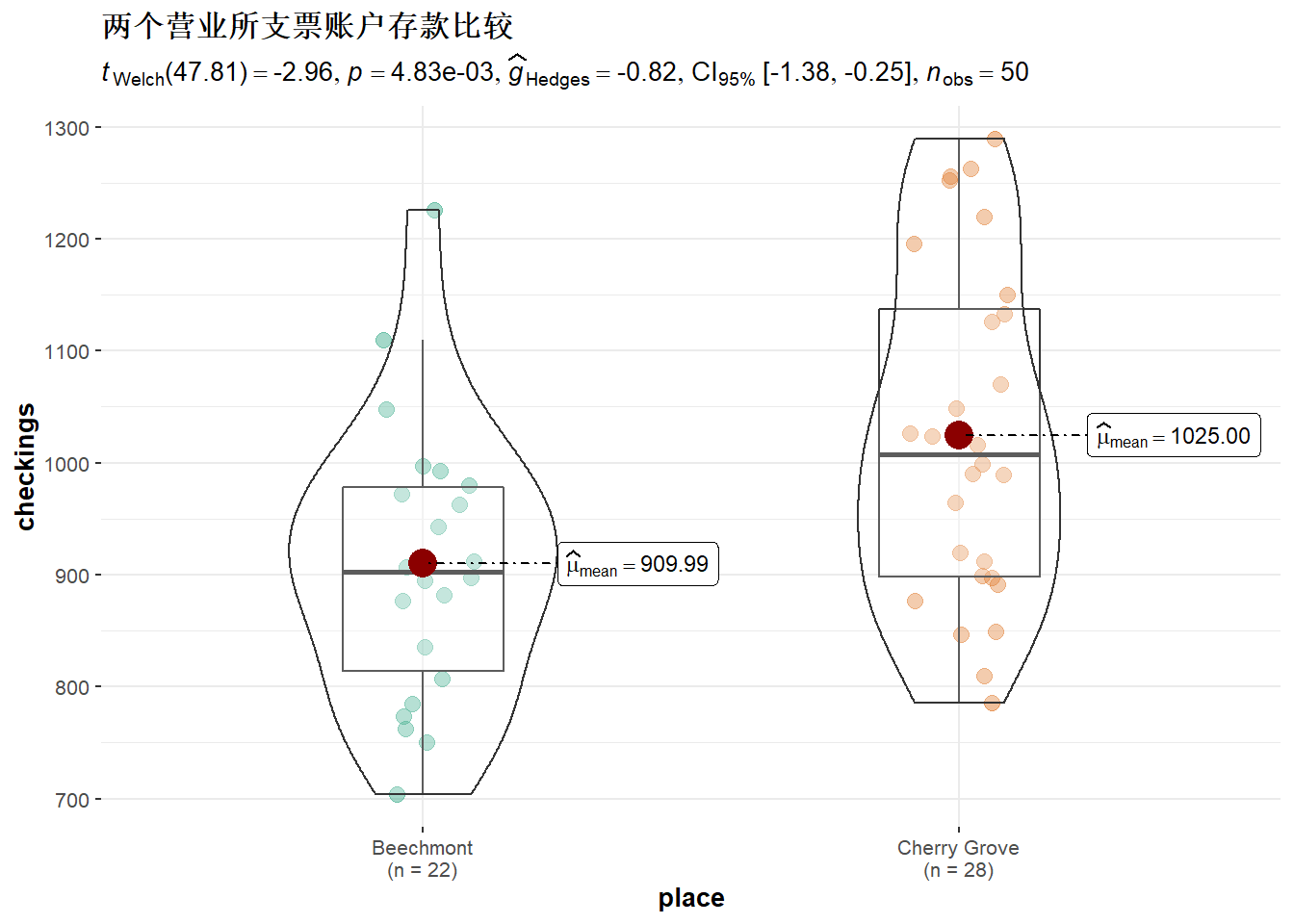
## 2.41379310 0.0157874230.4.4.2 两个银行营业所顾客平均存款比较
某银行要比较两个营业所的支票账户的平均存款额。 作双侧检验,水平0.05。没有方差信息时可以直接选用Welch检验。
设第一个营业所随机抽查了n1=28个支票账户, 均值为x¯=1025(美元),样本标准差为S1=150, 第二个营业所随机抽查了n2=22个支票账户, 均值为y¯=910, 样本标准差为S2=125。
从原始数据出发计算检验:
t.test(CheckAcct[[1]], CheckAcct[[2]],
var.equal = FALSE, alternative = "two.sided")##
## Welch Two Sample t-test
##
## data: CheckAcct[[1]] and CheckAcct[[2]]
## t = 2.956, df = 47.805, p-value = 0.004828
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## 36.77503 193.25224
## sample estimates:
## mean of x mean of y
## 1025.0000 909.9864p值为0.005,在0.05水平下显著, 两个营业所的账户平均余额有显著差异。
用ggstatsplot包图示:
d <- rbind(
data.frame(place = names(CheckAcct)[1],
checkings = CheckAcct[[1]]),
data.frame(place = names(CheckAcct)[2],
checkings = CheckAcct[[2]]))
library(ggstatsplot)
ggbetweenstats(
data = d,
x = place,
y = checkings,
title = "两个营业所支票账户存款比较"
)
30.4.4.3 两种工具软件的比较
考虑开发信息系统的两种工具软件的比较。 新的软件声称比旧的软件能加快进度。 设使用旧软件时平均项目完成时间为μ1, 使用新软件时为μ2。
检验:
H0:μ1≤μ2⟷Ha:μ1>μ2
(对立假设是新软件的工期更短) 取0.05水平。
t.test(SoftwareTest[['Current']], SoftwareTest[['New']],
var.equal = FALSE, alternative = 'greater')##
## Welch Two Sample t-test
##
## data: SoftwareTest[["Current"]] and SoftwareTest[["New"]]
## t = 2.2721, df = 21.803, p-value = 0.01665
## alternative hypothesis: true difference in means is greater than 0
## 95 percent confidence interval:
## 9.514309 Inf
## sample estimates:
## mean of x mean of y
## 325 286p值为0.017, 使用新的工具软件的平均项目完成时间显著地少于使用旧工具软件。
30.4.4.4 两种工艺所需时间的比较
工厂希望比较同一生产问题两种工艺各自需要的时间, 将选用时间较短的工艺。 可以一组工人用工艺1,一组工人用工艺2, 随机分组。 两组之间工人的个体差异会使得差异的比较误差较大。
所以,让同一个工人分别采用两种工艺, 次序先后随机。 这样不会引入个体差异的影响, 精度较高。 使用成对检验。 用双侧检验,水平0.05。
t.test(Matched[["Method 1"]], Matched[["Method 2"]],
paired=TRUE, alternative = "two.sided")##
## Paired t-test
##
## data: Matched[["Method 1"]] and Matched[["Method 2"]]
## t = 2.1958, df = 5, p-value = 0.07952
## alternative hypothesis: true mean difference is not equal to 0
## 95 percent confidence interval:
## -0.05120834 0.65120834
## sample estimates:
## mean difference
## 0.330.4.5 均值比较的样本量和功效计算
针对假定两组方差相等的独立两样本t检验, 设已知合并的标准差估计σ, 要检验的两组均值差的下界为δ, 可以用power.t.test()估计需要的样本量,如:
power.t.test(
delta = 2.5, sd = 1.5,
type = "two.sample",
alternative = "two.sided",
sig.level=0.05,
power=0.90)##
## Two-sample t test power calculation
##
## n = 8.649245
## delta = 2.5
## sd = 1.5
## sig.level = 0.05
## power = 0.9
## alternative = two.sided
##
## NOTE: n is number in *each* group这里输出的样本量是两组各自的样本量, 假定两组样本量相等。 结果表明两组都至少要有n=9个观测。
对于成对t检验, 只要将type输入为"paired", 因为成对t检验实际上是对两个变量的差值进行检验, 所以sigma参数输入的是差值的标准差。
pwr包可以用来计算功效和样本量。 对于独立两样本比较问题, 定义要检验的效应大小:
d=μ2−μ1σ,
其中μ1, μ2是两组的均值, σ是两组共同的标准差, d为效应大小。 给定检验水平、单双侧、效应大小, 功效与样本量可以互相唯一决定。
常用的d值有:
- 小:d=0.2;
- 中: d=0.5;
- 大: d=0.8。
例30.2 考虑两个银行营业所顾客平均存款比较问题, 用独立两样本t检验。
以估计的均值为两组均值, 估计的合并标准差为σ, 计算效应大小:
x <- na.omit(CheckAcct[[1]])
y <- na.omit(CheckAcct[[2]])
d <- (mean(y) - mean(x)) / sd(c(x, y)); d## [1] -0.7681087计算两组各n=(28+22)/2=25个观测时的功效:
pwr.t.test(
type="two.sample",
alternative="two.sided",
d = -0.7681,
sig.level = 0.05,
n = 25 )##
## Two-sample t test power calculation
##
## n = 25
## d = 0.7681
## sig.level = 0.05
## power = 0.7583484
## alternative = two.sided
##
## NOTE: n is number in *each* group功效为76%。
计算功效达到80%所需样本量:
pwr.t.test(
type="two.sample",
alternative="two.sided",
d = -0.7681,
sig.level = 0.05,
power = 0.80 )##
## Two-sample t test power calculation
##
## n = 27.60138
## d = 0.7681
## sig.level = 0.05
## power = 0.8
## alternative = two.sided
##
## NOTE: n is number in *each* group功效80%需要每组有28个观测。
但是,在这里我们用了观测到的两组均值的差作为我们要发现的差别。 实际上, 我们可能需要发现更小一些的效应,这时需要更大的样本量。 比如, 指定Cohen规定的“中等”效应:
cohen.ES(test = "t", size = "medium")##
## Conventional effect size from Cohen (1982)
##
## test = t
## size = medium
## effect.size = 0.5pwr.t.test(
type="two.sample",
alternative="two.sided",
d = 0.5,
sig.level = 0.05,
power = 0.80 )##
## Two-sample t test power calculation
##
## n = 63.76561
## d = 0.5
## sig.level = 0.05
## power = 0.8
## alternative = two.sided
##
## NOTE: n is number in *each* group要发现中等的效应, 需要将样本量增大到每组各64个观测。
当要比较的两组的样本量不同时可以用pwr.t2n.test()计算功效, 输入n1和n2两个样本量。 比如,n1=28, n2=22, 比较中等的均值差异效应:
pwr.t2n.test(
alternative="two.sided",
d = 0.5,
sig.level = 0.05,
n1 = 28, n2 = 22 )##
## t test power calculation
##
## n1 = 28
## n2 = 22
## d = 0.5
## sig.level = 0.05
## power = 0.4052476
## alternative = two.sided功效仅有41%。
30.4.6 多元均值置信域
待补充。
30.5 单个比例的假设检验和置信区间
30.5.1 方法
设要比较的是总体的某个比例, 如选民中对候选人甲的支持率。 这时总体是两点分布总体, 支持为1, 不支持为0,参数为p=P(X=1)。 其它的比例问题类似, p是“成功概率”。
关于单总体的比例,也有双侧、右侧、左侧检验问题:
H0:p=p0⟷Ha:p≠p0H0:p≤p0⟷Ha:p>p0H0:p≥p0⟷Ha:p<p0
在R中, 大样本情况下可以用prop.test(x, n, p=p0)作单个比例的检验, n是样本量,x是样本中符合条件(如支持)的个数, 检验使用近似卡方统计量, 用alternative选项选择双侧、右侧、左侧检验。 这个函数也给出比例p的近似1−α置信区间, 用conf.level选项指定置信度。
大样本时还有
p̂ −pp(1−p)/n‾‾‾‾‾‾‾‾‾‾√
近似服从标准正态分布, 可以据此计算Z检验。 自定义的R函数如下:
prop.test.1s <- function(x, n, p=0.5, alternative="two.sided"){
phat <- x/n
zstat <- (phat - p)/sqrt(p*(1-p)/n)
if(alternative=="two.sided"){ # 双侧检验
pvalue <- 2*(1 - pnorm(abs(zstat)))
} else if(alternative=="less"){ # 左侧检验
pvalue <- pnorm(zstat)
} else if(alternative=="greater"){ # 右侧检验
pvalue <- 1 - pnorm(zstat)
} else {
stop("alternative unknown!")
}
c(stat=zstat, pvalue=pvalue)
}因为比例问题本质上是一个二项分布推断问题, 所以R还提供了binom.test(x, n, p=p0)函数进行精确检验并计算精确置信区间, 但其结果略保守。 用法与prop.test()类似。
30.5.2 高尔夫培训女生比例检验例子
橡树溪高尔夫培训机构的女性学员比例较少,只有20%。 为了增加女性学员,设计了促销措施。一个月后调查, 希望证明女性学员比例增加了。
设女性学员比例为p,
H0:p≤0.20⟷Ha:p>0.20
取检验水平0.05。 抽查了400名学员,其中100名是女性学员,p̂ =0.25。
用prop.test()检验:
prop.test(100, 400, p=0.20, alternative = "greater")##
## 1-sample proportions test with continuity correction
##
## data: 100 out of 400, null probability 0.2
## X-squared = 5.9414, df = 1, p-value = 0.007395
## alternative hypothesis: true p is greater than 0.2
## 95 percent confidence interval:
## 0.2149649 1.0000000
## sample estimates:
## p
## 0.25检验p值为0.0074,小于检验水平0.05, 所以女性学员比例已经显著地高于过去的20%了。
用自定义的大样本Z检验函数prop.test.1s():
prop.test.1s(100, 400, p=0.20, alternative = "greater")## stat pvalue
## 2.500000000 0.006209665检验p值为0.0062,与基于卡方检验的prop.test()结果略有差别。
用基于二项分布的binom.test()检验:
binom.test(100, 400, p=0.20, alternative = "greater")##
## Exact binomial test
##
## data: 100 and 400
## number of successes = 100, number of trials = 400, p-value = 0.008595
## alternative hypothesis: true probability of success is greater than 0.2
## 95 percent confidence interval:
## 0.2146019 1.0000000
## sample estimates:
## probability of success
## 0.25p值为0.0086。
30.5.3 单个比例检验的样本量和功效
pwr包的pwr.p.test()函数可以进行单个比例假设检验的样本量和功效计算。 该函数用参数h指定要检验的比例差异大小, 这个比例差异的效应大小用ES.h()函数进行计算。 比如,H0:p=0.20, Ha:p=0.25, 则比例差异的效应大小为:
ES.h(p1 = 0.25, p2 = 0.20)## [1] 0.1199023效应大小的计算公式为((Cohen 1988)):
h=2arcsinp1‾‾√−2arcsinp2‾‾√.(30.1)
比例差异的常用值为:
- 小(small): h=0.2;
- 中(medium): h=0.5;
- 大(large): h=0.8。
公式(30.1)定义的比例差异效应大小与p1和p2的具体值有关系。 比如, 同样是p1−p2=0.05:
ES.h(p1 = 0.10, p2 = 0.05)## [1] 0.1924743这个效应比0.20和0.25的差异效应大了许多。 公式(30.1)考虑到了两个比例的相对差距, 而不仅是绝对差距。
给定效应大小、检验水平后, 可以给定样本量计算功效, 如:
pwr.p.test(
h = ES.h(p1 = 0.25, p2 = 0.20),
sig.level = 0.05,
alternative = "greater",
n = 400)##
## proportion power calculation for binomial distribution (arcsine transformation)
##
## h = 0.1199023
## n = 400
## sig.level = 0.05
## power = 0.774333
## alternative = greater功效为77%。 计算达到80%功效所需的样本量:
pwr.p.test(
h = ES.h(p1 = 0.25, p2 = 0.20),
sig.level = 0.05,
alternative = "greater",
power = 0.80)##
## proportion power calculation for binomial distribution (arcsine transformation)
##
## h = 0.1199023
## n = 430.044
## sig.level = 0.05
## power = 0.8
## alternative = greater所需样本量为431。
还可以图示功效与样本量的关系曲线:
pwr.p.test(
h = ES.h(p1 = 0.25, p2 = 0.20),
sig.level = 0.05,
alternative = "greater",
power = 0.80) |>
plot()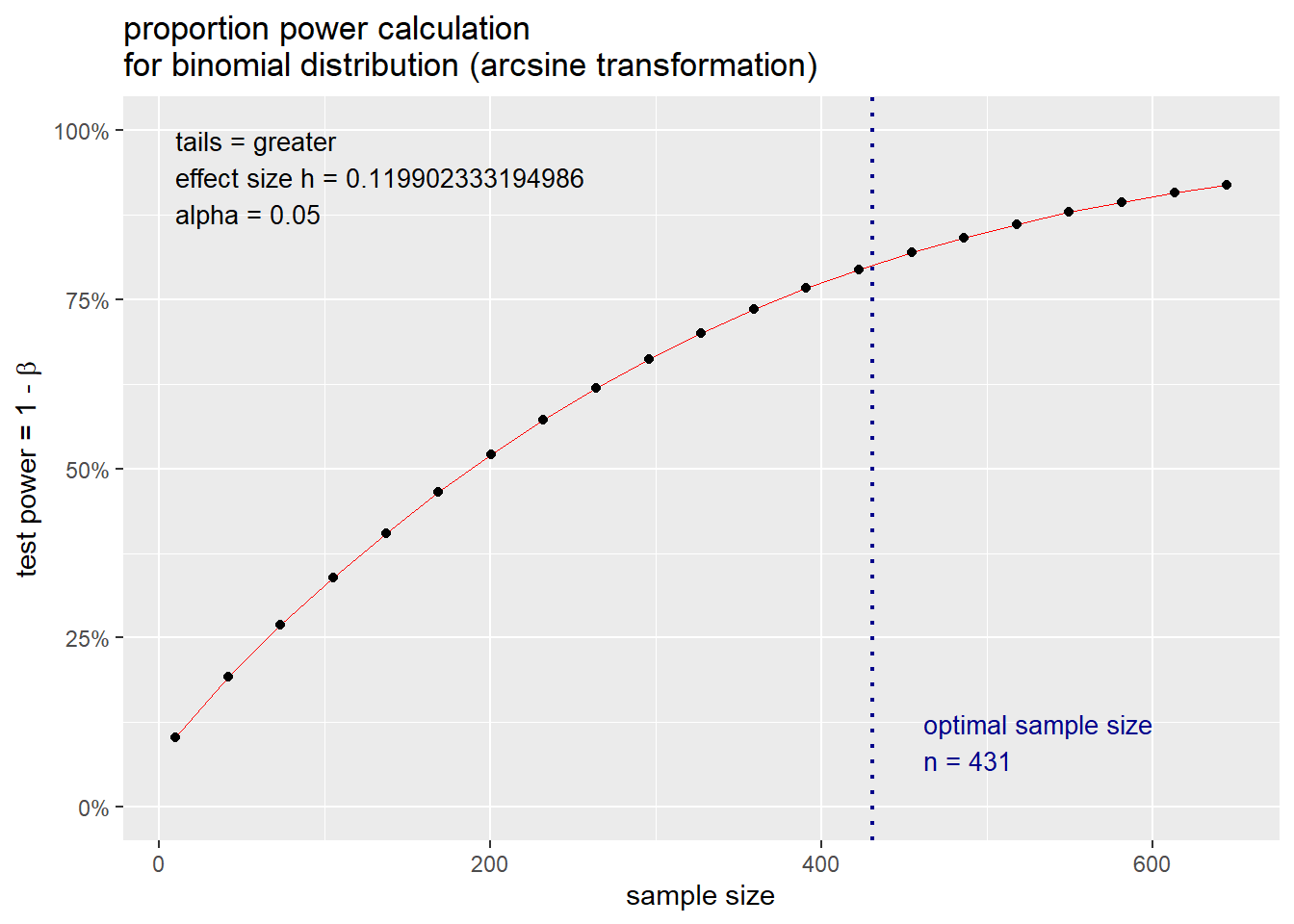
30.6 两个比例的比较
30.6.1 方法
设有X和Y两个独立的总体, 如男性和女性, 比较p1=P(X=1)和p2=P(Y=1)。
检验问题包括:
H0:p1=p2H0:p1≤p2H0:p1≥p2⟷Ha:p1≠p2⟷Ha:p1>p2⟷Ha:p1<p2
在大样本情况下, 可以用R函数 prop.test(c(nsucc1, nsucc2), c(n1,n2), alternative=...) 进行独立两样本比例的比较检验, 其中n1和n2是两个样本量, nsucc1和nsucc2是两个样本中符合特征的个数(个数除以样本量即样本中的比例), alternative的选择也是"two.sided"、"less"、"greater"。
还可以比较p1−p2与某个δ。 设两个总体中分别抽取了n1和n2个样本点, 样本比例分别为p̂ 1和p̂ 2。 估计共同的样本比例
p̂ =n1p̂ 1+n2p̂ 2n1+n2
当δ=0时取统计量
Z=p̂ 1−p̂ 2p̂ (1−p̂ )(1n1+1n2)‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√当p1=p2时Z在大样本情况下近似服从标准正态分布。 当δ≠0时取统计量
Z=p̂ 1−p̂ 2−δp̂ 1(1−p̂ 1)n1+p̂ 2(1−p̂ 2)n2‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√当p1−p2=δ时Z在大样本情况下近似服从N(0,1)分布。
可以定义Z检验R函数为:
prop.test.2s <- function(x, n, delta=0.0, alternative="two.sided"){
phat <- sum(x)/sum(n)
p <- x / n
if(delta==0.0){
zstat <- (p[1] - p[2])/sqrt(phat*(1-phat)*(1/n[1] + 1/n[2]))
} else {
zstat <- (p[1] - p[2] - delta)/sqrt(p[1]*(1-p[1])/n[1] + p[2]*(1-p[2])/n[2])
}
if(alternative=="two.sided"){ # 双侧检验
pvalue <- 2*(1 - pnorm(abs(zstat)))
} else if(alternative=="less"){ # 左侧检验
pvalue <- pnorm(zstat)
} else if(alternative=="greater"){ # 右侧检验
pvalue <- 1 - pnorm(zstat)
} else {
stop("alternative unknown!")
}
c(stat=zstat, pvalue=pvalue)
}独立两总体比例比较的小样本情形意义不大, 可考虑使用Fisher精确检验, R函数为fisher.test()。
30.6.2 报税代理分理处的错误率比较
某个代理报税的机构希望比较下属的两个分理处申报纳税返还的出错率。 各自随机选取取了n1=250和n2=300件申报, 第一个分理处错了35件,错误率p̂ 1=0.14; 第二个分理处错了27件,错误率p̂ 2=0.09。
作双侧检验,水平0.10。
用prop.test():
prop.test(c(35,27), c(250,300), alternative = "two.sided")##
## 2-sample test for equality of proportions with continuity correction
##
## data: c(35, 27) out of c(250, 300)
## X-squared = 2.9268, df = 1, p-value = 0.08712
## alternative hypothesis: two.sided
## 95 percent confidence interval:
## -0.007506845 0.107506845
## sample estimates:
## prop 1 prop 2
## 0.14 0.09p值0.087,有显著差异,第一处的错误率高。 因为比例需要较大样本量, 所以样本量不太大时, 有人用0.10这样的检验水平。
用自定义的prop.test.2s():
prop.test.2s(c(35,27), c(250,300), alternative = "two.sided")## stat pvalue
## 1.84618928 0.06486473使用Fisher精确检验:
fisher.test(
rbind(c(35, 250-35),
c(27, 300-27)),
alternative = "two.sided")##
## Fisher's Exact Test for Count Data
##
## data: rbind(c(35, 250 - 35), c(27, 300 - 27))
## p-value = 0.07809
## alternative hypothesis: true odds ratio is not equal to 1
## 95 percent confidence interval:
## 0.9345221 2.9208940
## sample estimates:
## odds ratio
## 1.644457fisher.test()要求输入2×2矩阵, 两行分别为两组的成功数和失败数。 上面的检验结果p值为0.078, 在0.10水平下两个比例有显著差异。
30.6.3 比例比较的样本量
如果预先近似估计了两个总体的比例分别约为p1和p2, 则检验两个比例有无显著差距所需的样本量可以利用power.prop.test()计算, 如:
power.prop.test(
power = 0.80,
sig.level = 0.05,
p1 = 0.15, p2 = 0.30 )##
## Two-sample comparison of proportions power calculation
##
## n = 120.4719
## p1 = 0.15
## p2 = 0.3
## sig.level = 0.05
## power = 0.8
## alternative = two.sided
##
## NOTE: n is number in *each* group输出的样本量是每组需要的样本量。 结果表明每组需要n=121个观测。
也可以给定样本量计算功效,如:
power.prop.test(
n = 100,
sig.level = 0.05,
p1 = 0.15, p2 = 0.30 )##
## Two-sample comparison of proportions power calculation
##
## n = 100
## p1 = 0.15
## p2 = 0.3
## sig.level = 0.05
## power = 0.7222795
## alternative = two.sided
##
## NOTE: n is number in *each* group功效为72%。
pwr包的pwr.2p.test()函数可以进行比例比较的样本量和功效计算。 如:
pwr.2p.test(
h = ES.h(p1 = 0.30, p2 = 0.15),
power = 0.80,
sig.level = 0.05)##
## Difference of proportion power calculation for binomial distribution (arcsine transformation)
##
## h = 0.3638807
## n = 118.5547
## sig.level = 0.05
## power = 0.8
## alternative = two.sided
##
## NOTE: same sample sizes需要各自119个观测。
计算中等比例差异效应的样本量:
pwr.2p.test(
h = 0.5,
power = 0.80,
sig.level = 0.05)##
## Difference of proportion power calculation for binomial distribution (arcsine transformation)
##
## h = 0.5
## n = 62.79088
## sig.level = 0.05
## power = 0.8
## alternative = two.sided
##
## NOTE: same sample sizes需要各自63个观测值。 注意需要检测的比例差异效应越大, 需要的样本量就越小。
实际上, 当要比较的两个样本样本量不同时, 可以用pwr.2p2n.test()函数来计算功效, 将n=选项替换成n1=和n2=选项。 比如, n1=250, n2=300, 检验小的比例差异效应:
pwr.2p2n.test(
h = 0.2,
n1 = 250, n2 = 300,
sig.level = 0.05)##
## difference of proportion power calculation for binomial distribution (arcsine transformation)
##
## h = 0.2
## n1 = 250
## n2 = 300
## sig.level = 0.05
## power = 0.6463766
## alternative = two.sided
##
## NOTE: different sample sizes也可以给定功效以及n1,求n2:
pwr.2p2n.test(
h = 0.2,
n1 = 250,
power = 0.8,
sig.level = 0.05)##
## difference of proportion power calculation for binomial distribution (arcsine transformation)
##
## h = 0.2
## n1 = 250
## n2 = 912.1748
## sig.level = 0.05
## power = 0.8
## alternative = two.sided
##
## NOTE: different sample sizesn2为913。
30.7 方差的假设检验和置信区间
30.7.1 单总体方差的假设检验和置信区间
方差和标准差是总体的重要数字特征, 在金融应用中标准差代表波动率, 在工业生产中标准差也是重要的质量指标, 如机床加工精度可以用标准差表示。
对总体方差σ2可以做双侧、左侧、右侧检验, 与某个σ20比较。
设总体为正态总体,检验问题:
H0:H0:H0:σ2=σ20⟷Ha:σ2≠σ20σ2≥σ20⟷Ha:σ2<σ20σ2≤σ20⟷Ha:σ2>σ20
可以用如下的自定义函数计算单正态总体方差的检验:
var.test.1s <- function(x, n=length(x), var0, alternative="two.sided"){
if(length(x)==1){ # 输入的是方差
varx <- x
} else {
varx <- var(x)
}
xi <- (n-1)*varx/var0
if(alternative=="less"){
pvalue <- pchisq(xi, n-1)
} else if (alternative=="right"){
pvalue <- pchisq(xi, n-1, lower.tail=FALSE)
} else if(alternative=="two.sided"){
pvalue <- 2*min(pchisq(xi, n-1), pchisq(xi, n-1, lower.tail=FALSE))
}
c(statistic=xi, pvalue=pvalue)
}可以输入样本数据到x中, 输入σ20到var0中, 进行检验; 也可以输入S2到x中,输入样本量n到n中, 输入σ20到var0中, 进行检验。
30.7.2 独立两总体方差的比较
设两个独立的正态总体的方差分别为σ21, σ22, 有双侧、左侧、右侧检验:
H0:H0:H0:σ21=σ22⟷Ha:σ21≠σ22σ21≥σ22⟷Ha:σ21<σ22σ21≤σ22⟷Ha:σ21>σ22
设两个总体分别抽取n1和n2个样本点, 样本方差分别为S2x和S2y。
检验统计量
F=S2xS2y
在σ21=σ22时F服从F(n1−1,n2−1)分布。
如果输入x, y为两个样本的具体值, 可以用var.test(x, y, alternative=...)检验, 其中alternative的选择是"two.sided"、"less"、"greater"。
var.test()假定总体都服从正态分布。 R中mood.test()是一种不要求正态分布假定的检验方法。 bartlett.test()检验多个独立正态总体方差是否全相等。
30.7.3 方差检验例子
例: 某车间生产铜丝, 生产一向比较稳定。 为了检查生产工艺是否受控, 从产品中随机抽取10根铜丝检查其折断力, 得数据如下:
578,572,570,568,572,570,570,572,596,584.
问:从样本看, 能否认为折断力指标的标准差保持在以往的8.0水平?
用前面的自定义函数进行方差的卡方检验, 作双侧检验:
var.test.1s(x = c(
578, 572, 570, 568, 572,
570, 570, 572, 596, 584),
var0 = 64,
alternative = "two.sided")## statistic pvalue
## 10.6500000 0.6009287检验p值为0.60, 在0.05水平下不拒绝零假设, 可认为生产工艺水平受控。
例: 某车间要比较在两种不同温度下生产的针织品断裂强度。 设两种温度下分别抽取的产品样品断裂强度如下:
70℃80℃20.5,18.8,19.8,20.9,21.5,19.5,21.0,21.217.7,20.3,20.0,18.8,19.0,20.1,20.2,19.1
问:两种温度下断裂强度的方差有误显著差异?
用var.test():
var.test(c(
20.5, 18.8, 19.8, 20.9, 21.5, 19.5, 21.0, 21.2), c(
17.7, 20.3, 20.0, 18.8, 19.0, 20.1, 20.2, 19.1),
alternative = "two.sided")##
## F test to compare two variances
##
## data: c(20.5, 18.8, 19.8, 20.9, 21.5, 19.5, 21, 21.2) and c(17.7, 20.3, 20, 18.8, 19, 20.1, 20.2, 19.1)
## F = 1.069, num df = 7, denom df = 7, p-value = 0.9322
## alternative hypothesis: true ratio of variances is not equal to 1
## 95 percent confidence interval:
## 0.214011 5.339386
## sample estimates:
## ratio of variances
## 1.068966检验p值为0.93, 在0.05水平下不拒绝零假设, 认为两种温度下的断裂强度的方差没有显著差异。
30.8 拟合优度检验
30.8.1 各类比例相等的检验
设类别变量X有m个不同类别, 抽取n个样本点后, 各类的频数分别为f1,f2,…,fm。
零假设为所有类的比例相同; 对立假设为各类比例不完全相同。
在零假设下,每个类的期望频数为n/m。
检验统计量为
χ2=∑i=1m(fi−nm)2nm
当χ2超过某一临界值时拒绝零假设。 在H0成立且大样本情况下χ2统计量近似服从χ2(m−1)分布 (自由度为组数减1)。
设x中包含各类的频数, R函数chisq.test(x)作各类的总体比例相等的拟合优度卡方检验。
例: 投掷一枚骰子1000次, 一点到六点的出现次数分别为: 168, 159, 168, 180, 167, 158, 问这枚骰子是否均匀?
解答: 利用chisq.test()函数,得
chisq.test(c(168, 159, 168, 180, 167, 158))##
## Chi-squared test for given probabilities
##
## data: c(168, 159, 168, 180, 167, 158)
## X-squared = 1.892, df = 5, p-value = 0.8639卡方统计量等于1.892, 零假设下服从χ2(5)分布, p值为0.8639, 结果不显著, 不拒绝零假设, 认为六个面的概率相等, 骰子是均匀的。
library(ggstatsplot)
ggpiestats(
data = data.frame(face=1:6,
counts=c(168, 159, 168, 180, 167, 158)),
x = face,
counts = counts,
title = "Dice equality"
)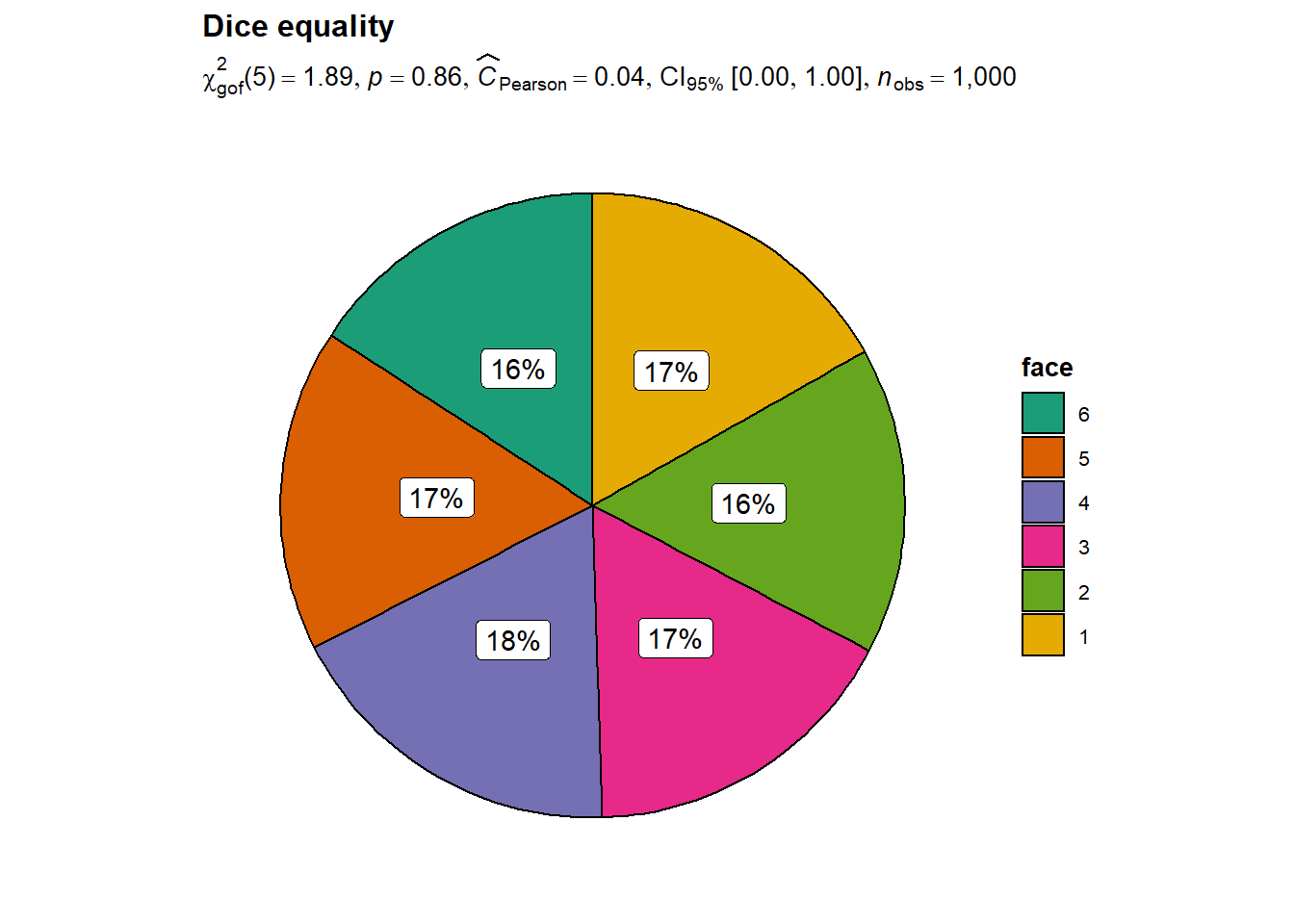
30.8.2 各类比例为指定值的检验
设分类变量X的各类每类有一个总体比例的假设, 希望作为零假设检验。
设共有m个类,在零假设中, 各类的比例分别为p1,p2,…,pm。
取了n个样本点组成的样本, 各类的频数分别为f1,f2,…,fm, 期望频数分别为np1,np2,…,npm。
检验统计量为
χ2=∑i=1m(fi−npi)2npi
在H0下成立且大样本情况下χ2近似服从χ2(m−1), 自由度为组数减1。 因为是大样本检验法, 每个组的期望频数不能低于5, 否则可以合并较小的类。
设x中包含各类的频数, p中包含H0假定的各类的概率, R函数chisq.test(x, p)作各类的总体比例为指定概率的拟合优度卡方检验。
例: 市场占有率的检验例子
某类产品的当前市场占比为公司A占30%, 公司B占50%,公司C占20%。 近期C公司推出了新产品代替本公司的老产品, 公司C委托一个咨询公司调查分析新产品是否导致了市场占有率的变动。 抽查了200位消费者, 购买三个公司的产品的人数分配为:
(48,98,54).
设p1,p2,p3分别为三个公司现在的市场占有率,零假设为:
H0:p1=0.30, p2=0.50, p3=0.20
取检验水平0.05。
卡方统计量
χ2=(48−200×0.3)2200×0.3+(98−200×0.5)2200×0.5+(54−200×0.2)2200×0.2=7.34
p值=P(χ2(3−1)>7.34)=0.02548, 拒绝零假设, 认为市场占有率有变化。
用chisq.test()计算:
chisq.test(c(48, 98, 54), p=c(0.3, 0.5, 0.2))##
## Chi-squared test for given probabilities
##
## data: c(48, 98, 54)
## X-squared = 7.34, df = 2, p-value = 0.02548p值为0.025,在0.05水平下显著, 可以认为市场占有率有显著变化。
注意, 因为卡方检验本身也是利用了大样本近似分布, 所以p值结果本身就是近似地, 一般仅使用一到两位有效数字, 不要报告过多有效数字。
30.8.3 带有未知参数的单分类变量的拟合优度假设检验
如果H0下的概率有未知参数, 先用最大似然估计法估计未知参数, 然后将未知参数代入计算各类的概率, 从而计算期望频数, 计算卡方统计量。 求p值时自由度要改为“组数减1减去未知参数个数”。
例: 设某次选举有5位候选人, 其中呼声最高的是甲和乙。 问:甲、乙的支持率相等吗?
这不能用独立的两个比例的比较来解决, 因为这两个比例是互斥的, 不属于独立情况。
将类别简化为:甲,乙,其他。 零假设为“甲、乙的支持率都等于p, 其他三位候选人的支持率为1−2p,p未知”; 对立假设是甲、乙的支持率不相等。
假设调查了1000位选民, 其中300名支持甲,200名支持乙,500名支持其他三位候选人。
在假定零假设成立的情况下先用最大似然估计法估计未知参数p: p̂ =(300+200)/1000/2=0.25。 这样,三个类的概率估计为(0.25,0.25,0.50)。
然后,计算检验统计量:
chisq.test(c(300, 200, 500), c(0.25, 0.25, 0.50))## Warning in chisq.test(c(300, 200, 500), c(0.25, 0.25, 0.5)): Chi-squared
## approximation may be incorrect##
## Pearson's Chi-squared test
##
## data: c(300, 200, 500) and c(0.25, 0.25, 0.5)
## X-squared = 3, df = 2, p-value = 0.2231其中的p值所用的自由度错误,我们需要自己计算p值:
res <- chisq.test(c(300, 200, 500), c(0.25, 0.25, 0.50))## Warning in chisq.test(c(300, 200, 500), c(0.25, 0.25, 0.5)): Chi-squared
## approximation may be incorrectc(statistic=res$statistic,
pvalue=pchisq(res$statistic, res$parameter - 1,
lower.tail=FALSE))## statistic.X-squared pvalue.X-squared
## 3.00000000 0.08326452检验p值为0.08而非原来的0.22。 在0.05水平下不显著, 结论为两个候选人的支持率没有显著差异。
30.8.4 拟合优度检验的功效和样本量
pwr包可以计算拟合优度检验的功效和样本量。
30.8.4.1 市场占有率例子
考虑前面的市场占有率的例子。 零假设为:
H0:p1=0.30, p2=0.50, p3=0.20.
设要计算功效的对立假设的具体情况是:
H1:p1=0.24, p2=0.49, p3=0.27.据此先计算卡方检验的效应, 使用ES.w1()函数:
null <- c(0.30, 0.50, 0.20)
alt <- c(0.24, 0.49, 0.27)
ES.w1(null, alt)## [1] 0.1915724卡方检验效应大小的常用取值为:
- 小:0.1;
- 中: 0.3;
- 大: 0.5。
所以0.19属于中小规模的效应,需要较大样本量。 计算功效大小:
pwr.chisq.test(
w = ES.w1(null, alt),
N = 200,
df = 3-1,
sig.level = 0.05)##
## Chi squared power calculation
##
## w = 0.1915724
## N = 200
## df = 2
## sig.level = 0.05
## power = 0.677598
##
## NOTE: N is the number of observations功效为68%。 计算达到80%功效所需样本量:
pwr.chisq.test(
w = ES.w1(null, alt),
power = 0.80,
df = 4-1,
sig.level = 0.05)##
## Chi squared power calculation
##
## w = 0.1915724
## N = 297.0726
## df = 3
## sig.level = 0.05
## power = 0.8
##
## NOTE: N is the number of observations样本量为297。
计算中等大小的效应以及80%功效所需样本量:
cohen.ES(test = "chisq", size = "medium")##
## Conventional effect size from Cohen (1982)
##
## test = chisq
## size = medium
## effect.size = 0.3pwr.chisq.test(
w = 0.3,
power = 0.80,
df = 4-1,
sig.level = 0.05)##
## Chi squared power calculation
##
## w = 0.3
## N = 121.1396
## df = 3
## sig.level = 0.05
## power = 0.8
##
## NOTE: N is the number of observations中等的效应大小只需要122个观测。
30.8.4.2 候选人例子
考虑前面的5个候选人的例子。 将第3、4、5位候选人合并为一类。 零假设为:
H0:p1=p2=p,p3=1−2p.
其中p是未知参数。 为了计算功效, 需要给出对立假设下的一个具体分布。 这里仅指定要检验中等的效应。 于是功效为:
pwr.chisq.test(
w = 0.3,
N = 1000,
df = 3-1-1,
sig.level = 0.05)##
## Chi squared power calculation
##
## w = 0.3
## N = 1000
## df = 1
## sig.level = 0.05
## power = 1
##
## NOTE: N is the number of observations功效为100%, 所以中等大小的效应用1000个样本点过于充裕了。
如果按实际数据作为对立假设下的实际分布, 对应的效应大小为:
null <- c(0.25, 0.25, 0.50)
alt <- c(0.30, 0.30, 0.50)
ES.w1(null, alt)## [1] 0.1414214这也对应于较小的效应, 意味着较低的功效或者较大的样本量。 比如, 功效为:
pwr.chisq.test(
w = ES.w1(null, alt),
N = 1000,
df = 3-1-1,
sig.level = 0.05)##
## Chi squared power calculation
##
## w = 0.1414214
## N = 1000
## df = 1
## sig.level = 0.05
## power = 0.9940005
##
## NOTE: N is the number of observations因为样本量很大,所以功效达到了99%。 计算达到80%功效所需样本量:
pwr.chisq.test(
w = ES.w1(null, alt),
power = 0.80,
df = 3-1-1,
sig.level = 0.05)##
## Chi squared power calculation
##
## w = 0.1414214
## N = 392.443
## df = 1
## sig.level = 0.05
## power = 0.8
##
## NOTE: N is the number of observations需要的样本量为393。
30.9 检验分布类型
vcd包提供了一个goodfit函数, 可以用来拟合指定的某种理论分布(包括泊松、二项、负二项分布), 并检验服从该理论分布的零假设。
例如,我们生成一组速率参数为2的泊松随机数, 检验其分布是否泊松分布:
library(vcd)## Loading required package: gridset.seed(101)
datax <- rpois(100, 2)
summary(goodfit(datax, "poisson"))##
## Goodness-of-fit test for poisson distribution
##
## X^2 df P(> X^2)
## Likelihood Ratio 4.289456 5 0.5085374检验其是否服从二项分布,取二项分布试验数为10:
summary(goodfit(datax, "binomial", par = list(size = 10)))##
## Goodness-of-fit test for binomial distribution
##
## X^2 df P(> X^2)
## Likelihood Ratio 5.052451 5 0.4095126与二项分布也相容。 在检验分布类型时, 这种两种分布都不能拒绝的情况是常见的。
30.10 列联表独立性卡方检验
30.10.1 检验方法
设分类变量X有m个类, 分类变量Y有k个类, 随机抽取了样本量为n的样本, 设X的第i类与Y的第j类交叉的频数为fij。
零假设为X与Y相互独立, 即行变量与列变量相互独立。
交叉频数列成列联表形式,第i行第j列为fij。 共有mk个单元格, 将这mk个单元格的频数值看成是来自有mk个类别的多项分布的样本的频数结果。 注意, 如果样本不是随机抽取, 而是按照X或者安装Y分类观察或者试验得到的, 结果就不能看作是来自mk个类别的多项分布样本, 这里的方法就不适用。
第i行的行和为fi⋅, X的第i类的百分比为ri=fi⋅/n;
第j列的列和为f⋅j, Y的第j类的百分比为cj=f⋅j/n。
当X, Y独立时, (i,j)格子的期望频数为 Eij=n×ri×cj。
列联表独立性检验统计量
χ2=∑i=1m∑j=1k(fij−Eij)2Eij
其中Eij=nricj, ri为X第i类的百分比, cj为Y第j类的百分比。
在H0下χ2近似服从(m−1)(k−1)自由度的卡方分布。 设统计量值为c, p值为P(χ2((m−1)(k−1))>c)。
如果x, y分别是两个变量的原始观测值, chisq.test(x, y)可以做列联表独立性检验。 如果x保存了矩阵格式的列联表, 矩阵行名是X各个类的名称, 矩阵列名是Y各个类的名称, 则chisq.test(x)可以做列联表独立性检验。
列联表卡方检验法的检验统计量在零假设下的卡方分布是大样本情况的近似分布。 如果每个变量仅有两个类,每个类的期望频数不能少于5; 如果有多个单元格,期望频数少于5的单元格的个数不能超过20%, 否则应该合并较小的类。
如果列联表的数据不是来自于总数n固定的随机抽样, 而是按照X变量分组抽取的, 这时零假设就变成了m个独立的总体的多项分布是否相同的问题, 这个问题恰好也可以使用上面的卡方统计量, 近似分布的自由度不变。 如果数据按Y变量分组抽取也一样。
30.10.2 列联表独立性卡方检验例子
30.10.2.1 性别与啤酒种类的独立性检验
Alber’s Brewery of Tucson, Arizona是啤酒制造与销售商。 有三类啤酒产品:淡啤酒,普通啤酒,黑啤酒。
了解不同顾客喜好有利于制定更精准的销售策略。 希望了解男女顾客对不同类型的偏好有没有显著差异, 实际就是检验性别与啤酒类型偏好的独立性。
随机抽取了150位顾客, 得到如下的列联表:
ctab.beer <- rbind(c(
20, 40, 20),
c(30,30,10))
colnames(ctab.beer) <- c("Light", "Regular", "Dark")
rownames(ctab.beer) <- c("Male", "Female")
addmargins(ctab.beer)## Light Regular Dark Sum
## Male 20 40 20 80
## Female 30 30 10 70
## Sum 50 70 30 150列联表独立性检验:
chisq.test(ctab.beer)##
## Pearson's Chi-squared test
##
## data: ctab.beer
## X-squared = 6.1224, df = 2, p-value = 0.04683在0.05水平下认为啤酒类型偏好与性别有关。 男性组的偏好分布、女性组的偏好分布、所有人的偏好分布:
tab2 <- round(prop.table(addmargins(ctab.beer, 1), 1), 3)
rownames(tab2)[3] <- "All"
tab2## Light Regular Dark
## Male 0.250 0.500 0.250
## Female 0.429 0.429 0.143
## All 0.333 0.467 0.200可以看出男性中对淡啤酒偏好偏少, 女性中对淡啤酒偏好偏多。
30.10.3 功效与样本量计算
在上述啤酒种类偏好的例子中, 假设要在0.01水平下检验出中等的效应大小, 样本量N=150, 计算其功效如下:
cohen.ES(test = "chisq", size = "medium")##
## Conventional effect size from Cohen (1982)
##
## test = chisq
## size = medium
## effect.size = 0.3pwr.chisq.test(
w = 0.3,
N = 150,
df = (2-1)*(3-1),
sig.level = 0.05)##
## Chi squared power calculation
##
## w = 0.3
## N = 150
## df = 2
## sig.level = 0.05
## power = 0.9185674
##
## NOTE: N is the number of observations功效为92%。
如果明确指定了对立假设, 则可以用ES.w2()计算所对应的效应大小。 比如, 零假设是性别与啤酒种类独立, 而对立假设是性别与偏好的如下概率分布:
Gender∖BeerMaleFemaleLight2/153/15Regular4/153/15Dark2/151/15
就需要按此计算要检验的效应大小:
dist_tab <- matrix(
c(2, 4, 2,
3, 3, 1)/15,
byrow=TRUE, ncol=3,
dimnames = list(
c("Male", "Female"),
c("Light", "Regular", "Dark")))
dist_tab## Light Regular Dark
## Male 0.1333333 0.2666667 0.13333333
## Female 0.2000000 0.2000000 0.06666667ES.w2(dist_tab)## [1] 0.2020305计算此效应大小对应的功效:
pwr.chisq.test(
w = ES.w2(dist_tab),
N = 150,
df = (2-1)*(3-1),
sig.level = 0.05)##
## Chi squared power calculation
##
## w = 0.2020305
## N = 150
## df = 2
## sig.level = 0.05
## power = 0.5932776
##
## NOTE: N is the number of observations因为要发现的效应更小, 所以达到的功效(59%)较低。 这说明, 如果啤酒偏好数据中反映的比例是真实情况的话, 实际上有41%的概率会不拒绝零假设。
计算达到80%功效所需的样本量:
pwr.chisq.test(
w = ES.w2(dist_tab),
power = 0.80,
df = (2-1)*(3-1),
sig.level = 0.05)##
## Chi squared power calculation
##
## w = 0.2020305
## N = 236.0499
## df = 2
## sig.level = 0.05
## power = 0.8
##
## NOTE: N is the number of observations需要的样本量为236。
30.11 非参数检验
常用的有独立两样本比较的Wilcoxon秩和检验, 单样本的符号秩检验和符号检验等,
30.11.1 单样本的符号秩检验
wilcox.test(x, mu)进行符号秩检验, 适用于非正态总体, 检验H0:μ=μ0。
例如, Heathrow机场打分是否在7分以上的检验:
wilcox.test(AirRating[["Rating"]], mu=7, alternative="greater")## Warning in wilcox.test.default(AirRating[["Rating"]], mu = 7, alternative =
## "greater"): cannot compute exact p-value with ties## Warning in wilcox.test.default(AirRating[["Rating"]], mu = 7, alternative =
## "greater"): cannot compute exact p-value with zeroes##
## Wilcoxon signed rank test with continuity correction
##
## data: AirRating[["Rating"]]
## V = 457, p-value = 0.0469
## alternative hypothesis: true location is greater than 7p值为0.047, 在0.05水平下拒绝原假设, 认为打分显著超过7分。
非参数检验一般功效较低, 这里的p值0.047就比用t检验得到的0.035的p值大一些。 p值越大, 越不容易得到显著的检验结果。
30.11.2 独立两样本比较的Wilcoxon秩和检验
wilcox.test(x, y)可以对独立两组进行位置参数的比较, 这是一个非参数检验。
例如, 对两个银行营业所顾客平均存款的比较:
wilcox.test(CheckAcct[[1]], CheckAcct[[2]],
alternative = "two.sided")## Warning in wilcox.test.default(CheckAcct[[1]], CheckAcct[[2]], alternative =
## "two.sided"): cannot compute exact p-value with ties##
## Wilcoxon rank sum test with continuity correction
##
## data: CheckAcct[[1]] and CheckAcct[[2]]
## W = 447, p-value = 0.00679
## alternative hypothesis: true location shift is not equal to 0p值为0.007, 小于0.05, 两个营业所的顾客平均存款有显著差异。
30.11.3 成对比较的Wilcoxon配对检验
对成对比较问题, 可以计算两个变量的差进行符号秩检验, 称为Wilcoxon配对检验。
例如,同一组工人比较两种工艺的时间的问题:
wilcox.test(Matched[["Method 1"]], Matched[["Method 2"]],
paired=TRUE, alternative = "two.sided")## Warning in wilcox.test.default(Matched[["Method 1"]], Matched[["Method 2"]], :
## cannot compute exact p-value with zeroes##
## Wilcoxon signed rank test with continuity correction
##
## data: Matched[["Method 1"]] and Matched[["Method 2"]]
## V = 14, p-value = 0.1056
## alternative hypothesis: true location shift is not equal to 0p值为0.11, 超过0.05, 认为两种工艺时间的差异不显著。
References
Cohen, J. 1988. Statistical Power Analysis for the Behavioral Sciences. 2nd ed. Routledge. https://doi.org/https://doi.org/10.4324/9780203771587.
Kabacoff, Robert I. 2012. R语言实战. 人民邮电出版社.
Venables, W. N., and B. D. Ripley. 2002. Modern Applied Statistics with s. 4th Ed. Springer.
韭菜热线原创版权所有,发布者:风生水起,转载请注明出处:https://www.9crx.com/79364.html




