

探索性数据分析(Exploratory data analysis, EDA)是在进行推断性统计建模之前, 对数据的分布、变量之间的关系、观测之间的聚集等特性用汇总统计、作图等方法进行探索, 这是必不可少的步骤。 有时我们不知道数据告诉我们什么信息, 不知道要提什么问题, 这就必须用EDA来获得对数据的洞察, 提示我们随后要进行的研究。 即使一开始研究目标就很明确, 我们也需要用EDA方法确定数据中是否有错误, 变量分布是否满足模型需要的假定, 变量值有没有异常, 变量之间的关系从图形直观看是否符合我们要建立的模型。
数据中的变量大致可以分为属性变量(分类变量)和区间变量(数值型的变量)。 属性变量又分为名义型的, 没有大小次序, 以及有序的(如学历等级)。 区间变量包括取整数值的和取浮点值的变量, 其中取整数值的变量当可取值较少时, 也呈现出一定的分类变量特征。
以NHANES包的NHANES数据集为例。 这是一个规模较大的示例数据框, 可以看作是美国扣除住院病人以外的人群的一个随机样本, 有10000个观测,有76个变量, 主题是个人的健康与营养方面的信息。
首先需要了解数据框的行数、列数, 有哪些变量, 变量的存储类型, 可以用dplyr::glimpse():
library(tidyverse) # Wickham的数据整理的整套工具
library(NHANES); data(NHANES)dplyr::glimpse(NHANES)## Rows: 10,000
## Columns: 76
## $ ID <int> 51624, 51624, 51624, 51625, 51630, 51638, 51646, 5164…
## $ SurveyYr <fct> 2009_10, 2009_10, 2009_10, 2009_10, 2009_10, 2009_10,…
## $ Gender <fct> male, male, male, male, female, male, male, female, f…
## $ Age <int> 34, 34, 34, 4, 49, 9, 8, 45, 45, 45, 66, 58, 54, 10, …
## $ AgeDecade <fct> 30-39, 30-39, 30-39, 0-9, 40-49, 0-9, 0-9, 40…
## $ AgeMonths <int> 409, 409, 409, 49, 596, 115, 101, 541, 541, 541, 795,…
## $ Race1 <fct> White, White, White, Other, White, White, White, Whit…
## $ Race3 <fct> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ Education <fct> High School, High School, High School, NA, Some Colle…
## $ MaritalStatus <fct> Married, Married, Married, NA, LivePartner, NA, NA, M…
## $ HHIncome <fct> 25000-34999, 25000-34999, 25000-34999, 20000-24999, 3…
## $ HHIncomeMid <int> 30000, 30000, 30000, 22500, 40000, 87500, 60000, 8750…
## $ Poverty <dbl> 1.36, 1.36, 1.36, 1.07, 1.91, 1.84, 2.33, 5.00, 5.00,…
## $ HomeRooms <int> 6, 6, 6, 9, 5, 6, 7, 6, 6, 6, 5, 10, 6, 10, 10, 4, 3,…
## $ HomeOwn <fct> Own, Own, Own, Own, Rent, Rent, Own, Own, Own, Own, O…
## $ Work <fct> NotWorking, NotWorking, NotWorking, NA, NotWorking, N…
## $ Weight <dbl> 87.4, 87.4, 87.4, 17.0, 86.7, 29.8, 35.2, 75.7, 75.7,…
## $ Length <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ HeadCirc <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ Height <dbl> 164.7, 164.7, 164.7, 105.4, 168.4, 133.1, 130.6, 166.…
## $ BMI <dbl> 32.22, 32.22, 32.22, 15.30, 30.57, 16.82, 20.64, 27.2…
## $ BMICatUnder20yrs <fct> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ BMI_WHO <fct> 30.0_plus, 30.0_plus, 30.0_plus, 12.0_18.5, 30.0_plus…
## $ Pulse <int> 70, 70, 70, NA, 86, 82, 72, 62, 62, 62, 60, 62, 76, 8…
## $ BPSysAve <int> 113, 113, 113, NA, 112, 86, 107, 118, 118, 118, 111, …
## $ BPDiaAve <int> 85, 85, 85, NA, 75, 47, 37, 64, 64, 64, 63, 74, 85, 6…
## $ BPSys1 <int> 114, 114, 114, NA, 118, 84, 114, 106, 106, 106, 124, …
## $ BPDia1 <int> 88, 88, 88, NA, 82, 50, 46, 62, 62, 62, 64, 76, 86, 6…
## $ BPSys2 <int> 114, 114, 114, NA, 108, 84, 108, 118, 118, 118, 108, …
## $ BPDia2 <int> 88, 88, 88, NA, 74, 50, 36, 68, 68, 68, 62, 72, 88, 6…
## $ BPSys3 <int> 112, 112, 112, NA, 116, 88, 106, 118, 118, 118, 114, …
## $ BPDia3 <int> 82, 82, 82, NA, 76, 44, 38, 60, 60, 60, 64, 76, 82, 7…
## $ Testosterone <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ DirectChol <dbl> 1.29, 1.29, 1.29, NA, 1.16, 1.34, 1.55, 2.12, 2.12, 2…
## $ TotChol <dbl> 3.49, 3.49, 3.49, NA, 6.70, 4.86, 4.09, 5.82, 5.82, 5…
## $ UrineVol1 <int> 352, 352, 352, NA, 77, 123, 238, 106, 106, 106, 113, …
## $ UrineFlow1 <dbl> NA, NA, NA, NA, 0.094, 1.538, 1.322, 1.116, 1.116, 1.…
## $ UrineVol2 <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ UrineFlow2 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ Diabetes <fct> No, No, No, No, No, No, No, No, No, No, No, No, No, N…
## $ DiabetesAge <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ HealthGen <fct> Good, Good, Good, NA, Good, NA, NA, Vgood, Vgood, Vgo…
## $ DaysPhysHlthBad <int> 0, 0, 0, NA, 0, NA, NA, 0, 0, 0, 10, 0, 4, NA, NA, 0,…
## $ DaysMentHlthBad <int> 15, 15, 15, NA, 10, NA, NA, 3, 3, 3, 0, 0, 0, NA, NA,…
## $ LittleInterest <fct> Most, Most, Most, NA, Several, NA, NA, None, None, No…
## $ Depressed <fct> Several, Several, Several, NA, Several, NA, NA, None,…
## $ nPregnancies <int> NA, NA, NA, NA, 2, NA, NA, 1, 1, 1, NA, NA, NA, NA, N…
## $ nBabies <int> NA, NA, NA, NA, 2, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ Age1stBaby <int> NA, NA, NA, NA, 27, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ SleepHrsNight <int> 4, 4, 4, NA, 8, NA, NA, 8, 8, 8, 7, 5, 4, NA, 5, 7, N…
## $ SleepTrouble <fct> Yes, Yes, Yes, NA, Yes, NA, NA, No, No, No, No, No, Y…
## $ PhysActive <fct> No, No, No, NA, No, NA, NA, Yes, Yes, Yes, Yes, Yes, …
## $ PhysActiveDays <int> NA, NA, NA, NA, NA, NA, NA, 5, 5, 5, 7, 5, 1, NA, 2, …
## $ TVHrsDay <fct> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ CompHrsDay <fct> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ TVHrsDayChild <int> NA, NA, NA, 4, NA, 5, 1, NA, NA, NA, NA, NA, NA, 4, N…
## $ CompHrsDayChild <int> NA, NA, NA, 1, NA, 0, 6, NA, NA, NA, NA, NA, NA, 3, N…
## $ Alcohol12PlusYr <fct> Yes, Yes, Yes, NA, Yes, NA, NA, Yes, Yes, Yes, Yes, Y…
## $ AlcoholDay <int> NA, NA, NA, NA, 2, NA, NA, 3, 3, 3, 1, 2, 6, NA, NA, …
## $ AlcoholYear <int> 0, 0, 0, NA, 20, NA, NA, 52, 52, 52, 100, 104, 364, N…
## $ SmokeNow <fct> No, No, No, NA, Yes, NA, NA, NA, NA, NA, No, NA, NA, …
## $ Smoke100 <fct> Yes, Yes, Yes, NA, Yes, NA, NA, No, No, No, Yes, No, …
## $ Smoke100n <fct> Smoker, Smoker, Smoker, NA, Smoker, NA, NA, Non-Smoke…
## $ SmokeAge <int> 18, 18, 18, NA, 38, NA, NA, NA, NA, NA, 13, NA, NA, N…
## $ Marijuana <fct> Yes, Yes, Yes, NA, Yes, NA, NA, Yes, Yes, Yes, NA, Ye…
## $ AgeFirstMarij <int> 17, 17, 17, NA, 18, NA, NA, 13, 13, 13, NA, 19, 15, N…
## $ RegularMarij <fct> No, No, No, NA, No, NA, NA, No, No, No, NA, Yes, Yes,…
## $ AgeRegMarij <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 20, 15, N…
## $ HardDrugs <fct> Yes, Yes, Yes, NA, Yes, NA, NA, No, No, No, No, Yes, …
## $ SexEver <fct> Yes, Yes, Yes, NA, Yes, NA, NA, Yes, Yes, Yes, Yes, Y…
## $ SexAge <int> 16, 16, 16, NA, 12, NA, NA, 13, 13, 13, 17, 22, 12, N…
## $ SexNumPartnLife <int> 8, 8, 8, NA, 10, NA, NA, 20, 20, 20, 15, 7, 100, NA, …
## $ SexNumPartYear <int> 1, 1, 1, NA, 1, NA, NA, 0, 0, 0, NA, 1, 1, NA, NA, 1,…
## $ SameSex <fct> No, No, No, NA, Yes, NA, NA, Yes, Yes, Yes, No, No, N…
## $ SexOrientation <fct> Heterosexual, Heterosexual, Heterosexual, NA, Heteros…
## $ PregnantNow <fct> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…结果中<int>表示取整数值, <dbl>表示取浮点型值, <fct>表示因子, <chr>表示字符串类型。
NHANES数据中包含了两次考察的结果, 所以每个受访者可能有两个观测, 少数受访者仅有一个, 也有的受访者有多个观测。 这样会使得变量的统计分析结果不易解释, 因此我们仅筛选其中SurveyYr为2011_12的观测, 并对每个ID仅保留最后一个观测, 生成数据框d_nhsub:
d_nhsub <- NHANES |>
dplyr::filter(SurveyYr == "2011_12") |>
group_by(ID) |>
slice_tail(n=1) |>
ungroup()
dim(d_nhsub)## [1] 3211 7629.1 单个分类变量分布
我们筛选出d_nhsub数据集中因子型的变量:
d_nhsub |>
map_lgl(is.factor) |>
keep(identity) |>
names()## [1] "SurveyYr" "Gender" "AgeDecade" "Race1"
## [5] "Race3" "Education" "MaritalStatus" "HHIncome"
## [9] "HomeOwn" "Work" "BMICatUnder20yrs" "BMI_WHO"
## [13] "Diabetes" "HealthGen" "LittleInterest" "Depressed"
## [17] "SleepTrouble" "PhysActive" "TVHrsDay" "CompHrsDay"
## [21] "Alcohol12PlusYr" "SmokeNow" "Smoke100" "Smoke100n"
## [25] "Marijuana" "RegularMarij" "HardDrugs" "SexEver"
## [29] "SameSex" "SexOrientation" "PregnantNow"以Education变量为例, 计算其频数和百分比如下:
d_nhsub |>
count(Education) |>
mutate(
pct = n / sum(n)
)## # A tibble: 6 × 3
## Education n pct
## <fct> <int> <dbl>
## 1 8th Grade 163 0.0508
## 2 9 - 11th Grade 268 0.0835
## 3 High School 421 0.131
## 4 Some College 695 0.216
## 5 College Grad 624 0.194
## 6 <NA> 1040 0.324在数据清理阶段对分类变量制作频数表, 可以发现输入错的类别值。
用基本R的table等函数统计:
table(d_nhsub[["Education"]])##
## 8th Grade 9 - 11th Grade High School Some College College Grad
## 163 268 421 695 624base::table()默认忽略缺失值, 这在指标显示时会有误导。加选项useNA="ifany":
table(d_nhsub[["Education"]],
useNA = "ifany")##
## 8th Grade 9 - 11th Grade High School Some College College Grad
## 163 268 421 695 624
## <NA>
## 1040百分比表:
table(NHANES[["Education"]],
useNA = "ifany") |>
prop.table()##
## 8th Grade 9 - 11th Grade High School Some College College Grad
## 0.0451 0.0888 0.1517 0.2267 0.2098
## <NA>
## 0.2779可以直接用ggplot2::geom_bar()制作频数条形图, 可以用geom_col()基于统计的频数表制作频数或者百分比的条形图, 如:
d_edu <- d_nhsub |>
count(Education) |>
mutate(
pct = n / sum(n)
)
ggplot(d_edu, aes(x = Education, y=n)) +
geom_col() +
theme(
axis.text.x = element_text(
angle = 45, vjust = 1, hjust = 1) )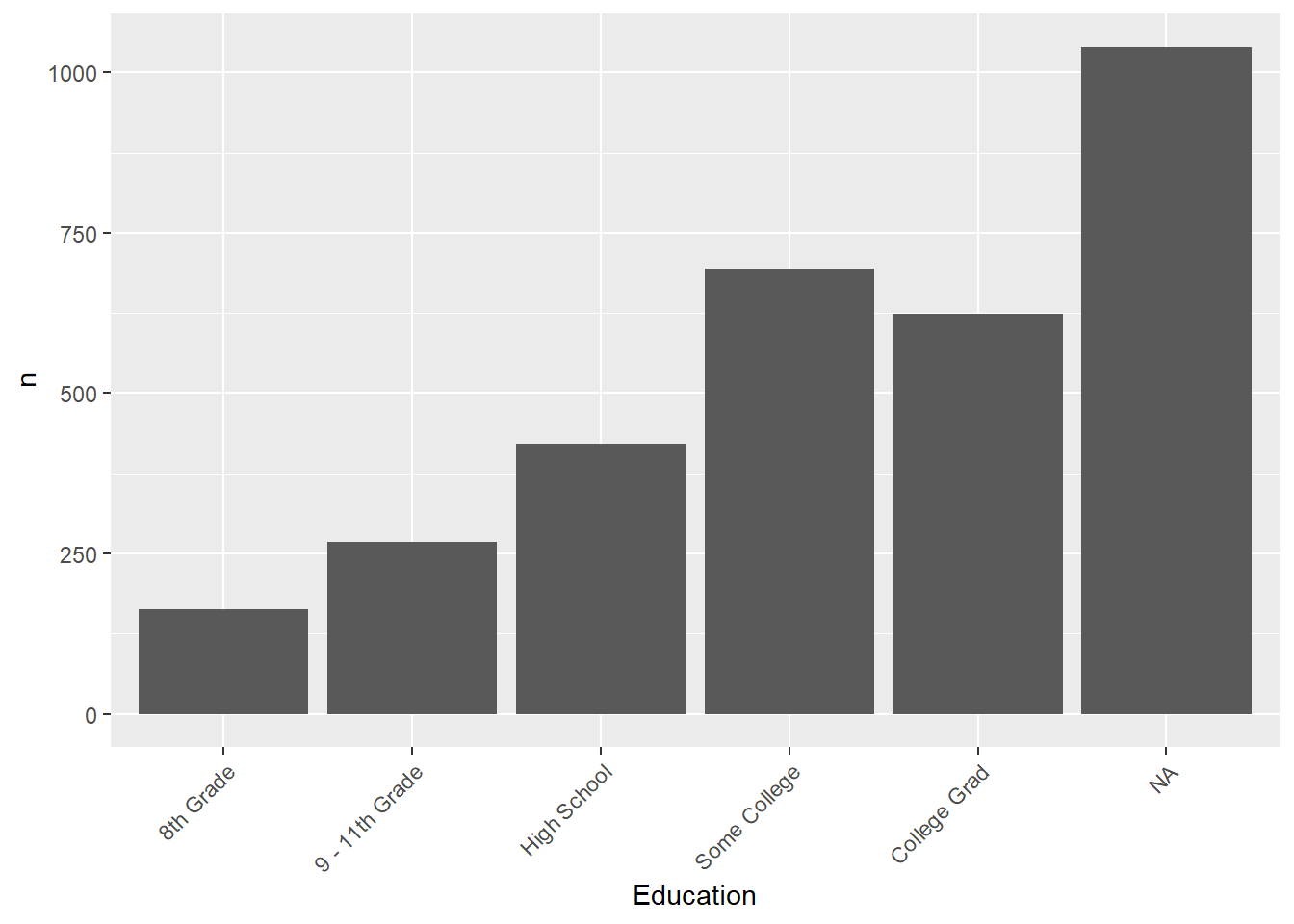

ggplot(d_edu, aes(x = Education, y=pct)) +
geom_col() +
scale_y_continuous(
name = "Percent",
labels = scales::percent) +
theme(
axis.text.x = element_text(
angle = 45, vjust = 1, hjust = 1) )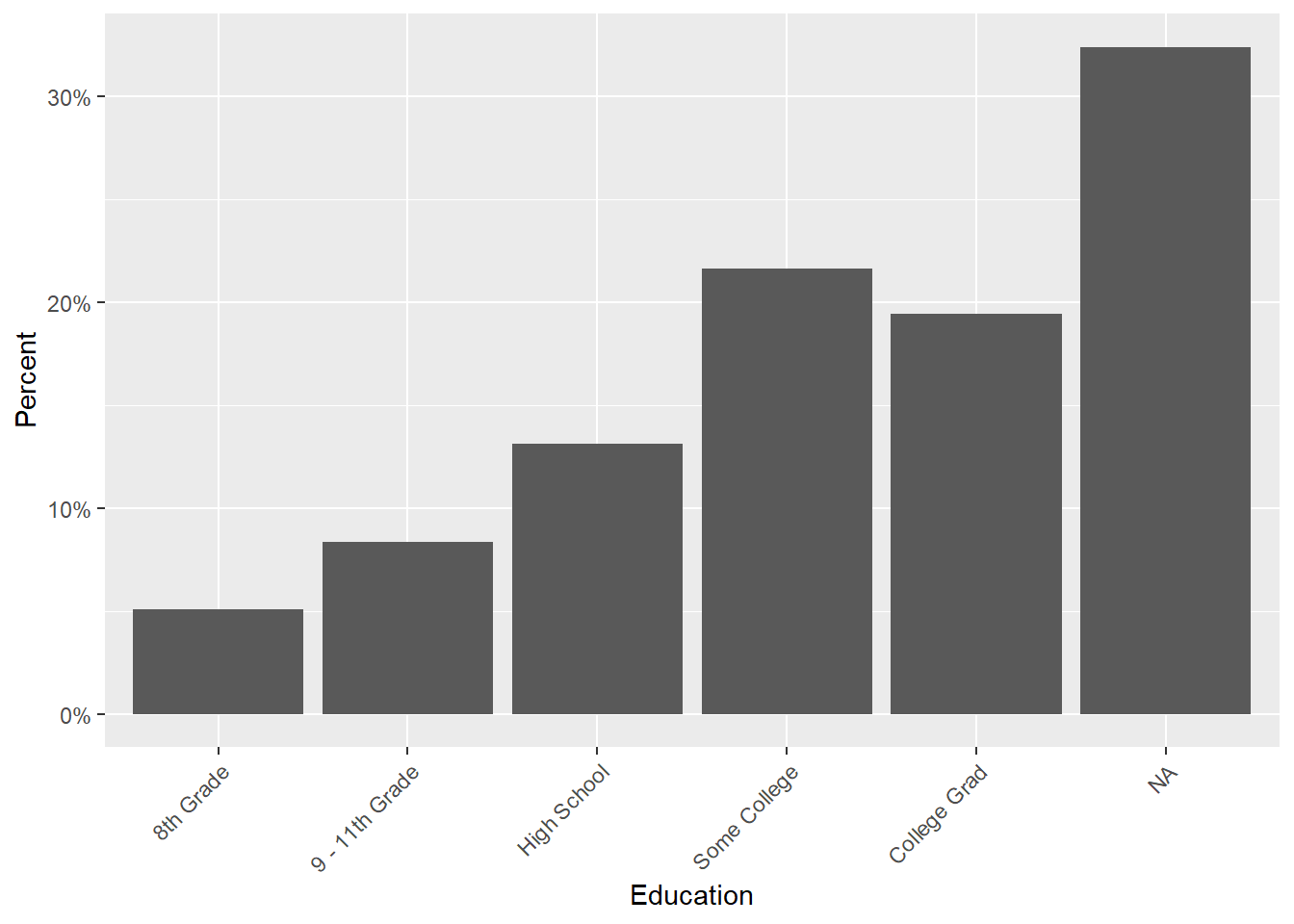
29.2 单个区间型变量分布
d_nhsub中所有浮点型值的变量:
d_nhsub |>
map_lgl(is.double) |>
keep(identity) |>
names()## [1] "Poverty" "Weight" "Length" "HeadCirc" "Height"
## [6] "BMI" "Testosterone" "DirectChol" "TotChol" "UrineFlow1"
## [11] "UrineFlow2"所有整数值的变量:
d_nhsub |>
map_lgl(is.integer) |>
keep(identity) |>
names()## [1] "ID" "Age" "AgeMonths" "HHIncomeMid"
## [5] "HomeRooms" "Pulse" "BPSysAve" "BPDiaAve"
## [9] "BPSys1" "BPDia1" "BPSys2" "BPDia2"
## [13] "BPSys3" "BPDia3" "UrineVol1" "UrineVol2"
## [17] "DiabetesAge" "DaysPhysHlthBad" "DaysMentHlthBad" "nPregnancies"
## [21] "nBabies" "Age1stBaby" "SleepHrsNight" "PhysActiveDays"
## [25] "TVHrsDayChild" "CompHrsDayChild" "AlcoholDay" "AlcoholYear"
## [29] "SmokeAge" "AgeFirstMarij" "AgeRegMarij" "SexAge"
## [33] "SexNumPartnLife" "SexNumPartYear"整数值的变量兼有区间型和分类变量的特点。 例如, 子女数(nBabies):
d_babies <- d_nhsub |>
count(nBabies) |>
mutate(pct = n / sum(n))
knitr::kable(d_babies)| nBabies | n | pct |
|---|---|---|
| 0 | 3 | 0.0009343 |
| 1 | 158 | 0.0492059 |
| 2 | 284 | 0.0884460 |
| 3 | 159 | 0.0495173 |
| 4 | 70 | 0.0218001 |
| 5 | 30 | 0.0093429 |
| 6 | 11 | 0.0034257 |
| 7 | 7 | 0.0021800 |
| 8 | 4 | 0.0012457 |
| 11 | 1 | 0.0003114 |
| NA | 2484 | 0.7735908 |
ggplot(d_babies, aes(x = nBabies, y=pct)) +
geom_col() +
scale_y_continuous(
name = "Percent",
labels = scales::percent) +
labs(caption="Note: 2484 NAs not shown.")## Warning: Removed 1 rows containing missing values (position_stack).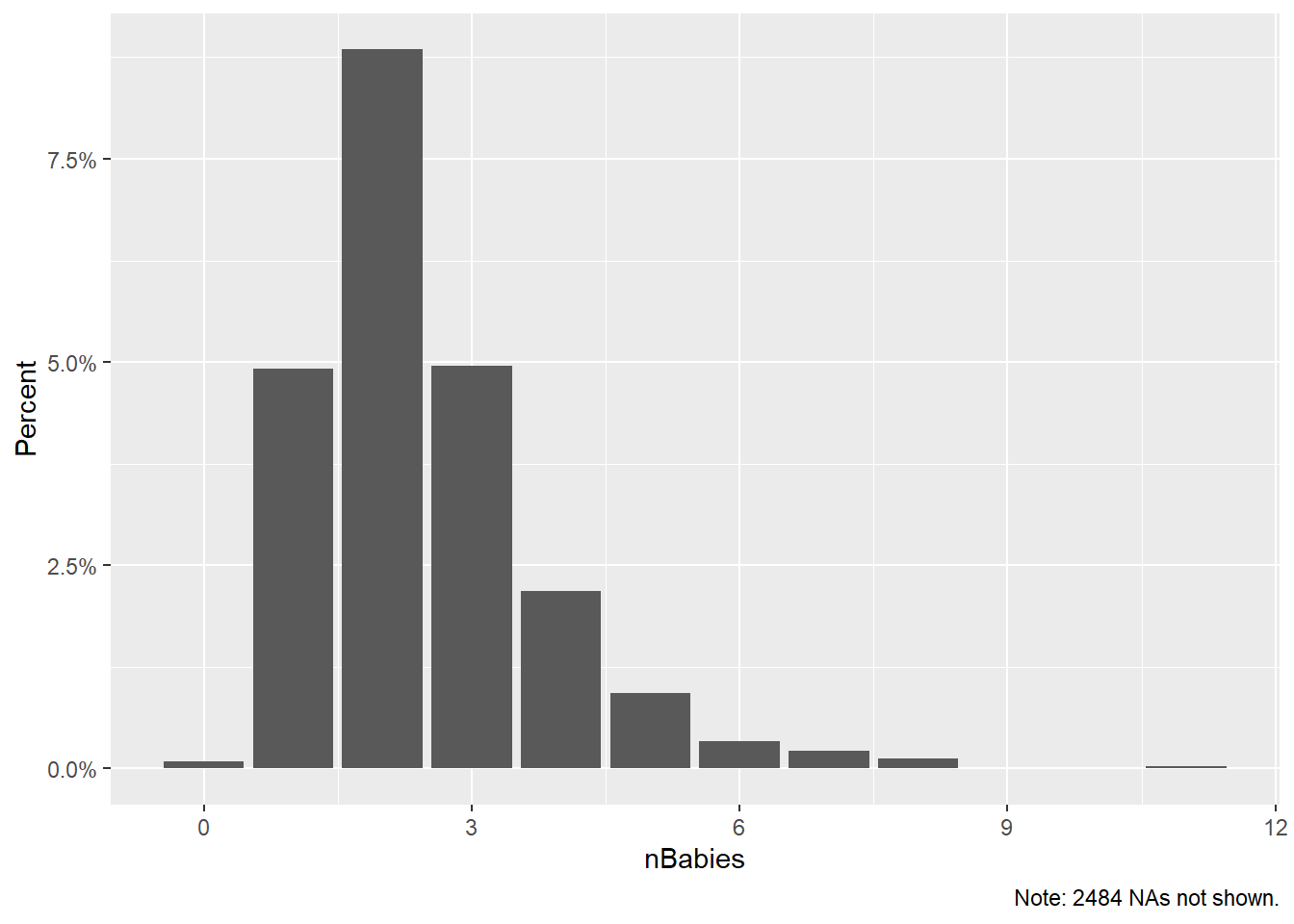
变量Height是2岁以上受访者的身高(单位:厘米)测量值。 可以用基本R的summary()函数显示“五数概括”和平均值:
summary(d_nhsub[["Height"]])## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 83.8 154.8 164.7 159.7 173.2 200.4 133这说明有133个缺失值, 在非缺失值中, 最小为83.8, 最大为200.4, 中位数是164.7, 平均身高为159.7。 有四分之一的人身高低于154.8, 有四分之一的人身高超过173.2。
可以用dplyr::summarize()计算指定的统计量, 如:
d_nhsub |>
summarize(
n = n(),
mean = mean(Height, na.rm=TRUE),
median = median(Height, na.rm=TRUE),
std = sd(Height, na.rm=TRUE)
)## # A tibble: 1 × 4
## n mean median std
## <int> <dbl> <dbl> <dbl>
## 1 3211 160. 165. 21.5用直方图反映分布情况:
ggplot(d_nhsub, aes(x = Height)) +
geom_histogram(bins=50)## Warning: Removed 133 rows containing non-finite values (stat_bin).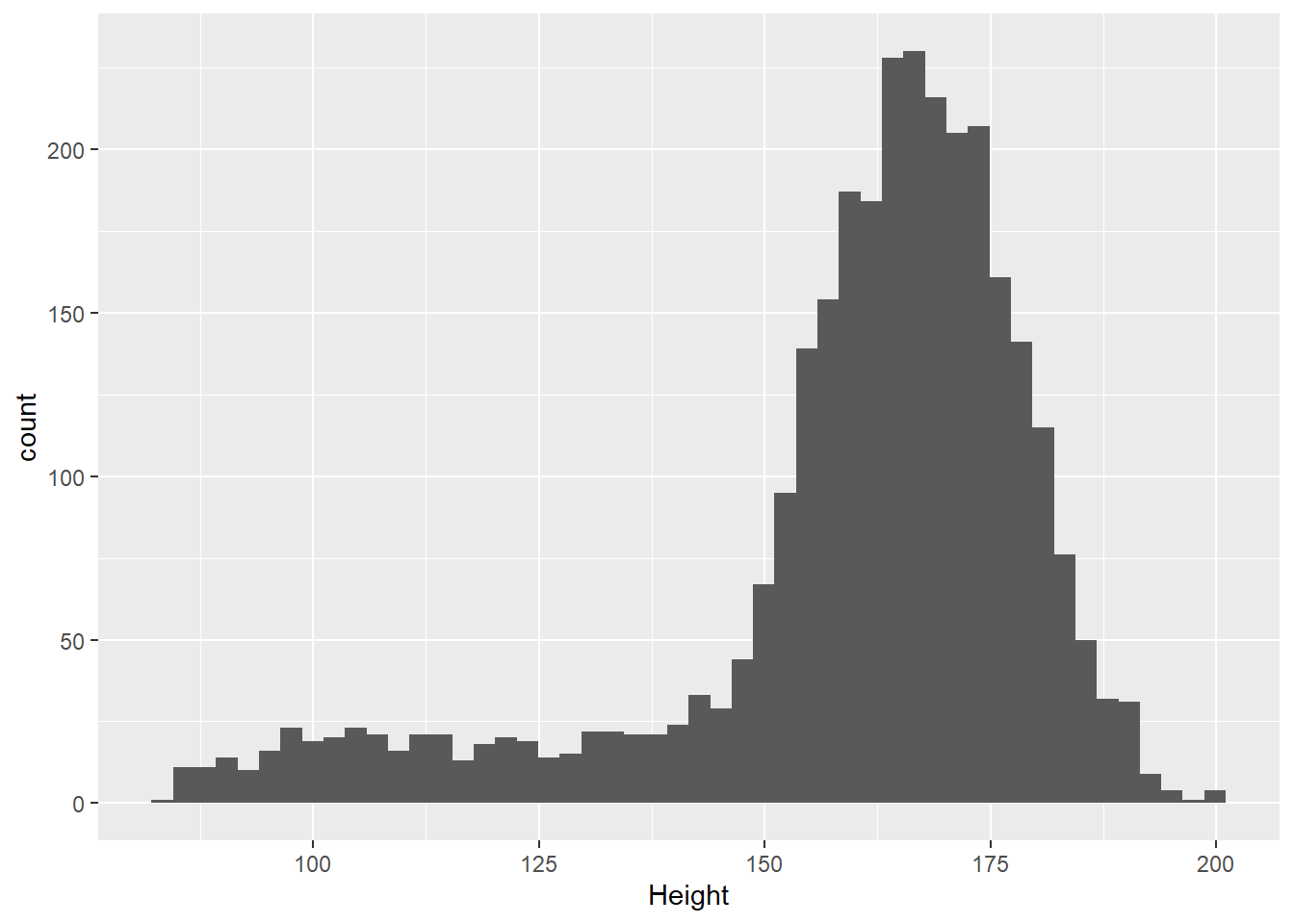
可以用折线表示直方图:
ggplot(d_nhsub, aes(x = Height)) +
geom_freqpoly(bins=50)## Warning: Removed 133 rows containing non-finite values (stat_bin).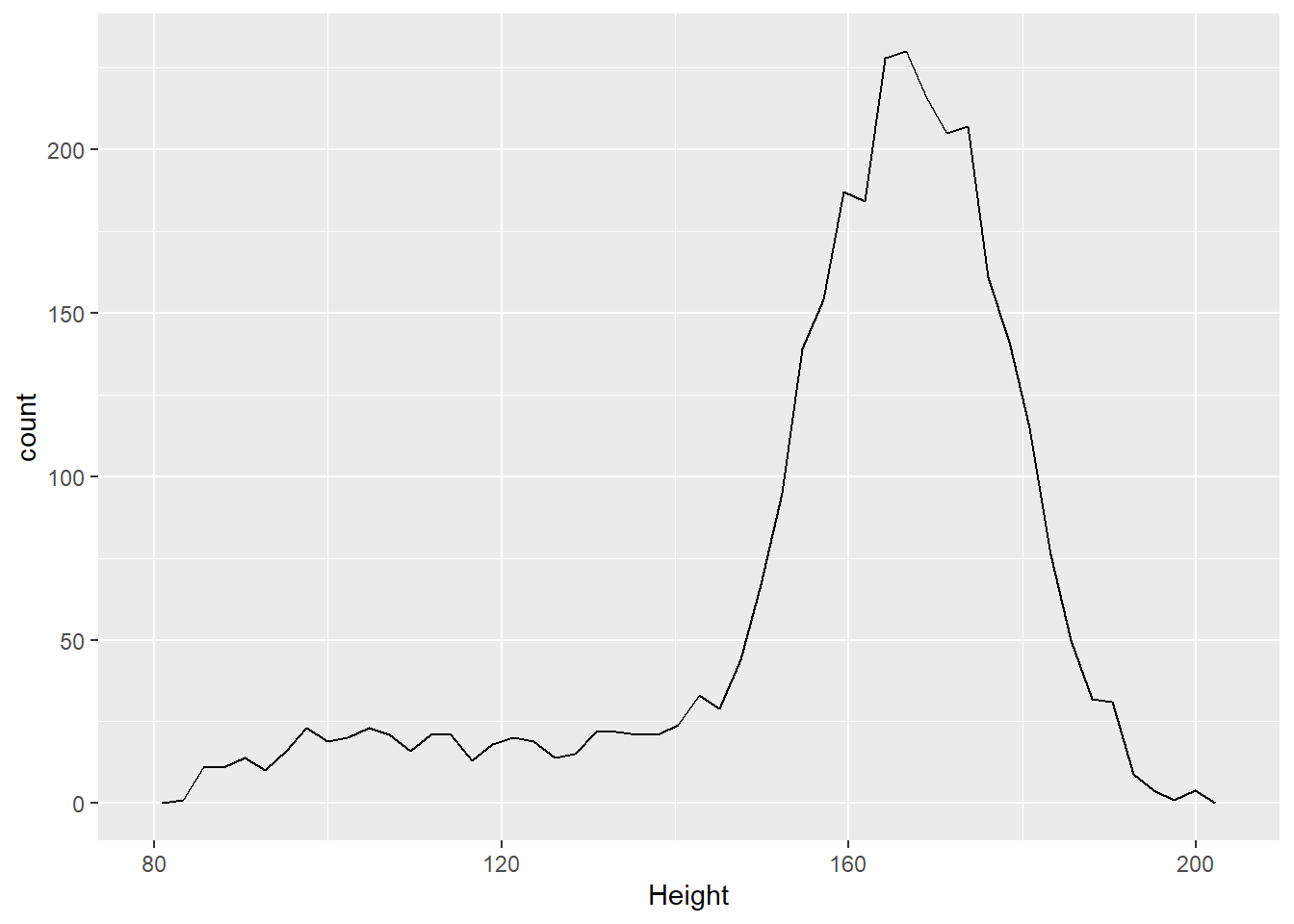
以上两个图的纵坐标是频数, 将纵坐标改为密度估计:
ggplot(d_nhsub, aes(x = Height, y = ..density..)) +
geom_freqpoly(bins=50)## Warning: Removed 133 rows containing non-finite values (stat_bin).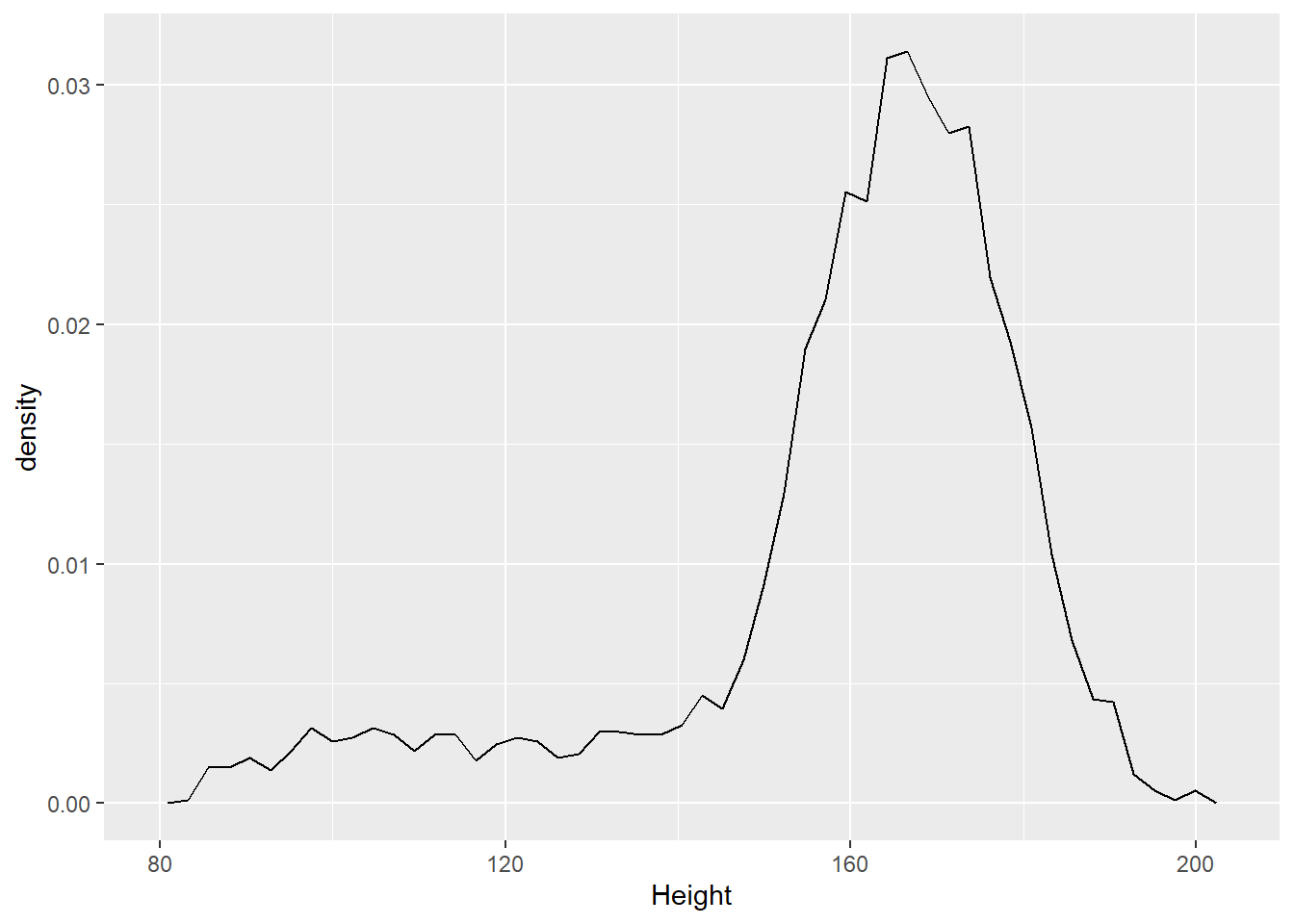
上面的y = ..density..可以改为y = after_stat(density)。
作身高的核密度估计图:
ggplot(d_nhsub, aes(x = Height)) +
geom_density()## Warning: Removed 133 rows containing non-finite values (stat_density).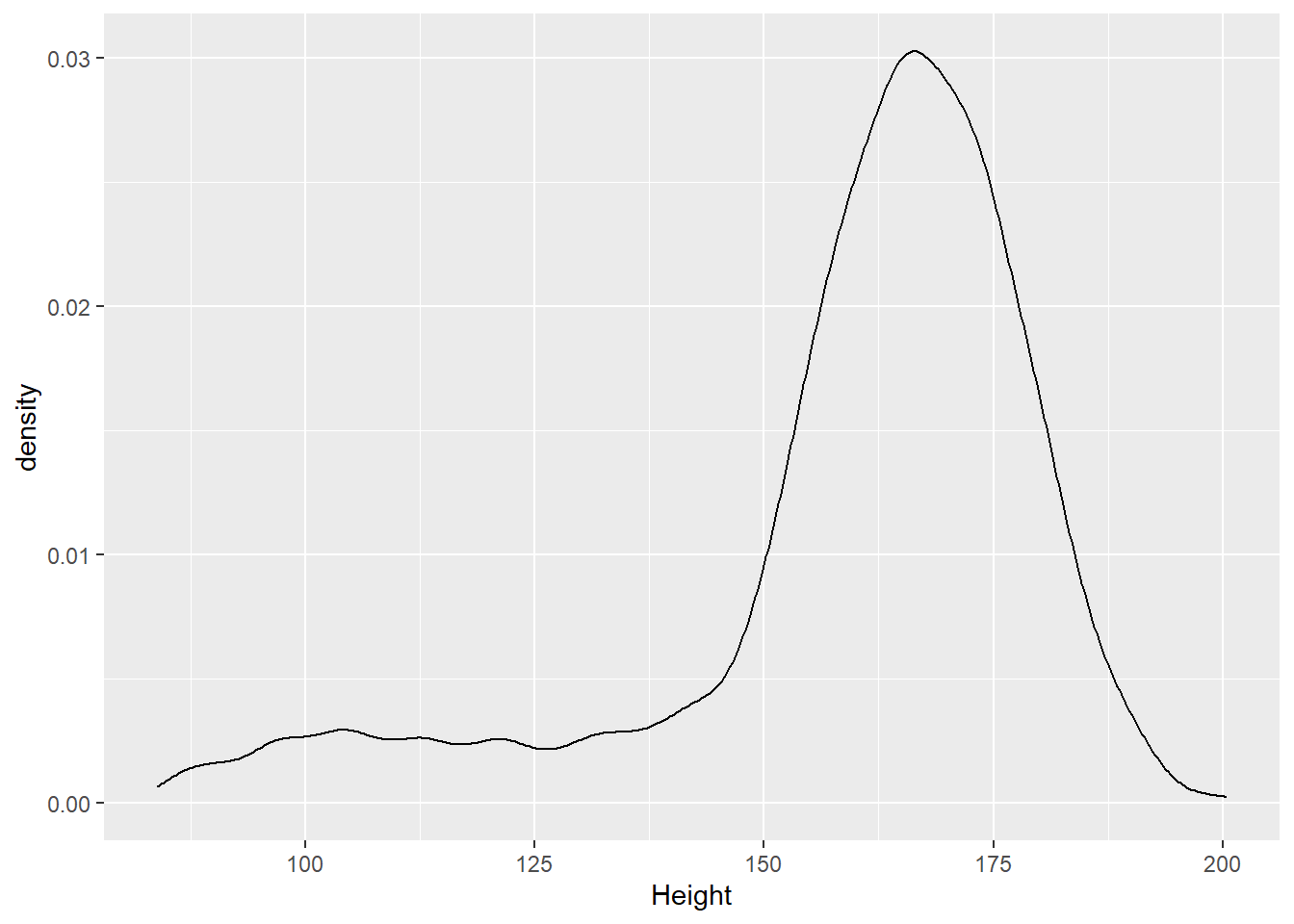
将直方图与核密度估计图叠加:
ggplot(d_nhsub, aes(x = Height)) +
geom_histogram(
aes(y = ..density..),
bins=50) +
geom_density(color="red")## Warning: Removed 133 rows containing non-finite values (stat_bin).## Warning: Removed 133 rows containing non-finite values (stat_density).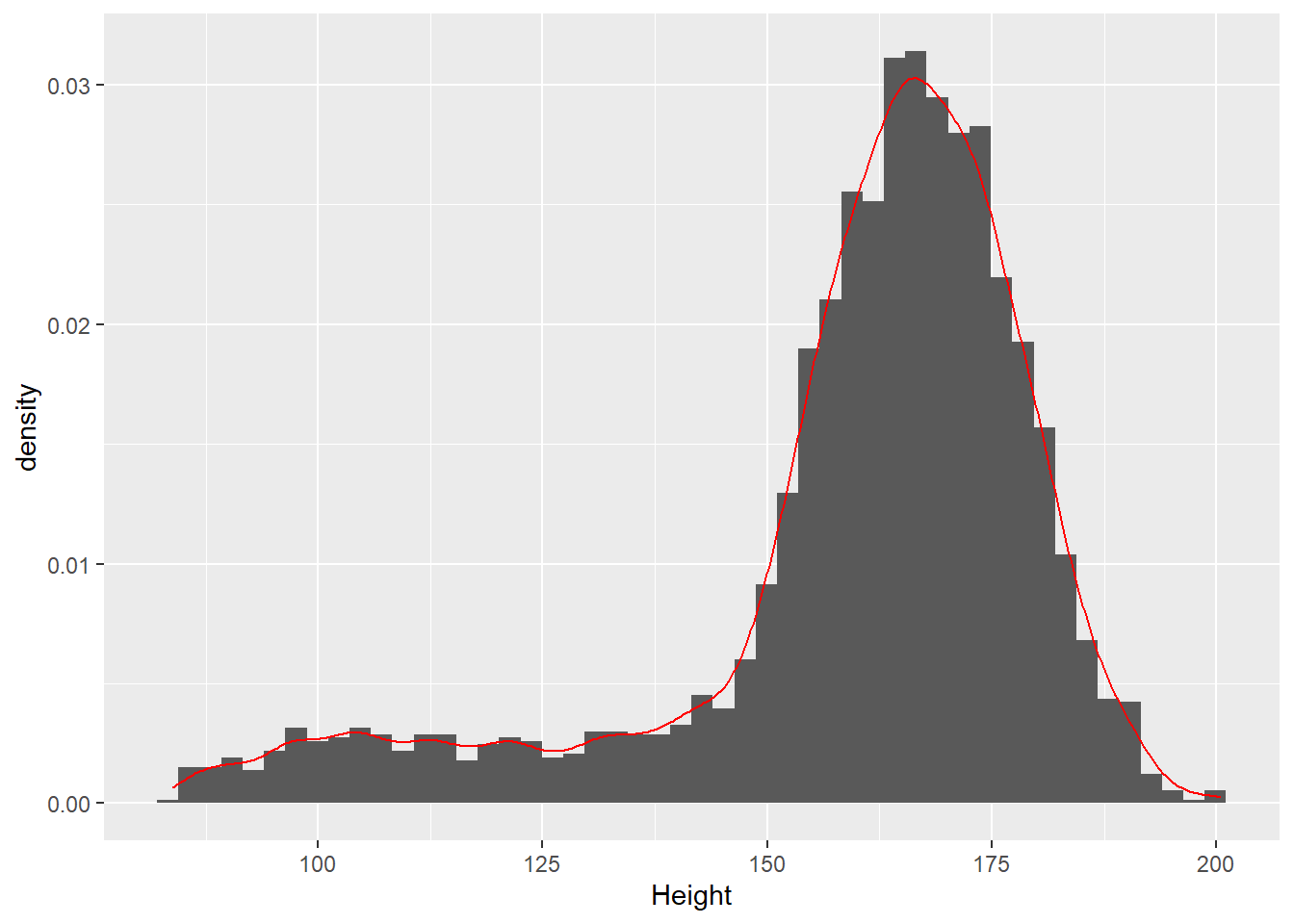
分布也可以用盒形图、小提琴图表示:
ggplot(d_nhsub, aes(x = "", y = Height)) +
geom_boxplot() +
labs(x = "")## Warning: Removed 133 rows containing non-finite values (stat_boxplot).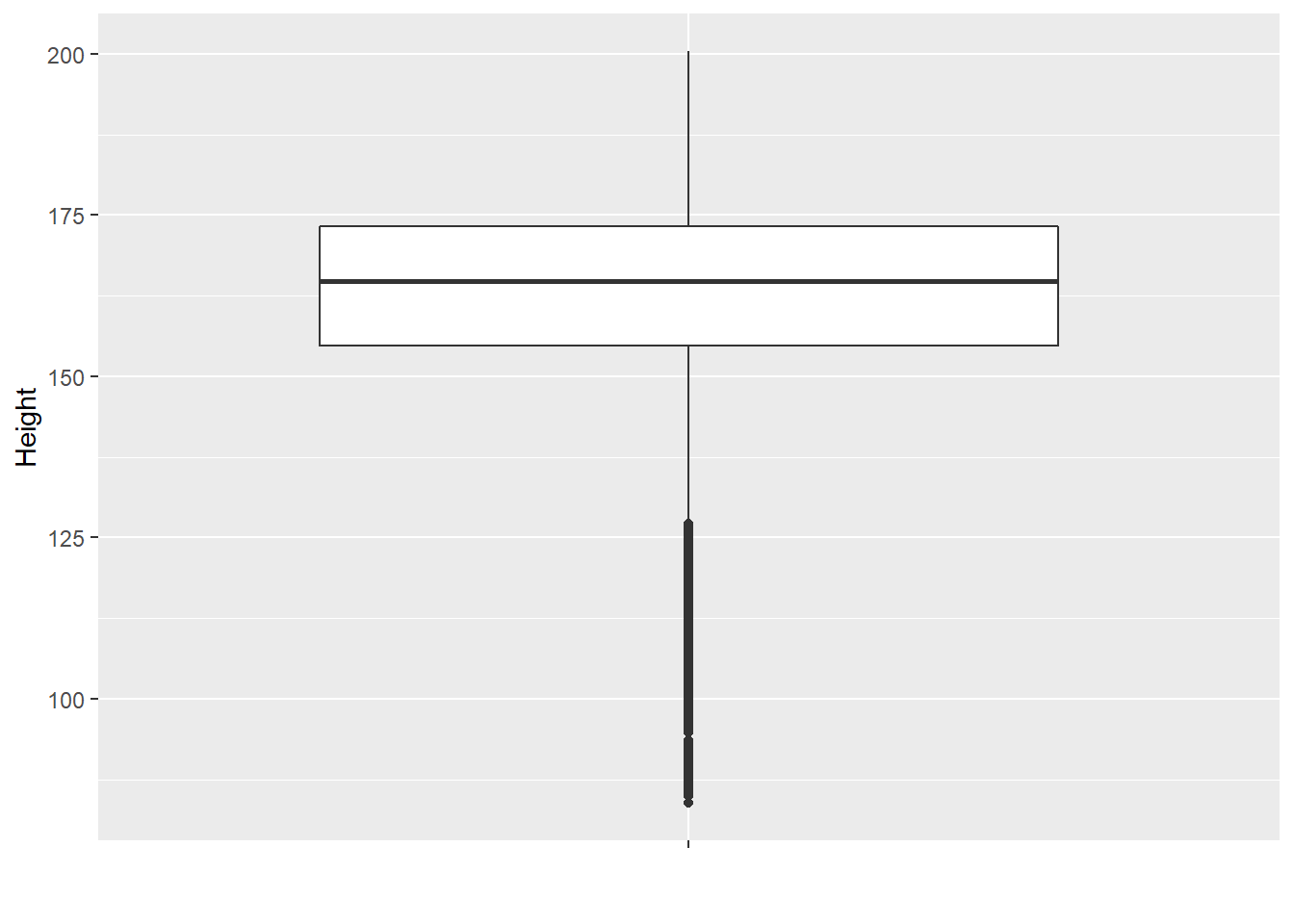
ggplot(d_nhsub, aes(x = "", y = Height)) +
geom_violin() +
labs(x = "")## Warning: Removed 133 rows containing non-finite values (stat_ydensity).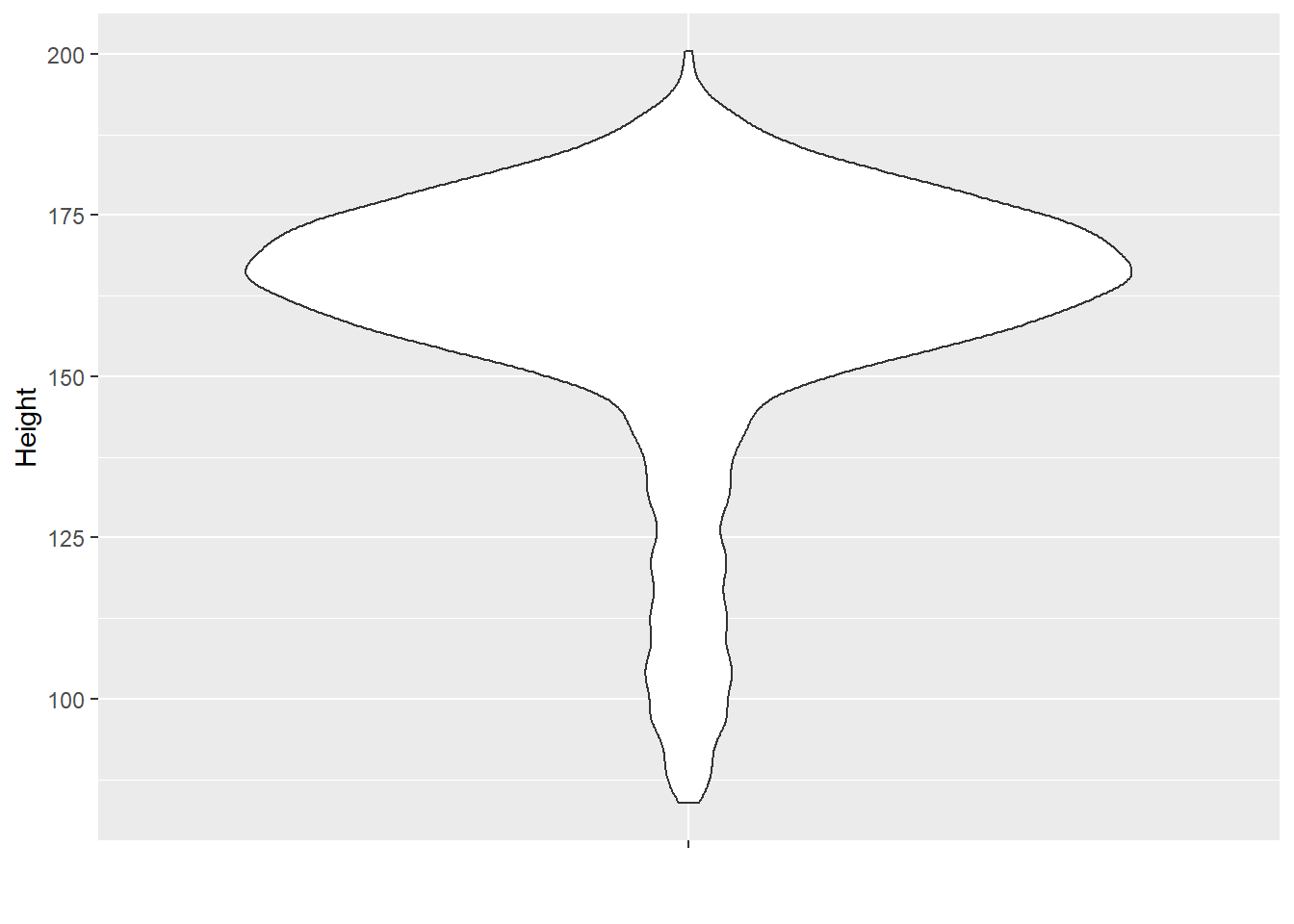
正态QQ图:
ggplot(d_nhsub, aes(sample = Height)) +
geom_qq() +
geom_qq_line() ## Warning: Removed 133 rows containing non-finite values (stat_qq).## Warning: Removed 133 rows containing non-finite values (stat_qq_line).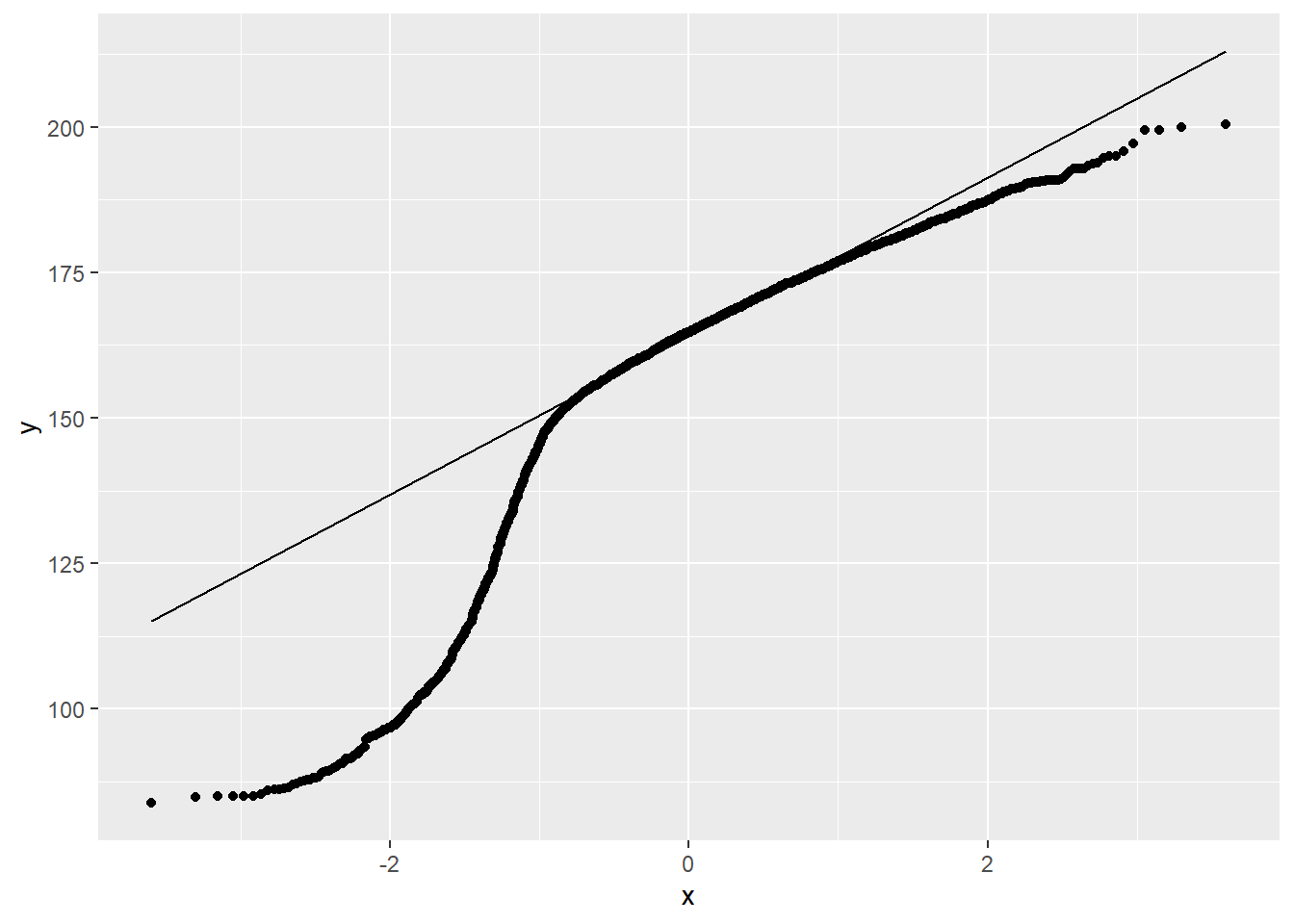
这是明显的左偏分布。 这是由未成年与成年的分布差异造成的。 选择年龄在18岁及以上的部分:
d_nhsub |>
dplyr::filter(Age >= 18) |>
ggplot(aes(sample = Height)) +
geom_qq() +
geom_qq_line() ## Warning: Removed 22 rows containing non-finite values (stat_qq).## Warning: Removed 22 rows containing non-finite values (stat_qq_line).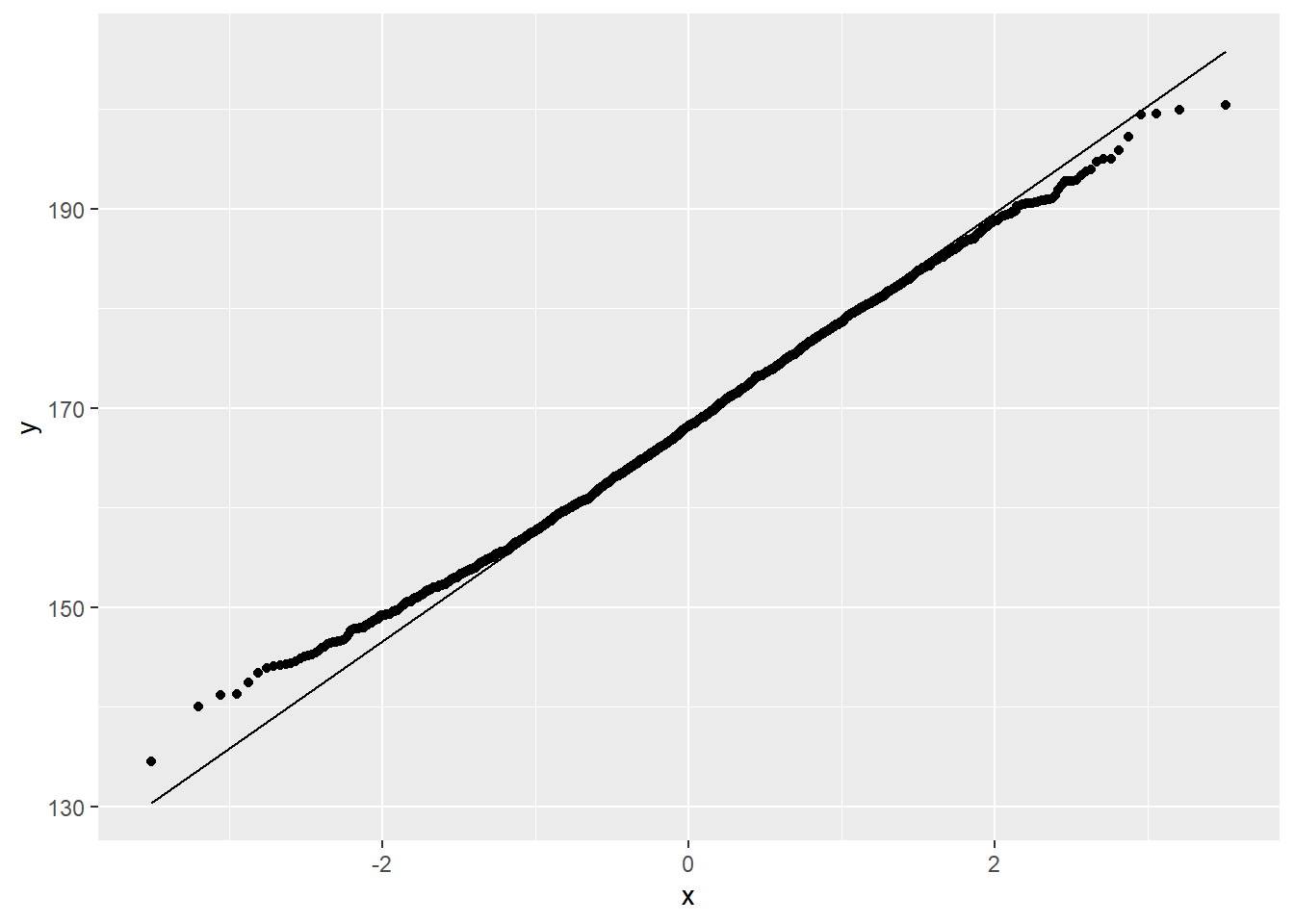
29.3 用skimr进行简单概括
skimr扩展包可以对一个数据集的所有变量进行简单概括, 分为分类变量和数值型变量两组,如:
library(skimr)## Warning: package 'skimr' was built under R version 4.2.2skim(d_nhsub, Gender, Age, Height) |> print()## ── Data Summary ────────────────────────
## Values
## Name d_nhsub
## Number of rows 3211
## Number of columns 76
## _______________________
## Column type frequency:
## factor 1
## numeric 2
## ________________________
## Group variables None
##
## ── Variable type: factor ───────────────────────────────────────────────────────
## skim_variable n_missing complete_rate ordered n_unique top_counts
## 1 Gender 0 1 FALSE 2 fem: 1621, mal: 1590
##
## ── Variable type: numeric ──────────────────────────────────────────────────────
## skim_variable n_missing complete_rate mean sd p0 p25 p50 p75 p100
## 1 Age 0 1 35.1 23.3 0 14 33 54 80
## 2 Height 133 0.959 160. 21.5 83.8 155. 165. 173. 200.
## hist
## 1 ▇▆▆▅▃
## 2 ▁▁▂▇▂对于分类变量Gender, 概括内容包括缺失观测数(missing), 非缺失观测数(complete), 总观测数(n), 不同值个数(n_unique), 取值频数最多的典型值及其频数以及缺失个数(top_counts), 是否有序因子(ordered)。
对于连续型(区间型)变量Age和Height, 也包括了缺失观测数、非缺失观测数、总观测数, 另外给出了样本均值、标准差和“五数概括”, 即最小值(p0),最大值(p100), 中位数(p50),四分位数(p25和p75)。
29.4 两个分类变量之间的关系
考察两个分类变量:性别(Gender)和教育程度(Education)之间的关系。 先计算交叉频数分布:
d_gened <- d_nhsub |>
count(Gender, Education) |>
group_by(Gender) |>
mutate(in_gend_pct = n / sum(n)) |>
ungroup()
knitr::kable(d_gened)| Gender | Education | n | in_gend_pct |
|---|---|---|---|
| female | 8th Grade | 68 | 0.0419494 |
| female | 9 – 11th Grade | 120 | 0.0740284 |
| female | High School | 215 | 0.1326342 |
| female | Some College | 388 | 0.2393584 |
| female | College Grad | 330 | 0.2035780 |
| female | NA | 500 | 0.3084516 |
| male | 8th Grade | 95 | 0.0597484 |
| male | 9 – 11th Grade | 148 | 0.0930818 |
| male | High School | 206 | 0.1295597 |
| male | Some College | 307 | 0.1930818 |
| male | College Grad | 294 | 0.1849057 |
| male | NA | 540 | 0.3396226 |
其中in_gend_pct是在性别内部的学历比例。
或:
with(d_nhsub, table(
Education, Gender
))## Gender
## Education female male
## 8th Grade 68 95
## 9 - 11th Grade 120 148
## High School 215 206
## Some College 388 307
## College Grad 330 294更详细的列联表:
with(d_nhsub, gmodels::CrossTable(
Education, Gender
))##
##
## Cell Contents
## |-------------------------|
## | N |
## | Chi-square contribution |
## | N / Row Total |
## | N / Col Total |
## | N / Table Total |
## |-------------------------|
##
##
## Total Observations in Table: 2171
##
##
## | Gender
## Education | female | male | Row Total |
## ---------------|-----------|-----------|-----------|
## 8th Grade | 68 | 95 | 163 |
## | 3.105 | 3.315 | |
## | 0.417 | 0.583 | 0.075 |
## | 0.061 | 0.090 | |
## | 0.031 | 0.044 | |
## ---------------|-----------|-----------|-----------|
## 9 - 11th Grade | 120 | 148 | 268 |
## | 2.442 | 2.607 | |
## | 0.448 | 0.552 | 0.123 |
## | 0.107 | 0.141 | |
## | 0.055 | 0.068 | |
## ---------------|-----------|-----------|-----------|
## High School | 215 | 206 | 421 |
## | 0.026 | 0.028 | |
## | 0.511 | 0.489 | 0.194 |
## | 0.192 | 0.196 | |
## | 0.099 | 0.095 | |
## ---------------|-----------|-----------|-----------|
## Some College | 388 | 307 | 695 |
## | 2.365 | 2.525 | |
## | 0.558 | 0.442 | 0.320 |
## | 0.346 | 0.292 | |
## | 0.179 | 0.141 | |
## ---------------|-----------|-----------|-----------|
## College Grad | 330 | 294 | 624 |
## | 0.189 | 0.201 | |
## | 0.529 | 0.471 | 0.287 |
## | 0.294 | 0.280 | |
## | 0.152 | 0.135 | |
## ---------------|-----------|-----------|-----------|
## Column Total | 1121 | 1050 | 2171 |
## | 0.516 | 0.484 | |
## ---------------|-----------|-----------|-----------|
##
## 比较男女之间教育程度的堆叠条形图:
ggplot(d_gened, aes(
x = Gender, fill = Education, y = n)) +
geom_col(position = "stack")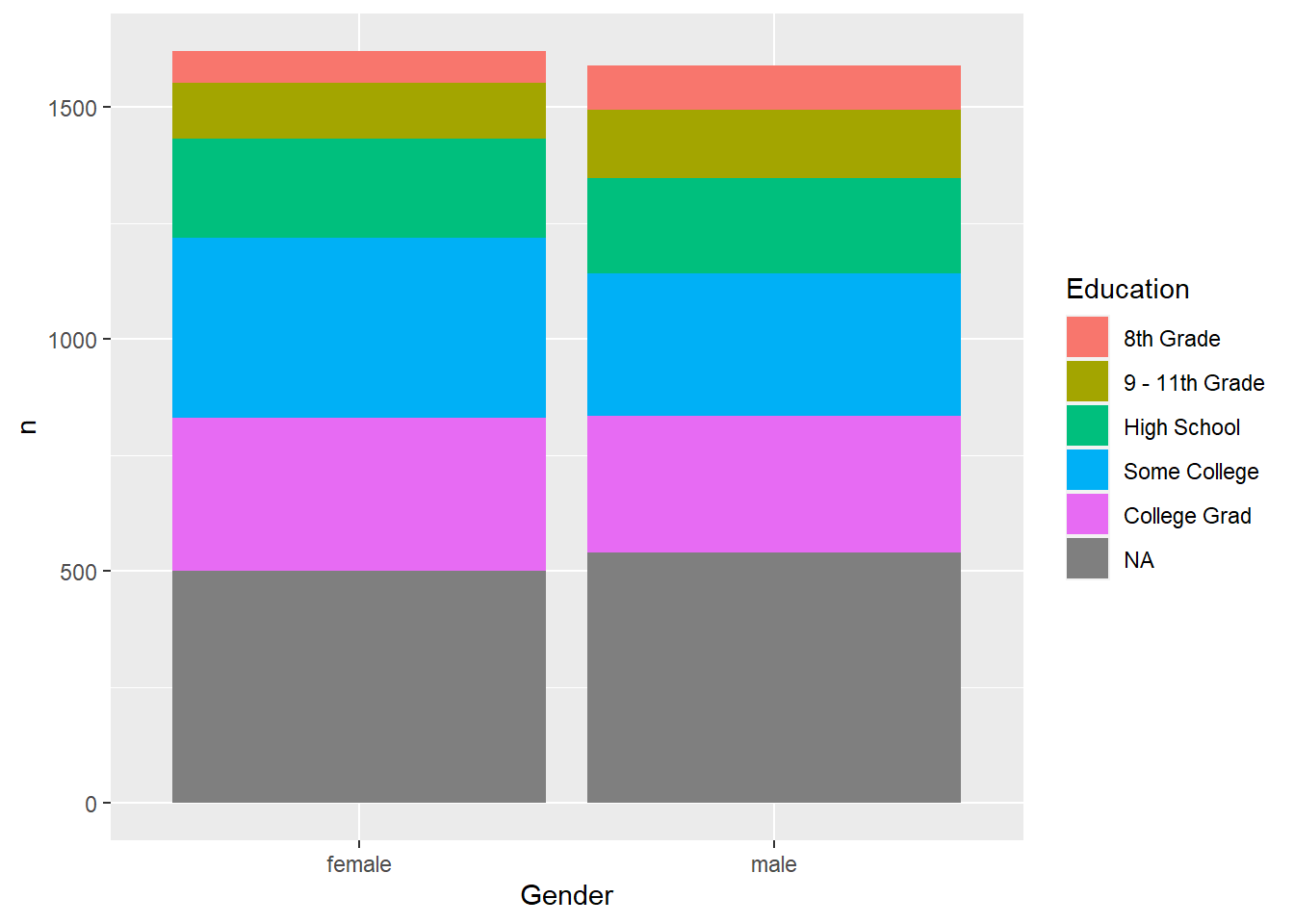
并列条形图,使用百分比比较:
ggplot(d_gened, aes(
x = Gender, fill = Education, y = in_gend_pct)) +
geom_col(position = "dodge")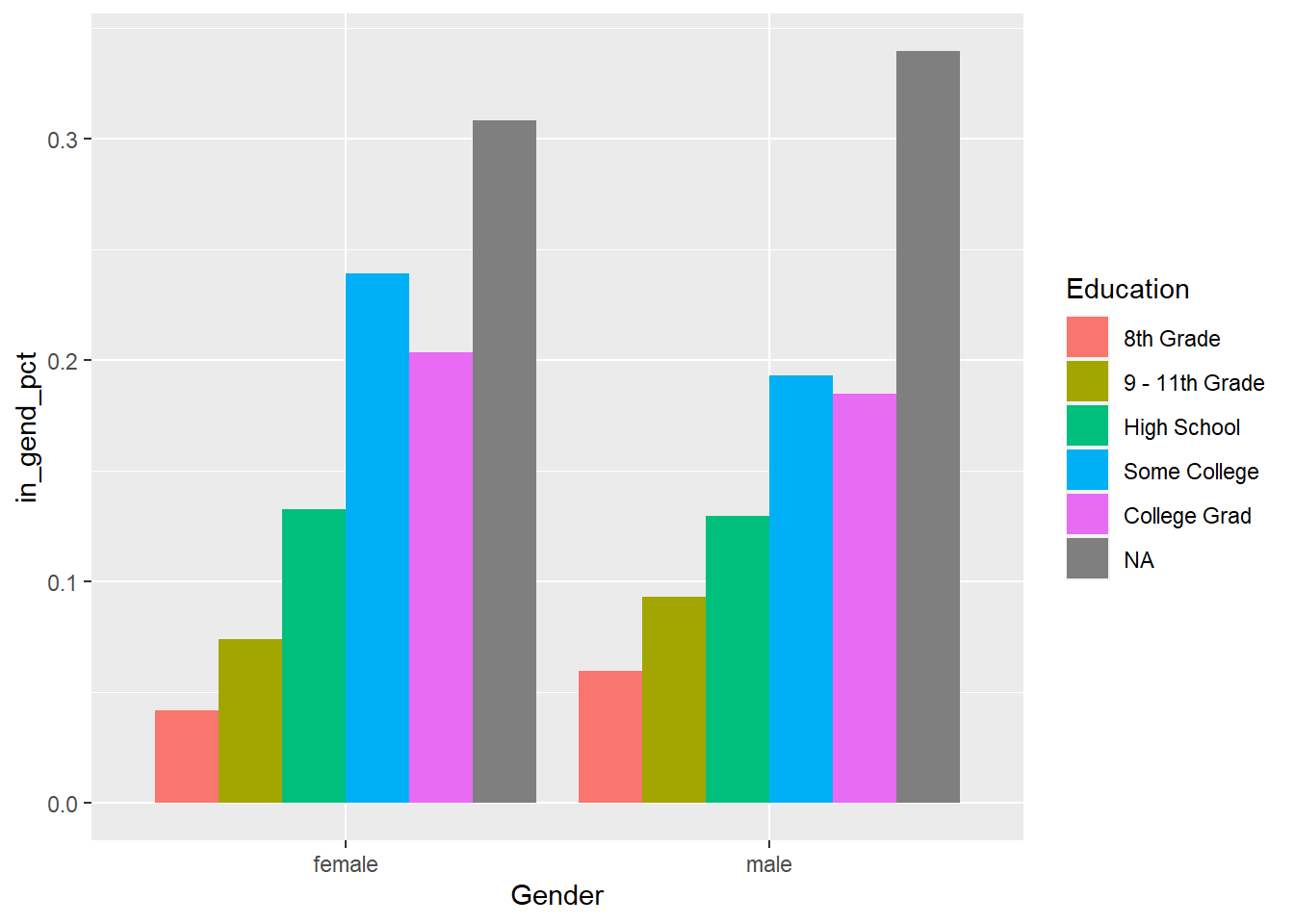
不显示缺失值:
ggplot(drop_na(d_gened), aes(
x = Gender, fill = Education, y = in_gend_pct)) +
geom_col(position = "dodge") +
labs(y="")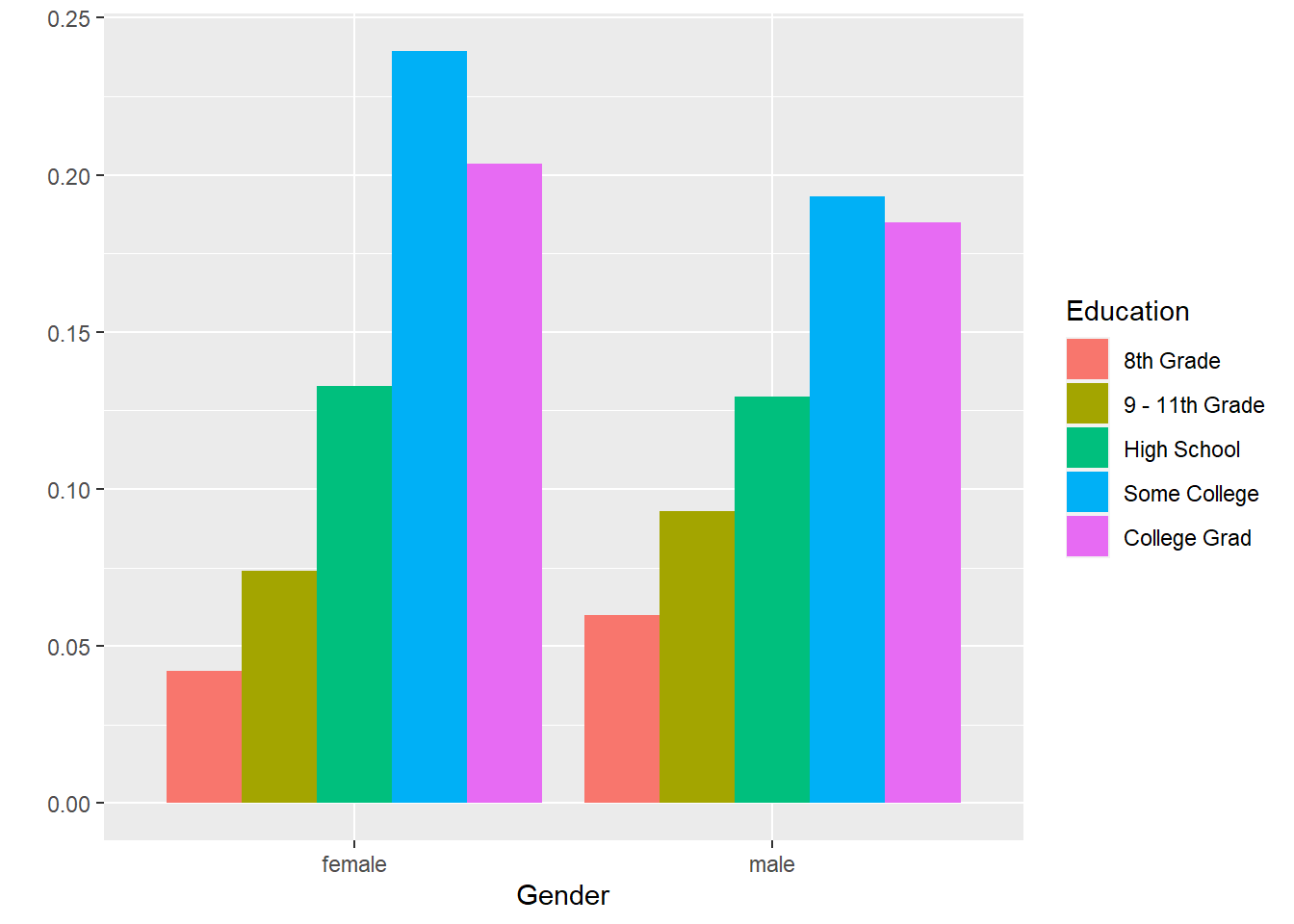
分两组比较分布:
ggplot(drop_na(d_gened), aes(
x = Education, y = in_gend_pct)) +
facet_wrap(~ Gender, ncol=1) +
geom_col() +
coord_flip() +
labs(y="")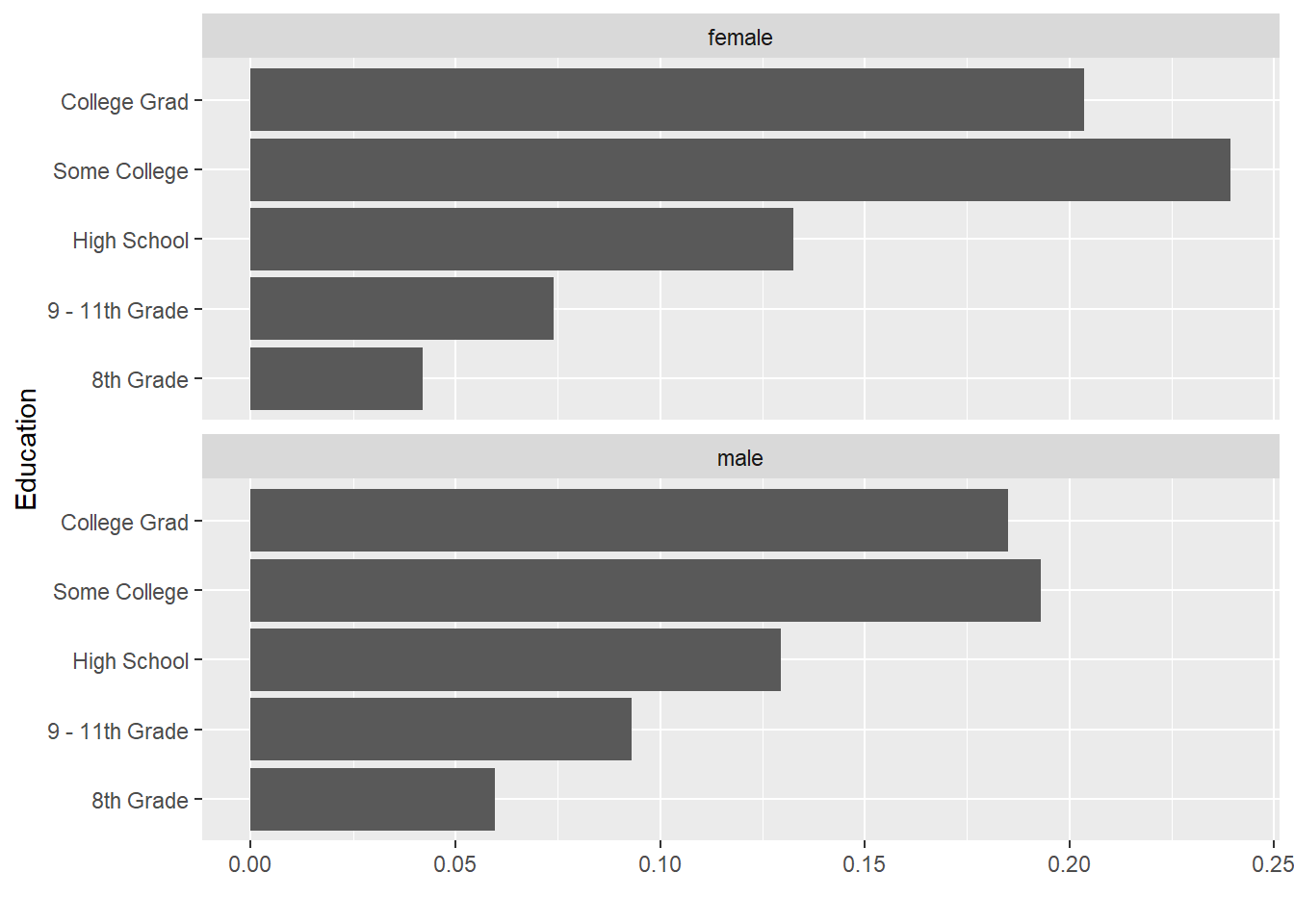
较复杂的频数表, 也可以看成一个矩阵, 用色块图表示频数,如:
ggplot(d_gened, aes(
x = Gender, y = Education, fill = n)) +
geom_tile()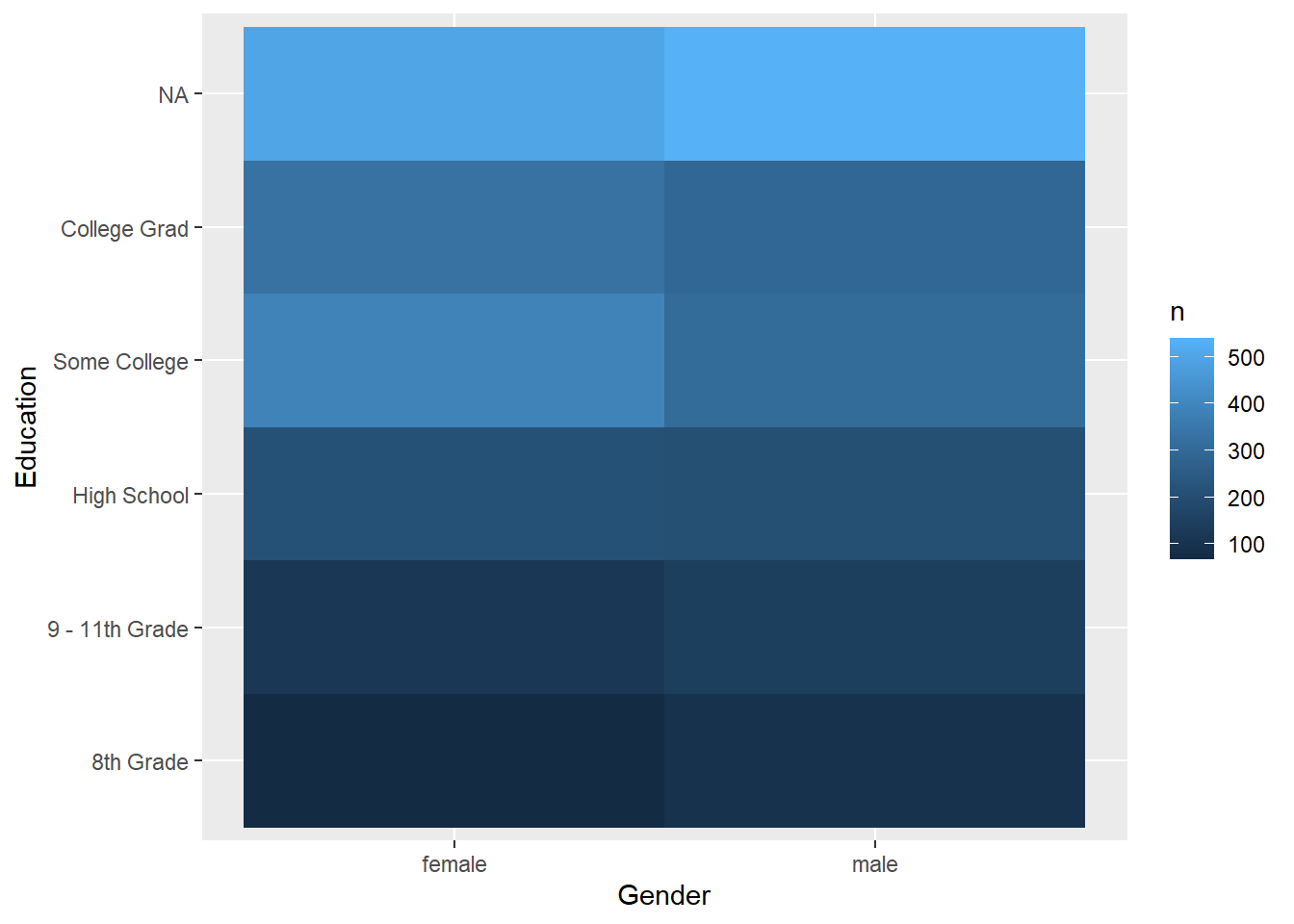
29.5 一个分类变量与一个区间型变量之间的关系
考虑不同性别的身高的比较。我们选择18岁以上的样本。
男、女身高的并列盒形图:
d_genht <- d_nhsub |>
dplyr::filter(Age >= 18) |>
select(Gender, Height, Age, Weight, BMI)
ggplot(d_genht, aes(
x = Gender, y = Height)) +
geom_boxplot()## Warning: Removed 22 rows containing non-finite values (stat_boxplot).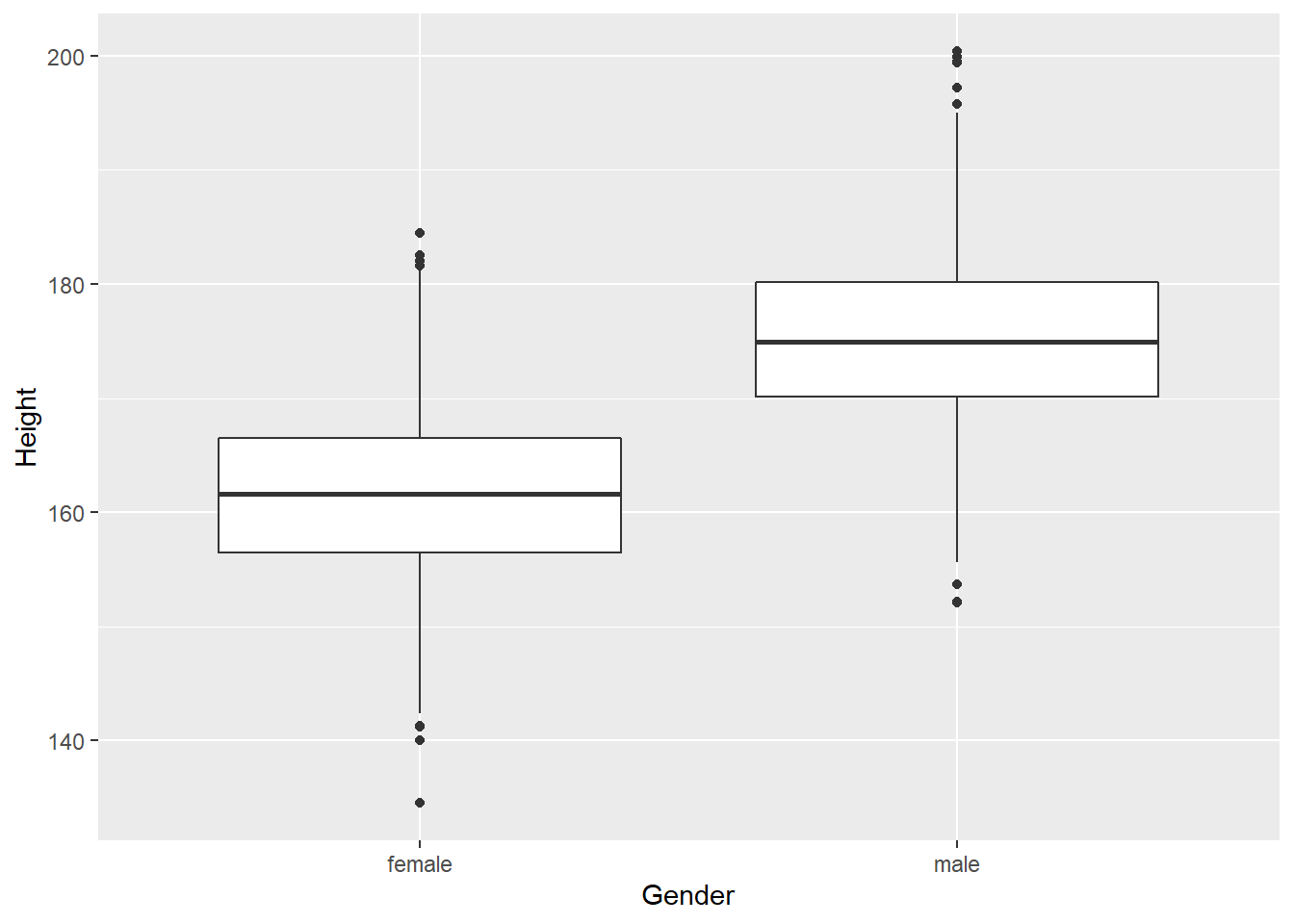
并列小提琴图:
ggplot(d_genht, aes(
x = Gender, y = Height)) +
geom_violin()## Warning: Removed 22 rows containing non-finite values (stat_ydensity).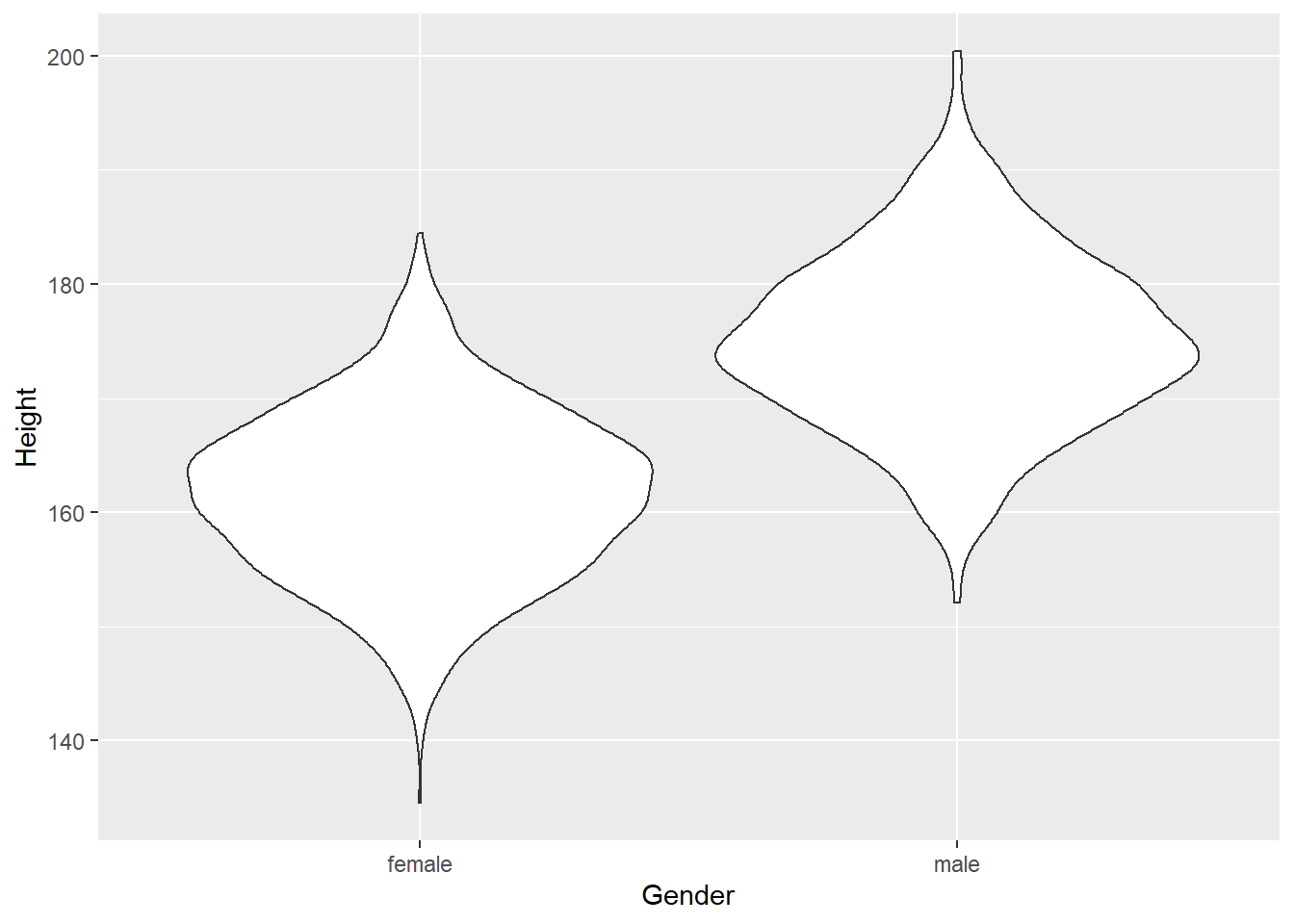
点图:
ggplot(d_genht, aes(
x = Gender, y = Height)) +
geom_jitter(
width = 0.3, height = 0,
size = 0.5, alpha = 0.5)## Warning: Removed 22 rows containing missing values (geom_point).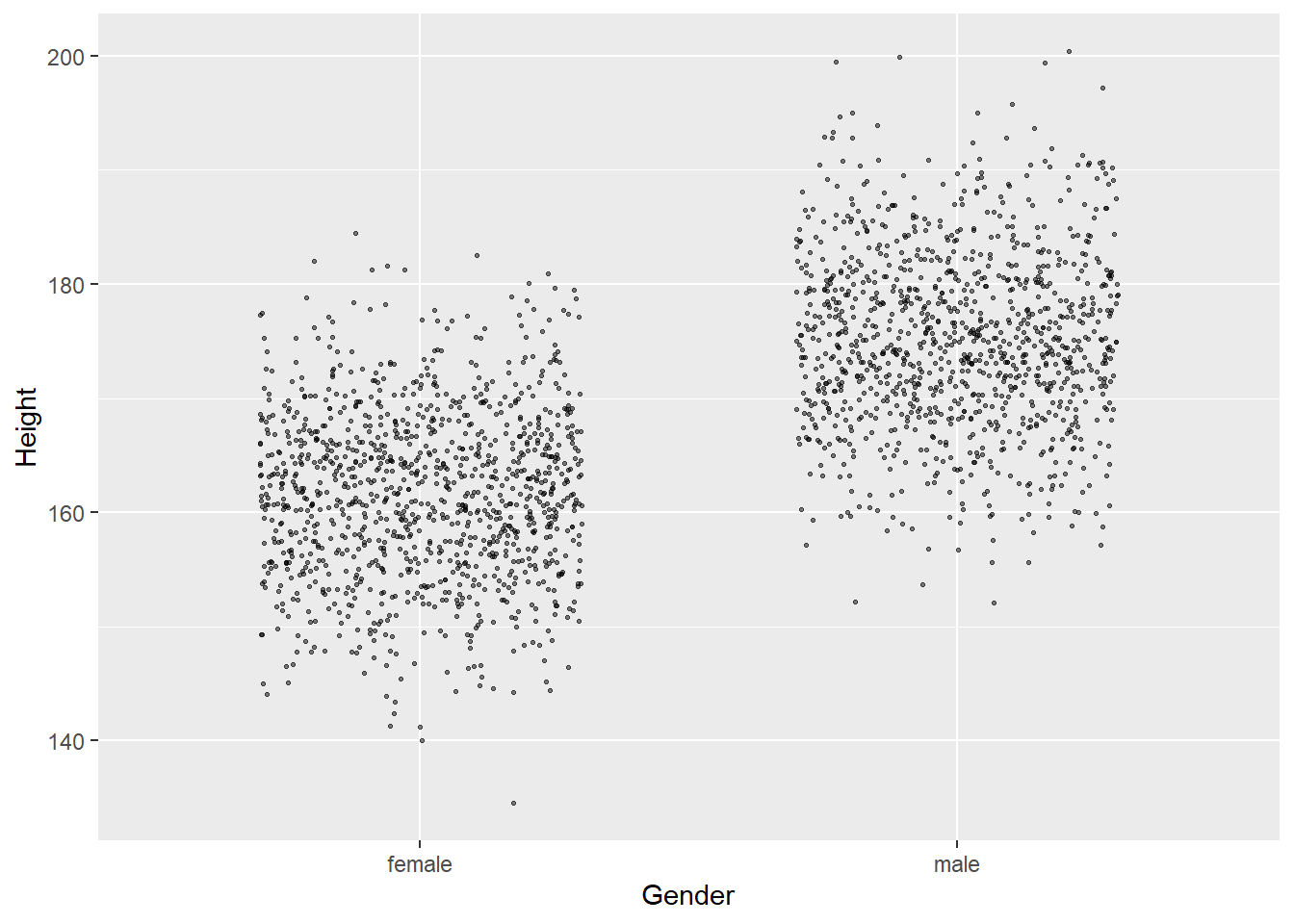
比较核密度估计:
ggplot(d_genht, aes(
x = Height,
color = Gender)) +
geom_density()## Warning: Removed 22 rows containing non-finite values (stat_density).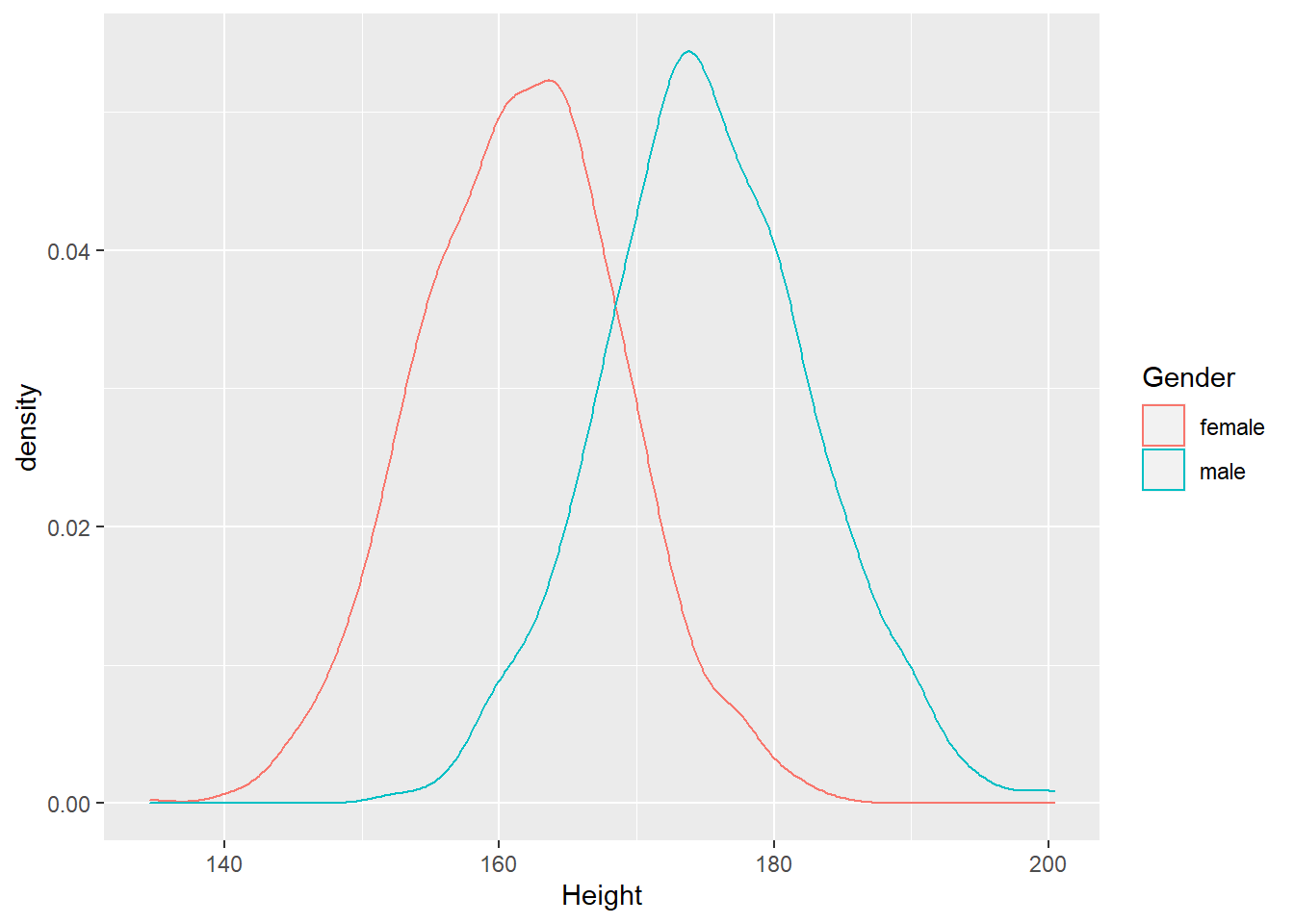
29.6 两个区间型变量之间的关系
考虑身高(Height)和体重(Weight)的关系。 可以计算两者的相关系数:
d_genht |>
summarize(cor = cor(Height, Weight, use="complete.obs"))## # A tibble: 1 × 1
## cor
## <dbl>
## 1 0.434用散点图表示两者关系:
ggplot(d_genht, aes(x = Height, y = Weight)) +
geom_point()## Warning: Removed 24 rows containing missing values (geom_point).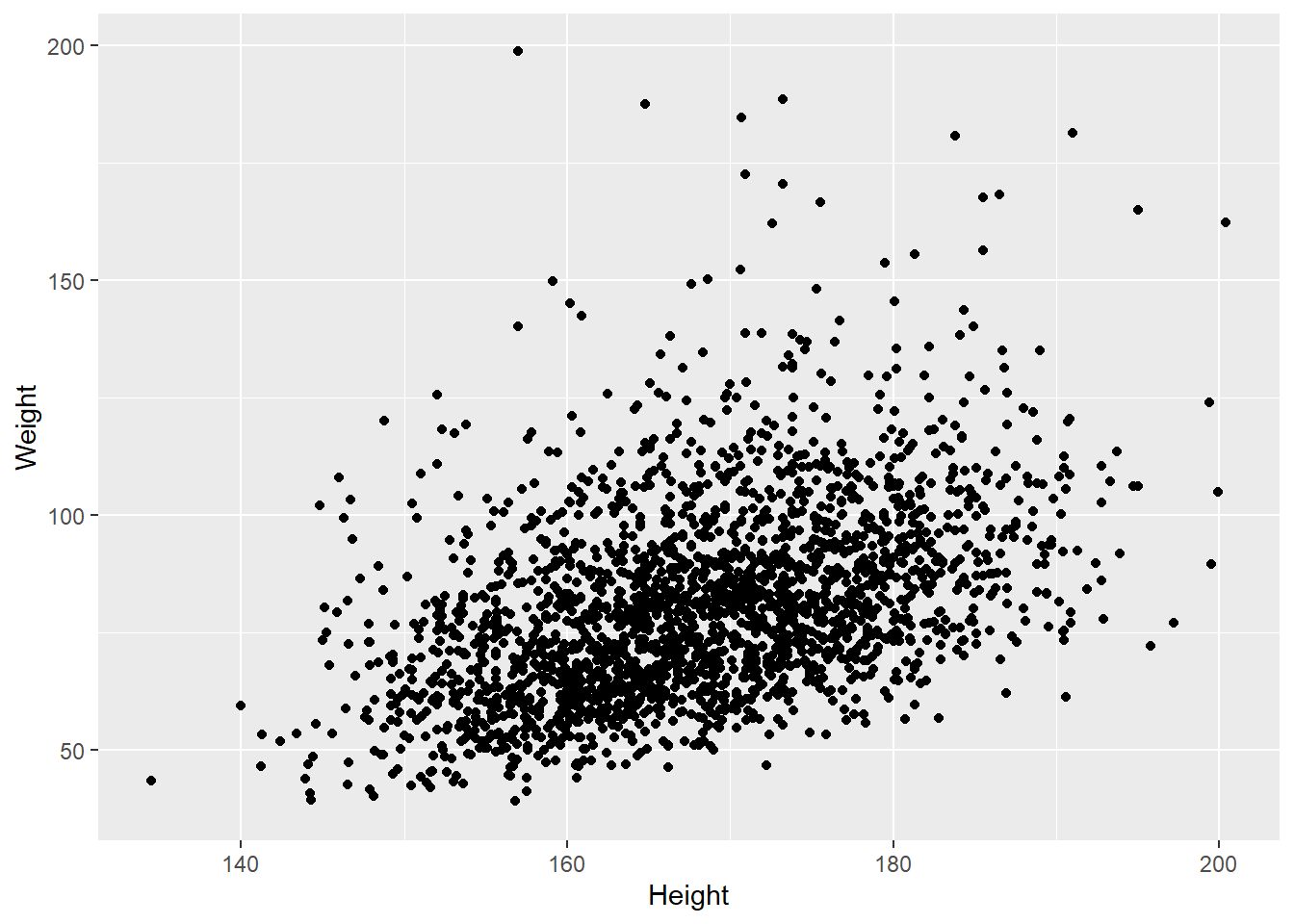
叠加拟合曲线:
ggplot(d_genht, aes(x = Height, y = Weight)) +
geom_point() +
geom_smooth()## `geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")'## Warning: Removed 24 rows containing non-finite values (stat_smooth).## Warning: Removed 24 rows containing missing values (geom_point).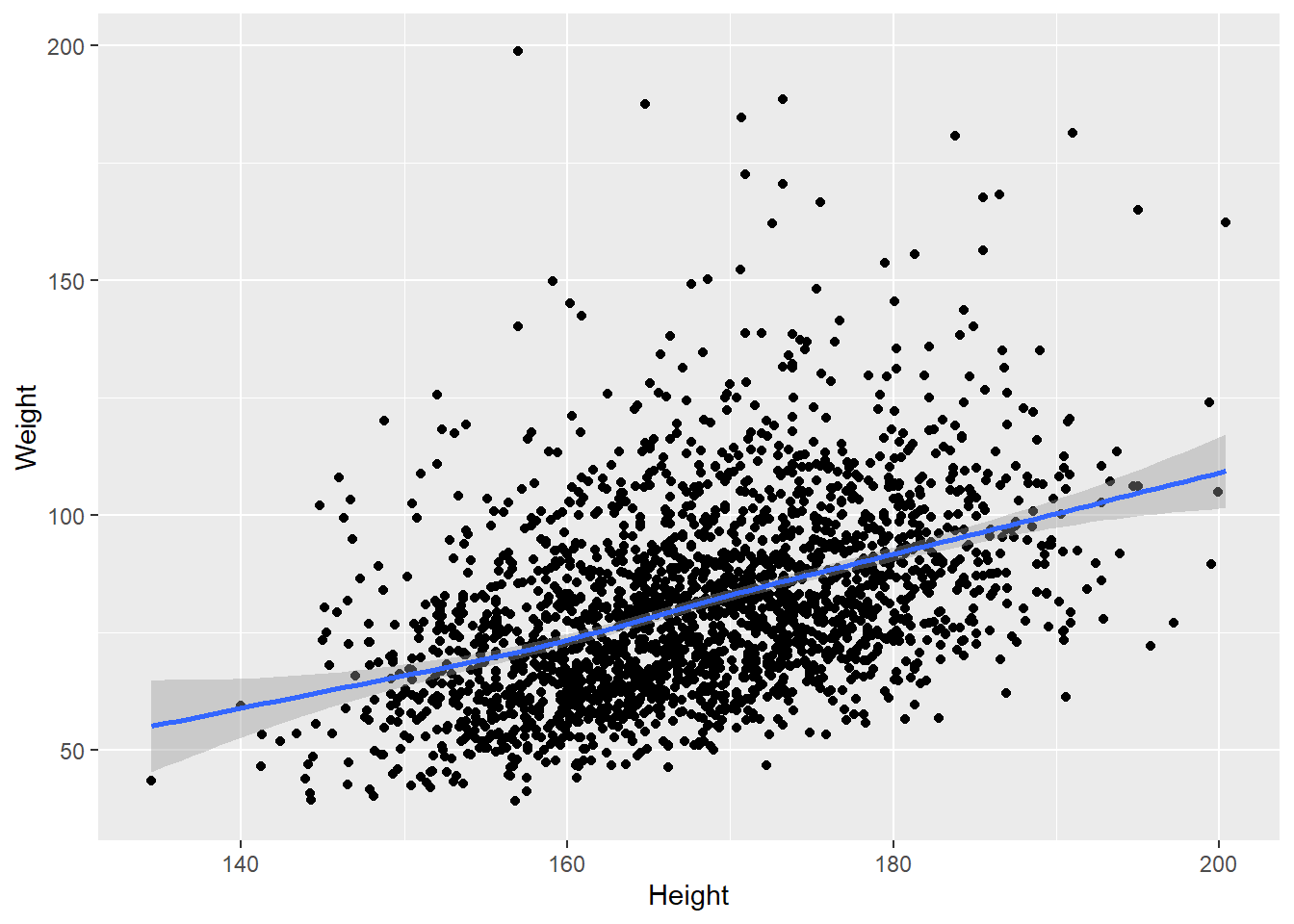
多个区间变量之间可以计算相关系数矩阵:
d_genht |>
select(Height, Weight, BMI, Age) |>
cor(use = "pairwise.complete.obs")## Height Weight BMI Age
## Height 1.00000000 0.43360892 -0.03996646 -0.15849296
## Weight 0.43360892 1.00000000 0.87627484 -0.01645548
## BMI -0.03996646 0.87627484 1.00000000 0.06683342
## Age -0.15849296 -0.01645548 0.06683342 1.00000000可以用图形方式表示相关系数矩阵:
d_cor <- d_genht |>
select(Height, Weight, BMI, Age) |>
cor(use = "pairwise.complete.obs")
library(ggcorrplot)## Warning: package 'ggcorrplot' was built under R version 4.2.2ggcorrplot(d_cor,
hc.order=TRUE,
lab=TRUE)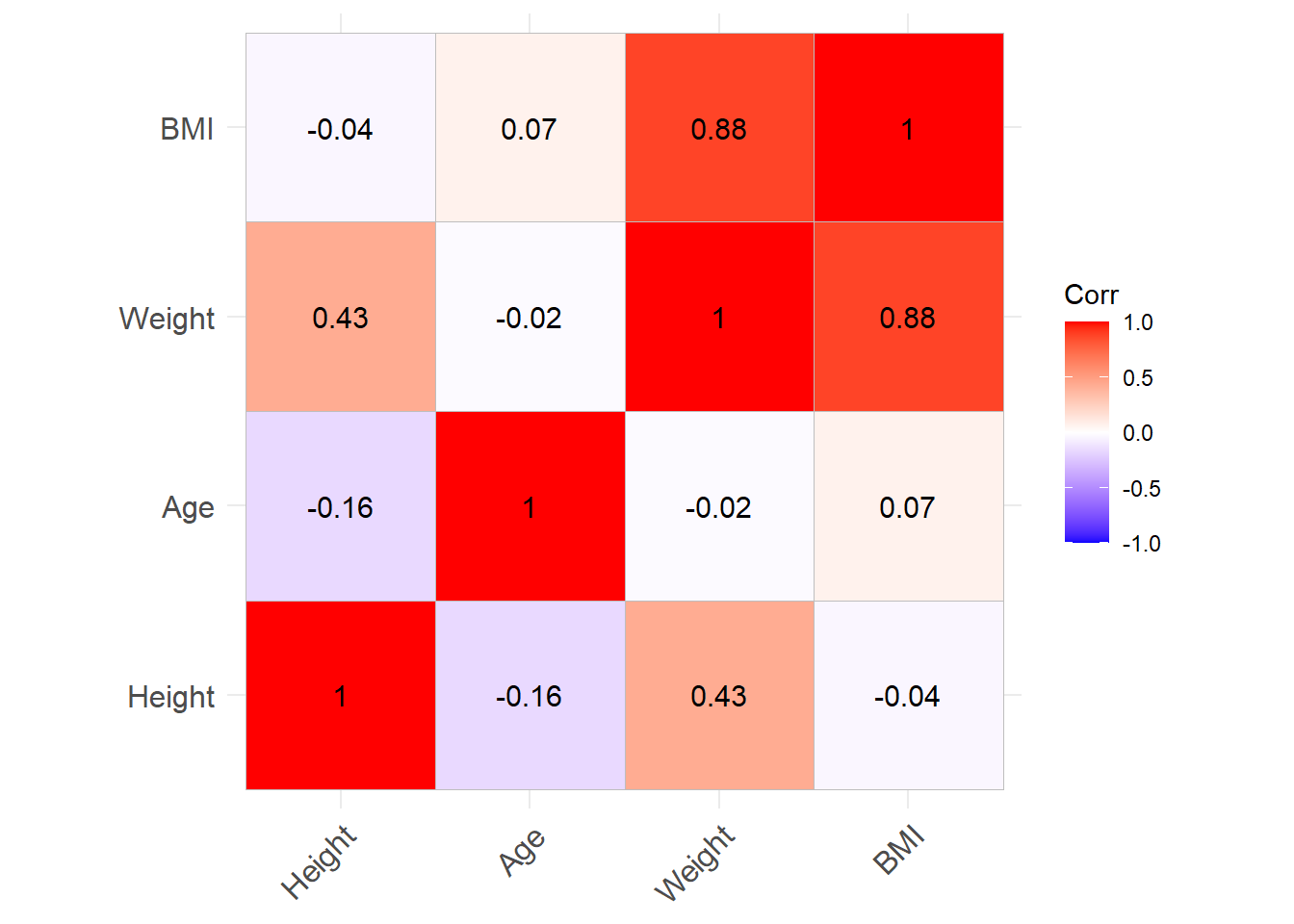
变量不太多时, 可以作散点图矩阵:
library(GGally)## Warning: package 'GGally' was built under R version 4.2.2## Registered S3 method overwritten by 'GGally':
## method from
## +.gg ggplot2d_genht |>
select(Height, Weight, BMI, Age) |>
ggscatmat()## Warning: Removed 22 rows containing non-finite values (stat_density).## Warning: Removed 20 rows containing non-finite values (stat_density).## Warning: Removed 24 rows containing non-finite values (stat_density).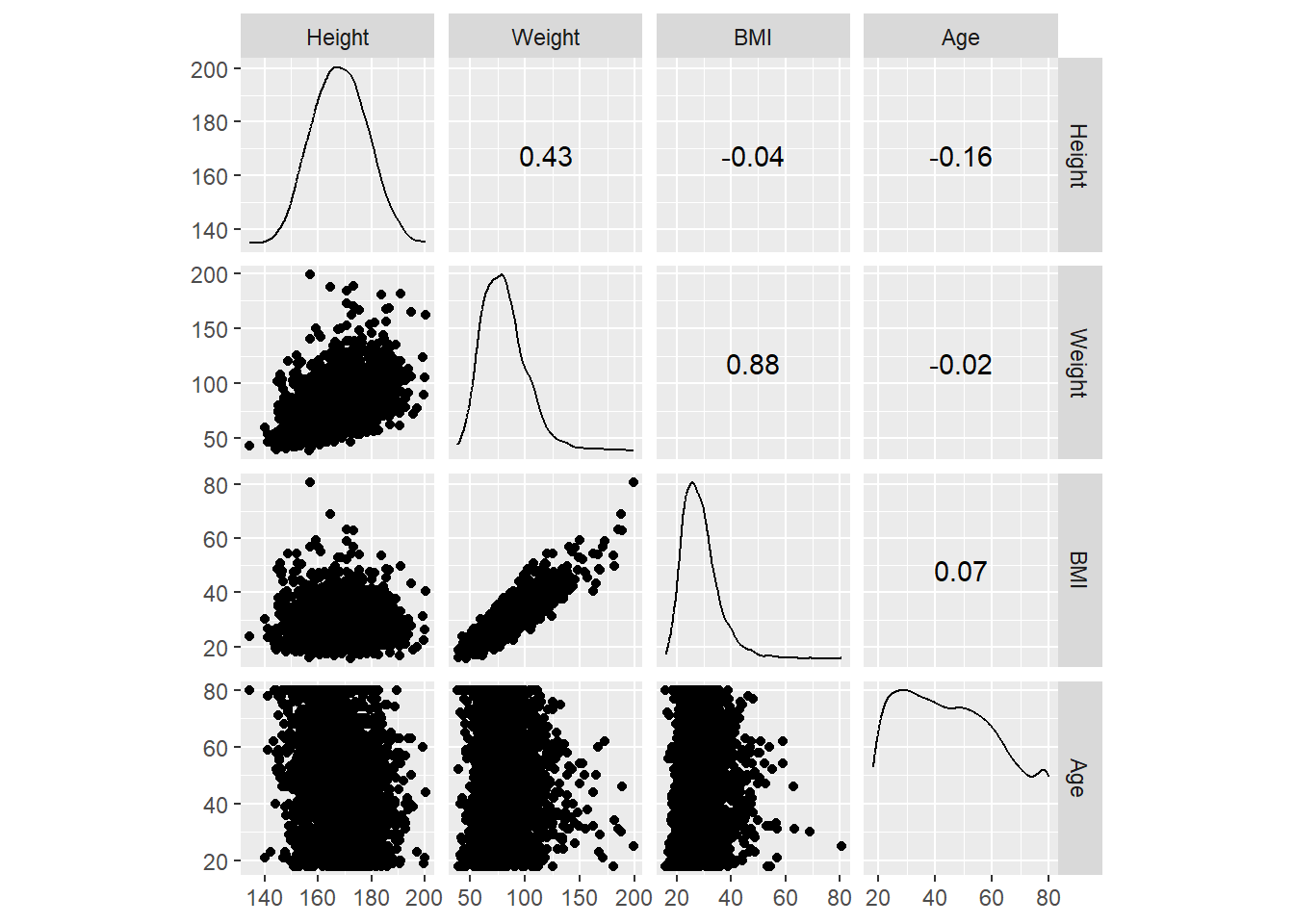
29.7 一个分类变量对两个区间型变量的影响
为了研究一个变量z对另外两个变量x、y的影响, 可以按z的值切片作其它两个变量的图形, 如比较不同性别的体重、身高关系:
ggplot(d_genht, aes(x = Height, y = Weight)) +
geom_point() +
geom_smooth() +
facet_wrap(~ Gender) ## `geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")'## Warning: Removed 24 rows containing non-finite values (stat_smooth).## Warning: Removed 24 rows containing missing values (geom_point).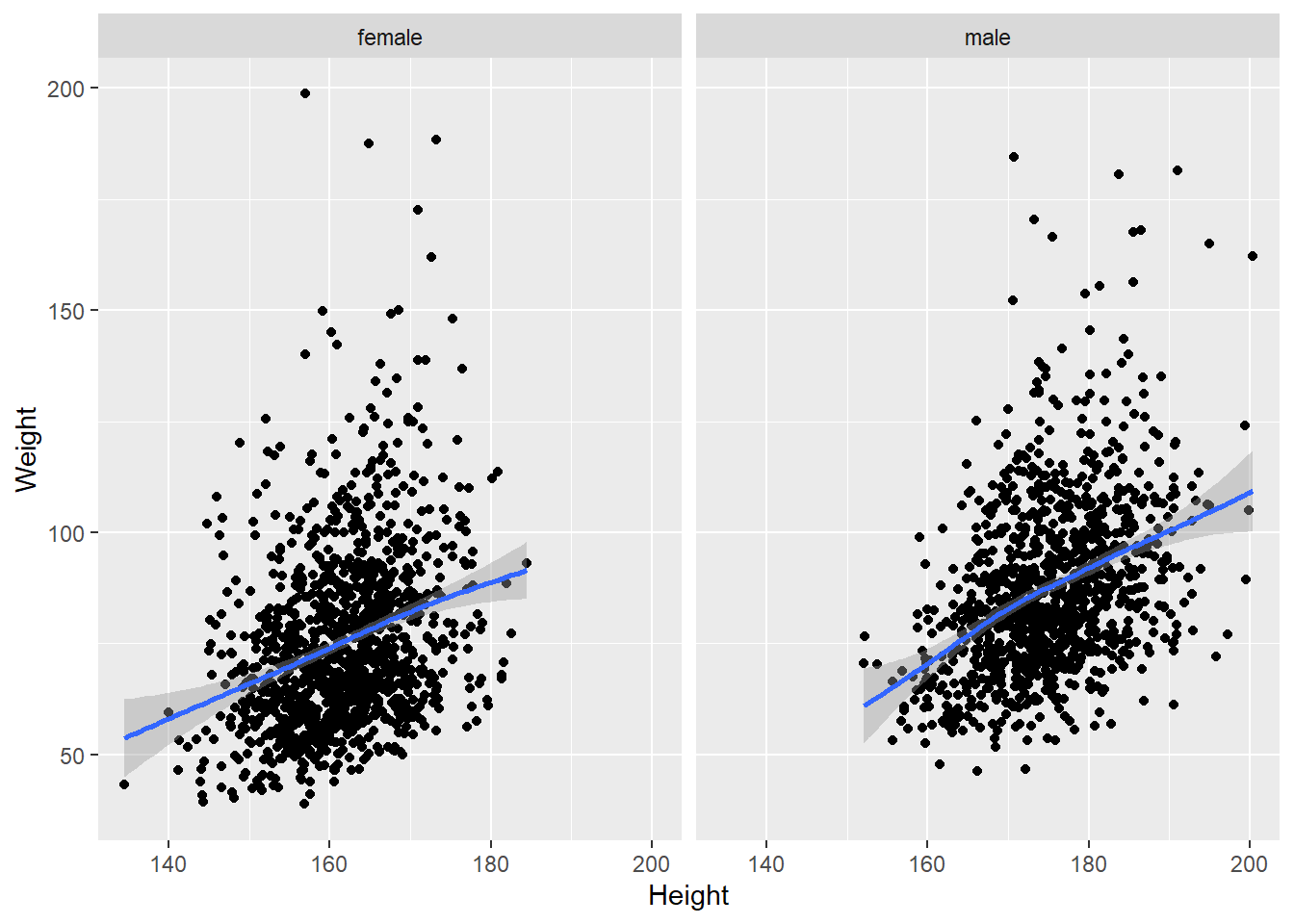
29.8 时间序列数据
如果数据含有时间序列, 将时间序列画成曲线图可以发现趋势、季节性等特征, 参见28.6。
韭菜热线原创版权所有,发布者:风生水起,转载请注明出处:https://www.9crx.com/79362.html




