

介绍
支持向量机是1990年代由计算机科学家发明的一种有监督学习方法,
使用范围较广,预测精度较高。
最大分隔边界判别法
分隔超平面
对因变量为两分类的情形,
设自变量
如果存在曲面将
使得两类的样本可以分开,
就有了一种简单的判别准则。
超平面是最简单的分隔曲面。
在平面空间
超平面就是直线,其方程为
其中
在平面空间
分别满足
可以用其方程的法向
设
而点
则利用
两式相减得
用
则
即从平面上的点
即即从平面上的点
例如,考虑分隔线
法线方向为
上面的一个点
参见图44.1。
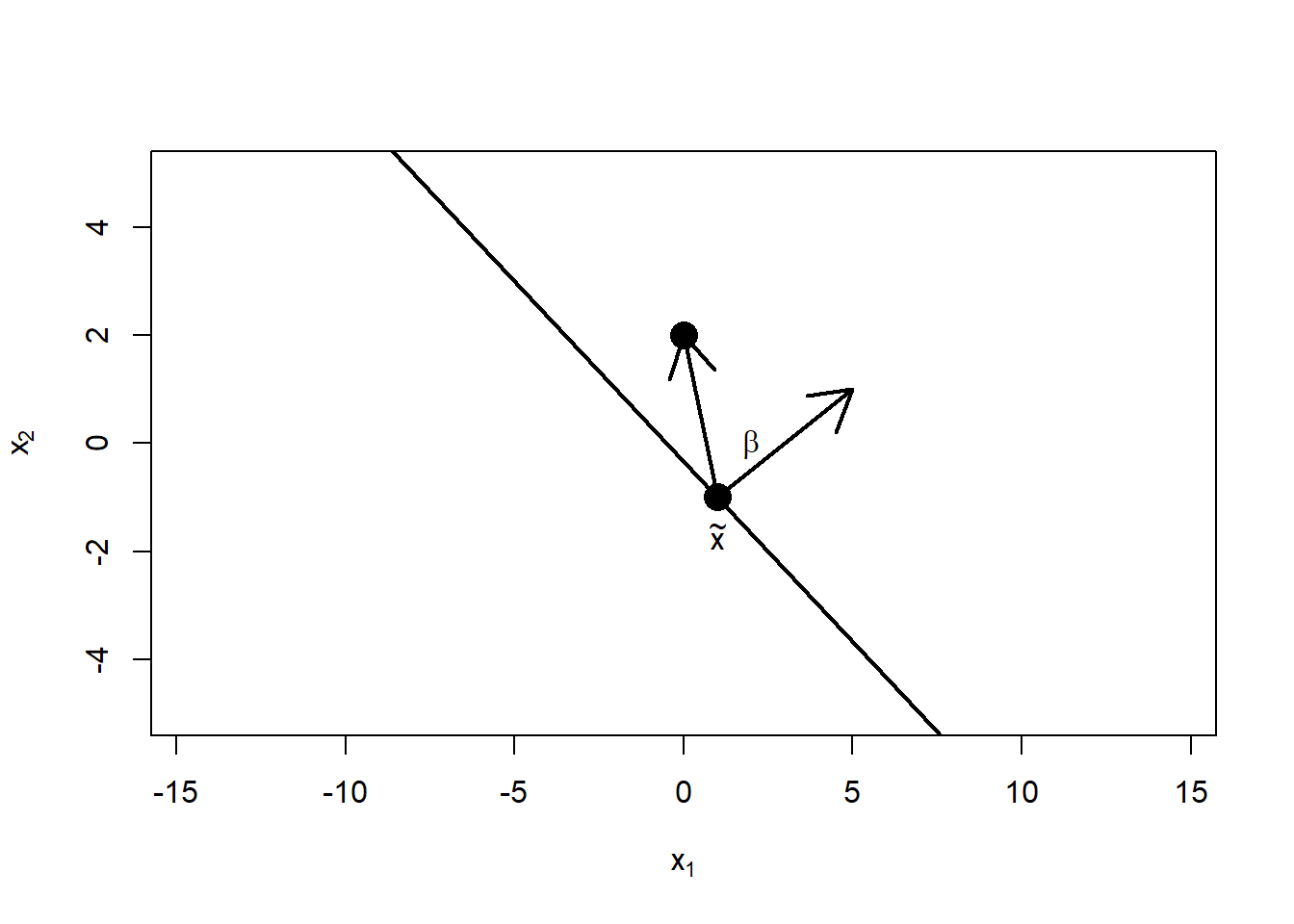

图44.1: 直线将平面分为两部分
对于自变量
可以定义分隔超平面:
将
两个空间的点可以用分隔超平面上的一个点
即内积
设两类判别问题的自变量数据保存为矩阵
其中的每一行为
对应于每个点有一个
设法找到一个超平面将两类的点分开在两边。
例如,
在图44.2中,
要区分蓝色和粉红色的点。
在左图中有三条直线都可以分开两种点。
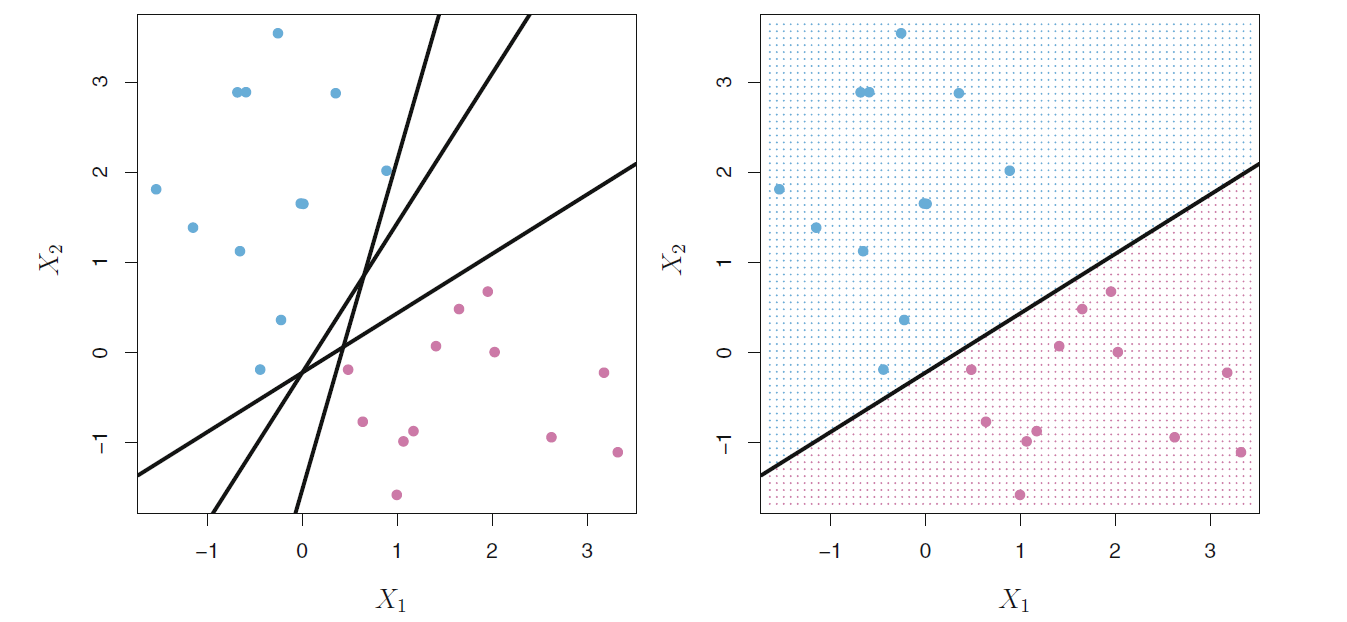
图44.2: 分隔线选择
找到的分隔线必须满足
可以统一地写成
这种要求可以推广到
即找到超平面使得
当分隔超平面存在时,
就可以用
对一个待判别的观测
计算
就可以判别
绝对值越大时,
判决越可靠。
如果
则点
对其判决不够可信。
最大分隔边界超平面
如图44.2的左图所示,
只要分隔超平面能分隔开训练集的样本点,
就不止有一个分隔超平面。
需要找到最优的分隔超平面。
想法是让两类的点都尽可能远离分隔面。
对某个候选的分隔超平面,
计算各个观测样本点到超平面的距离并求出最近距离,
称为margin(分隔边界)。
从所有的分隔超平面中求margin最大的一个
(见图44.3),
用这个最大边界的超平面作为判决准则,
这种方法称为最大分隔边界判别法(maximal margin classifier)。
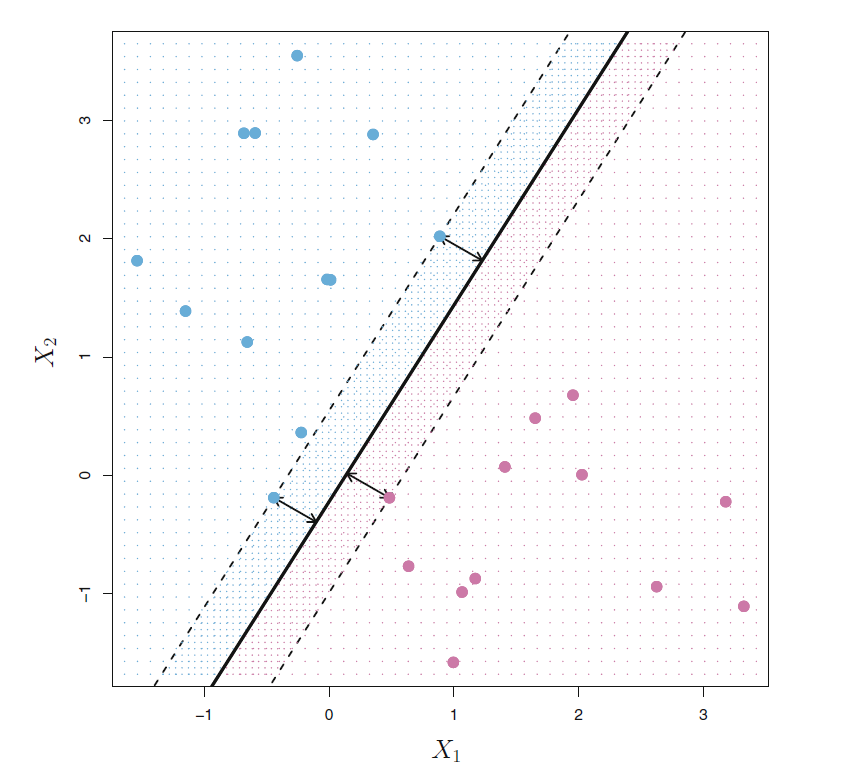
图44.3: 分隔边界
在图44.3中,
有三个观测点到最优超平面的距离相等,都等于最大分隔边界(margin),
这样的点称为支持向量(support vector)。
这些点改变位置会使得分隔线改变位置,
而其它点轻微改变位置则不会使得分隔线改变位置,
除非其它点到分隔线的距离小于分隔边界了。
这是最大分隔边界判别法以及后面讲到的支持向量机方法的重要性质。
支持向量判别法
问题
要求分隔超平面将两类完全分开有时不能做到,
即使能做到,
因为最大分隔边界超平面的选取过于依赖于边界处的支持向量,
几个点对结果的影响过大,
结果不够稳健,
也容易造成过度拟合。
见图44.5,
右图中增加一个点后,分隔线偏离了很多,
分隔边界变得很窄而且对原有点的判别效果变差了。
各个点距离边界越远,判别效果越好。
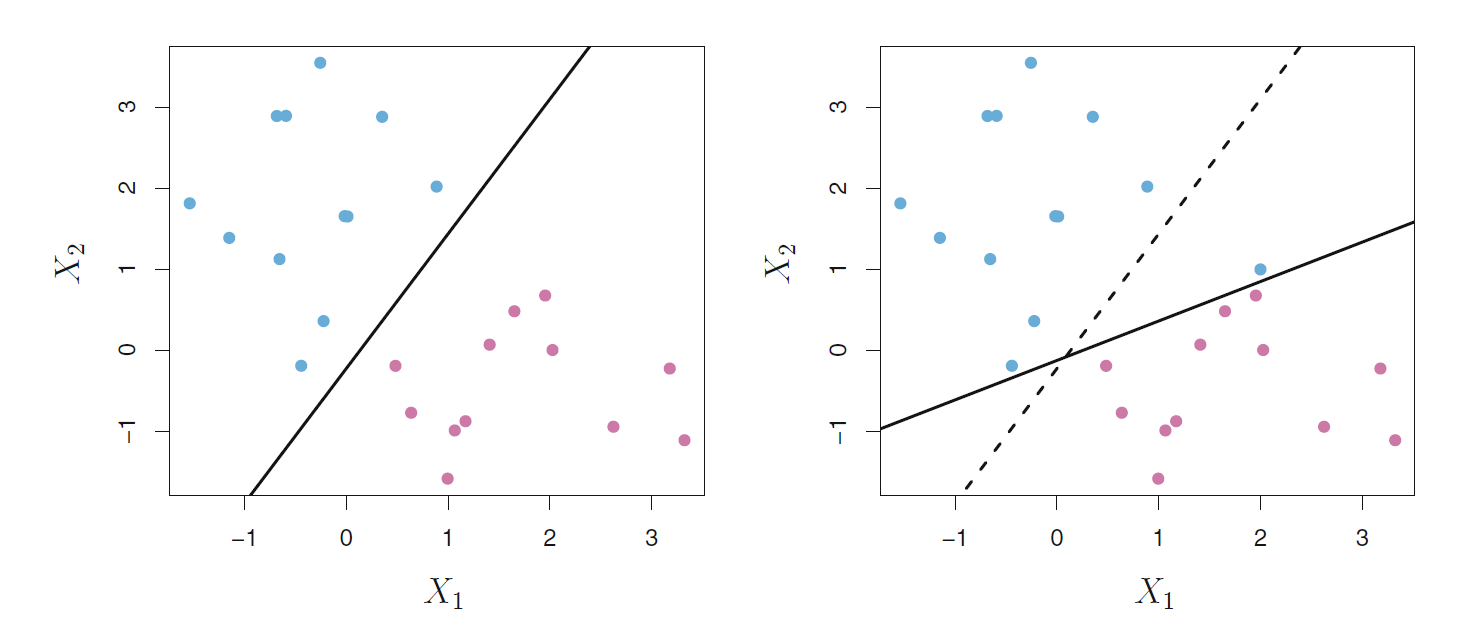
图44.5: 分隔超平面的不稳健性
解决这个问题的办法是,
不严格要求能够区分所有点,
而是将大多数点区分好,
结果更具有稳健性,
有少数点可以落在边界区域,
甚至于落入分隔超平面的错误一面。
这种方法称为支持向量判别法,
或者软分隔边界法。
见图44.6,
左图中的1号和8号点进入了分隔区域,
右图中的1号和8号点进入了分隔区域,
11和12号点进入了错误的一面。
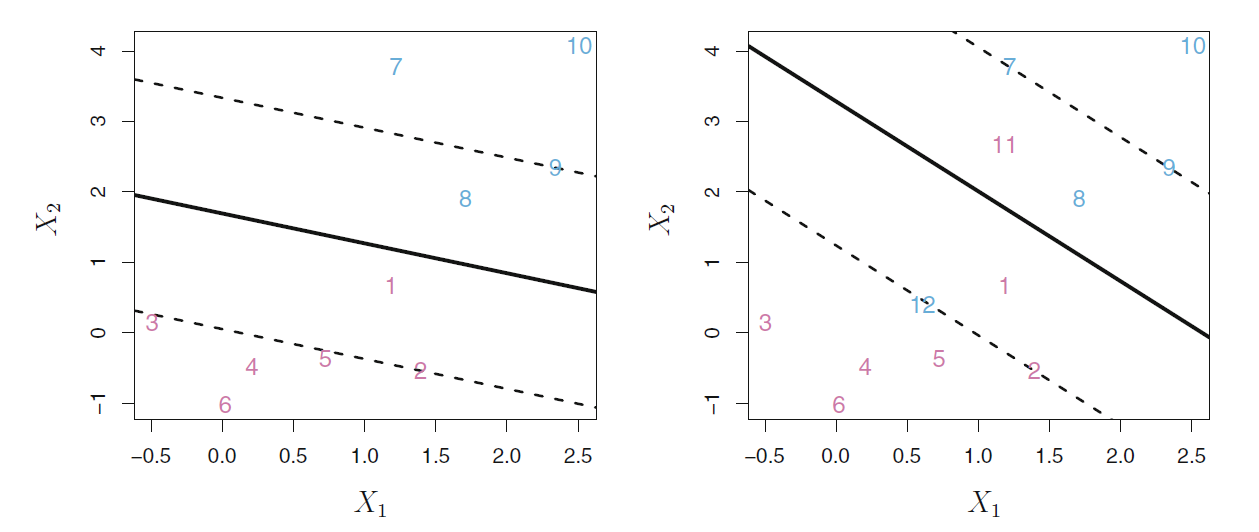
图44.6: 软分隔边界演示
支持向量判别法
支持向量判别法仍然求出一个分隔超平面,
对待判的观测点,
按其在超平面的那一面判决其类属。
超平面的求法使用软分隔边界,
表述为如下的优化问题:
其中
容许进入边界和错判的点的比例越大。
使得对点在分割边界以外的要求略微放宽。
求得上述优化问题的解以后,
对新的观测
只要计算函数
以
优化问题中的
如果
则软分隔规则对第
第
例如图44.6右图的3, 4, 5, 6,10和2, 7, 9号点。
当
第
如第1,8号点。
当
第
如第11, 12号点。
调节参数
当
不能有任何点在错误一侧,
也不能进入分隔边界区域。
对
至多有
增大
解出的边界宽度也会增大。
见图44.7,
各图形对应的调节参数由大到小,
过大的
结果方差较小,偏差较大;
过小的
预测方差较大,偏差较小。
所以,
这里的调节参数与其它有监督学习方法中的调节参数类似,
应该在偏差与方差之间折衷,
可以用交叉验证方法求最优调节参数值。
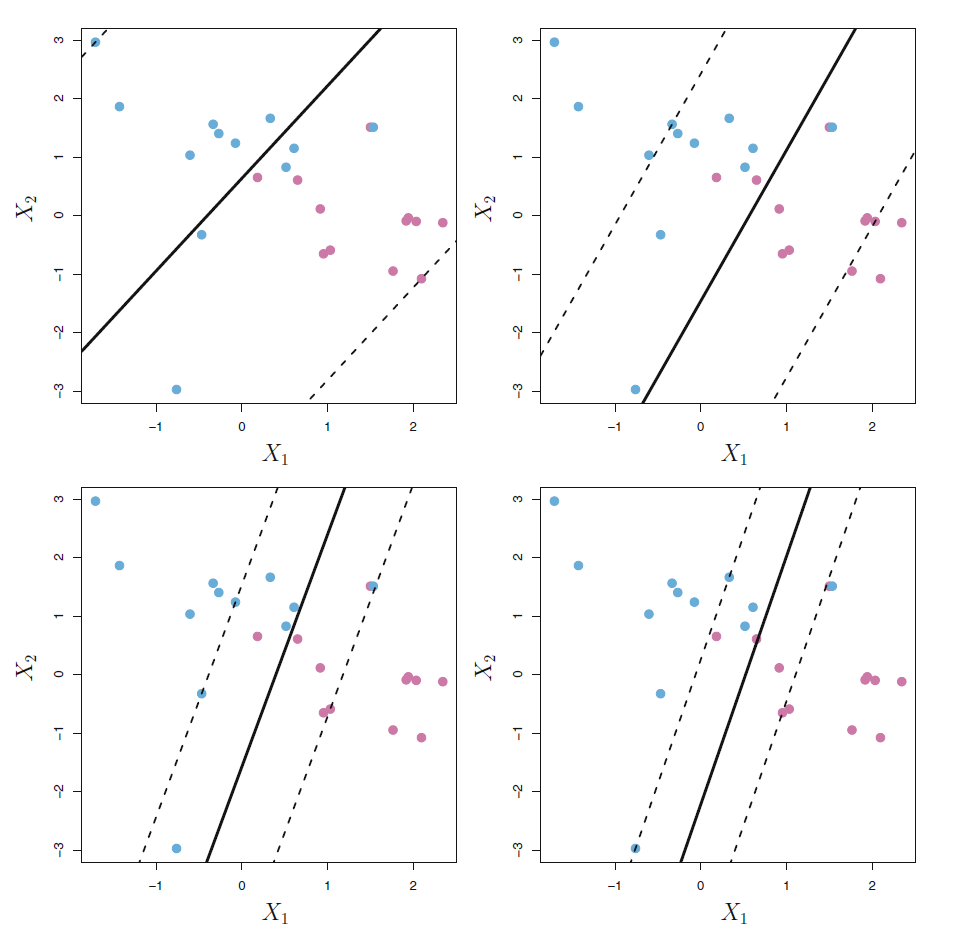
图44.7: 软分隔边界不同调节参数的影响
上面的优化问题的解有一个重要性质:
最终的解仅仅依赖边界点(即落在分隔区域的边界上的点)以及进入边界区域或者进入错误一面的点,
这些点称为支持向量;
那些被分隔区域完全正确地区分在两边的点不起作用。
从这个性质来看条件参数
当
分隔边界很宽,
许多点进入了边界区域或者错误一面,
有许多个支持向量,
最终解由许多个点决定,
这时解的方差较低,
但对应于较简单的模型,所以可能会有较大偏差。
当
只有少数几个支持向量,
模型稳定性差,
有过度拟合危险,
方差可能较大。
支持向量判别法只依赖于少数支持向量这个性质与距离判别法很不同,
结果仅由靠近边界的点决定,
那些离边界很远的点则不起作用;
距离判别法则是由所有点决定。
逻辑回归判别法与支持向量判别法有类似的性质,
也是主要依赖那些边界附近的点。
支持向量机方法
支持向量判别法仅仅支持超平面作为分隔,
对于分隔区域是曲面的情形则不能处理。
支持向量机方法可以解决这个问题。
非线性边界方法
分隔超平面是线性边界,
对于图44.8这样的分隔边界非线性的问题无法解决,
其它的线性判别法也不能解决这样的非线性边界判别问题。
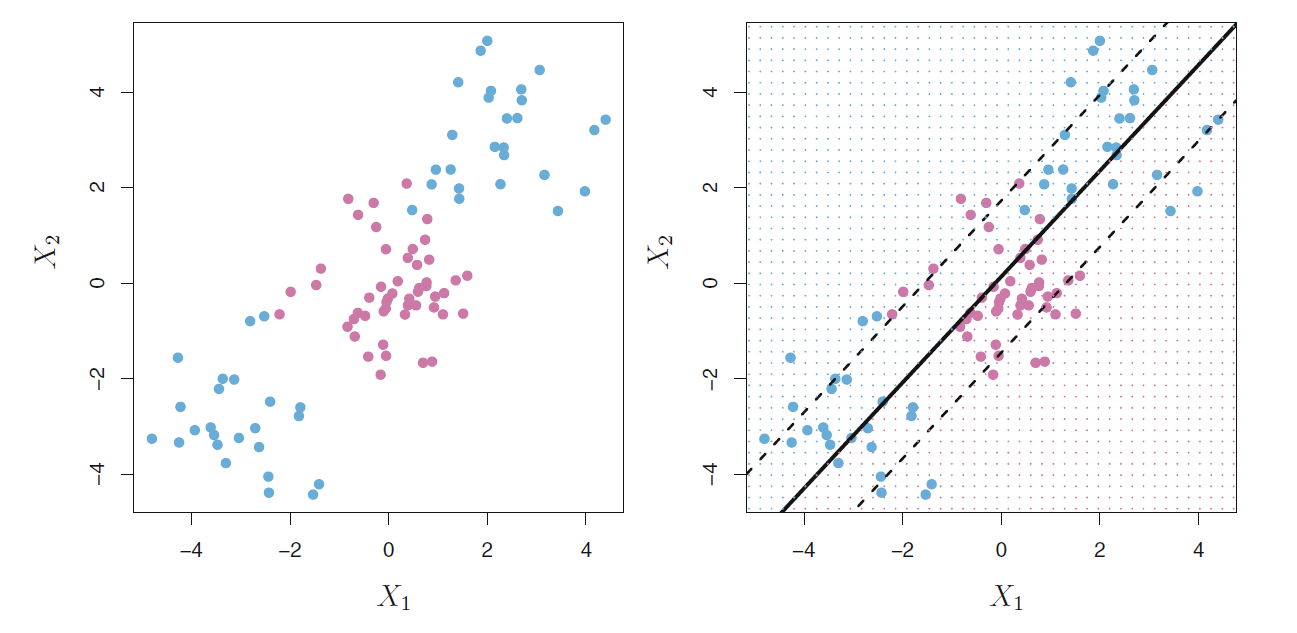
图44.8: 线性边界无法解决的例子
解决非线性问题的常用方法是增加非线性项如二次项、三次项。
比如,将自变量由
则支持向量判别法的优化问题变成了
这样得到的边界在
但是在原来
还可以增加高次项和交叉项,
或者考虑其它的非线性变换。
增加非线性项的方法有无数多种,
一一测试是不现实的,
支持向量机方法则给出了一种增加非线性项的一般方法,
对应的边界可以快速求解。
支持向量机
支持向量机利用了Hilbert空间的方法将线性问题扩展为非线性问题。
线性的支持向量判别法可以通过
其中
记
则
为了估计参数,
不需要用到各
而只需要其两两的内积值,
而且在判别函数中只有支持向量对应的
记
则线性判别函数为
支持向量机方法将
存在从
使得
核函数
比如,
取
就又回到了线性的支持向量判别法。
利用核代替内积后,
判别法的判别函数变成
这在原始观测
但在特征空间
核有多种取法。
例如,
取
其中
称为多项式核,
则结果是多项式边界的判别法,
本质上是对线性的支持向量方法添加了高次项和交叉项。
前一小节就是
可以看出,
增加了二次项以后,
将
考虑在高维的
但在
判决函数可以表示为
这又可以表示为内积形式:
理论研究表明,给定核函数
必存在一个Hilbert空间
于是,
给了一个核函数,
就可以将原来的
通过映射
这样得到的判别函数在
但在原始的
训练这样的SVM时只要计算观测两两的
为什么不直接增加非线性项?
原因是计算这些核函数值计算量是确定的,
而增加许多非线性项,
则可能有很大的计算量,
映射
计算核函数值而不是计算映射
支持向量机的理论基于再生核希尔伯特空间(RKHS),
可参见44.7,
以及(Trevor Hastie 2009)节5.8和节12.3.3。
图44.9的左图是用多项式核解决非线性边界判别问题的演示。
两条粗实线是分隔曲面,
虚线是边界区域的边缘。
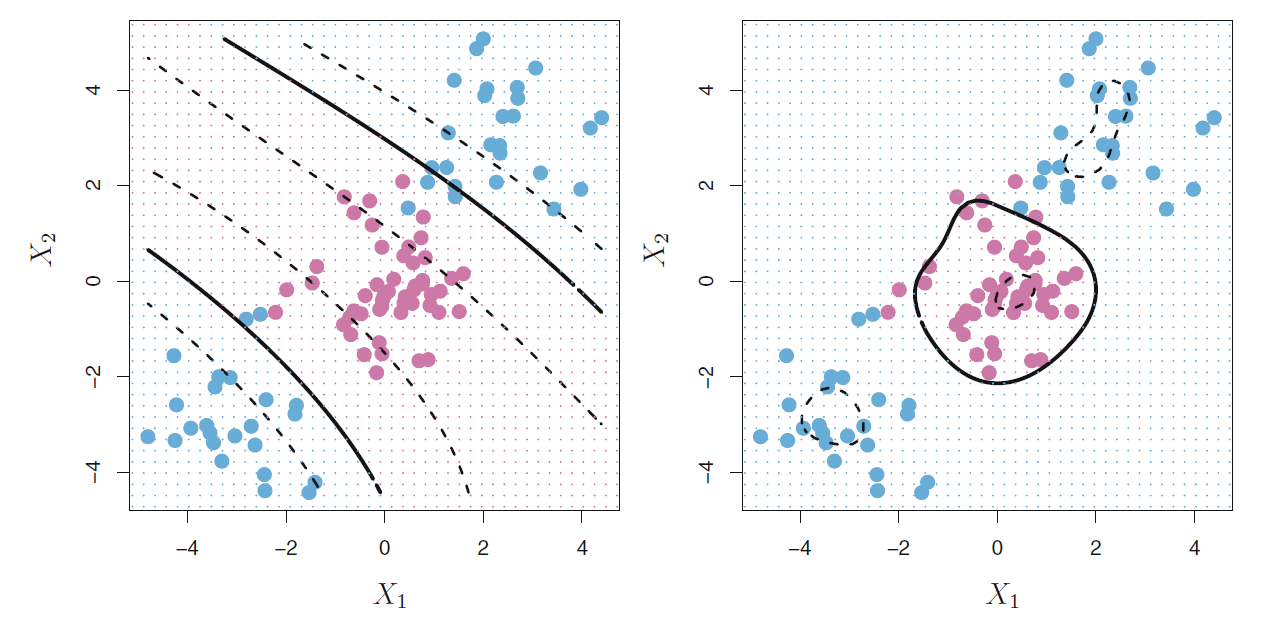
图44.9: 多项式核与径向核判别的例子
另一种常用的核是径向核(radial kernel),
定义为
当
其核函数值不变。
44.9的右图是用径向核支持向量机进行判别的演示。
使用径向核时,
判别函数为
对一个待判别的观测
如果
则
这样的性质使得径向核方法具有很强的局部性,
只有离
支持向量机用于Heart数据
考虑心脏病数据Heart的判别。
共297个观测,
随机选取其中207个作为训练集,
90个作为测试集。
library(rsample)
Heart <- read_csv(
"data/Heart.csv",
show_col_types = FALSE) |>
dplyr::select(-1) |>
mutate(
AHD = factor(AHD, levels=c("Yes", "No"))
)## New names:
## • `` -> `...1`Heart <- na.omit(Heart)
set.seed(101)
heart_split <- initial_split(
Heart, prop = 0.50)
heart_train <- training(heart_split)
heart_test <- testing(heart_split)
test.y <- heart_test$AHD定义一个错判率函数:
classifier.error <- function(truth, pred){
tab1 <- table(truth, pred)
err <- 1 - sum(diag(tab1))/sum(c(tab1))
err
}线性的SVM
支持向量判别法就是SVM取多项式核,
阶数
需要一个调节参数C,C越大,
分隔边界越窄,
过度拟合危险越大。
先随便取调节参数C=1试验支持向量判别法:
##
## Attaching package: 'kernlab'## The following object is masked from 'package:purrr':
##
## cross## The following object is masked from 'package:ggplot2':
##
## alpha## Setting default kernel parameters## Length Class Mode
## 1 ksvm S4计算拟合结果并计算错判率:
## fitted
## truth Yes No
## Yes 69 10
## No 12 57## SVC错判率: 0.15超参数调优方法参见47.3。
多项式核SVM
res.svm1 <- ksvm(
AHD ~ .,
data = heart_train,
kernel="polydot",
kpar = list(degree = 2),
C = 0.1,
scale=TRUE)
fit.svm1 <- predict(res.svm1)
summary(res.svm1)## Length Class Mode
## 1 ksvm S4## fitted
## truth Yes No
## Yes 77 2
## No 2 67## 2阶多项式核SVM错判率: 0.03注意这是拟合情况。
在测试集上的预测错误率:
pred.svm1t <- predict(res.svm1, heart_test)
tab1 <- table(truth = heart_test$AHD, pred = pred.svm1t); tab1## pred
## truth Yes No
## Yes 46 12
## No 26 65## 测试集上2阶多项式核SVM错判率: 0.26径向核SVM
径向核需要的参数为
取参数sigma = 0.1。
res.svm3 <- ksvm(
AHD ~ .,
data = heart_train,
kernel="rbfdot",
kpar = list(sigma = 0.1),
C = 0.1,
scaled = TRUE)
fit.svm3 <- predict(res.svm3)
summary(res.svm3)## Length Class Mode
## 1 ksvm S4## fitted
## truth Yes No
## Yes 74 5
## No 32 37cat("径向核(sigma=0.1, cost=0.1)SVM拟合错判率:",
round(classifier.error(heart_train$AHD, fit.svm3), 2), "\n")## 径向核(sigma=0.1, cost=0.1)SVM拟合错判率: 0.25多分类的支持向量机
当因变量不止两个类的时候,
从分隔超平面推广过来的支持向量机分类方法很难直接推广到多个类。
所以最常用的方法是按两类处理,
或者是两两判别,
或者是一个类相对于其余类判别。
两两判别
设因变量有
得到
对于待判样品
用这些判别函数每一个都判一遍,
得到
然后这
那个类别的票最高就判入哪一类。
多分类支持向量机鸢尾花数据计算实例
考虑著名的鸢尾花数据集的判别问题。
所有数据用作训练集合。
取径向基,用指定的调整参数:
res.msvm1 <- ksvm(
Species ~ .,
data = iris,
kernel="rbfdot",
kpar = list(sigma = 0.01),
C = 1,
scaled=TRUE)
summary(res.msvm1)## Length Class Mode
## 1 ksvm S4## fitted
## truth setosa versicolor virginica
## setosa 50 0 0
## versicolor 0 46 4
## virginica 0 11 39## 径向核(gamma=0.01, cost=1)多类SVM错判率: 0.1附录:特征空间、正定核、再生核希尔伯特空间
参考:
-
(Trevor Hastie 2009)节5.8和节12.3.3。
-
Jean Gallier and Jocelyn Quaintance(2019).
Algebra, Topology, Differential Calculus,
and Optimization Theory
For Computer Science and Machine Learning, Chapter 54.
http://www.cis.upenn.edu/~jean/math-basics.pdf -
Mohri, Mehryar / Rostamizadeh, Afshin / Talwalkar, Ameet(2018).
Foundations of Machine Learning, Chapter 6.
2nd Ed., MIT Press.
https://cs.nyu.edu/~mohri/mlbook/
正定核
介绍
设
要考虑
希望将
设存在映射
其中
具有内积
称
称
定义
称
简称正定核。
例44.1 设
令
有
涉及到从原始空间
对任意
有
这蕴含
不要求
所以严格来说应该称为“对称半正定核”,
但是“正定核”的叫法已经广泛采用。
令
则
这给出了正定核的等价定义:
设
对任意
都有
则称
这时
若
则
当且仅当
且对任意
有
即
称这样的正定核为实对称正定核,
仍简称正定核。
因为正定核是
所以满足Cauchy-Schwarz不等式:
运算封闭性
正定核的运算封闭性(见(Mohri, Rostamizadeh, and Talwalkar 2018)定理6.10):
- 两个正定核的和仍为正定核。
- 两个正定核的乘积仍为正定核。
- 正定核的正常数倍仍为正定核。
- 正定核的张量积仍为正定核。即若
K1(x,y) ,K2(x′,y′) 为正定核,
则K(u,v)=K1(x,y)K2(x′,y′) 为正定核,
其中u=(x,x′) ,v=(v,v′) 。 - 正定核的点极限仍为正定核。
即设Kn(⋅,⋅) 为正定核且limn→∞Kn(x,y)=K(x,y) ,
∀x,y ,则K(x,y) 为正定核。 - 设映射
ψ:→ℝn ,
K0 是ℝn×ℝn→ℂ 的正定核,
则K(x,y)=K0(ψ(x),ψ(y)) 是正定核。 - 设幂级数
h(x)=∑∞j=0ajxj 在(−ρ,ρ) 收敛(ρ>0 ),
X(x,y) 为正定核,取值在(−ρ,ρ) 内,
则h(K(x,y)) 为正定核。
正定核的标准化(见(Mohri, Rostamizadeh, and Talwalkar 2018)引理6.9):
设
定义
称
一些正定核
对
设
则
事实上,
对
这是上一个正定核当
对映射
事实上,
对
令
这是一个正定核,称为高斯核或者径向基函数。
证明:
取
易见
只要证明
而
幂级数
所以
再生核希尔伯特空间
设
是否存在希尔伯特空间
这个空间是存在的,
称为
一般地,
可以构造
某些具体的
设
定义
记
则
令
可以定义
在
设
则
可以定义映射
则
于是
可以将
对于
对任意
有
上式称为再生性,
即通过特征空间
也即核函数
可以恢复(再生)
当
References
Mohri, Mehryar, Afshin Rostamizadeh, and Ameet Talwalkar. 2018. Foundations of Machine Learning. 2nd Edition. MIT Press.
Trevor Hastie, Jerome Friedman, Robert Tibshirani. 2009. The Elements of Statistical Learning. 2nd Ed. Springer.
韭菜热线原创版权所有,发布者:风生水起,转载请注明出处:https://www.9crx.com/80062.html




