

在当今的数据驱动投资环境中,数据的质量、可用性和具体性可以决定一个策略的成功与否。然而,投资专业人士经常面临限制:历史数据集可能无法捕捉新兴风险,替代数据往往不完整或成本高昂,开源模型和数据集则偏向于主要市场和英语内容。
随着企业寻求更灵活和前瞻性的工具,合成数据——特别是从生成 AI(GenAI)中衍生出来的——正在成为一种战略资产,提供了一种新的方式来模拟市场情景、训练机器学习模型和回测投资策略。本文探讨了生成 AI 驱动的合成数据如何重塑投资工作流程——从模拟资产相关性到增强情绪模型——以及从业者需要了解的内容,以评估其效用和局限性。
合成数据究竟是什么?生成式人工智能模型又是如何生成这些数据的?为什么它们在投资应用场景中越来越相关?
考虑两个常见的挑战。一位组合经理希望在不同市场环境下优化表现,但受限于历史数据,无法涵盖尚未发生的“假设”情景。同样,一位监测德语新闻中小盘股情绪的数据科学家可能会发现,大多数可用的数据集都是用英语编制的,且主要关注大盘公司,这既限制了覆盖面,也降低了相关性。在两种情况下,合成数据都提供了一个实用的解决方案。
生成式人工智能合成数据的独特之处——以及为何现在很重要
合成数据是指人工生成的数据集,其统计特性能够模拟真实世界数据。虽然这一概念并不新奇——蒙特卡洛模拟和自助法等技术长期以来一直支持金融分析——但变化在于生成方式 。
GenAI 指的是一类能够生成跨模态(如文本、表格、图像和时间序列)高保真合成数据的深度学习模型。与传统方法不同,GenAI 模型可以直接从数据中学习复杂的现实世界分布,从而消除对生成过程的严格假设。这种能力在投资管理领域开启了强大的应用场景,特别是在真实数据稀缺、复杂、不完整或受限于成本、语言或监管的领域。
不同类型的 GenAI 模型包括变分自编码器(VAEs)、生成对抗网络(GANs)、基于扩散的模型以及大型语言模型(LLMs)。这些模型都是基于神经网络架构构建的,尽管它们在规模和复杂性上有所不同。这些方法已经在行业内展示了增强某些数据驱动工作流程的潜力。例如,VAEs 已被用于创建合成波动率曲面以改善期权交易(Bergeron et al., 2021)。GANs 已被证明在投资组合优化和风险管理方面很有用(Zhu, Mariani and Li, 2020; Cont et al., 2023)。基于扩散的模型在模拟各种市场环境下资产回报相关矩阵方面也证明了其有用性(Kubiak et al., 2024)。而 LLMs 在市场模拟方面也证明了其有用性(Li et al., 2024)。
表1. 合成数据生成的方法。
| 方法 | 生成的数据类型 | 示例应用 | 生成型? |
| 蒙特卡洛 | 时间序列 | 投资组合优化,风险管理 | 否 |
| 基于 copula 的函数 | 时间序列,表格 | 信用风险分析,资产相关性建模 | 否 |
| 自回归模型 | 时间序列 | 波动率预测,资产回报模拟 | 不 |
| 自助法 | 时间序列、表格、文本 | 创建置信区间、压力测试 | 否 |
| 变分自编码器 | 表格数据、时间序列、音频、图像 | 模拟波动率曲面 | 是 |
| 生成对抗网络 | 表格、时间序列、音频、图像, | 组合优化、风险管理、模型训练 | 是 |
| 扩散模型 | 表格,时间序列,音频,图像, | 相关建模,组合优化 | 是 |
| 大型语言模型 | 文本,表格,图像,音频 | 情绪分析,市场模拟 | 是 |
评估合成数据质量
合成数据应该具有现实性,并且与真实数据的统计特性相匹配。现有的评估方法可以分为两类:定量和定性。
定性方法涉及可视化真实数据集和合成数据集之间的比较。例如,可以可视化分布、比较变量对之间的散点图、时间序列路径和相关矩阵。例如,一个训练用于模拟资产回报以估计风险价值的 GAN 模型应该成功地再现分布的厚尾。一个在不同市场环境下训练生成合成相关矩阵的扩散模型应该充分捕捉资产间的联动性。
定量方法包括用于比较分布的统计测试,如柯尔莫哥洛夫-斯米尔诺夫检验、人口稳定性指数和詹森-香农散度。这些测试输出统计值,表明两个分布之间的相似性。例如,柯尔莫哥洛夫-斯米尔诺夫检验输出一个 p 值,如果小于 0.05,表明两个分布显著不同。这可以提供一个更具体的测量来衡量两个分布之间的相似性,而不是通过可视化。
另一种方法是“基于合成数据训练,基于真实数据测试”,即模型在合成数据上训练,在真实数据上测试。可以将该模型的性能与在真实数据上进行训练和测试的模型进行比较。如果合成数据成功地复制了真实数据的特性,那么两个模型的性能应该相似。
在行动:利用生成式 AI 合成数据增强金融情绪分析
为了将这一实践应用到实际中,我使用了一个公开的数据集 FiQA-SA[1],对一个小型开源 LLM Qwen3-0.6B 进行了微调,用于金融情绪分析。该数据集包含 822 个训练样本,大多数句子被分类为“正面”或“负面”情绪。
我随后使用 GPT-4o 生成了 800 个合成训练样本。GPT-4o 生成的合成数据集比原始训练数据更加多样化,涵盖了更多的公司和情绪(图 1)。增加训练数据的多样性为 LLM 提供了更多的例子,使其能够从文本内容中识别情绪,这可能在处理未见过的数据时提高模型的性能。
图1. 实际数据(左)、合成数据(右)以及包含实际和合成数据的增强训练数据集(中)的情绪类别分布。
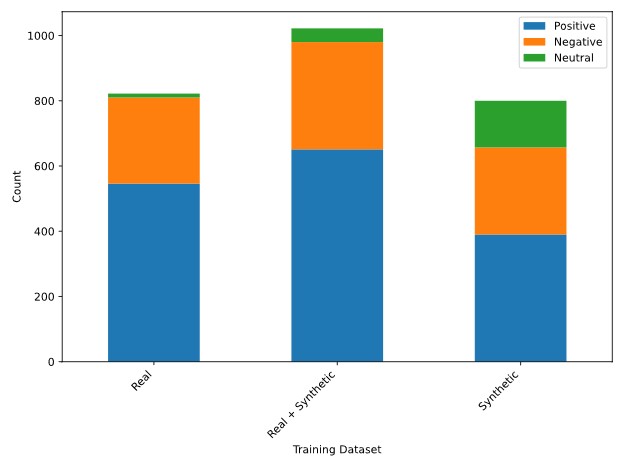

表2. 实际训练数据集和合成训练数据集的示例句子。
| 句子 | 类别 | 数据 |
| weir 公司股价下跌,导致富时指数从历史最高点回落。 | 负面 | 真实 |
| 阿斯利康获得 FDA 批准其新的关键肺癌药物。 | 正面 | 真实 |
| 壳牌和 BG 的股东将于一月底对这笔交易进行投票。 | 中性 | 真实 |
| 特斯拉的季度报告显示车辆交付量增长了15%。 | 积极 | 合成 |
| 百事公司召开新闻发布会以应对最近的产品召回事件。 | 中立 | 合成 |
| Home Depot 的 CEO 在内部争议中突然辞职。 | 负面 | 合成 |
经过在相同训练程序下对第二个模型进行微调,结合使用真实数据和合成数据后,验证数据集上的 F1 分数提高了近 10 个百分点(表 3),最终测试数据集上的 F1 分数为 82.37%。
表 3. 模型在 FiQA-SA 验证数据集上的性能。
| Model | 加权 F1 评分 |
| Model 1(真实数据) | 75.29% |
| Model 2(真实数据 + 合成数据) | 85.17% |
我发现增加合成数据的比例过多会产生负面影响。合成数据过多和过少之间存在一个最佳区间。
不是万能药,但是一项有价值的工具
合成数据不是真实数据的替代品,但值得一试。选择一种方法,评估合成数据的质量,并在沙盒环境中进行 A/B 测试,比较使用不同比例合成数据的工作流程与未使用合成数据的工作流程。你可能会对结果感到惊讶。
您可以在 RPC Labs 的 GitHub 仓库查看所有代码和数据集 ,并在研究与政策中心的“ 投资管理中的合成数据 ”研究报告中更深入地了解 LLM 案例研究。
[1] 数据集可在以下链接下载:https://huggingface.co/datasets/TheFinAI/fiqa-sentiment-classification
韭菜热线原创版权所有,发布者:风生水起,转载请注明出处:https://www.9crx.com/91326.html




